首先祝大家新年快樂,身體健康,萬事如意,
一般來說一個系統最先出現瓶頸的點很可能是資料庫,比如我們的生產系統并發量很高在跑一段時間后,資料庫中某些表的資料量會越來越大,海量的資料會嚴重影響資料庫的讀寫性能,
這個時候我們會開始優化系統,一般會經過這么幾個程序:
- 找出SQL慢查詢,針對該SQL進行優化,比如改進SQL的寫法,查看執行計劃對全表掃描的欄位建立索引
- 引入快取,把一部分讀壓力加載到記憶體中
- 讀寫分離
- 引入佇列,把并發的請求使其串行化,來減輕系統瞬時壓力
- 分表/分庫
對于第五點優化方案我們來細說一下,分表分庫通常有兩種拆分維度:1.垂直切分,垂直切分往往跟業務有強相關關系,比如把某個表的某些不常用的欄位遷移出去,比如訂單的明細資料可以獨立成一張表,需要使用的時候才讀取 2.水平切分,比如按年份來拆分,把資料庫按年或者按某些規則按時間段分成多個表,
拆分表之后每個表的資料量將會變小,帶來的好處是不言而喻的,不管是全表掃描,還是索引查詢都會有比較高的提升,如果把不同的表檔案落在多個磁盤上那資料庫的IO性能還能進一步提高,
