gpfdist原理決議
前言:gpfdist作為批量向postgresql寫入資料的工具,了解其內部原理有助于正確使用以及提供更合適的資料同步方案,文章先簡要介紹gpfdist的整體流程,然后針對重要步驟詳細展開,文章有的地方可能探索不夠深入,感興趣的可以繼續深入,如有錯誤請指出,
1 整體流程
Gpfdist的整體流程可簡單分為4步,
(1) 決議引數;
(2) 從指定的埠串列中搜尋可用埠;
(3) 監聽第一個可用埠;
(4) 注冊該埠的可讀事件,等待連接請求;
(5) 回應各類事件,
下面通過原始碼及注釋詳細介紹上述程序,
int main(int argc, const char* const argv[]) { if (gpfdist_init(argc, argv) == -1) gfatal(NULL, "Initialization failed"); return gpfdist_run(); }
Main函式很簡短,呼叫了gpfdist_init與gpfdist_run,其中gpfdist_run比較簡單,原始碼如下,僅僅呼叫了libevent的事件分發函式,以回呼形式回應各類事件(主要是socket讀寫事件),
int gpfdist_run() { return event_dispatch(); }
gpfdist_init比較復雜,完成了libevent的初始化、事件系結、http服務啟動等功能,原始碼如下,其中apr是Apache的可移植運行庫,在該專案中主要用于資源管理,不影響理解gpfdist原理,這里不再介紹,有興趣的可參考https://apr.apache.org/,
int gpfdist_init(int argc, const char* const argv[]) { /*初始化apr資源池*/ if (0 != apr_app_initialize(&argc, &argv, 0)) gfatal(NULL, "apr_app_initialize failed"); atexit(apr_terminate); if (0 != apr_pool_create(&gcb.pool, 0)) gfatal(NULL, "apr_app_initialize failed"); //apr_signal_init(gcb.pool); gcb.session.tab = apr_hash_make(gcb.pool); //決議命令列引數 parse_command_line(argc, argv, gcb.pool); ...... event_init(); signal_register(); //啟動http服務 http_setup(); .....
gpfdist_init通過呼叫http_setup函式完成http服務的啟動,http_setup原始碼如下,主要功能是測驗哪些埠可以使用,
http_setup(void) { SOCKET f; int on = 1; struct linger linger; struct addrinfo hints; struct addrinfo *addrs, *rp; int s; int i; char service[32]; const char *hostaddr = NULL; //系結gpfdist的檔案讀寫函式,用于從檔案或其他方式讀寫資料 gpfdist_send = gpfdist_socket_send; gpfdist_receive = gpfdist_socket_receive; ......
/* 下面的內容就是從指定埠串列中測驗哪些埠可用*/ for (;;) { //利用第一個埠組成socket使用的網路地址 snprintf(service,32,"%d",opt.p); memset(&hints, 0, sizeof(struct addrinfo)); hints.ai_family = AF_UNSPEC; /* Allow IPv4 or IPv6 */ hints.ai_socktype = SOCK_STREAM; /* tcp socket */ hints.ai_flags = AI_PASSIVE; /* For wildcard IP address */ hints.ai_protocol = 0; /* Any protocol */ s = getaddrinfo(hostaddr, service, &hints, &addrs); ....... /* 測驗地址是否可用,這個for回圈只會執行一次,因為rp->ai_next=0*/ for (rp = addrs; rp != NULL; rp = rp->ai_next) { gprint(NULL, "Trying to open listening socket:\n"); print_listening_address(rp); /* * getaddrinfo gives us all the parameters for the socket() call * as well as the parameters for the