1.概述
在應用系統開發程序中,由于初期資料量小,開發人員寫SQL陳述句時更重視功能上的實作,但是當應用系統正式上線后,隨著生產資料量的急劇增長,很多SQL陳述句開始逐漸顯露出性能問題,對生產環境的影響也越來越大,此時這些有問題的SQL陳述句就成為整個系統性能的瓶頸,因此我們必須要對它們進行優化,該章節將詳細介紹在MySQL中優化SQL陳述句的方法,
2.通過show status命令了解各種SQL的執行頻率
MySQL客戶端連接成功后,通過show [session|global]status命令可以提供服務器狀態資訊,也可以在作業系統上使用mysqladmin extended-status命令獲得這些訊息,show [session|global] status可以根據需要加上引數“session”或者“global”來顯示session級(當前連接)的統計結果和global級(自資料庫上次啟動至今)的統計結果,如果不寫,默認使用引數是“session”,
下面的命令顯示了當前session中所有統計引數的值:
-- 查看會話所有統計的值 SHOW STATUS LIKE 'Com_%'; Or SHOW SESSION STATUS LIKE 'Com_%';
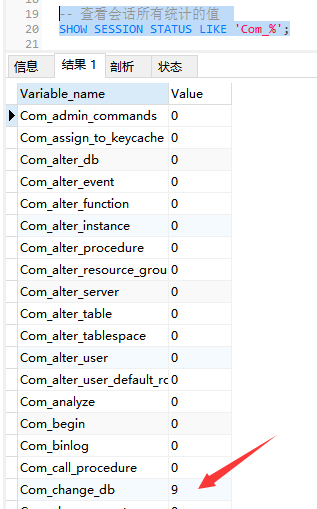
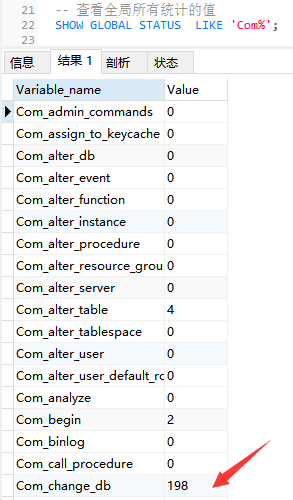
下面的命令顯示了當前global中所有統計引數的值:
-- 查看全域所有統計的值
SHOW GLOBAL STATUS LIKE 'Com_%';
Com_xxx表示每個xxx陳述句執行的次數,我們通常比較關心的是以下幾個統計引數:
●Com_select:執行SELECT操作的次數,一次查詢只累加1,
●Com_insert:執行INSERT操作的次數,對于批量插入的INSERT操作,只累加一次,
●Com_update:執行UPDATE操作的次數,
●Com_delete:執行DELETE操作的次數,
上面這些引數對于所有存盤引擎的表操作都會進行累計,下面這幾個引數只是針對InnoDB存盤引擎的,累加的演算法也略有不同,
●Innodb_rows_read:SELECT查詢回傳的行數,
●Innodb_rows_inserted:執行INSERT操作插入的行數,
●Innodb_rows_updated:執行UPDATE操作更新的行數,
●Innodb_rows_deleted:執行DELETE操作洗掉的行數,
通過以上幾個引數,可以很容易地了解當前資料庫的應用系統是以插入更新為主還是以查詢操作為主,以及各種型別的SQL大致的執行比例是多少,對于更新操作的計數,是對執行次數的計數,不論提交還是回滾都會進行累加,
對于事務型的應用,通過Com_commit和Com_rollback可以了解事務提交和回滾的情況,對于回滾操作非常頻繁的資料庫,可能意味著應用撰寫存在問題,此外,以下幾個引數便于用戶了解資料庫的基本情況, ?
