前言
身邊一直都有小伙伴在問:MongoDB到底是什么?它有到底什么特性?有什么與眾不同?在什么情況下使用MongoDB最合適?以什么樣的姿勢是最好的?難道就一定要用嗎?....說實話,這些問題都問到精髓了,也看得出來你們的急切和真切,有時候大家都比較忙,很難抽出一天的時間,坐而論道,把這些問題掰扯清楚,然后忽如睡醒,豁然開悟,當然,個人也不是專業的”布道者“,所以,通過電話、微信、QQ、釘釘或者其它的辦公聊天軟體,讓我幾句話給大家說明白,有些困難,也不切實際,所以,難免有時候,你們是曼聯藏不住的哀怨,我也是意猶未盡,現在,我把我前兩年分享的一個PPT,分享給大家,希望通過這個分享,能讓大家對MongoDB有一個相對完整的全面認識,
第一部分 概述
1.1 MongoDB 初識

1.2 MongoDB“江湖”地位
名副其實的 名列前茅、青年才俊
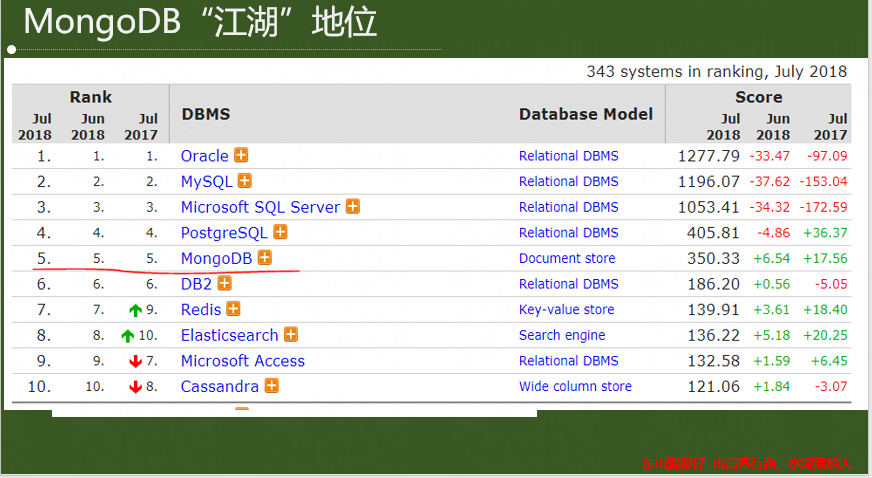
廣受好評 迷弟迷妹 眾多
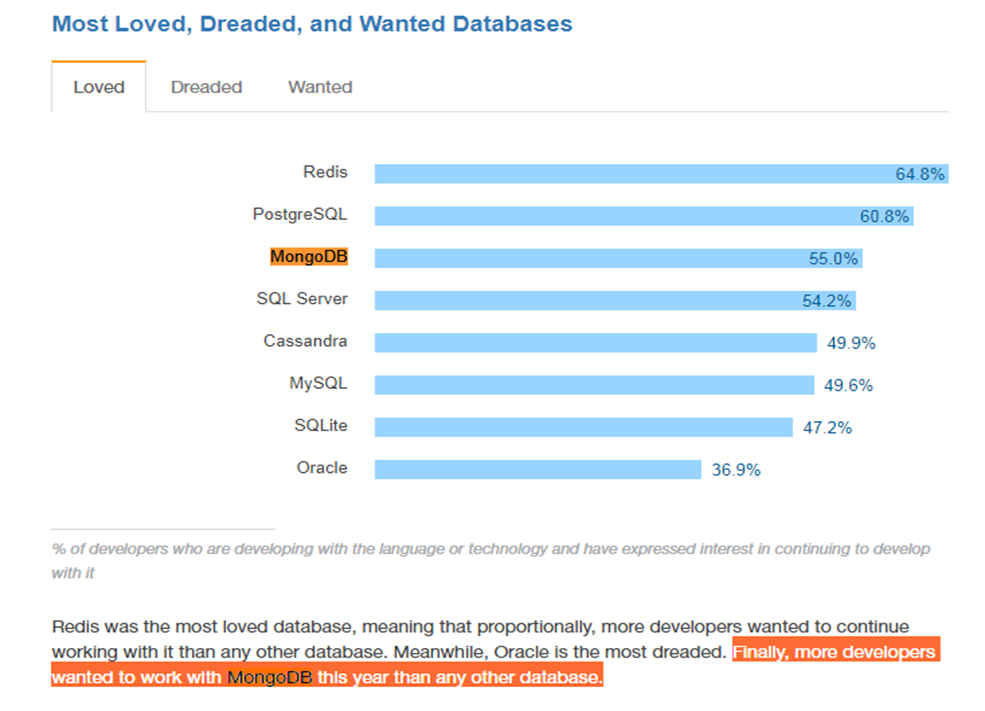
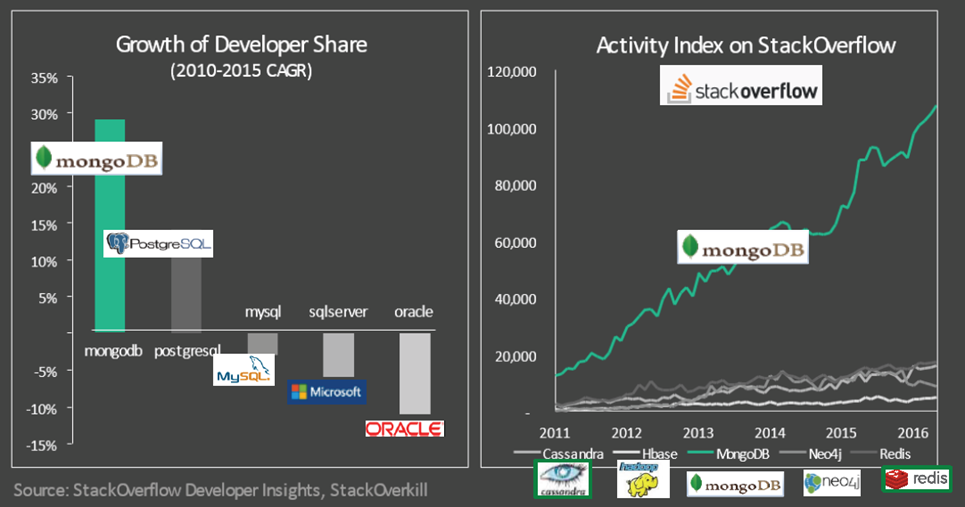
未來可期,潛力股
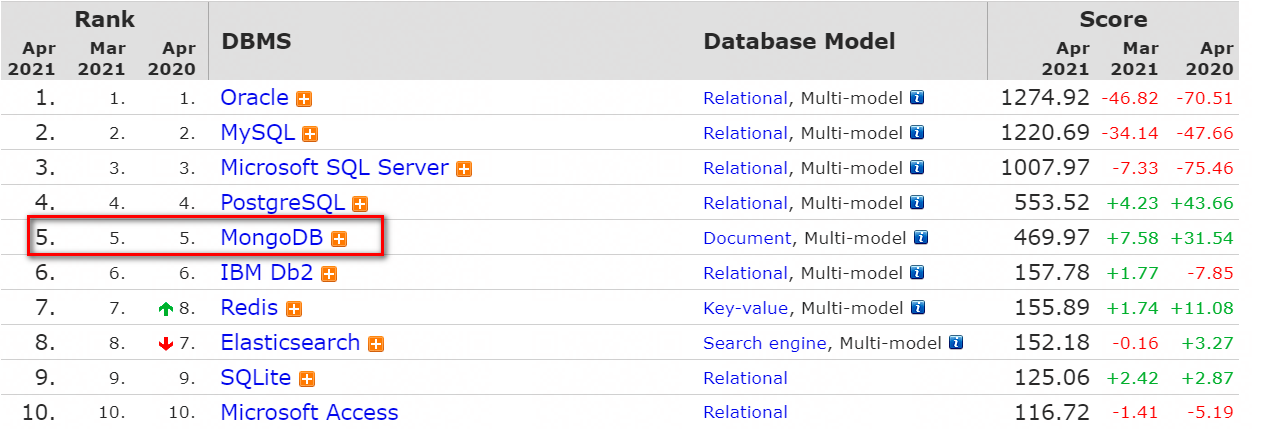
兩年已過,熱度不減,你的地位依然無可替代
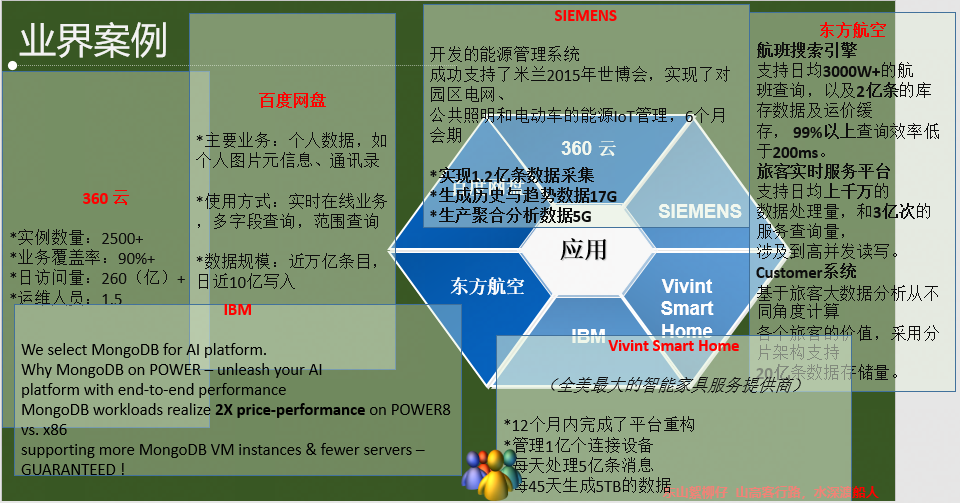
1.3 業界案例
第二部分 MongoDB 特性
2.1 特性之動態檔案模型
2.2 特性之副本集
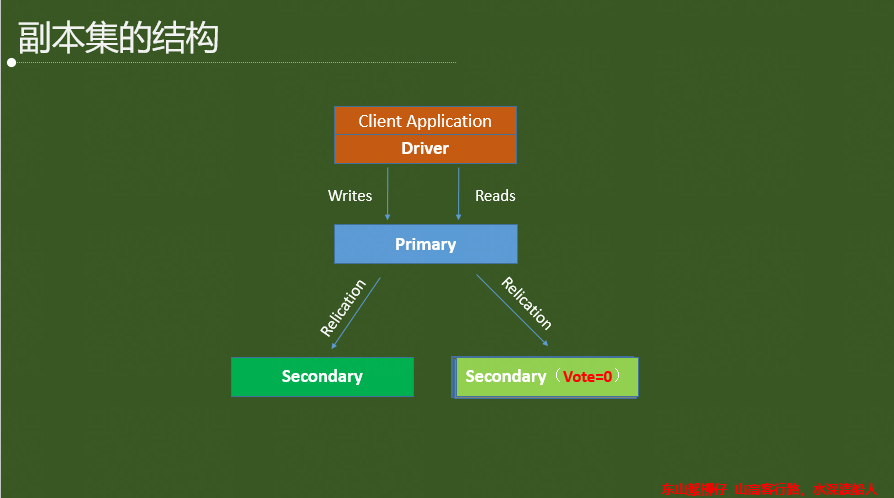
復制集的作用:
(1)高可用,防止設備(服務器、網路)故障,提供自動FailOver功能;
