抖音資料采集、分析,可視化顯示資料,粉絲畫像、評論詞云(附代碼)
短視頻、直播資料實時采集介面,請查看檔案: TiToData
免責宣告:本檔案僅供學習與參考,請勿用于非法用途!否則一切后果自負,
資料獲取
資料采集來源:TiToData,一共是有5000+抖音大V的資料資訊,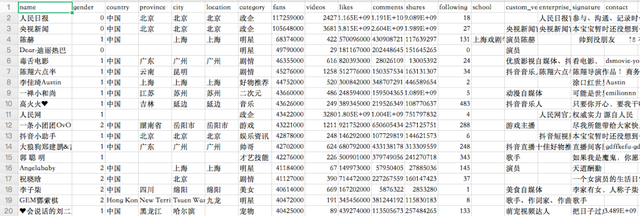
主要包含大V們的昵稱、性別、地點、型別、點贊數、粉絲數、視頻數、評論數、分享數、關注數、畢業學校、認證、簡介等資訊,
其中粉絲最多的是「人民日報」,接近1.2億,「央視新聞」也破億了,記得之前破億的時候還上過熱搜~
粉絲最少的博主也有近150w+的粉絲,這5000多位大V累計236.5億粉絲,地球人口的三倍多!
資料可視化
匯入相關庫,然后讀取資料,
1. from pyecharts.charts import Pie, Bar, TreeMap, Map, Geo
2. from wordcloud import WordCloud, ImageColorGenerator
3. from pyecharts import options as opts
4. import matplotlib.pyplot as plt
5. from PIL import Image
6. import pandas as pd
7. import numpy as np
8. import jieba
9.
10. df = pd.read_csv('douyin.csv', header=0, encoding='utf-8-sig')
11. print(df)
性別分布情況
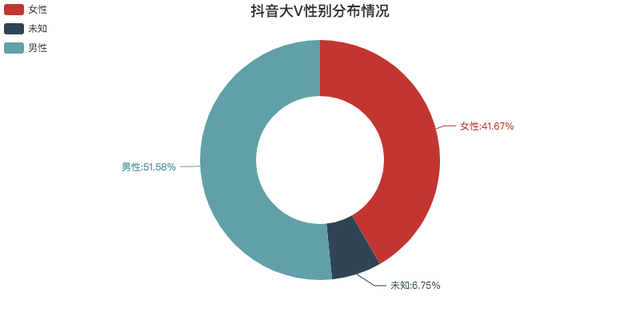
整體上看,男女比例差別不大,
除去未知的資料,基本是1:1,
可視化代碼如下,
1. def create_gender(df):
2. df = df.copy()
3. # 修改數值
4. df.loc[df.gender == '0', 'gender'] = '未知'
5. df.loc[df.gender == '1', 'gender'] = '男性'
6. df.loc[df.gender == '2', 'gender'] = '女性'
7. # 根據性別分組
8. gender_message = df.groupby(['gender'])
9. # 對分組后的結果進行計數
10. gender_com = gender_message['gender'].agg(['count'])
11. gender_com.reset_index(inplace=True)
12.
13. # 餅圖資料
14. attr = gender_com['gender']
15. v1 = gender_com['count']
16.
