表
姓名 日期 金額 型別 型別1 產品
小花 2020-07-01 500 106 1818,1819
小美 2020-08-06 356 135 106 1818
小華 2020-09-08 485 208 2635,2918
小張 2020-06-01 588 146 1456,1978
小紅 2020-09-12 500 158 146 1456,1818
得出表1(當有沒有型別1時,取型別;當有型別1時,取型別1=型別的那列)
姓名 日期 金額 門號 產品
小花,小美 2020-07-01 856 106 1818,1819
小張,小紅 2020-06-01 1088 146 1456,1818,1978
小華 2020-09-08 485 208 2635,2918
uj5u.com熱心網友回復:
CREATE TABLE #T
(
姓名 VARCHAR(10),
日期 DATE,
金額 MONEY,
型別 VARCHAR(10),
型別1 VARCHAR(10),
產品 VARCHAR(20)
)
INSERT INTO #T VALUES('小花','2020-07-01',500,106 ,'', '1818,1819')
INSERT INTO #T VALUES('小美','2020-08-06',356,135 ,106 ,'1818')
INSERT INTO #T VALUES('小華','2020-09-08',485,208 ,'','2635,2918')
INSERT INTO #T VALUES('小張','2020-06-01',588,146 ,'', '1456,1978')
INSERT INTO #T VALUES('小紅','2020-09-12',500,158,146,'1456,1818')
--sql2017+
SELECT
string_agg(姓名,',') AS 姓名,
MIN(日期) AS 日期,SUM(金額) AS 金額,ISNULL(NULLIF(型別1,''),型別) AS 型別,
string_agg(產品,',') AS 產品
FROM #T
GROUP BY ISNULL(NULLIF(型別1,''),型別)
--sql2008+
;WITH ct
AS
(
SELECT 姓名,日期,金額,ISNULL(NULLIF(型別1,''),型別) AS 型別,產品 FROM #T
)
SELECT
STUFF((SELECT ','+姓名 FROM ct WHERE 型別=a.型別 FOR XML PATH('')) ,1,1,'')AS 姓名,
MIN(日期) AS 日期,SUM(金額) AS 金額,型別,
STUFF((SELECT ','+產品 FROM ct WHERE 型別=a.型別 FOR XML PATH('')) ,1,1,'')AS 產品
FROM ct a
GROUP BY 型別
DROP TABLE #T
uj5u.com熱心網友回復:
CREATE TABLE #A(
NAME VARCHAR(50),
DDATE DATE,
AMOUNT INT,
TTYPE INT,
TTYPE1 INT,
PRODUCT VARCHAR(50)
)
INSERT INTO #A VALUES ('小花','2020-07-01',500,106,NULL,'1818,1819')
INSERT INTO #A VALUES ('小美','2020-08-06',356,135,106,'1818')
INSERT INTO #A VALUES ('小華','2020-09-08',485,208,NULL,'2635,2918')
INSERT INTO #A VALUES ('小張','2020-06-01',588,146,NULL,'1456,1978')
INSERT INTO #A VALUES ('小紅','2020-09-12',500,158,146,'1456,1818')
SELECT XX.NAME,XX.DDATE,XX.AMOUNT,XX.TTYPE,
STUFF((SELECT DISTINCT ','+value FROM xxsplit(XX.PRODUCT,',') FOR XML PATH('')),1,1,'') PRODUCT FROM (
SELECT STUFF((SELECT DISTINCT ','+B.NAME FROM #A B WHERE ISNULL(A.TTYPE1,A.TTYPE)=ISNULL(B.TTYPE1,B.TTYPE) FOR XML PATH ('')),1,1,'') NAME,
MIN(A.DDATE) DDATE,SUM(A.AMOUNT) AMOUNT,ISNULL(A.TTYPE1,A.TTYPE) TTYPE,
STUFF((SELECT DISTINCT ','+B.PRODUCT FROM #A B WHERE ISNULL(A.TTYPE1,A.TTYPE)=ISNULL(B.TTYPE1,B.TTYPE) FOR XML PATH ('')),1,1,'') PRODUCT
FROM #A A GROUP BY ISNULL(A.TTYPE1,A.TTYPE))XX
DROP TABLE #A
好眼熟的問題