如果純手工拆分,比如按年份拆分成多個表,那么上層業務代碼也得進行調整,每次讀寫都得判斷該使用哪張表,如果是跨多個年份的分頁查詢更加難搞,人肉分表基本上不可能實作的,對于上層編碼簡直是個噩夢,所以針對分表分庫我們通常會使用某些中間件,比如Mycat,Sharding-JDBC等中間件,使用這些組件確實能實作分表分庫,并且對業務層代碼屏蔽了資料庫架構的改動,但是配置略顯麻煩,如果你使用的是SQL Server資料庫,并且目前還不需要分庫,只需要分表,那么其實使用內置的磁區表功能是最簡單的方案,只需要打開SQL Server Management Studio簡單設定幾下就可以了,對于你上層應用完全是無感的,你的代碼、資料庫連接串都不需要改動,
以下我們通過2個簡單的測驗,來簡單的演示下如何進行表磁區操作,以及測驗下磁區前后性能變化,
測驗寫性能
我們的測驗方案:新建一張logs表,按年份寫入資料,2019年寫入1000000資料,2020年也寫入100000資料,為了加快寫入的速度,每個年份并行10個執行緒同時寫,每個執行緒寫100000資料,一共1000000資料,然后把logs表改成磁區表再用同樣的方式寫入2000000資料,記錄耗時 比較兩次的耗時,