17. # 初始化配置
18. pie = Pie(init_opts=opts.InitOpts(width="800px", height="400px"))
19. # 添加資料,設定半徑
20. pie.add("", [list(z) for z in zip(attr, v1)], radius=["40%", "75%"])
21. # 設定全域配置項,標題、圖例、工具箱(下載圖片)
22. pie.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V性別分布情況", pos_left="center", pos_top="top"),
23. legend_opts=opts.LegendOpts(orient="vertical", pos_left="left"),
24. toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}))
25. # 設定系列配置項,標簽樣式
26. pie.set_series_opts(label_opts=opts.LabelOpts(is_show=True, formatter="{b}:{d}%"))
27. pie.render("抖音大V性別分布情況.html")
點贊數
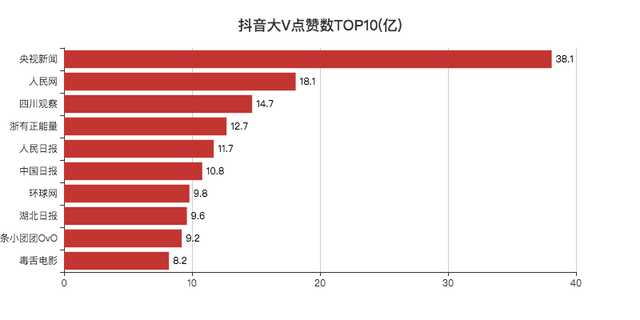
點贊數TOP10,除了「小團團」和「毒舌」,其他都是新聞媒體類的大V,
今年因為疫情,有很多新聞在抖音上都是第一時間傳播,所以影響力比較大,點贊也就比較多了,
記得「四川觀察」還被評論區調侃為四處觀察,意思是發布訊息非常快,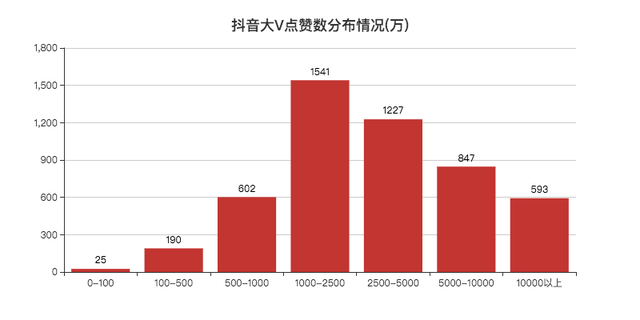
好奇為什么會有100萬點贊數的大V,小F的抖音號都有20w+的贊,
最后發現是第三方監測收錄的問題,下次可以直接剔除這批資料,
點贊破億的有500多個大V,1000萬到5000萬點贊數的大V人數最多,
可視化代碼如下,
1. def create_likes(df):
2. # 排序,降序
3. df = df.sort_values('likes', ascending=False)
4. # 獲取TOP10的資料
5. attr = df['name'][0:10]
6. v1 = [float('%.1f' % (float(i) / 100000000)) for i in df['likes'][0:10]]
7.
8. # 初始化配置
9. bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
10. # x軸資料
11. bar.add_xaxis(list(reversed(attr.tolist())))
12. # y軸資料
13. bar.add_yaxis("", list(reversed(v1)))
14. # 設定全域配置項,標題、工具箱(下載圖片)、y軸分割線
15. bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V點贊數TOP10(億)", pos_left="center", pos_top="18"),
16. toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
17. xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
18. # 設定系列配置項,標簽樣式
19. bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
20. bar.reversal_axis()
21. bar.render("抖音大V點贊數TOP10(億).html")
22.
23.
24. def create_cut_likes(df):
25. # 將資料分段
