分布式系統主要包含的內容很多,我就針對兩個核心方面做一下解讀:分布式應用服務和物件遠程呼叫、資料的分布式存盤,先說說分布式應用服務以及物件遠程呼叫的元老之一:
EJB/RMI(Enterprise Java Beans/Remote Method Invocation)吧!
分布式應用和物件遠程呼叫
那個時候的Java工程師,對于EJB的大名如雷貫耳,曾經EJB VS Spring大戰(Spring With Not EJB)讓程式員們的論戰激情興奮,其實爭論的主題就是需不需要組件間實作分布式呼叫,并在分布式網路環境保持住組件狀態,到底什么是分布式環境的組件狀態呢?所謂分布式服務組件的無狀態 VS 有狀態
簡單點說,有狀態就是后端服務組件讓遠程呼叫程序看起來更像本地化呼叫,客戶端不用考慮過多組件狀態hold的問題,這樣更容易設計出純粹的面向物件化組件,而無狀態反過來,后端服務組件專注于接收客戶端請求并處理問題,給予客戶端回應就夠了,不要hold住狀態徒增煩惱,狀態保持的事情讓客戶端自己解決,
例如:購物車就是個例子,無狀態的購物車,服務組件是讓客戶端通過cookie解決購物清單問題;有狀態的購物,組件服務是自己保持住購物清單狀態,那么客戶端和服務端的物件看起來責任更清晰,

Rod Jonhson(Spring之父)就是用這本書掀起了當年的Spring的奪位之戰,
大戰最終的結局大家已經很清楚了——Spring逆襲完勝,EJB從此淡出江湖,無狀態呼叫模式成為了主流,當然EJB本身的問題也不少,雖然之后EJB3標準由Hibernate作者重新操刀設計,也是為時已晚,曾經我也是EJB力挺者之一,也跟著EJB一起淡出江湖了!_"
其實這種勝出,本質上是分布式系統架構向單態架構的認慫,JavaEE的頭牌EJB(企業級JavaBean)在當時代表著一種超前的設計,這種設計架構也算是當前流行的微服務架構的前浪吧,只是被拍死在了沙灘上,我們看看當時EJB VS Spring 架構:
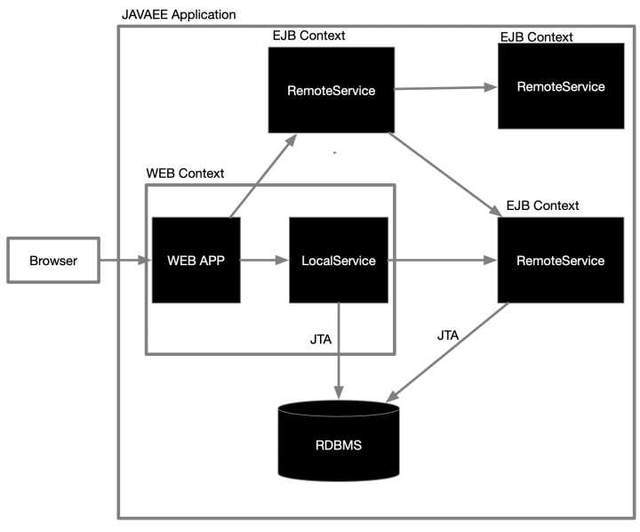
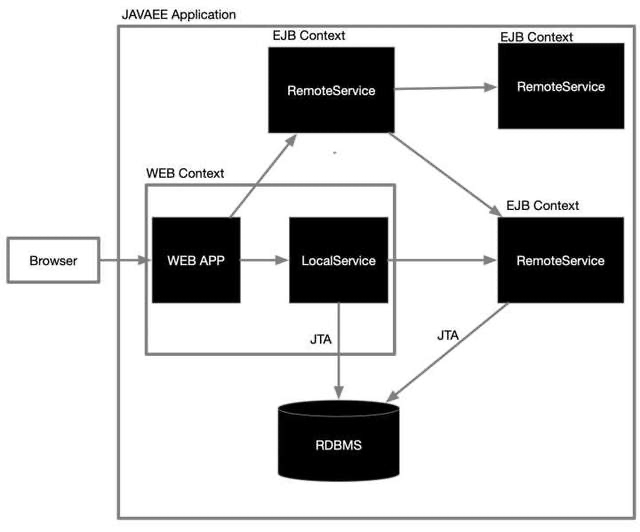
上面的圖是JavaEE的組件服務通訊圖,有獨立部署的遠程Remote EJB容器,也有和WEB一起部署的本地Local EJB容器,它們作為組件互相之間通信(RMI),既可以WEB應用訪問EJB,也可以EJB訪問EJB,通過JTA(JAVA事務介面)統一管理資料庫的事務操作,實作真正的分布式事務,像不像現在的微服務,像不像現在的常用的RPC呼叫,作為分布式系統架構,難道它不標準嗎,難道這個架構它不美嗎!!!
