一、HBase 是什么?
HBase 是一個分布式的、面向列的開源資料庫,該技術來源于 Fay Chang 所撰寫的 Google 論文 “Bigtable:一個結構化資料的分布式存盤系統” ,就像 Bigtable 利用了 Google 檔案系統(File System)所提供的分布式資料存盤一樣,HBase 在 Hadoop 之上提供了類似于 Bigtable 的能力,HBase 是 Apache 的 Hadoop 專案的子專案,HBase 不同于一般的關系資料庫,它是一個適合于非結構化資料存盤的資料庫,另一個不同的是 HBase 基于列的而不是基于行的模式,
二、HBase 的特點?
- 大:一個表可以有上億行,上百萬列,
- 面向列:面向串列(簇)的存盤和權限控制,列(簇)獨立檢索,
- 稀疏:對于為空(NULL)的列,并不占用存盤空間,因此,表可以設計的非常稀疏,
- 無模式:每一行都有一個可以排序的主鍵和任意多的列,列可以根據需要動態增加,同一張表中不同的行可以有截然不同的列,
- 資料多版本:每個單元中的資料可以有多個版本,默認情況下,版本號自動分配,版本號就是單元格插入時的時間戳,
- 資料型別單一:HBase 中的資料都是字串,沒有型別,
- 支持過期:HBase 支持 TTL 過期特性,用戶設定過期時間,超過 TTL 的資料會被系統自動清理,
三、Hbase 資料模型?
HBase 以表的形式存盤資料,表由行和列組成,列劃分為若干個列簇(column family),如下圖所示,
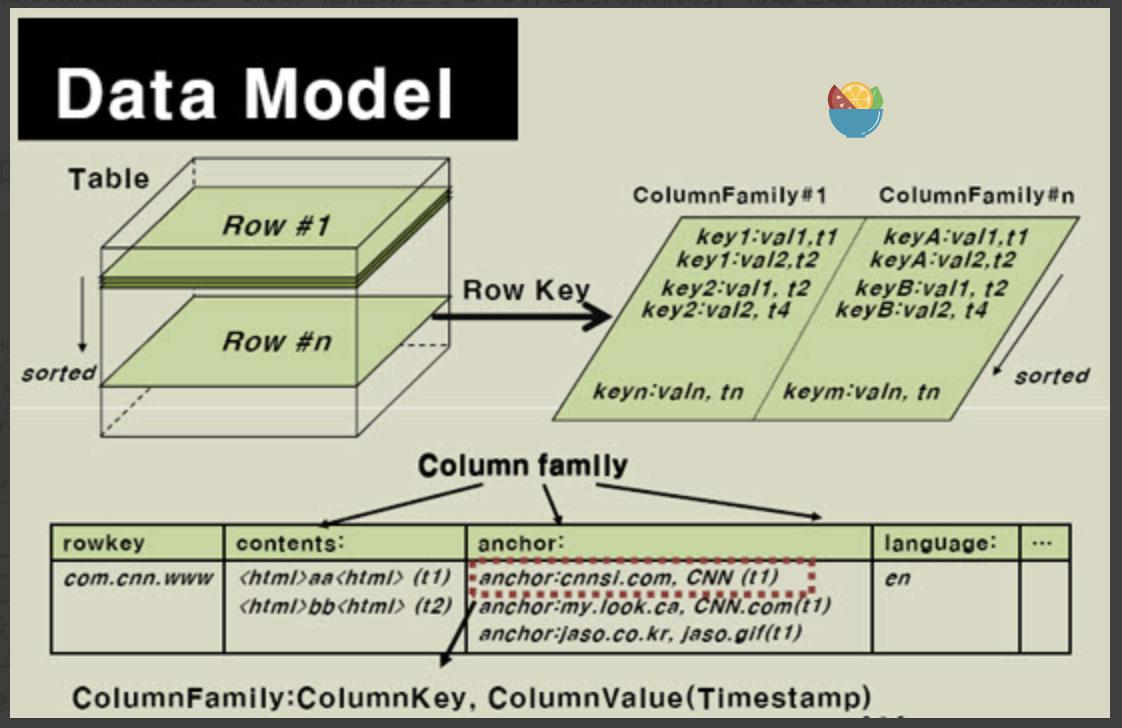
- 表(Table): HBase 會將資料組織進一張張的表里面,但是需要注意的是表名必須是能用在檔案路徑里的合法名字,因為 HBase 的表是映射成 hdfs 上面的檔案,
- 行(Row): 在表里面,每一行代表著一個資料物件,每一行都是以一個行鍵(Row Key)來進行唯一標識的,行鍵并沒有什么特定的資料型別, 以二進制的位元組來存盤,