26. Bins = [0, 1000000, 5000000, 10000000, 25000000, 50000000, 100000000, 5000000000]
27. Labels = ['0-100', '100-500', '500-1000', '1000-2500', '2500-5000', '5000-10000', '10000以上']
28. len_stage = pd.cut(df['likes'], bins=Bins, labels=Labels).value_counts().sort_index()
29. # 獲取資料
30. attr = len_stage.index.tolist()
31. v1 = len_stage.values.tolist()
32.
33. # 生成柱狀圖
34. bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
35. bar.add_xaxis(attr)
36. bar.add_yaxis("", v1)
37. bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V點贊數分布情況(萬)", pos_left="center", pos_top="18"),
38. toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
39. yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
40. bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black"))
41. bar.render("抖音大V點贊數分布情況(萬).html")
粉絲數
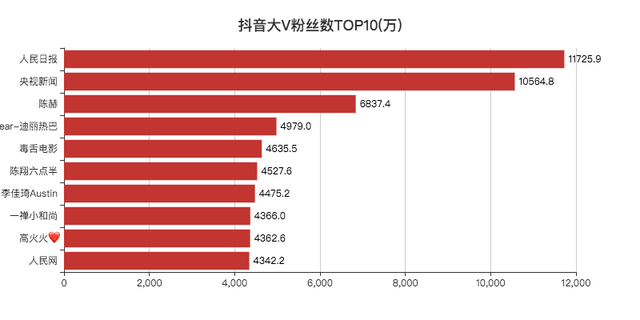
「人民日報」和「央視新聞」粉絲都破億了,
和去年的抖音資料一對比,「熱巴」還少了幾十萬的粉絲,陳赫倒是漲了不少粉絲,
今年直播帶歡訓熱,李佳琦排入前十,也不足為奇,畢竟帶貨一哥,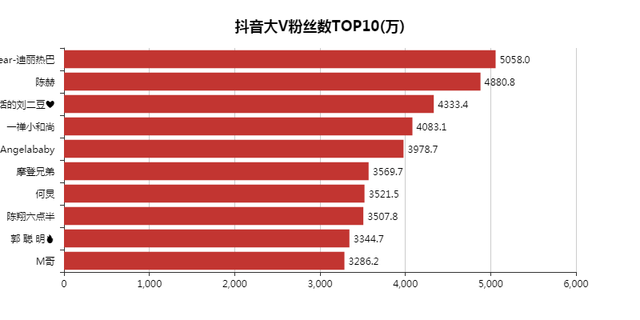
再來看一下大V們粉絲數的分布情況,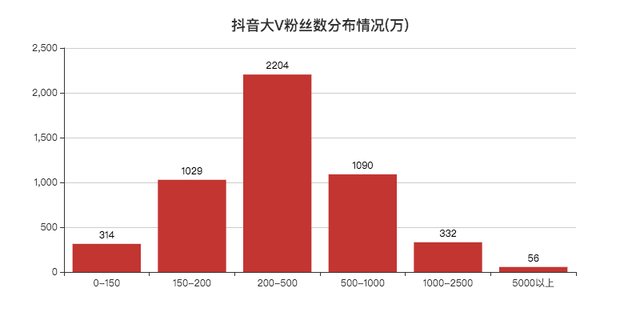
5000萬以上56個,妥妥的大佬,
200w~500w的人數最多,好多一時爆火的博主,一段時間后也基本不怎么漲粉了,
可能都停留到了這里,比如小F以前刷過的「三支花」,想不明白這都能火...
這里的可視化代碼和上面差不多,就不放出來了,
評論數TOP10
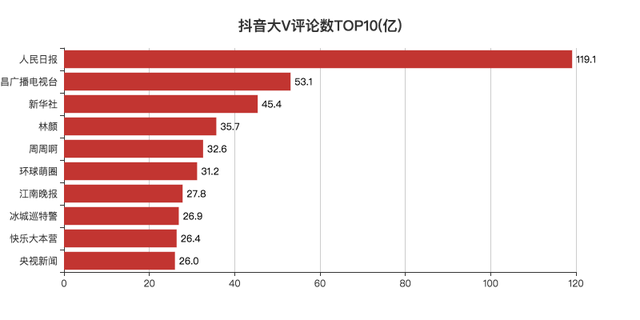
抖音視頻的評論區也是比較有意思的地方,
比如刷劇催更的,「趕緊去更新,都過了十幾分鐘了,生產隊的驢都不敢休息這么久」,
還有五只瘋狂搖頭的貓,也占領了評論區一段時間,
只能說,太魔性了~
總的來說,媒體類的視頻評論較多,
分享數TOP10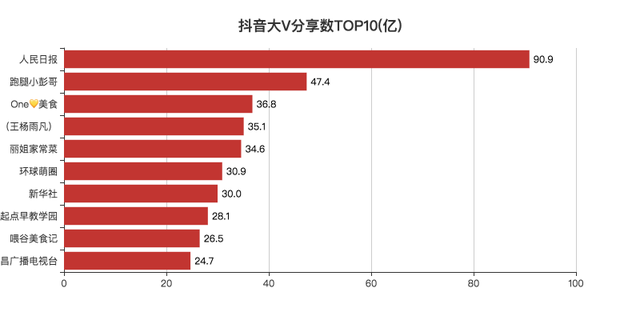
抖音的分享是視頻對外傳播的一個方法,可以讓更多的人看到視頻,
從資料上看,大家還是比較喜歡分享新聞類以及美食類的視頻,
可能過年疫情,居家一個月的時間,除了葛優躺看新聞,就是吃吃吃,
每個人,也就都有了一個成為大廚的夢想,
各型別點贊數/粉絲數匯總分布圖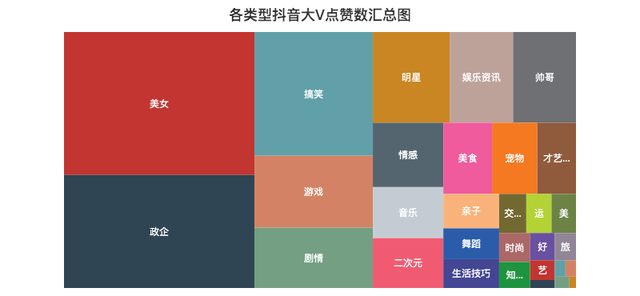
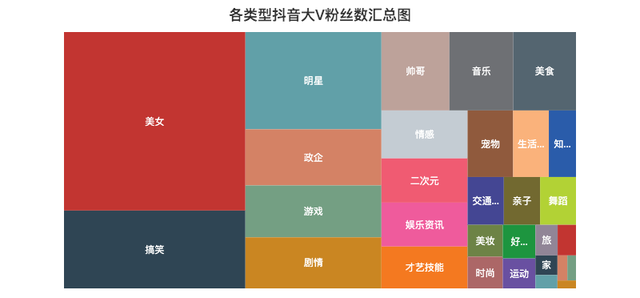
記得曾經一位大佬說過,抖音這個產品是消磨你時間的(Kill Time),而不是節約時間(Save Time),技術稍微深一點的視頻基本上生存不下去,
由上面的矩形樹圖可以知道,大家都喜歡「美女」型別的視頻,畢竟誰不喜歡漂亮妹子呢~
比如說深情看銅人的妹子、高考送滿天星的妹子,刀小刀等等,妹子爆火的視頻太多了...