我們再看看Spring早期逆襲的架構:
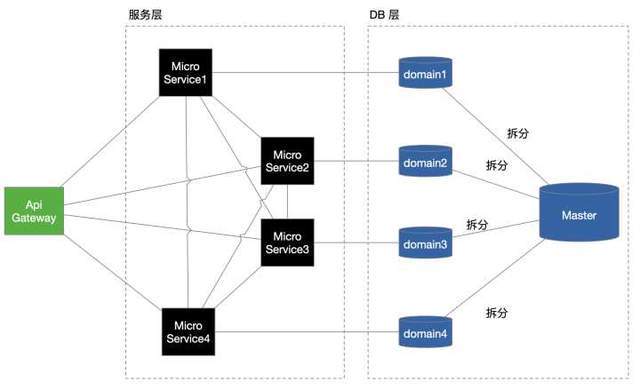
上圖是Spring的SSH架構圖,典型的單實體架構,通過一個AOP切面攔截技術,對程式員代碼層面的實作了事務呼叫的隱藏和透明化,讓開發專注于自身的服務,這就很有親和力,架構看起來是不是很簡單,
對了,就是用這種簡單的架構打敗了看起來很美但復雜的架構,所以你問我,分布式系統的優點是什么?它很美,通過網路服務的組件化,實作更純粹的面向物件模型,給程式員一個統一的編程模式來應對分布式服務在網路上的復雜性,
那分布式系統的缺點又是什么呢?
頭號缺點,部署復雜,就憑這點,就極不利于測驗,嚴重影響敏捷,這個真的不是單EJB部署復雜,只要是分布式應系統,就一定部署復雜,我們可以想想目前的微服務,再輕量化設計,依然逃不開部署復雜的問題,雖然生產環境部署分開發布也有好處,但是90%的部署都發生在開發階段,那么頻繁的測驗、開發除錯和重新啟動部署,對于個體程式員來講,就是比單實體服務要更加是個沉重負擔,
第二個缺點就是將原來集中在資料庫的SQL訪問模式轉變成了網路服務之間的介面呼叫,無論是EJB也好,微服務也好,這種分布式系統的呼叫模式本質都是反人性的,因為人都喜歡集中在一個中心去解決問題,形式簡單,出現變化更容易定位和適應,分散不同地方的服務,無論從服務編排也好,介面變更也好,錯誤跟蹤也好,讓人去處理都太費勁了,
因此Spring的單體服務就是憑借著部署簡單、適應敏捷、人性化等特質,打敗了EJB,分布式系統第一次完敗,但是為什么最終依然演化出了微服務架構呢?而且熱度不減當年,其實我認為就是曾經EJB熱度的又一次輪回,SpringCloud也開始了當年EJB之路,微服務在架構拆解之路上,甚至開始了資料庫和微服務打包獨立的情況,下面是微服務的架構模樣:
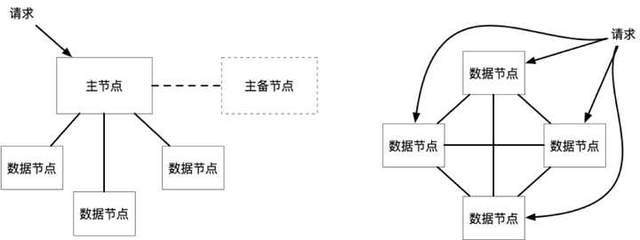
上圖是API網關進行多個微服務的調度,微服務之間互相調度,每個微服務擁有自己的獨立資料庫,都是從一個傳統Master單庫切分而來,Master庫也逐漸成為資料中心庫,提供基礎資料交換和資料分析(OLAP)
我們看看微服務的架構和上面的EJB分布式架構多么的像,其實都是一個血脈遺傳下來的,那就是分布式系統,但是微服務演化到拆庫就真的好嗎?我不敢茍同,咱們可以把資料庫的不同資料表比喻成一個家庭的多個成員,難道把家庭成員強行拆開就一定好嗎?家里原來公用一臺電視機,現在拆分一個成員,就要配一臺電視,難道看電視還要跑回來看嗎?這就是類比了資料欄位到底是冗余,還是走介面呼叫?這個會讓設計者太痛苦的,本質是反人性的,
為什么非要這樣做呢?說到底就是想讓關系型資料庫實作垂直切分,形成更好的性能水平提升,也就是說,問題根子出在關系型資料庫身上了,關系型資料庫天然就不支持分布式化,無法更好的實作資料庫級的水平伸縮,所以將來一定是分布式資料存盤系統替代關系型資料庫的時代,因為我們如果有了一個廉價且性能強大的資料庫系統,通過水平伸縮解決性能問題,我們又何必費勁的搞業務資料的垂直切分呢!這就是下來說分布式存盤的關鍵作用,
分布式資料存盤
資料的分布式存盤具體表現形式也就是分布式資料庫,分布式資料庫不同于分布式應用服務,不存在開發測驗階段費勁的發布重啟,所以并不影響敏捷性;另外資料呼叫都集中在一個訪問代理上,因此不需要像分布式應用服務那么反人性的考慮介面管理,分布式資料庫的水平伸縮力,恰恰解決了微服務必須分庫的尷尬問題,可以讓程式員專注于資料訪問的業務問題上,既然這么多好處,為什么不能大規模應用呢?問題的根源就出在事務上了!
