我們所有的查詢陳述句,MySQL 都會為其選擇一個最合適的執行計劃,這個執行計劃就展示了接下來執行查詢的具體方式,在日常作業中我們可以在 SQL 陳述句前面加上 EXPLAIN 關鍵字來查看具體的執行計劃,
舉個例子:

這種就是我們日常用到 EXPLAIN 看到的最直接結果,也是這個查詢陳述句最終的執行計劃,這個筆記就是用來解釋這個執行計劃中的各個列分別對應的是什么意思,不過在整理具體之前,先簡明扼要的說一下每個欄位的具體含義:
| 列名 | 描述 | 備注 |
|---|---|---|
| id | 在一個大的查詢中,每個 SELECT 對應一個唯一的 id | id 小的先執行 |
| select_type | SELECT 關鍵字對應的查詢型別 | 連接查詢和子查詢的時候才有用 |
| partitions | 匹配的磁區資訊 | |
| type | 針對單表的訪問方式 | 我們最常用的欄位 |
| possible_Keys | 可能用到的索引 | |
| key | 實際使用的索引 | |
| key_len | 實際使用的索引長度 | |
| ref | 當使用索引列等值查詢時,與索引列等值匹配的物件資訊 | |
| rows | 預估的需要讀取的記錄條數 | |
| filtered | 針對預估的需要讀取的記錄,經過搜索條件過濾后剩余記錄條數的百分比 | |
| Extra | 一些額外的資訊 | 重點 |
執行計劃輸出中各列詳解
id 列
通常來說一個查詢陳述句都有一個或多個 SELECT ,在執行計劃中每一個 SELECT 都會被單獨分配一個 id,而 id 小的會被優先執行,為方便理解,我們舉幾個簡單的例子:

這種單表等值查詢,顯而易見的只有一個 SELECT 而且實際上也只訪問了一張表,所以下面的 id 只有一個是 1,如果我們使用外連接去查詢兩張表,但是只有一個 SELECT 的情況呢?

從結果上我們可以反過來推測,因為 SQL 中僅包含一個 SELECT,所以只有一個 id,值為 1;但是因為這個外連接查詢分別查詢了 s1 表和 s2 表,所以執行計劃中有兩行,要注意,執行計劃的每一行都是針對某一個表的"子查詢",
在實際開發程序中,如果我們使用子查詢或者 UNION 子句就可能出現多個 SELECT,這里我分別舉一個 UNION 和 子查詢 的例子,

如果你在實驗程序中,發現你的子查詢并沒有因為有多個 SELECT 而分配不同的 id,請不要懷疑自己的知識認知,這只是因為你的子查詢被 MySQL 的查詢優化器進行了重寫,轉換為了連接查詢(半連接),

說一個特殊的情況,相信如果大家仔細閱讀了上面的內容的話,就會發現在我們舉的例子中出現了一個怪咖,就是 union 子句查詢的執行計劃中出現了一個 id 為 null 的情況

這個其實是一個內部的臨時表,MySQL 為了讓 id 為 1 和 2 的資料進行去重,他使用的是內部臨時表,MySQL 在內部創建了一個名為 <union1,2> 的臨時表,id 為 null 是表示這個表是臨時的,
select_type 列
在前面的例子中我們也說到了一個查詢陳述句中可能包含若干個 SELECT,查詢若干個表,每一個表都是一個小查詢,而 select_type 就是來說明這個小查詢的型別的,
這一部分的筆記,我前期已經整理過了,如果大家感興趣可以直接點擊下面的連接去查看,我這里就不再贅述了,
詳細解釋MySQL explain 中的 select_type 是什么
table 列
無論我們的查詢陳述句有多復雜,其中包含多少個表,使用什么連接、子查詢、UNION 子句等方式進行組合,到最后還是對每個表進行單表訪問,
EXPLAIN 陳述句的輸出的每條記錄都對應著某個單表的訪問方法,該記錄的 table 列代表該表的表名,

type 列
坦白的說,這一列應該是我們在查看 MySQL 的執行計劃的時候最常看也是最無腦看的一列了,因為我們在學習 《Java 開發規范》的時候,上面明確規定了 SQL 的級別,原文如下:

開發規范中的這個所謂的級別,本質上就是說的 EXPLAIN 執行計劃中 type 列的級別,完整的訪問方法包括 system、const、eq_ref、ref、fulltext、ref_or_null、index_merge、unique_subquery、index_subquery、range、index、ALL,為了方便大家閱讀,我先單獨整理一個表格來說明各個級別的具體含義,然后再分別具體說明級別資訊,
| 型別 | 描述 | 備注 |
|---|---|---|
| system | 如果表里面只有一條資料,而且表使用的存盤引擎(如 MyISAM)的統計資訊是準確的, | 條件太苛刻,幾乎見不到 |
| const | 使用主鍵或唯一二級索引與常數進行等值匹配時 | 效率高,常見 |
| eq_ref | 連接查詢是,如果被驅動表是通過主鍵或者不允許為 null 的唯一二級索引列進行等值匹配的方法訪問的 | 常見 |
| ref | 通過普通的二級索引與常數進行等值匹配時 | 常見 |
| fulltext | 全文索引 | 幾乎用不到 |
| ref_or_null | 對二級索引進行等值匹配且該索引的值也可以為 null 的時候 | 常見 |
| index_merge | 兩個以上的索引合并 | 不常見 |
| unique_subquery | 如果子查詢可以轉換為 EXISTS 子查詢,而且轉換之后可以使用主鍵或者不允許為 null 的唯一二級索引進行等值匹配 | |
| index_subquery | 如果子查詢可以轉換為 EXISTS 子查詢,而且轉換之后可以使用普通二級索引進行等值匹配 | |
| range | 使用索引進行范圍查詢 | 常見 |
| index | 使用索引覆寫,掃描前部索引記錄的時候 | 常見,但是不推薦 |
| ALL | 全表掃描 | 常見,但是不推薦 |
為了方便理解,每個我們都舉一個具體的例子,當然如果你的時間有限,可以不看下面的內容,只需要記住上面的這個表格就可以了:
-
system 這個基本上見不到的,他要求表對應的存盤引擎的統計資訊是準確的,而我們通常是使用 InnoDB 存盤引擎,而這個存盤引擎的統計資訊是不準確的,so,forget it;
-
const 這個就非常常見了,當我們使用主鍵索引或者唯一二級索引搜索非空的等值查詢的時候,就是走的這個型別
比如說 SELECT * FROM info_information_unit WHERE id = 1

-
rq_ref 單獨拿出這個型別來,可能你會覺得有點眼生,實時上,我們常常在用,因為我們表結構設計上通常會使用一個表的主鍵和另外一個表關聯起來,這個時候被驅動表的型別就是 rq_ref
比如說:SELECT * FROM website_column wco LEFT JOIN website_label wl ON wco.id = wl.id WHERE wl.id = 123;

-
ref 這個其實我們也非常非常的常見,如果我們是使用我們添加的普通二級索引進行查詢的話,他的級別就是 ref,例子太多了,我敢保證你的單標查詢的 SQL 起碼百分之五十以上這樣的,
比如說:SELECT * FROM info_information_unit WHERE code = 'xxx';

-
fulltext 全文索引,其實目前 MySQL 支持了全文索引,而且現在也支持了中文的分詞器,但是,實際上絕大多數場景下,針對分詞查詢這種倒排索引的應用場景,我們通常會使用更加成熟的 Elasticsearch,這里不展開講述了,
-
ref_or_null 在我的理解里面,這種其實是一種特殊的 ref,和 ref 的區別在于他接受該索引列的值可是null 的情況,
比如說:SELECT * FROM info_information_unit WHERE code = 'a' or code IS NULL;

-
index_merge 我必須得說,學習這個型別之前,在我的認知里面,我們的查詢 SQL 中無論可以匹配上多少個索引,最終都會通過查詢優化器計算出成本最小的一個索引,然后使用這個索引對資料進行查詢,而這種是在某種常見下可以使用 Intersection、union、sort-union 這 3 種索引合并的方式來執行查詢的,
比如說:SELECT * FROM s1 WHERE key1 = 'a' AND key3 = 'a';

-
unique_subquery 和 index_subquery 這兩個只是最終是否能夠使用主鍵或者不允許存盤 null 的唯一二級索引進行匹配這一點上有差異,其他都是一樣的,所以我們把他們放在一起說,
他們都是針對一些包含 IN 子查詢的查詢陳述句,如果查詢優化器決定將 IN 子查詢轉換為 EXISTS 子查詢的話就會出現上面這種,
這里特殊說明一下,很多小伙伴對什么情況下查詢優化器才會把 IN 子查詢轉換 EXISTS 子查詢表示好奇,我后面會梳理查詢優化器對 IN 陳述句的特殊關照的相關材料,等我,

-
range 這個大家看起來應該也很眼熟吧,如果我們使用范圍查詢的時候,經常看到他,

-
index 這個偶爾會看到,但是也不是很常見,這種情況下其實相當于是對于二級索引這棵樹進行了全表掃描,他會掃描全部的索引記錄,比如說我們查詢聯合索引的非第一個欄位的時候,而且不需要回表的時候

-
ALL 這個最熟悉的全表掃描了,老實講,我希望你的查詢 SQL 的執行計劃中看不到他,
possible_keys 列 和 key 列
在EXPLAIN 輸出的執行計劃中,possible_keys 串列示在某個查詢陳述句中,對某表執行單標查詢時可能用到的索引有哪些,而 key 則是則是表示,最終用到的索引是什么,舉個例子:

但是需要注意的是,并不是可以供選的索引越多越好,因為可以供選擇的索引越多,查詢優化器在計算查詢成本的時候花費的時間就越長,
ref 列
當我們的查詢方法的類別是 const、eq_ref、ref、ref_or_null、unique_subquery、index_subquery 中的其中一個時,ref 列展示的就是與索引列進行等值查詢的東西是啥,
它有時是一個常數,有時是一個列,甚至可以是一個 function,

rows 列
如果查詢優化器決定使用全表掃描的方式對某個表執行查詢時,執行計劃的rows列就代表預計需要掃描的行數,如果使用索引來執行查詢時,執行計劃的rows列就代表預計掃描的索引記錄行數,
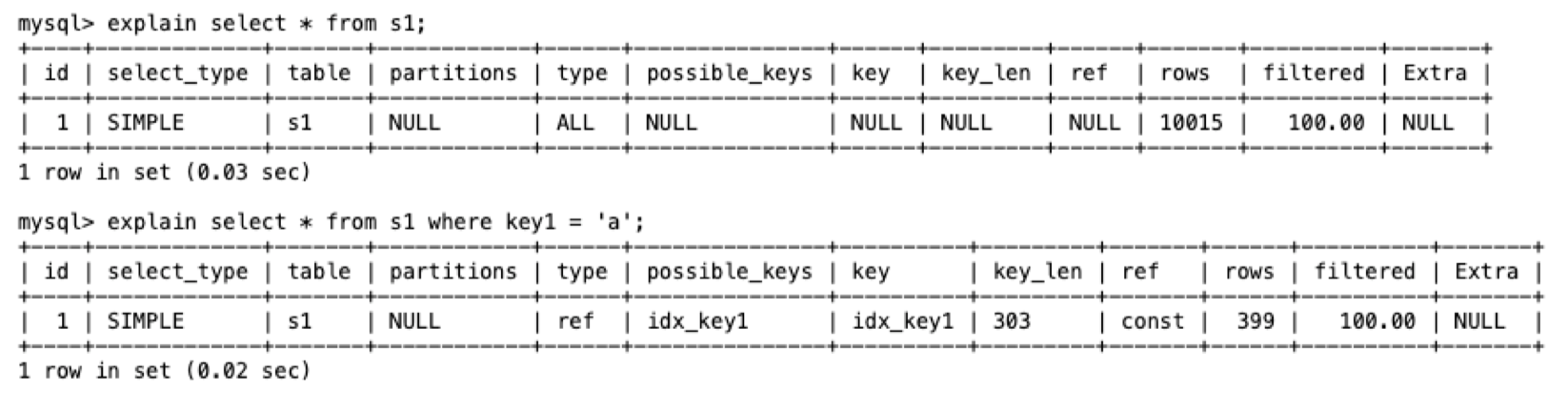
filtered 列
filtered 串列示針對預估的需要讀取的記錄,經過搜索條件過濾后剩余記錄條數的百分比,這個感覺說起來不好理解,我們可以舉兩個例子:

在這個查詢中,我們對于表中 10107 條資料,由于沒有搜索條件,所以他的過濾下的資料為 100%,

而在這個查詢中,由于我們增加了搜索過濾條件,經過過濾大概還能剩下 10107 x 10% = 1010 條資料,
Extra 列
Extra 是用來說明一些額外的資訊的,其實根據上面的內容,我們大概知道了一個 SQL 的執行計劃輸出列都是什么,分別代表什么意思,但是通過這列中的說明資訊,我們可以更準確的理解 MySQL 到底如何執行給定的查詢陳述句,
Extra 列中可以給出的宣告資訊非常非常的多,我手頭的材料中也說明了很多,但是我在這里還是做了一些精簡,因為這里面實際上有很多我們日常作業中根本用不上,我們只要對下面的這些描述有印象就可以了,如果遇到陌生的,可以在面向谷歌編程,
- No tables used: 查詢陳述句中沒有 FROM 子句
- Impossible WHERE 查詢陳述句的 WHERE 子句條件永遠為 false, 如: WHERE 1 != 1
- No matching min/max row :查詢串列處有 MIN 或者 MAX 聚集函式,但是沒有記錄符合 WHERE 子句中的搜索條件
- Using index : 使用了覆寫索引,
- Using index condition : 搜索條件中雖然出現了索引類,但是卻不能充當邊界條件來形成掃描區間,比如 key1 > 'z' and key1 like '%a'
- Using where: 當某個搜索條件需要在 server 層進行判斷時,提示 Using where
- Using join buffer:連接查詢的執行程序中,當被驅動表不能有效的利用索引加快訪問速度的時候,使用 join buffer 緩沖區來加快查詢速度的時候,會提示這個,
- Using filesort:在有些情況下對結果集中的記錄進行排序的時候,是可以使用到索引的,
- Using temporary: 在許多查詢的執行程序中,借助臨時表進行去重、排序等,
此隨筆是《MySQL 是怎樣運行的》的讀書筆記
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/270991.html
標籤:MySQL
上一篇:認識資料庫