另外「搞笑」、「游戲」、「劇情」類的視頻也比較吸引人,妥妥的Kill Time,
可視化代碼如下,
1. def create_type_likes(df):
2. # 分組求和
3. likes_type_message = df.groupby(['category'])
4. likes_type_com = likes_type_message['likes'].agg(['sum'])
5. likes_type_com.reset_index(inplace=True)
6. # 處理資料
7. dom = []
8. for name, num in zip(likes_type_com['category'], likes_type_com['sum']):
9. data = https://www.cnblogs.com/titodata/archive/2021/02/03/{}
10. data['name'] = name
11. data['value'] = num
12. dom.append(data)
13. print(dom)
14.
15. # 初始化配置
16. treemap = TreeMap(init_opts=opts.InitOpts(width="800px", height="400px"))
17. # 添加資料
18. treemap.add('', dom)
19. # 設定全域配置項,標題、工具箱(下載圖片)
20. treemap.set_global_opts(title_opts=opts.TitleOpts(title="各型別抖音大V點贊數匯總圖", pos_left="center", pos_top="5"),
21. toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
22. legend_opts=opts.LegendOpts(is_show=False))
23.
24. treemap.render("各型別抖音大V點贊數匯總圖.html")
平均視頻點贊數/粉絲數TOP10
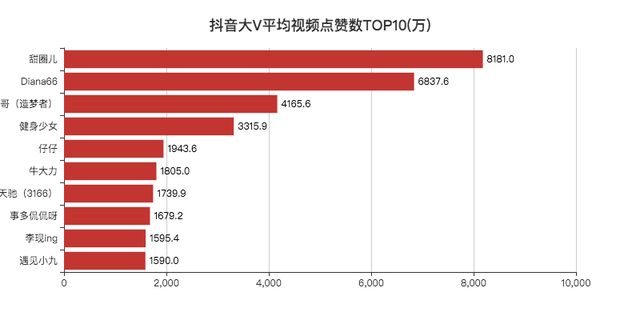
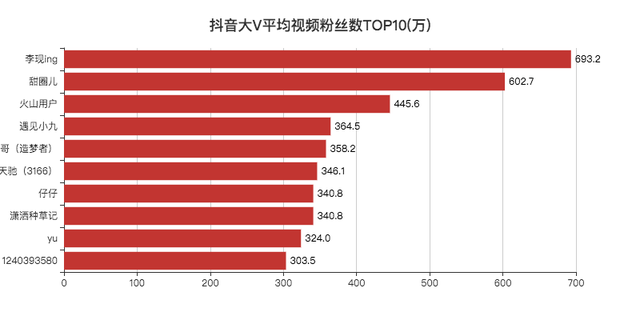
「李現」作為2019年的頂級流量,登頂第一,沒啥問題,
其他的博主小F一個也沒關注過,
去搜索了一下,發現大部分賬號只有一兩個視頻,
看了評論區,發現原來號被賣掉了,有可能是大V和公司分手了,畢竟現在好多做網紅的公司,不火就下一位,
另一種就是個人轉讓賬號,變現賺錢跑路咯,
可視化代碼如下,
1. def create_avg_likes(df):
2. # 篩選
3. df = df[df['videos'] > 0]
4. # 計算單個視頻平均點贊數
5. df.eval('result = likes/(videos*10000)', inplace=True)
6. df['result'] = df['result'].round(decimals=1)
7. df = df.sort_values('result', ascending=False)
8.