為什么關系型資料庫就具備ACID的事務的優勢呢?先簡單點說說事務的原理,事務就是對資料的加鎖解鎖,給資料行集加鎖,我(事務)要處理一行資料,我(事務)就申請一把鑰匙,給資料行上個鎖,其他人(事務)等著我解鎖了,其他人才能訪問,這個操作放到以單機設計為主的關系型資料庫上好解決,但是放到如今的分布式資料庫環境,這就特別麻煩了,因為資料被分成片,分布在不同的機器節點庫中,事務加鎖就要定位到所有相關的節點,事務問題就淋漓盡致地體現出了分布式系統在網路環境中多節點協作的復雜性,協作越緊密的事情,分布式系統干起來越吃力,為什么Key/Value資料庫,例如Redis用起來最舒服,也很流行,就是資料相互之間沒什么協作關系,
分布式資料庫事務這個夠嗆的問題,也沒有難住偉大的計算機科學家們,例如:TIDB繼承自Google Percolator,使用 Percolator 事務模型,實作了分布式事務,也就是現在又出現的一個新名詞:NewSQL,傳統關系型資料庫ACID特性+NoSQL,
我們先說說分布式資料庫的關鍵是什么?就是對一大塊資料進行分片(分塊/磁區),平平整整地放到不同的物理節點上,保持每個節點的資料量差不多是最佳的,這樣吞吐性能最好,若節點有的多,有的少,這就是出現傾斜了,那么資料多的節點就會承載更大的資料訪問壓力,
不同的資料節點有管理者進行管理,有的管理者是集中式任命的,例如HDFS的namenode,有的管理者是被推舉的,例如Elasticsearch master node,總之分布式資料庫就有管理節點負責調度資料節點,也有資料節點服務資料讀寫,就是這么一回事兒,
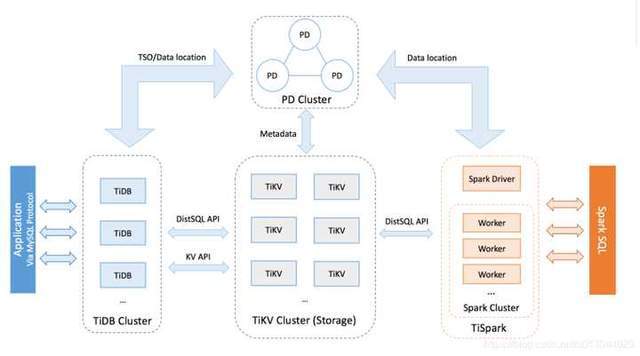
上圖就是兩種不同的資料管理方式,第一個是主從模型,例如HDFS的分塊,由namenode統一負責資料塊節點的分配調度;第二個是對等模型,例如GlusterFS,也就是每個節點即是主又是從,關鍵看自己節點的資料是否匹配請求,
我們再看看分布式事務的架構有多么復雜,就看看TIDB的架構吧!
上圖是TIDB作為一個整體存在,作為玩分布式資料庫的專家看了這個架構都會頭大,
TIDB作為面向客戶端的SQL請求和邏輯處理者,PD是集群的管理者,TiKV又通過key/value的形式持久化資料,TIDB、PD、TiKV,各自又是分布式集群,那么事務的發起、資料路由由PD負責,SQL的接收、事務程序的控制由TiDB負責,資料的落地由TiKV負責,通過這么一個責任分工明確的體系,就形成了真正的分布式事務,
其優點就是事務加鎖終于去中心化了,到達了分布式資料庫技術航行最遠的地方了,這可是谷歌的Percolator論文在2011年就發表了,谷歌真的是神族所在地,
可付出的代價依然不小,第一個很明顯,物理機器少不了,但是能到了這份上的業務也不在乎這么多資源了,第二就是TiDB的事務程序控制是在記憶體中進行的,等事務一致性同步好了,才會進入TiKV持久化,因此記憶體的消耗一定不得了,遇到延時類bug,記憶體就有可能因為資料洪水決堤,最后的問題還是網路互動太頻繁了,保障一個良好的網路環境極為重要,
好,就聊這么多吧,希望本文的一些淺見使我們對分布式系統有一些更深刻的理解,一句話:分布式系統太復雜了,你很難去控制它,需要的是深入去理解它,

我們是“讀位元組”技術專家團隊,感謝您的關注! 讀位元組官網
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/265087.html
標籤:大數據
下一篇:ClickHouse原始碼筆記4:FilterBlockInputStream, 探尋where,having的實作