- 列簇(Column Family): 在定義 HBase 表的時候需要提前設定好列簇, 表中所有的列都需要組織在列簇里面,列簇一旦確定后,就不能輕易修改,因為它會影響到 HBase 真實的物理存盤結構,但是列簇中的列標識(Column Qualifier)以及其對應的值可以動態增刪,表中的每一行都有相同的列簇,但是不需要每一行的列簇里都有一致的列標識(Column Qualifier)和值, 所以說是一種稀疏的表結構,
- 列標識(Column Qualifier): 列簇中的資料通過列標識來進行映射,其實這里可以不用拘泥于“列”這個概念,也可以理解為一個鍵值對,Column Qualifier 就是 Key, 列標識也沒有特定的資料型別,以二進制位元組來存盤,
- 單元(Cell): 每一個行鍵,列簇和列標識共同組成一個單元,存盤在單元里的資料稱為單元資料,單元和單元資料也沒有特定的資料型別,以二進制位元組來存盤,
- 時間戳(Timestamp): 默認下每一個單元中的資料插入時都會用時間戳來進行版本標識,讀取單元資料時,如果時間戳沒有被指定,則默認回傳最新的資料,寫入新的單元資料時,如果沒有設定時間戳,默認使用當前時間,每一個列簇的單元資料的版本數量都 HBase 單獨維護,默認情況下 HBase 保留 3 個版本資料,
RowKey
RowKey 可以使用任意字串(最大長度為 64KB,實際應用中長度一般為 10 ~ 100bytes),在 HBase 內部,Row Key 保存為位元組陣列,
在 HBase 使用程序中,設計 RowKey 是一個很重要的環節,我們在進行 RowKey 設計的時候可參照如下步驟:
- 結合業務場景特點,選擇合適的欄位來做為 RowKey, 且按照查詢頻次來放置欄位順序,
- 通過設計的 RowKey 能盡可能的將資料打散到整個集群中,均衡負載,避免熱點問題,
- 設計的 RowKey 應盡量簡短,
與 NoSQL 一樣,RowKey 是用來檢索記錄的主鍵,訪問 HBase table 中的行,只有三種方式:
- 通過單個 RowKey 訪問,
- 通過 scan 方式,設定 startRow 和 stopRow 引數進行范圍匹配,
- 全表掃描,即直接掃描整張表中的所有行記錄,