9. # 取TOP10
10. attr = df['name'][0:10]
11. v1 = ['%.1f' % (float(i)) for i in df['result'][0:10]]
12.
13. # 初始化配置
14. bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
15. # 添加資料
16. bar.add_xaxis(list(reversed(attr.tolist())))
17. bar.add_yaxis("", list(reversed(v1)))
18. # 設定全域配置項,標題、工具箱(下載圖片)、y軸分割線
19. bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V平均視頻點贊數TOP10(萬)", pos_left="center", pos_top="18"),
20. toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
21. xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
22. # 設定系列配置項
23. bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
24. # 翻轉xy軸
25. bar.reversal_axis()
26. bar.render("抖音大V平均視頻點贊數TOP10(萬).html")
抖音大V分布情況
省份看完了,來看一下城市TOP10吧,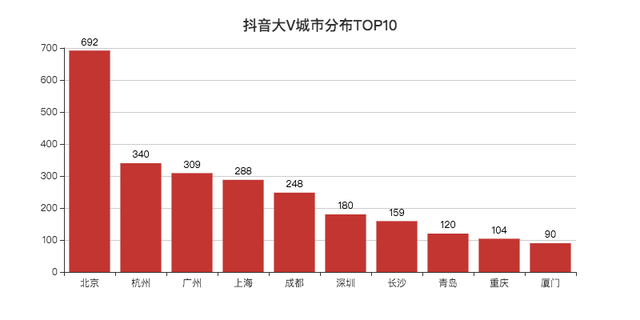
北京遙遙領先,大V的聚集地,
杭州盛產網紅的城市,位列第二,
可視化代碼如下,
1. def create_city(df):
2. df1 = df[df["country"] == "中國"]
3. df1 = df1.copy()
4. df1["city"] = df1["city"].str.replace("市", "")
5.
6. df_num = df1.groupby("city")["city"].agg(count="count").reset_index().sort_values(by="count", ascending=False)
7. df_city = df_num[:10]["city"].values.tolist()
8. df_count = df_num[:10]["count"].values.tolist()
9.
10. bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
11. bar.add_xaxis(df_city)
12. bar.add_yaxis("", df_count)
13. bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V城市分布TOP10", pos_left="center", pos_top="18"),
14. toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
15. yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
16. bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black"))
17. bar.render("抖音大V城市分布TOP10.html")
看完國內,就應該是國外了,
抖音上有著不少漢語講得非常好的「歪果仁」,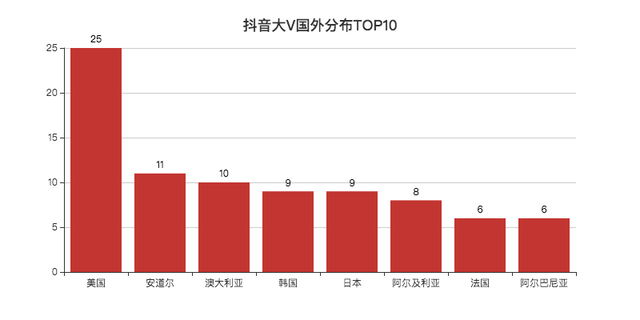
美國居第一,不少在美國的華人會分享他們在美國生活的一些事情,
國內也有人感興趣這方面的東西,看看國外的月亮究竟圓不圓,
哈哈說笑了,其實是讓我們了解國外的生活,
