一、同期群分析概念和理論
1 同期群分析方法介紹
??同期群分析(CohortAnalysis)實際上是一種用戶分群的細分型別,是一種“縱橫”結合的分析方法:
- 橫向上——分析同期群隨著周期推移而發生的變化;
- 縱向上——分析在生命周期相同階段的群組之間的差異,
??“同期群”:同一時期的群體,可以是“同一天注冊的用戶”、同一天第一次發生付費行為的用戶等等,“周期的指標變化”:用戶在一定周期內的留存率、付費率等等,同期群分析包含三個核心的元素:
- 客戶首次行為時間:這是劃分同期群體的基點;
- 時間周期維度:比如N日留存率、N日轉化率中的N日,一般即為+N日、+N月等
- 變化的指標:比如注冊轉化率、付款轉化率、留存率等等,
2 同期群分析的意義
??為啥要做同期群分析,不分群不行嗎?同期群分析,給到更加細致的衡量指標,幫助我們實時監控真實的用戶行為、衡量用戶價值,并為營銷方案的優化和改進提供支撐,避免“被平均”的虛榮資料,
二、SQL實作同期群分析
Excel資料源部分資料截圖:
1 python讀取Excel資料匯入MySQL
import pymysql
import xlrd
from datetime import datetime
# 1、讀取本地Excel資料集
book = xlrd.open_workbook('同期群.xlsx')
sheet = book.sheet_by_name('1-資料源')
print("資料行數:",sheet.nrows,'---',"資料列數:",sheet.ncols)
# 2、連接資料庫,創建游標、創建插入陳述句
db = pymysql.connect(host='localhost',user='root',password='123456',port=3306,db='同期群')
cursor = db.cursor()
sql = f"INSERT INTO tongqiqun (nick_name,pay_time,order_status,pay_amount,purchase_quantity,province) VALUES (%s,%s,%s,%s,%s,%s)"
# 3、插入函式
def insert_info():
# 回圈每行資料,跳過標題行,從第二行開始
for r in range(1, 5):
nick_name = sheet.cell(r,0).value # 用戶昵稱
# 支付時間處理
# pay_time = sheet.cell(r,1).value ->直接讀取會報錯,Excel的日期資料讀出來是double
# print(sheet.cell(1,1).value) ->43709.00699074074
try:
pay_time = xlrd.xldate_as_tuple(sheet.cell(r,1).value,0) # 轉換成元組
pay_time = datetime(*pay_time) # *args 任意位置引數傳參
except:
pay_time = None
order_status = sheet.cell(r,2).value # 訂單狀態
pay_amount = sheet.cell(r,3).value # 支付金額
# print(sheet.cell(1,4).value) ->1.0
purchase_quantity = int(sheet.cell(r,4).value) # 購買數量
province = sheet.cell(r,5).value # 省份
# 組裝元組格式資料,執行SQL插入腳本
data = https://www.cnblogs.com/xiaoshun-mjj/p/(nick_name,pay_time,order_status,pay_amount,purchase_quantity,province)
# print(data)
cursor.execute(sql,data)
insert_info()
??用了python的xlrd操作Excel檔案,pymysql庫連接MySQL資料庫,用xlrd讀取Excel資料時,會出現一些格式上的問題,比如,在Excel中的日期資料是以數值型存盤的,所以需要做一下處理才能匯入MySQL資料庫,不太建議用python來讀取Excel資料進行入庫操作,可以用Navicat可視化工具匯入更方便,匯入datatime型別資料時,先以varchar型別匯入,匯入完成后,執行SQL陳述句:
ALTER TABLE tongqiqun CHANGE pay_time create_date DATETIME;
即可,
2 資料清洗
??訂單狀態為“交易失敗”的行,付款時間是缺失的,
-- 篩選訂單狀態為:‘交易成功’的行,接下來分析只用到這兩個欄位:nick_name、pay_time
CREATE TABLE order_sheet1 AS
SELECT
nick_name,
pay_time
FROM tongqiqun
WHERE order_status = '交易成功';
2 計算留存量
(1)對用戶進行分組,用min()函式計算日期最小值
-- 1、每個用戶首單日期
SELECT
nick_name,
min(pay_time) as fir_time
FROM order_sheet1
GROUP BY nick_name;
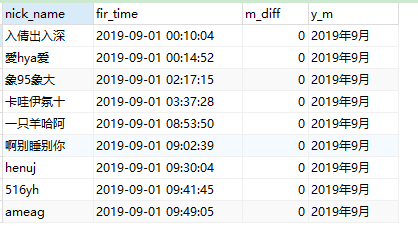
(2)計算客戶每次下單時間與首次下單時間的差值
??以用戶名為連接條件,讓每次下單的時間都與首次下單時間建立連接關系,假若資料量比較大,拼接需要遍歷整個表很多遍,對于這種中間的程序查詢,并不是最后的結果呈現,在保證查詢準確度的情況下,可以用分頁查詢limit陳述句來限制查詢的結果行數,從而提升運行效率,
-- 2、計算每單時間差、重采樣首次訂單時間
SELECT
a.nick_name,
b.fir_time,