物理存盤模型
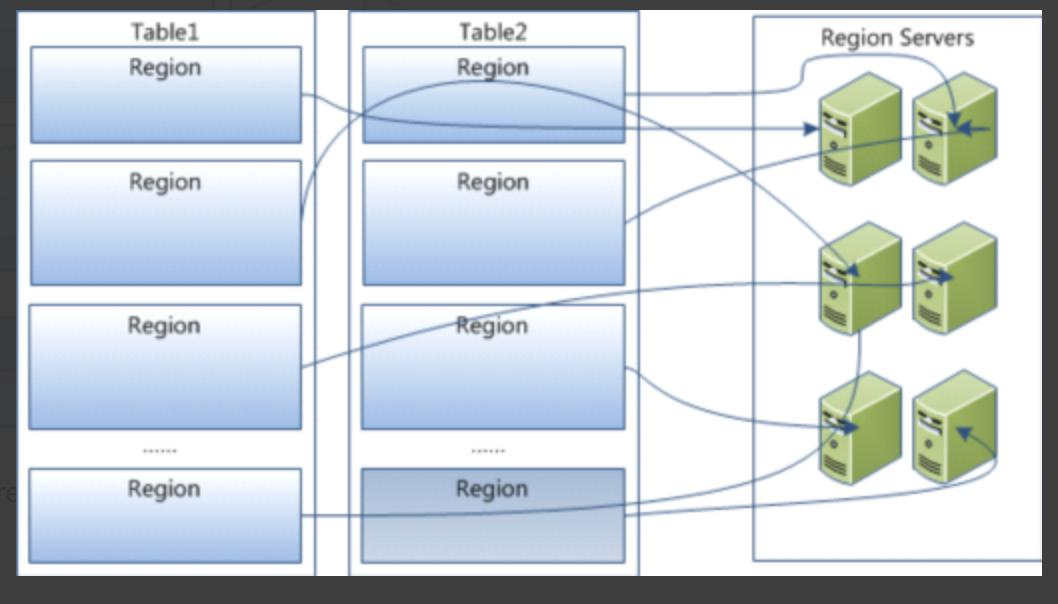
物理存盤上 HBase 將 Table 在行的方向上分割為多個 HRegion, 每個 HRegion 分散在不同的 HRegionServer 中,
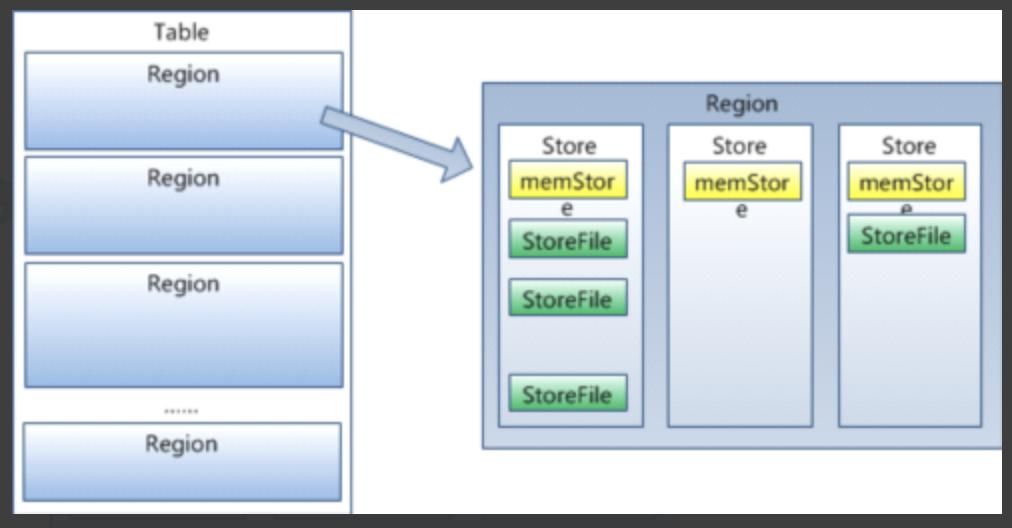
每個 HRegion 由多個 Store 構成, 每個 Store 由一個 memStore 和0或多個 StoreFile 組成, 每個 Store 保存一個 Columns Family,
四、Hbase 體系結構?
HBase 中的組件包括 Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog 等,
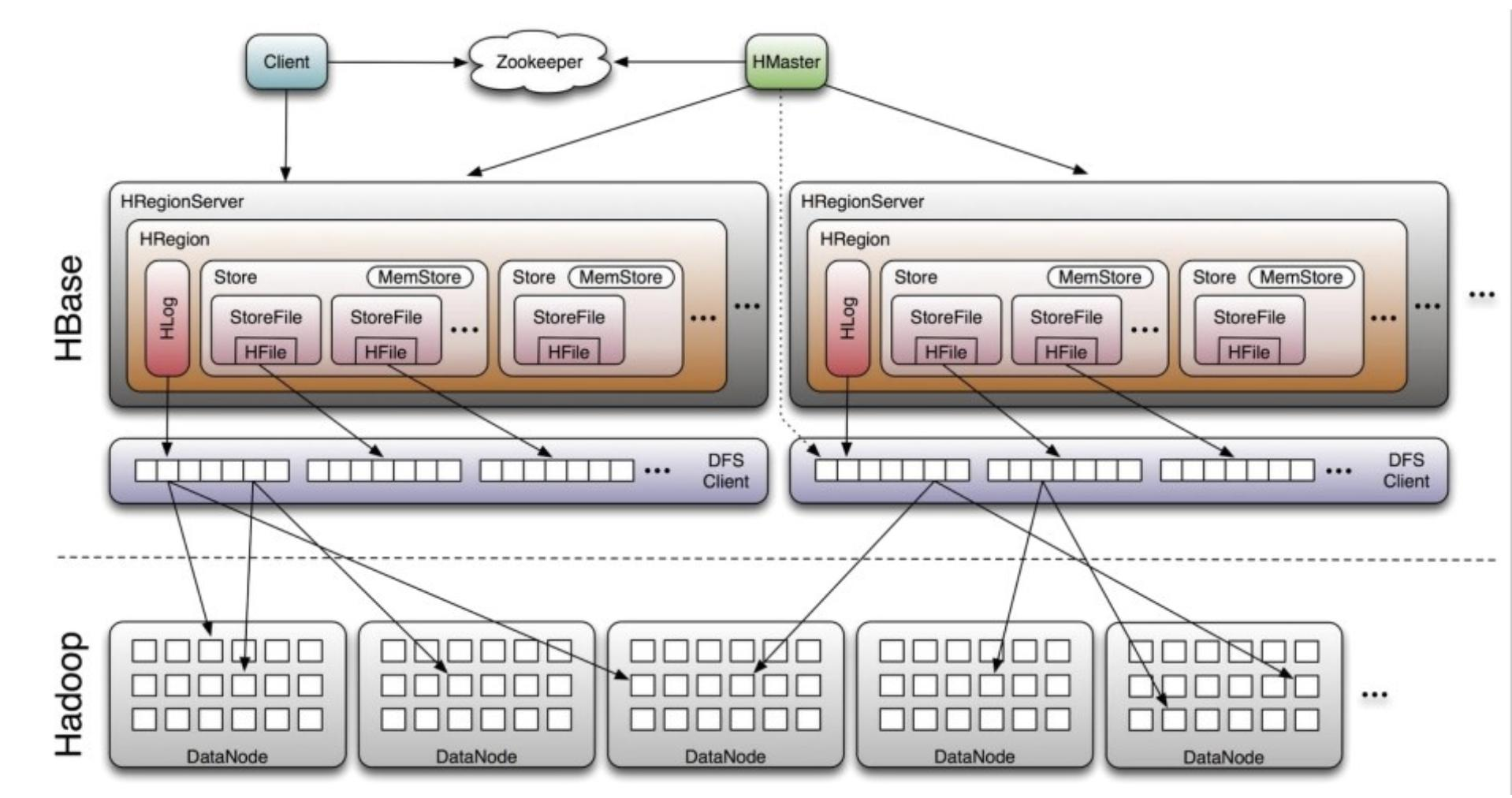
HBase 中的每張表都通過行鍵(RowKey)按照一定的范圍被分割成多個子表(HRegion),一個 HRegion 超過一定閾值就要被分割成兩個,這個程序由 HRegionServer 管理, 而 HRegion 的分配由 HMaster 管理,
HMaster
- 為 HRegion Server 分配 HRegion,
- 負責 HRegion Server 的負載均衡,
- 發現失效的 HRegion Server 并重新分配其上 HRegion,
- HDFS 上的垃圾檔案回收,
- 處理 schema 更新請求,
HMaster 僅僅維護 table 和 HRegion 的元資料資訊,而 table 的元資料資訊保存在 zookeeper 上,因此,HMaster 的負載很低,
HRegion Server
- 維護 HMaster 分配給他的 HRegion,并處理對這些 HRegion 的 IO 請求(client 訪問 HBase 上的資料并不需要 HMaster 參與),
- 負責切分正在運行程序中變得過大的 HRegion,
HRegion