抖音大V畢業學校TOP10
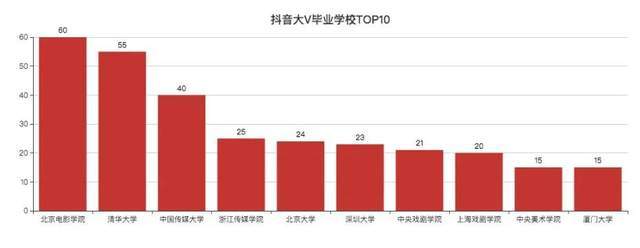
北影、中傳、浙傳、中戲、上戲、央美,妥妥的演藝圈大佬,
通過代碼查詢一下大V們的認證情況,
1. df1 = df[(df["custom_verify"] != "") & (df["custom_verify"] != "未知")]
2. df1 = df1.copy()
3. df_num = df1.groupby("custom_verify")["custom_verify"].agg(count="count").reset_index().sort_values(by="count", ascending=False)
4. print(df_num[:20])
得到結果如下,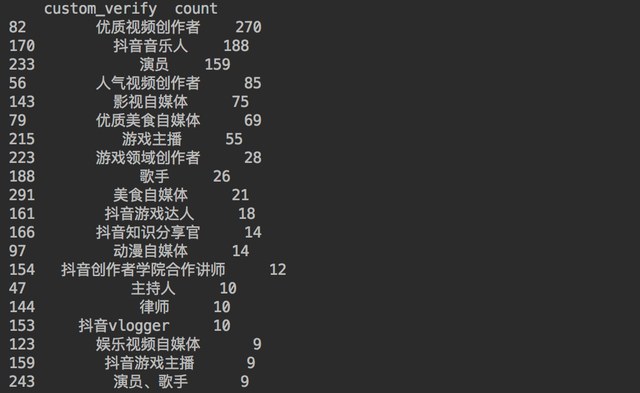
都是需要表演表達天賦的~
抖音大V簡介詞云
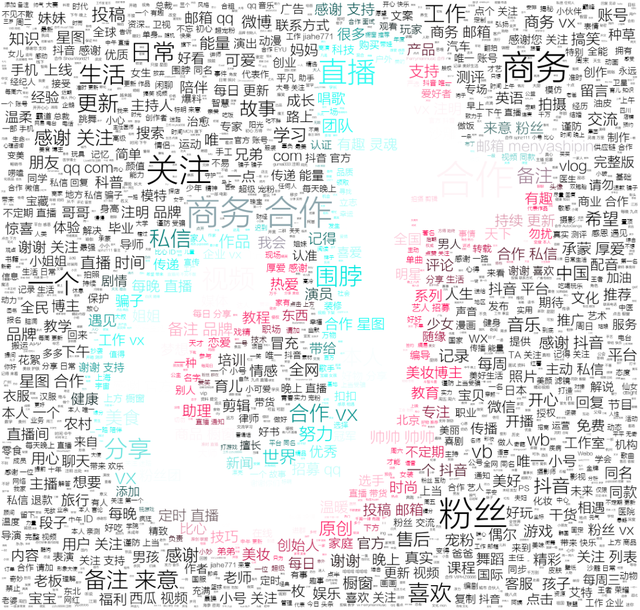
可以看到大部分大V都留下了商務合作的資訊,利好內容創作者,如此才能雙贏,
據統計,在抖音2200萬以上創作者實作了超過417億元的收入,
從創作到創益,這句話抖音講的很好,
可視化代碼如下,
1. def create_wordcloud(df, picture):
2. words = pd.read_csv('chineseStopWords.txt', encoding='gbk', sep='\t', names=['stopword'])
3. # 分詞
4. text = ''
5. df1 = df[df["signature"] != ""]
6. df1 = df1.copy()
7. for line in df1['signature']:
8. text += ' '.join(jieba.cut(str(line).replace(" ", ""), cut_all=False))
9. # 停用詞
10. stopwords = set('')
11. stopwords.update(words['stopword'])
12. backgroud_Image = plt.imread('douyin.png')
13. # 使用抖音背景色
14. alice_coloring = np.array(Image.open(r"douyin.png"))
15. image_colors = ImageColorGenerator(alice_coloring)
16. wc = WordCloud(
17. background_color='white',
18. mask=backgroud_Image,
19. font_path='方正蘭亭刊黑.TTF',
20. max_words=2000,
21. max_font_size=70,
22. min_font_size=1,
23. prefer_horizontal=1,
24. color_func=image_colors,
25. random_state=50,
26. stopwords=stopwords,
27. margin=5
28. )
29. wc.generate_from_text(text)
30. # 看看詞頻高的有哪些
31. process_word = WordCloud.process_text(wc, text)
32. sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)
33. print(sort[:50])
34. plt.imshow(wc)
35. plt.axis('off')
36. wc.to_file(picture)
37. print('生成詞云成功!')
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/256280.html
標籤:其他
上一篇:Mongo 創建索引