硬體為一臺14年產的筆記本,OS為win10,掛載2塊硬碟,1塊為5400轉的機械硬碟,1塊為15年加的SSD,磁盤性能可以說極為垃圾,未磁區時表檔案會落在機械硬碟上,
未磁區情況下測驗
使用腳本建表:
CREATE TABLE [dbo].[logs](
[id] [uniqueidentifier] NOT NULL,
[log_txt] [varchar](200) NULL,
[log_time] [datetime] NULL,
CONSTRAINT [PK_logs] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
)
新建一個控制臺程式撰寫代碼:
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!");
Task.Run(() =>
{
InsertData(2019);
});
Task.Run(() =>
{
InsertData(2020);
});
Console.ReadLine();
}
static void InsertData(int year)
{
var tasks = new List<Task>();
Stopwatch sw = new Stopwatch();
sw.Start();
for (int i = 0; i < 10; i++)
{
tasks.Add(Task.Run(()=> {
using (var conn = new SqlConnection())
{
conn.ConnectionString = "Persist Security Info = False; User ID =sa; Password =dev@123; Initial Catalog =fq_test; Server =.\\mssql2016";
conn.Open();
int index = 0;
for (int j = 0; j < 100000; j++)
{
var logtime = new DateTime(year, new Random().Next(1, 12), new Random().Next(1, 28));
conn.Execute("insert into logs2 values (newid(),'下訂單',@logtime)", new
{
logtime
});
Console.WriteLine("logtime:{0} index {1}", logtime, index++);