create function xxsplit(@sql varchar(MAX),@xx varchar(20))
returns @temp table(value varchar(20))
as
begin
declare @i int
set @i=charindex(@xx,@sql)
while @i>=1
begin
insert @temp values(left(@sql,@i-1))
set @sql=substring(@sql,@i+1,len(@sql)-@i)
set @i=charindex(@xx,@sql)
end
insert into @temp values(@sql)
return
end
uj5u.com熱心網友回復:
對不起,我沒有表達準確,不一定是最小日期,如果有型別1應該取型別的日期uj5u.com熱心網友回復:
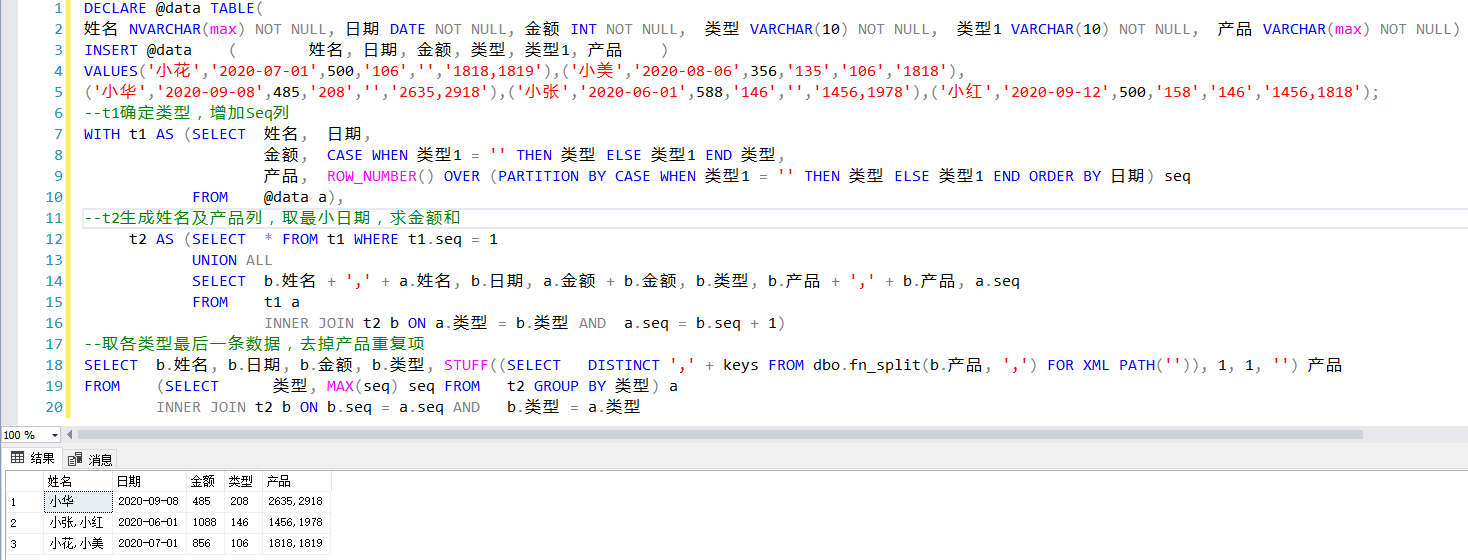
DECLARE @data TABLE(
姓名 NVARCHAR(max) NOT NULL, 日期 DATE NOT NULL, 金額 INT NOT NULL, 型別 VARCHAR(10) NOT NULL, 型別1 VARCHAR(10) NOT NULL, 產品 VARCHAR(max) NOT NULL)
INSERT @data ( 姓名, 日期, 金額, 型別, 型別1, 產品 )
VALUES('小花','2020-07-01',500,'106','','1818,1819'),('小美','2020-08-06',356,'135','106','1818'),
('小華','2020-09-08',485,'208','','2635,2918'),('小張','2020-06-01',588,'146','','1456,1978'),('小紅','2020-09-12',500,'158','146','1456,1818');
--t1確定型別,增加Seq列
WITH t1 AS (SELECT 姓名, 日期,
金額, CASE WHEN 型別1 = '' THEN 型別 ELSE 型別1 END 型別,
產品, ROW_NUMBER() OVER (PARTITION BY CASE WHEN 型別1 = '' THEN 型別 ELSE 型別1 END ORDER BY 日期) seq
FROM @data a),
--t2生成姓名及產品列,取最小日期,求金額和
t2 AS (SELECT * FROM t1 WHERE t1.seq = 1
UNION ALL
SELECT b.姓名 + ',' + a.姓名, b.日期, a.金額 + b.金額, b.型別, b.產品 + ',' + b.產品, a.seq
FROM t1 a
INNER JOIN t2 b ON a.型別 = b.型別 AND a.seq = b.seq + 1)
--取各型別最后一條資料,去掉產品重復項
SELECT b.姓名, b.日期, b.金額, b.型別, STUFF((SELECT DISTINCT ',' + keys FROM dbo.fn_split(b.產品, ',') FOR XML PATH('')), 1, 1, '') 產品
FROM (SELECT 型別, MAX(seq) seq FROM t2 GROUP BY 型別) a
INNER JOIN t2 b ON b.seq = a.seq AND b.型別 = a.型別
拆分函式可參考#2的
uj5u.com熱心網友回復:
如果有兩個型別1呢?如有沒有型別1有兩個型別呢?
uj5u.com熱心網友回復:
WITH CTE
AS
(SELECT A.*,SUBSTRING(A.ITEM,B.NUMBER,CHARINDEX(',',A.ITEM+',',B.NUMBER)-1) AS SINGLE_ITEM,
CASE WHEN ISNULL(A.TYPE1,'')='' THEN DT ELSE '' END AS DT_NEW,
ISNULL(NULLIF(A.TYPE1,''),A.TYPE) AS TYPE_NEW,
CASE WHEN B.NUMBER=1 THEN AMOUNT ELSE 0 END AS AMOUNT_NEW
FROM #T A
JOIN MASTER.DBO.SPT_VALUES B ON CHARINDEX(',',','+A.ITEM,B.NUMBER)=B.NUMBER
WHERE B.TYPE='P')
SELECT STUFF((SELECT DISTINCT ','+NAME FROM CTE WHERE A.TYPE_NEW=TYPE_NEW FOR XML PATH('')),1,1,'') AS NAME_LIST,
MAX(DT_NEW) AS DT,
SUM(AMOUNT_NEW) AS TOTAL,
TYPE_NEW,
STUFF((SELECT DISTINCT ','+SINGLE_ITEM FROM CTE WHERE A.TYPE_NEW=TYPE_NEW ORDER BY ','+SINGLE_ITEM FOR XML PATH('')),1,1,'') AS ITME_LIST
FROM CTE AS A
GROUP BY TYPE_NEW
uj5u.com熱心網友回復: