目錄
- 一、什么是記憶體碎片
- 二、如何判斷有記憶體碎片
- 三、記憶體碎片是怎么形成的
- 3.1 jemalloc分配機制導致
- 3.2 資料的修改洗掉操作導致
- 四、如何清理記憶體碎片
- 4.1 重啟
- 4.2 redis記憶體碎片自動清理機制
- 五、和現實的類比
一、什么是記憶體碎片
redis資料洗掉后,所占用記憶體不會馬上還給作業系統,而是交給記憶體分配管理器,所以對作業系統來說redis仍然占用著這些記憶體,
這里有個風險點是:redis釋放的記憶體有可能是不連續的,這種不連續的記憶體很可能無法再次使用,最終造成了記憶體的浪費,這種空閑但是無法使用的記憶體便是記憶體碎片,
接下來主要介紹redis的記憶體碎片情況,產生原因以及最終的應對方案,
二、如何判斷有記憶體碎片
可以通過redis提供的命令來查看redis的記憶體使用情況:
./redis-cli info memory
執行結果
# Memory
used_memory:5930032
used_memory_human:5.66M
used_memory_rss:8359936
used_memory_rss_human:7.97M
...
mem_fragmentation_ratio:1.32
used_memory是redis資料所占的記憶體大小,used_memory_rss是作業系統分配給redis的所有記憶體(包含沒有使用的碎片),
mem_fragmentation_ratio= used_memory_rss / used_memory
mem_fragmentation_ratio:
- 大于1但是小于1.5:是相對合理的,碎片化可以接受,可以不進行碎片整理,下一節的碎片形成的原因可以看出,碎片本身是無法徹底避免的,
- 大于1.5:碎片化嚴重,超過了50%,這種情況下需要想辦法對碎片進行整理,降低碎片化綠
- 小于1.0:redis資料所占記憶體小于作業系統所分配的記憶體,這不能說沒有碎片,這個時候說明redis的記憶體發送了swap,有一部分資料被交換到了硬碟,會嚴重影響redis的性能,需要馬上解決的,具體見作業系統swap對redis的影響,
三、記憶體碎片是怎么形成的
3.1 jemalloc分配機制導致
jemallco是redis的默認記憶體分配器,其分配策略不是完全按照作業系統的按需分配來進行的,而是按照2^n次方的方式來分配,比如8位元組,16位元組,32位元組、2KB,4KB,8KB等,固定大小,
當redis申請記憶體時候,jemalloc會分配一個大于所需記憶體但是最接近2^n的大小,比如需要20位元組,jemallo會分配32位元組,這樣天然就有12個位元組的碎片存在,且無法避免,
jemalloc這種分配方式的好處是減少記憶體分配的次數,上面的例子中需要20位元組,但是分配了32,如果后期再需要10位元組,則不再需要二次分配記憶體,
3.2 資料的修改洗掉操作導致
redis每個鍵值的大小都不一致,當有記憶體釋放后有可能太小最終無法被馬上使用,
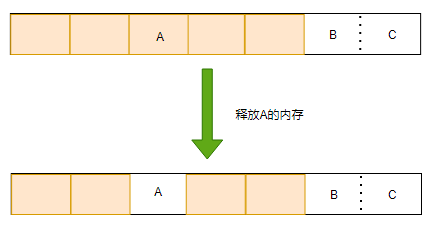
上圖中假定A、B、C三塊記憶體都為4KB,A被釋放后會有總共有3*4=12KB的記憶體可用,但是由于A、B、C不連續,如果這個時候有一個10KB的資料需要分配記憶體,以上記憶體是無法使用的,這就是記憶體的浪費,
大量的記憶體碎片會導致記憶體被浪費,這就需要對記憶體的碎片進行清理,
四、如何清理記憶體碎片
4.1 重啟
重啟是最簡單的辦法,但是重啟后如果沒有開啟rdb或者aof,資料會徹底丟失,
如果開啟了持久化機制,恢復需要一定的時間,恢復期間redis本身又不可用,
所以重啟不是第一選擇,比較優雅的辦法是采用redis自身的碎片清理機制,