}
}
}));
}
Task.WaitAll(tasks.ToArray());
sw.Stop();
Console.WriteLine("Year {0} complete , total time: {1}.", year, sw.ElapsedMilliseconds);
}
}
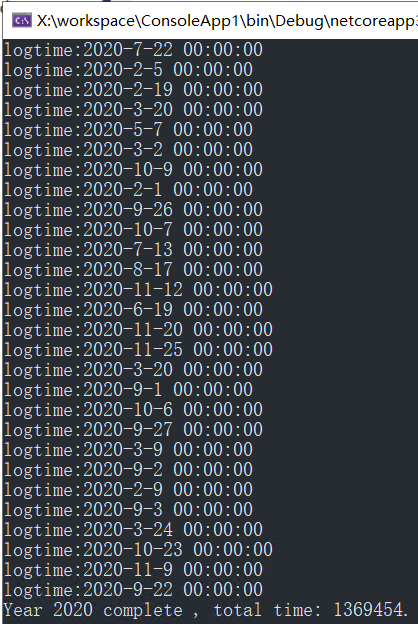
寫完2000000資料耗時1369454毫秒,
磁區情況下進行測驗
開始磁區
把一個表設定為磁區表大概有5個步驟:
- 添加檔案組
- 在檔案組添加檔案
- 新建磁區函式
- 新建磁區方案
- 開始磁區
以下演示下如何使用SQL SERVER Management Studio管理器進行表磁區:
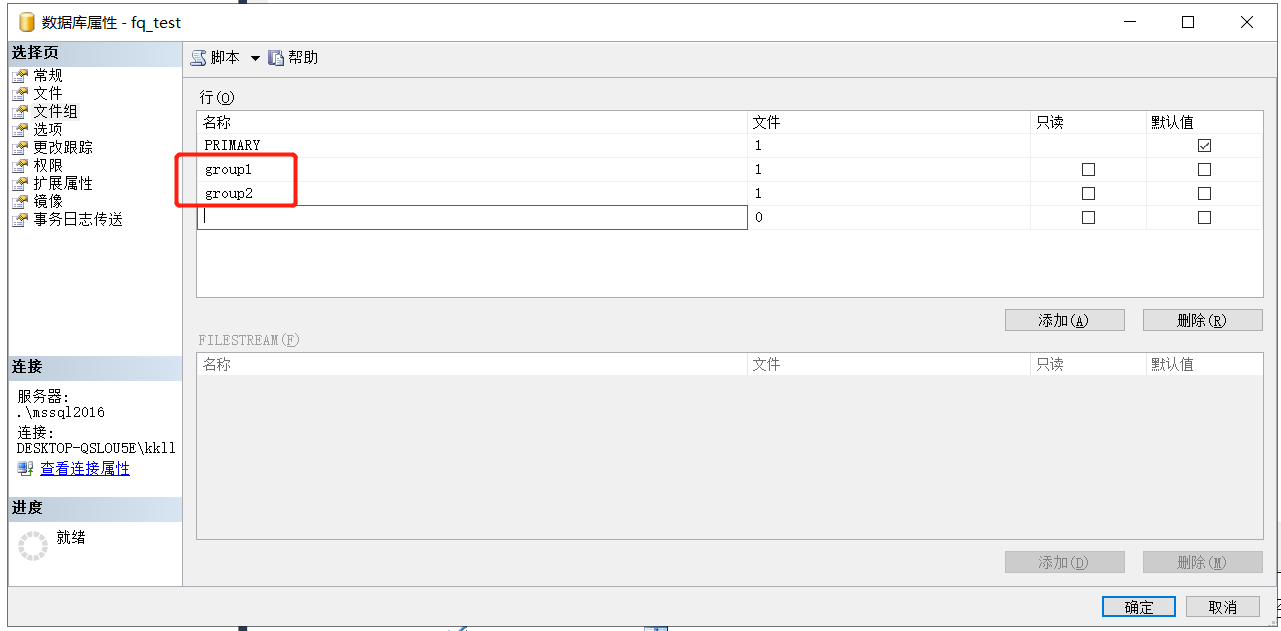
選中資料庫=>屬性=>檔案組,添加group1,group2兩個檔案組,
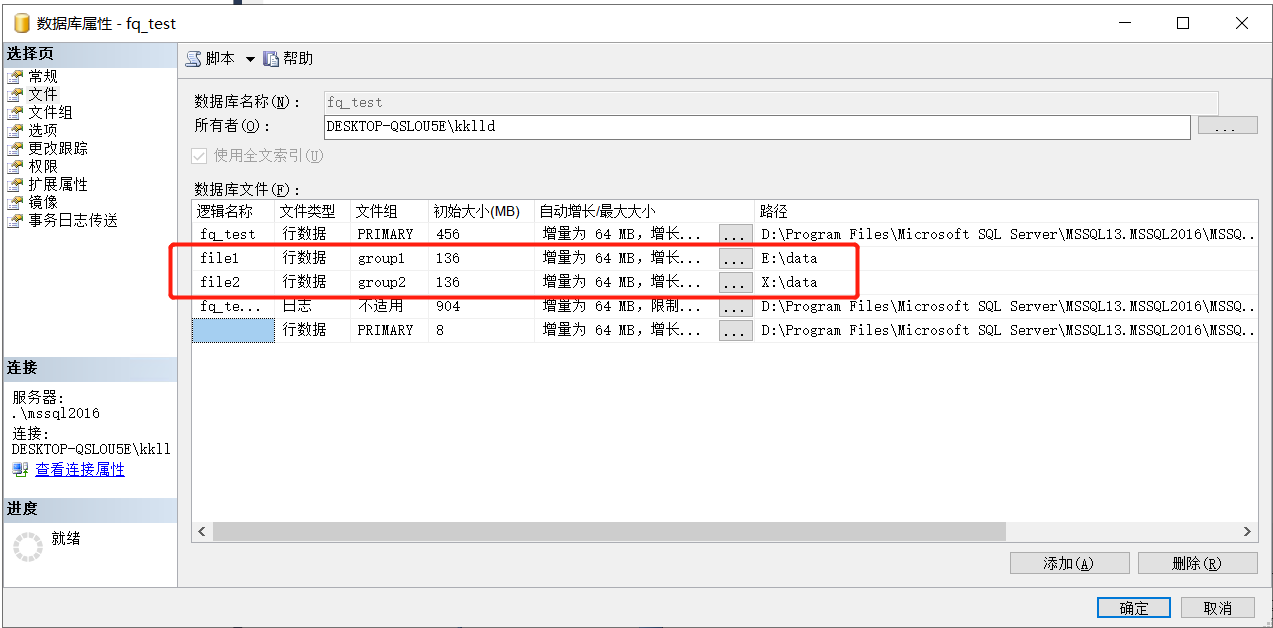