●Connections:試圖連接MySQL服務器的次數,
●Uptime:服務器作業時間,
●Slow_queries:慢查詢的次數,
3.定位執行效率較低的SQL陳述句
可以通過以下兩種方式定位執行效率較低的SQL陳述句,
●通過慢查詢日志定位那些執行效率較低的SQL陳述句,用--log-slow-queries[=file_name]選項啟動時,mysqld寫一個包含所有執行時間超過long_query_time秒的SQL陳述句的日志檔案,
●慢查詢日志在查詢結束以后才紀錄,所以在應用系統反映執行效率出現問題的時候查詢慢查詢日志并不能定位問題,可以使用show processlist命令查看當前MySQL在進行的執行緒,包括執行緒的狀態、是否鎖表等,可以實時地查看SQL的執行情況,同時對一些鎖表操作進行優化,
4.通過EXPLAIN分析低效SQL的執行計劃
通過定位執行效率較低的SQL陳述句后,可以通過EXPLAIN或者DESC命令獲取MySQL如何執行SELECT陳述句的資訊,包括在SELECT陳述句執行程序中表如何連接和連接的順序,比如想統計所有庫存階梯數量,需要關聯goods_stock表和goods_stock_price表,并且對goods_stock_price.Qty欄位做求和(sum)操作,相應 SQL 的執行計劃如下:
EXPLAIN SELECT SUM(sp.Qty)
FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp
ON s.ID=sp.GoodsStockID;

如上圖所示每個列的簡單解釋如下:
●select_type:表示 SELECT 的型別,常見的取值有:
◎SIMPLE(簡單表,即不使用表連接 或者子查詢),
◎PRIMARY(主查詢,即外層的查詢)、UNION(UNION 中的第二個或者后面的查詢陳述句)、◎SUBQUERY(子查詢中的第一個SELECT)等,
●table:輸出結果集的表,
●type:表示表的連接型別,性能由好到差的連接型別為:
◎system(表中僅有一行,即常量表),
◎const(單表中最多有一個匹配行,例如primary key或者unique index),
◎eq_ref(對于前面的每一行,在此表中只查詢一條記錄,簡單來說,就是多表連接中使用primary key或者unique index),
◎ref(與eq_ref類似,區別在于不是使用primary key或者unique index,而是使用普通的索引),
◎ref_or_null(與ref類似,區別在于條件中包含對NULL的查詢),
◎index_merge(索引合并優化),
◎unique_subquery(in的后面是一個查詢主鍵欄位的子查詢),
◎index_subquery(與unique_subquery類似,區別在于in的后面是查詢非唯一索引欄位的子查詢),
◎range(單表中的范圍查詢),
◎index(對于前面的每一行,都通過查詢索引來得到資料),
◎all(對于前面的每一行,都通過全表掃描來得到資料),
●possible_keys:表示查詢時,可能使用的索引,
●key:表示實際使用的索引,
●key_len:索引欄位的長度,
●rows:掃描行的數量,
●filtered:回傳結果的行占需要讀到的行(rows列的值)的百分比,
●Extra:執行情況的說明和描述,
5.確定問題并采取相應的優化措施
經過以上定位步驟,我們基本就可以分析到問題出現的原因,此時我們可以根據情況采取相應的改進措施,進行優化提高陳述句執行效率,
在上面的例子中,已經可以確認是goods_stock是走主鍵索引的,但是對goods_stock_price子表的進行了全表掃描導致效率的不理想,那么應該對goods_stock_price表的GoodsStockID欄位創建索引,具體命令如下:
-- 創建索引
CREATE INDEX idx_stock_price_1 ON goods_stock_price (GoodsStockID);
-- 附加洗掉跟查詢索引陳述句
ALTER TABLE goods_stock_price DROP INDEX idx_stock_price_1;
SHOW INDEX FROM goods_stock_price;
創建索引后,我們再看一下這條陳述句的執行計劃,具體如下:
EXPLAIN SELECT SUM(sp.Qty)
FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp
ON s.ID=sp.GoodsStockID;

可以發現建立索引后對goods_stock_price子表需要掃描的行數明顯減少(從 3 行減少到1行),可見索引的使用可以大大提高資料庫的訪問速度,尤其在表很龐大的時候這種優勢更為明顯,
參考文獻:
深入淺出MySQL大全
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/270987.html
標籤:MySQL