table 在行的方向上分割為多個 HRegion ,HRegion 是 HBase 中分布式存盤和負載均衡的最小單元,即不同的 HRegion 可以分布在不同的 HRegion Server 上,但同一個 HRegion 是不會拆分到多個 HRegion Server 上,
HRegion 按大小分割,每個表一般只有一個 HRegion ,隨著資料不斷的插入表,HRegion 不斷增大,當 HRegion 的某個列簇達到一定的閾值時就會分成兩個新的 HRegion ,
Zookeeper
- 保證任何時候,集群中只有一個 HMaster,避免 HMaster 的單點故障,
- 存盤所有 HRegion 的尋址入口,
- 實時監控 HRegion Server 的上線和下線資訊,并實時通知 HMaster,
- 存盤 HBase 的 schema 和 table 元資料,
HBase 依賴 Zookeeper,默認情況下 HBase 管理 Zookeeper 實體(啟動或關閉 Zookeeper),HMaster 與 HRegionServers 啟動時會向 Zookeeper 注冊,使 HMaster 可以隨時感知到各個 HRegionServer 的健康狀態,
Client
首先當一個請求發生時,HBase Client 使用 RPC 機制與 HMaster 和 HRegion Server 進行通信,對于管理類操作,Client 與 HMaster 進行 RPC 通信;對于資料讀寫操作,Client 與 HRegion Server 進行 RPC 通信,
HBase Client 使用 RPC 機制與 HMaster 和 HRegion Server 進行通信,但如何尋址呢?由于 Zookeeper 中存盤了 Meta 表的地址和 HMaster 的地址,所以 HBase Client 需要先到 Zookeeper 上進行尋址,
HBase Client 訪問 Zookeeper,可以根據 Meta 表獲取到 HRegion Server 地址,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/271182.html
標籤:其他