選中資料庫=>屬性=>檔案,添加file1,檔案組選group1,路徑選擇一個檔案目錄,這里選擇E盤data目錄,添加file2,檔案組選擇group2,路徑選擇一個檔案目錄,這里選擇X盤的data目錄,這樣當磁區的時候資料就會落在這2個目錄下,這里的路徑可以選擇在同一個硬碟,但是為了更高的讀寫性能,如果有條件建議直接指定在不同的硬碟下,
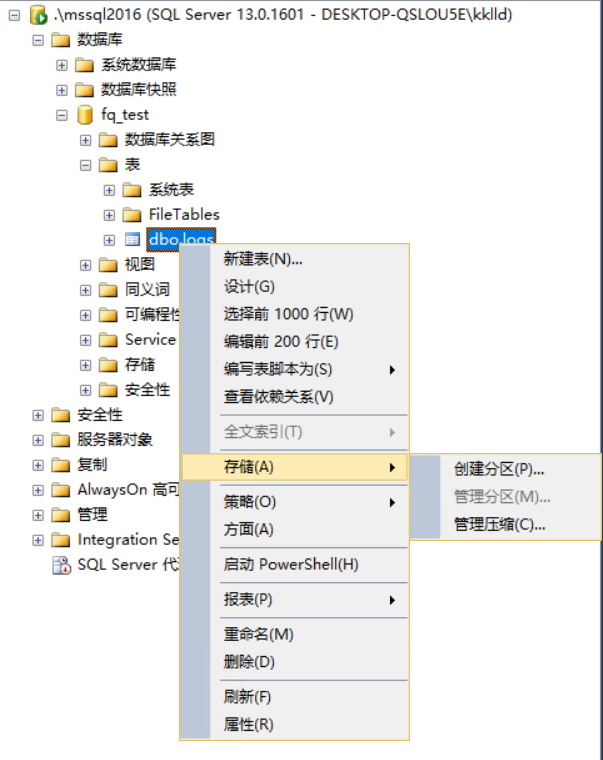
選中logs表=>存盤=>創建磁區,啟動磁區向導工具,
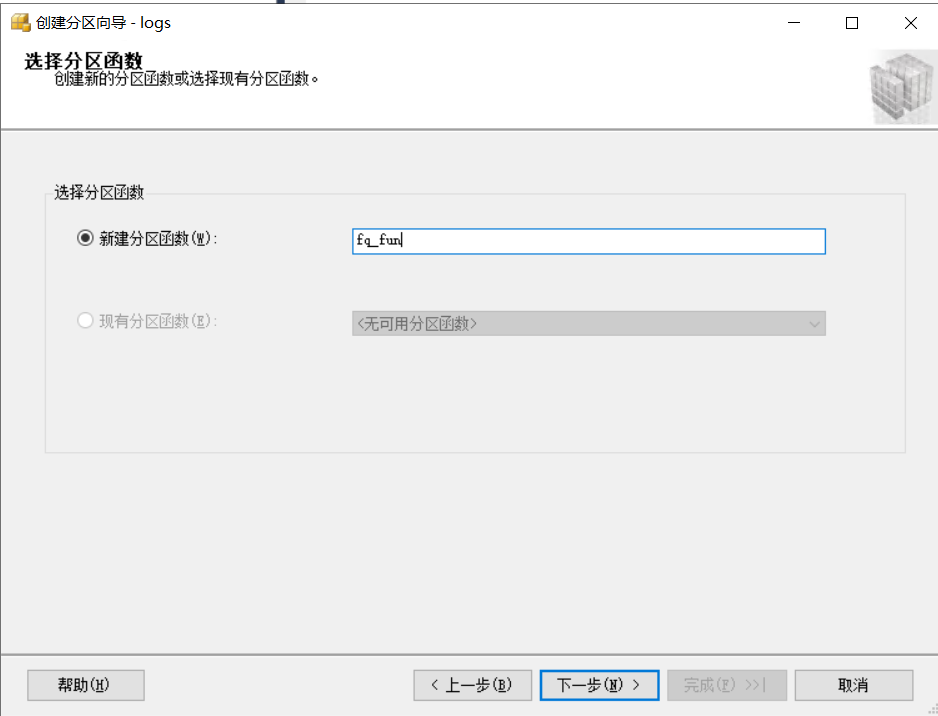
新建一個磁區函式,點擊下一步,
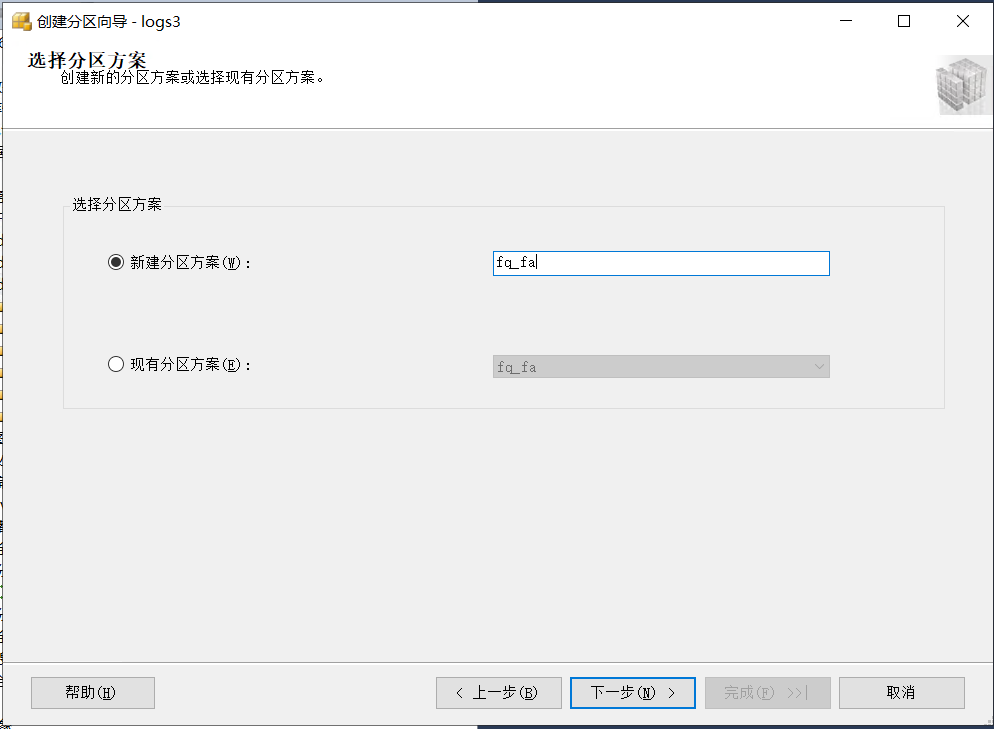
新建一個磁區方案,點擊下一步,
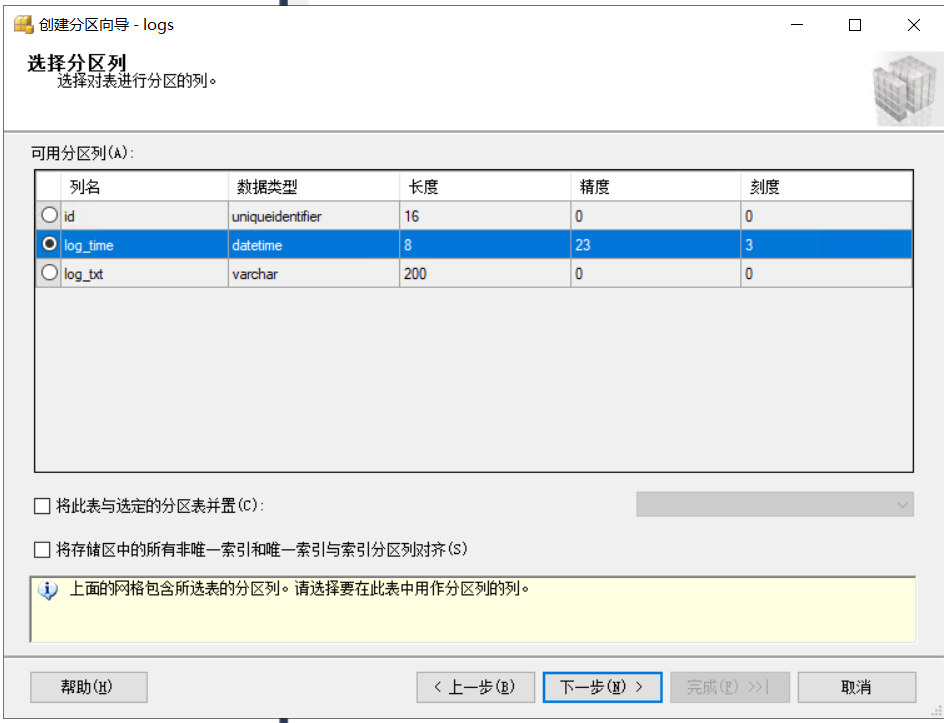
選擇一個磁區列,資料會根據該列進行水平拆分,這里選擇logtime,因為時間是比較適合水平切分的一個維度,
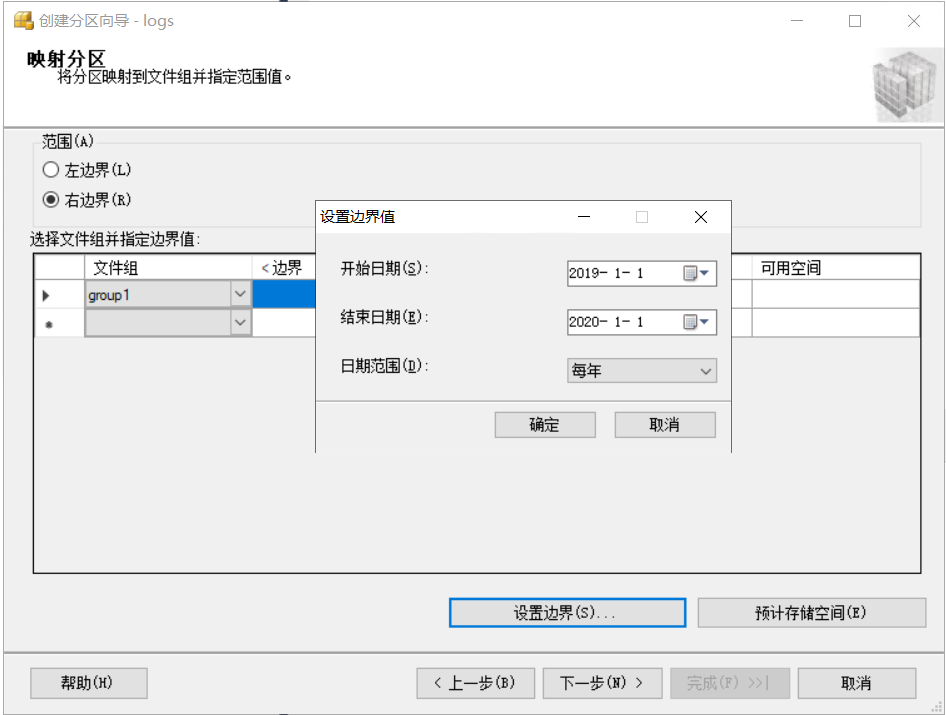
值得資料拆分的范圍,范圍選擇“右邊界”,右邊界跟左邊界的差異在于對邊界值的處理,右邊界是<,左邊界是<=,也就是包含邊界值,