bind() call. */ f = socket(rp->ai_family, rp->ai_socktype, rp->ai_protocol); //設定keep_alive linger等屬性 ...... if (bind(f, rp->ai_addr, rp->ai_addrlen) != 0) { ...... } /* listen with a big queue */ if (listen(f, opt.z)) { ...... } gcb.listen_socks[gcb.listen_sock_count++] = f; gprint(NULL, "Opening listening socket succeeded\n"); } ...... } /* * 為上述可用埠系結可讀事件回應函式do_accept,用于接收客戶端的連接, */ for (i = 0; i < gcb.listen_sock_count; i++) { /* when this socket is ready, do accept */ event_set(&gcb.listen_events[i], gcb.listen_socks[i], EV_READ | EV_PERSIST, do_accept, 0); ...... if (event_add(&gcb.listen_events[i], 0)) gfatal(NULL, "cannot set up event on listen socket: %s", strerror(errno)); } }
自此http服務已經建立起來,并準備好接收postgresql segment的連接,
2 核心資料結構間的聯系
接下來說明一下gpfdist中的幾個核心資料結構及其之間的關系,便于對下文代碼邏輯關系的理解,
session_t是一次會話,由成員key唯一標識,key = tid:path,tid = xid.cid.sn,其中xid是事務id,cid是查詢命令id,每次查詢時屬于同一個sql的segment請求的xid、cid相同,但由于各segment請求的path可能不同,因此同一個查詢的不同segment請求可能屬于不同session,另外注意tid長度不能超過1023位元組,
request_t代表一個segment的請求,因此session_t對應多個request_t,
fstream_t代表屬于同一session_t的request_t想要請求的資料流,其成員glob_and_copy_t包含多個檔案地址,fstream_t會順序讀取這些檔案回應給segment,
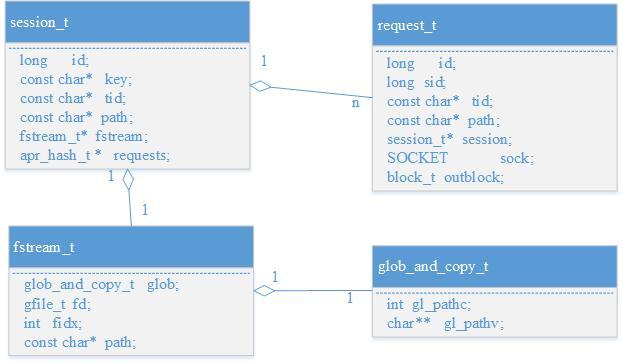
圖1 核心資料結構
3 接受連接
http服務接收到客戶端連接后由do_accept函式回應,該函式首先接收客戶端連接,并給該連接設定非阻塞等屬性,接著創建request_t物件并初始化其部分屬性,最后呼叫setup_read函式為該連接系結讀事件回應函式do_read_request,到此gpfdist已經與客戶端建立了連接并開始等待客戶端的http請求,
static void do_accept(int fd, short event, void* arg) { address_t a; socklen_t len = sizeof(a); SOCKET sock; request_t* r; apr_pool_t* pool; int on = 1; struct linger linger; /* do the accept */ if ((sock = accept(fd, (struct sockaddr*) &a, &len)) < 0) { gwarning(NULL, "accept failed"); goto failure; } /* set to non-blocking, and close-on-exec */ ...... /* set keepalive, reuseaddr, and linger */ ...... /* create a pool container for this socket */ ...... /* 呼叫setup_read為上述socket設定讀事件回應函式do_read_request */ if (setup_read(r)) { http_error(r, FDIST_INTERNAL_ERROR, "internal error"); request_end(r, 1, 0); } return; }
接收請求后的處理
如圖2,gpfdist接收到http請求后決議出相關引數,包含tid、cid、檔案路徑等資訊,然后系結到對應session上,根據請求型別分別呼叫不同函式完成對segment的回應,下面著重講解路徑提取、session系結兩個操作的細節,
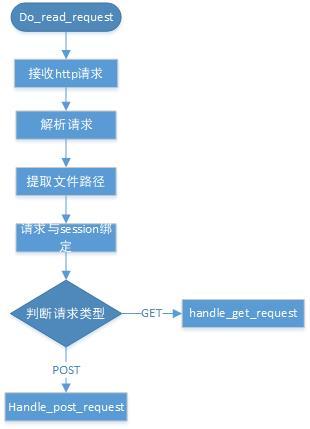
圖2 接收請求
(1)路徑提取
segment請求中路徑引數格式如下所示:
1.csv空格t*.csv
(注意:該串不能含有相對路徑”..”)