TIMESTAMPDIFF(month,b.fir_time,a.pay_time) AS m_diff,
CONCAT(year(b.fir_time),'年',month(b.fir_time),'月') AS y_m
FROM order_sheet1 a
LEFT JOIN (
SELECT
nick_name,
min(pay_time) as fir_time
FROM order_sheet1
GROUP BY nick_name
-- 測驗計算是否成功,提升運行效率
-- LIMIT 20
) b ON a.nick_name=b.nick_name
WHERE b.fir_time IS NOT NULL;
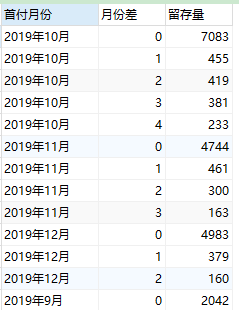
(3)計算留存量
??對首付月份、月份差分組,去重統計nick_name數量即可,
CREATE TABLE order_sheet2 AS
SELECT
t.y_m AS 首付月份,
t.m_diff AS 月份差,
COUNT(DISTINCT nick_name) AS 留存量
FROM
(SELECT
a.nick_name,
b.fir_time,
TIMESTAMPDIFF(month,b.fir_time,a.pay_time) AS m_diff,
CONCAT(year(b.fir_time),'年',month(b.fir_time),'月') AS y_m
FROM order_sheet1 a
LEFT JOIN (
SELECT
nick_name,
min(pay_time) as fir_time
FROM order_sheet1
GROUP BY nick_name
) b ON a.nick_name=b.nick_name
WHERE b.fir_time IS NOT NULL) t
GROUP BY t.y_m,t.m_diff;
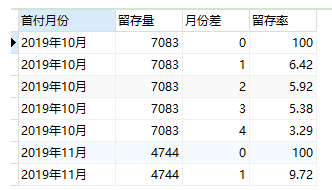
3 計算留存率
-- ① 提取首付月份、留存量
SELECT
首付月份,
留存量
FROM order_sheet2
WHERE 月份差=0;
-- ② 左連接,計算同期首付月份,各差值月份的留存率
SELECT
a.`首付月份`,
b.`留存量`,
a.`月份差`,
round( (a.`留存量`/b.`留存量`)*100,2) AS 留存率
FROM order_sheet2 a
LEFT JOIN (
SELECT
首付月份,
留存量
FROM order_sheet2
WHERE 月份差=0
) b ON a.`首付月份`=b.`首付月份`
-- ③ case when表格轉置,即月份差作為列名
SELECT
c.首付月份,
c.留存量,
CASE c.月份差 WHEN 1 THEN c.留存率 ELSE 0 END AS '+1月',
CASE c.月份差 WHEN 2 THEN c.留存率 ELSE 0 END AS '+2月',
CASE c.月份差 WHEN 3 THEN c.留存率 ELSE 0 END AS '+3月',
CASE c.月份差 WHEN 4 THEN c.留存率 ELSE 0 END AS '+4月',
CASE c.月份差 WHEN 5 THEN c.留存率 ELSE 0 END AS '+5月'
FROM
(SELECT
a.`首付月份`,
b.`留存量`,
a.`月份差`,
round( (a.`留存量`/b.`留存量`)*100,2) AS 留存率
FROM order_sheet2 a
LEFT JOIN (
SELECT
首付月份,
留存量
FROM order_sheet2
WHERE 月份差=0
) b ON a.`首付月份`=b.`首付月份`) c
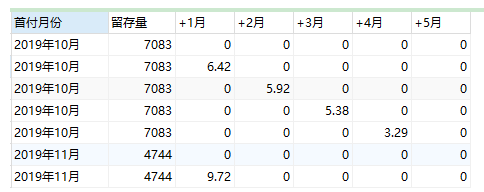
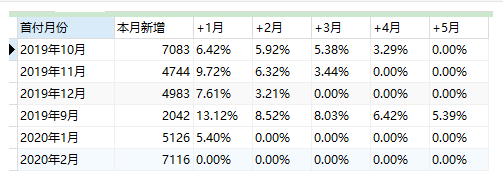
-- ④分組,最終計算留存率
SELECT
d.首付月份,
AVG(d.留存量) AS '本月新增',
CONCAT(SUM(d.`+1月`),'%') AS `+1月`,
CONCAT(SUM(d.`+2月`),'%') AS `+2月`,
CONCAT(SUM(d.`+3月`),'%') AS `+3月`,
CONCAT(SUM(d.`+4月`),'%') AS `+4月`,
CONCAT(SUM(d.`+5月`),'%') AS `+5月`
FROM(
SELECT
c.首付月份,
c.留存量,
CASE c.月份差 WHEN 1 THEN c.留存率 ELSE 0 END AS '+1月',
CASE c.月份差 WHEN 2 THEN c.留存率 ELSE 0 END AS '+2月',
CASE c.月份差 WHEN 3 THEN c.留存率 ELSE 0 END AS '+3月',
CASE c.月份差 WHEN 4 THEN c.留存率 ELSE 0 END AS '+4月',
CASE c.月份差 WHEN 5 THEN c.留存率 ELSE 0 END AS '+5月'
FROM(
SELECT
a.`首付月份`,
b.`留存量`,
a.`月份差`,
round( (a.`留存量`/b.`留存量`)*100,2) AS 留存率
FROM order_sheet2 a
LEFT JOIN (
SELECT
首付月份,
留存量
FROM order_sheet2
WHERE 月份差=0
) b ON a.`首付月份`=b.`首付月份`) c
) d
GROUP BY d.首付月份;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/270981.html
標籤:大數據
上一篇:elasticsearch報Data too large例外
下一篇:詳細虛擬機linux安裝配置