我們這里設定group1存盤2019的資料,group2存盤2020的資料,所以group1的邊界值設定為2020-01-01,group2的邊界值設定為2021-01-01 ,
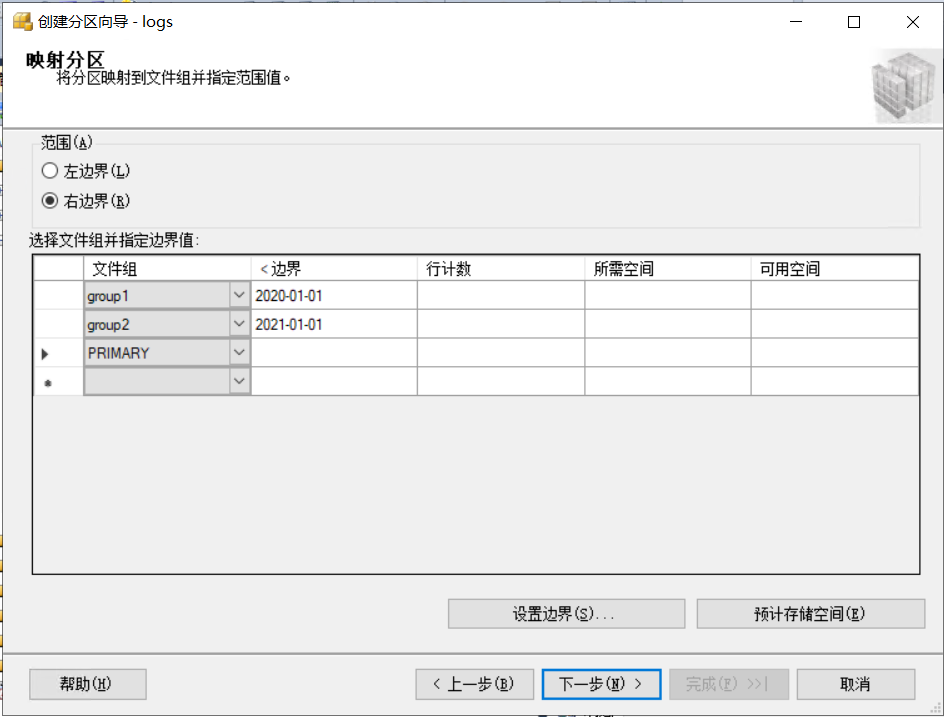
設定完是這個樣子,需要3個檔案組,當出現不在group1,group2范圍內的資料就會存盤在第三個檔案組內,
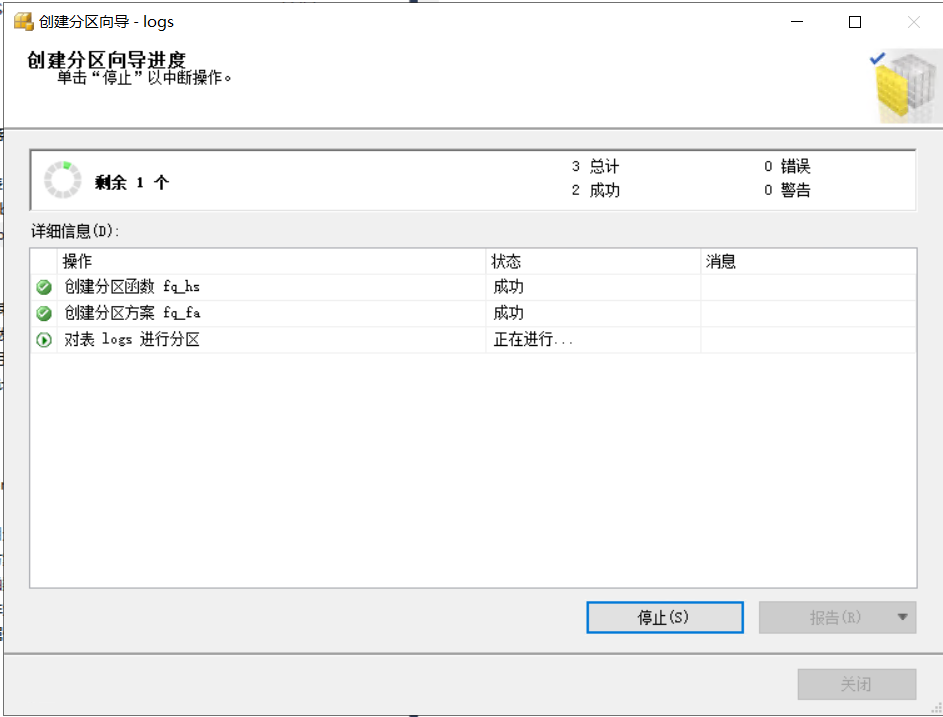
建好磁區函式、磁區方案后,可以選擇生成腳本或者立即執行,這里選擇“立即執行”,當執行完成后,表里的資料會按照磁區方案設定的邊界分散到多個檔案上,
在磁區情況下進行測驗
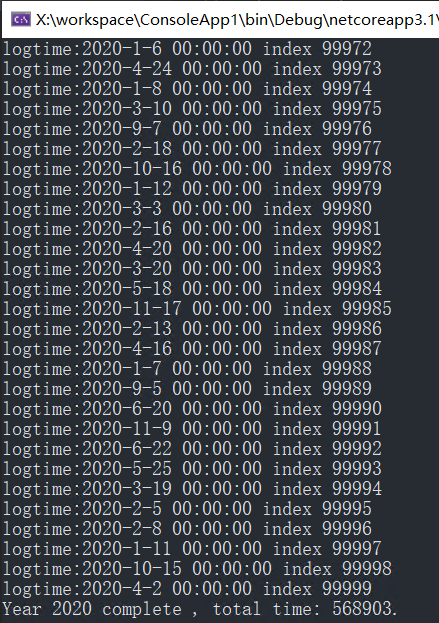
先清空logs表所有的資料,然后使用同樣的代碼進行測驗,測驗結果顯示寫完2000000資料耗時:568903毫秒,可以看到資料庫寫性能大副提高,大概提高了1倍不止的性能,這也比較符合兩塊磁盤同時IO的預期,
測驗讀性能
我們的測驗方案:新建一張log2表,使用上面的代碼按年份寫入2000000資料,然后使用select陳述句同時讀取2019,2020年的資料,把log表轉換成磁區表,重新測驗select的時間,比較兩次讀取資料的時間,