gpfdist會遍歷該字串,以空格為分隔符提取所有檔案路徑,并在每個路徑前拼接上gpfdist啟動時命令列輸入的目錄,最終得到如下路徑:
/home/test/data/1.csv 空格/home/test/data/t*.csv
轉換后的路徑將用于后面的檔案讀取或寫入操作,
(2)session與連接系結
接收到segment的http請求后需要將其與session系結,流程如圖3,首先根據請求的key查找對應的session是否存在,存在則請求與session系結,否則就新建并初始化fstream_t與session物件,
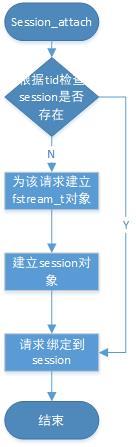
圖3 系結session
新建fstream_t時會重新組織檔案路徑并檢查是否有操作權限,首先把上文轉換后的路徑以空格分開,然后將每一個路徑中包含的通配符決議成具體的檔案名,得到如下的路徑串列(這里假設目錄下存在t1.csv t2.csv):
/home/test/data/1.csv
/home/test/data/t1.csv
/home/test/data/t2.csv
然后嘗試打開上述檔案以測驗是否有操作權限,
4 GET請求
如果segment是GET請求, 對應的socket會被設定可寫事件回應函式do_write,其流程如圖4:
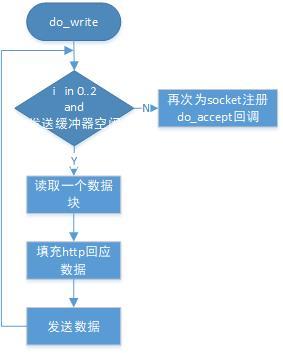
圖4 發送資料
在讀取一個資料塊時,gpfdist采用整行讀取方式,即每次回應的業務資料一定是源檔案的完整若干行,目前gpfdist對于csv檔案僅支持\n \r \r\n 三種行分隔符,但可通過修改scan_csv_records_crlf函式支持其他型別的行分隔符,另外csv檔案允許資料中含有行分隔符;對于text格式的檔案,行分隔只支持\n,
gpfdist會將本次讀取到的資料的元資訊填充到回應頭部,包含本次回應的業務資料的長度、行數、檔案名、在檔案中的偏移等資訊,
5 POST請求
圖5是gpfdist對post請求(寫請求)的處理流程,不再詳細展開,
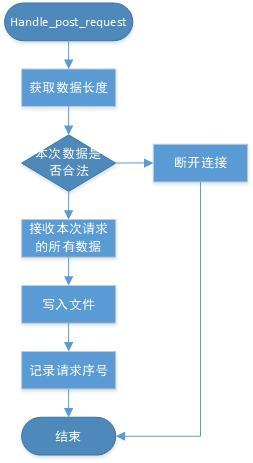
圖5 資料寫入檔案
6 外表檔案個數與segment數量的關系
在此只針對檔案形式的讀外表進行分析,讀外表的創建陳述句如下:
create external table test ( id integer, name varchar ) location (‘gpfdist://$IP:$PORT/$file_name’[,..]) format ‘csv’(delimiter’,’) ;
從以上陳述句可以看出,外表可以配置多個檔案,但應注意配置的檔案數量與segment存在以下關系:
(1) 只有一個檔案(通配符計為一個檔案)
每個segment都會請求該檔案的資料,當資料量小時,有的segment可能獲取不到資料,這不會對表的讀取造成任何影響,
(2) 配置兩個以上檔案
- 檔案數量 < segment數量
postgresql會給每個segment分配一個檔案進行讀取,
- 檔案數量 > segment
gpfdist報錯,讀表失敗,
參考:
https://docs.greenplum.org/6-12/common/gpdb-features.html
https://greenplum.org/readable-external-protocol-gpfdist/
https://greenplum.org/introduction-writable-gpfdist/
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/271154.html
標籤:PostgreSQL
上一篇:[20210316]MSSM表空間塊ITL的LCK 3.txt
下一篇:postgresql資料型別