4.2 redis記憶體碎片自動清理機制
4.0版本后redis提供了自動記憶體碎片清理機制,核心思想就是對記憶體進行搬家合并,讓空閑的記憶體合并到一起,形成大塊可以使用的連續空間,繼續上面的例子,
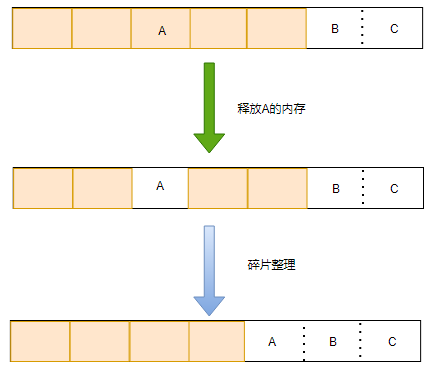
可以看到通過碎片整理的記憶體能夠存盤10KB的資料,
開啟碎片自動清理
默認是關閉的,
CONFIG SET activedefrag yes
redis自己的配置說明
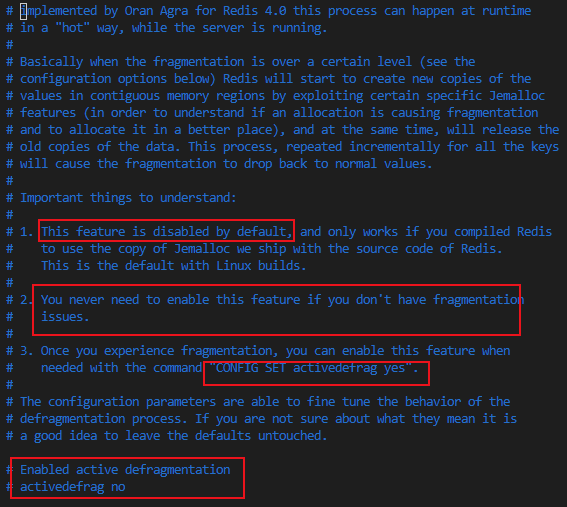
特別需要注意的是redis的自動記憶體碎片清理是由主執行緒執行的,執行期間無法處理客戶端請求,這會阻塞redis,影響redis的性能,所以不能頻繁的執行碎片清理,
redis也提供了一些引數用于控制碎片執行的時機和條件,
# The configuration parameters are able to fine tune the behavior of the
# defragmentation process. If you are not sure about what they mean it is
# a good idea to leave the defaults untouched.
# Enabled active defragmentation
# activedefrag no
# Minimum amount of fragmentation waste to start active defrag
# active-defrag-ignore-bytes 100mb
# Minimum percentage of fragmentation to start active defrag
# active-defrag-threshold-lower 10
# Maximum percentage of fragmentation at which we use maximum effort
# active-defrag-threshold-upper 100
# Minimal effort for defrag in CPU percentage, to be used when the lower
# threshold is reached
# active-defrag-cycle-min 1
# Maximal effort for defrag in CPU percentage, to be used when the upper
# threshold is reached
# active-defrag-cycle-max 25
# Maximum number of set/hash/zset/list fields that will be processed from
# the main dictionary scan
# active-defrag-max-scan-fields 1000
redis的上述組態檔也說明了,如非真的有必要,不要開啟碎片清理,
五、和現實的類比
買火車票,比如一班火車只有四個座位,分別在兩排,每一排都連著,
這個時候賣出兩張票,被兩個人買了,分別是第一排的一個座位和第二排的一個座位,剩余兩個座位,
這時候有人想買兩張連在一排的座位,就買不到了,雖然還有兩個座位,這就是碎片,是浪費,
平時坐火車我們有時候為了坐一起,會找協調其他旅客換座位,這就類似于碎片整理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/255550.html
標籤:NoSQL
下一篇:Redis Lua 腳本