sql陳述句:
select * from log2 where (logtime > '2019-05-01' and logtime < '2019-06-01') or (logtime > '2020-05-01' and logtime < '2020-06-01')
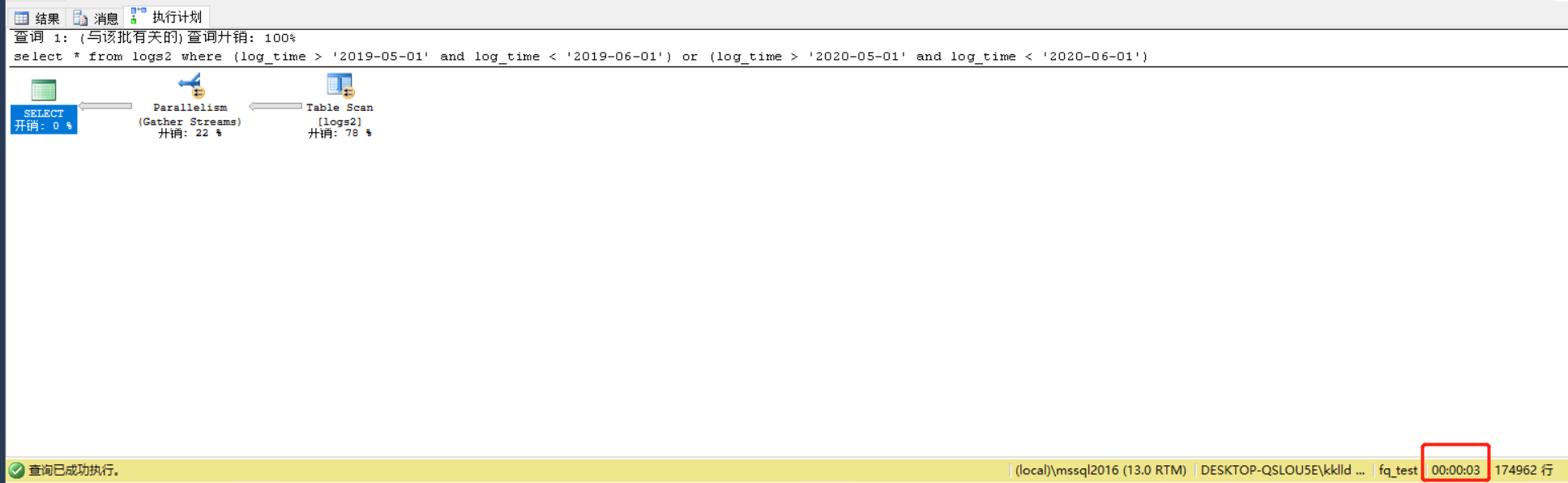
首先在未磁區的表上測驗查詢性能,花費時間為3s,
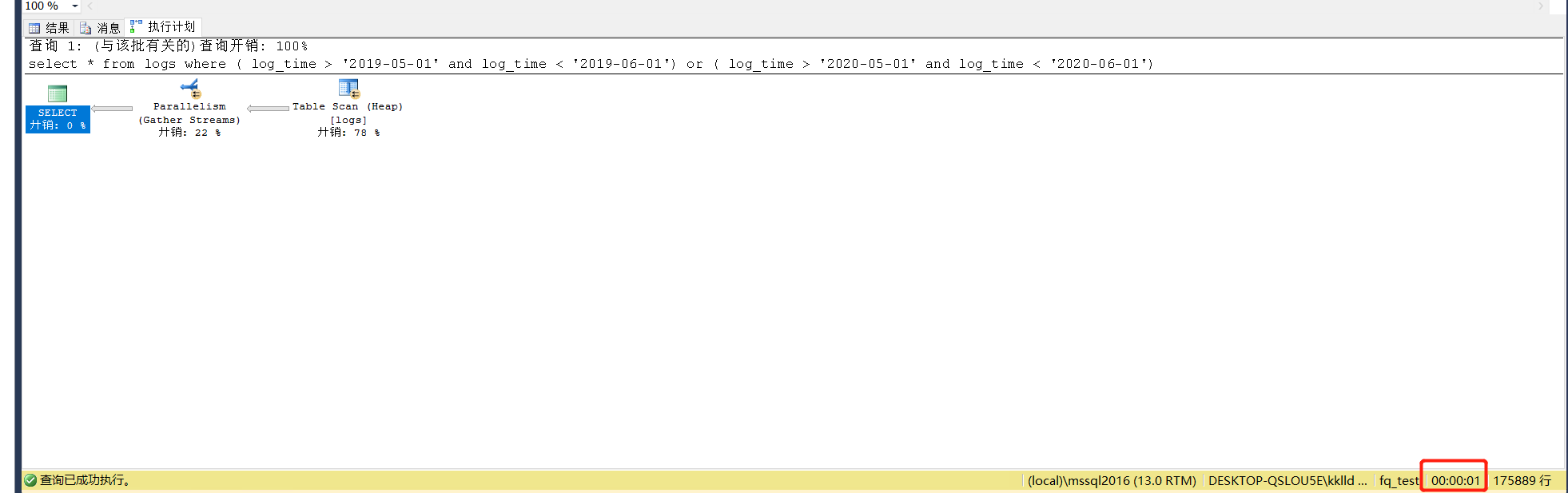
把表按前面的方法進行磁區拆分,查詢花費時間為1s,讀性能大概為未磁區時的3倍,
總結
經過簡單的測驗,SQL Server的磁區表功能能大副提高資料庫的讀寫性能,通過SQL Server Management Stduio的簡單設定就可以對資料庫表進行磁區操作,并且對應用層的代碼完全是無感的,比用分表分庫中間件來說簡單多了,
關注我的公眾號一起玩轉技術

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/260943.html
標籤:SQL Server