(2)災難恢復,當發生故障時,可以從其它節點快速恢復;
(3)功能隔離,用于分析、報表,資料挖掘,系統任務等;用于備份,
復制集成員最多50個,參與Primary選舉投票的成員最多7個,其他成員的votes屬性必須設定為0,即不參與投票,
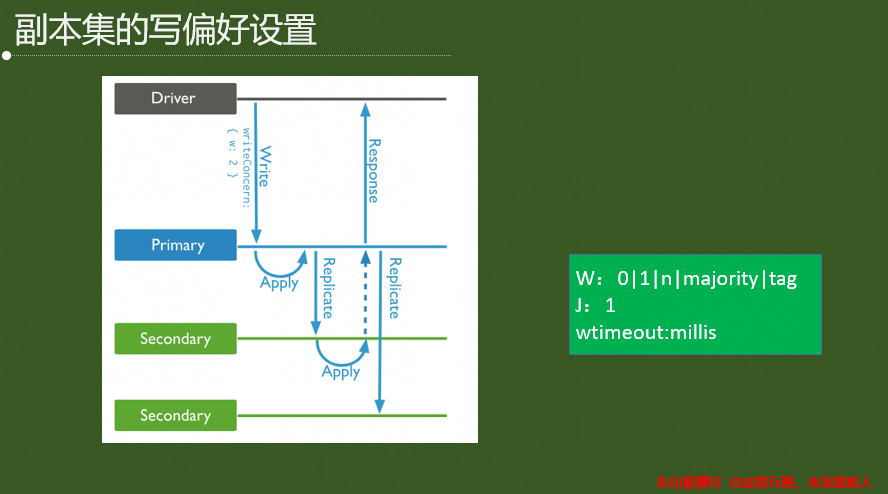
寫關注機制WriteConcert;用來指定MongoDB對寫操作的回執行為,
可在connection level 或者寫操作level指定,

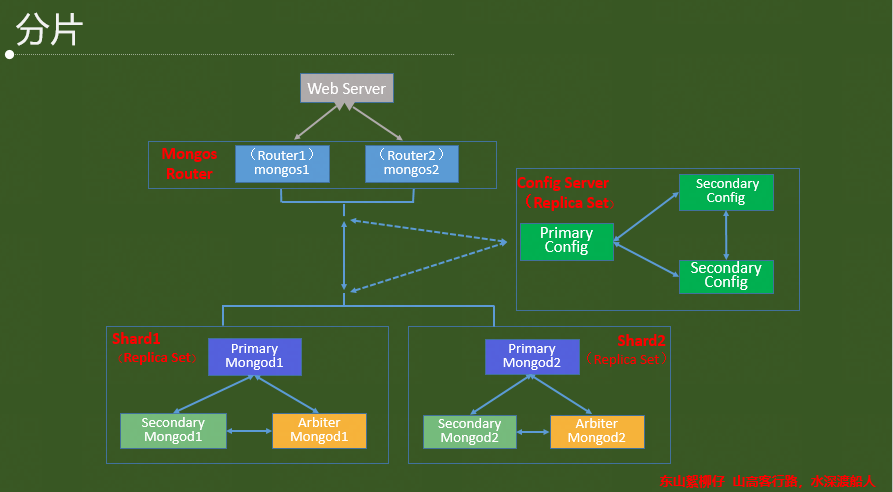
2.3 特性之分片
分片(sharding)的優勢
A.對集群進行抽象,讓集群“不可見”,分片對應用系統是透明的
MongoDB自帶了一個叫做mongos的專有路由行程,mongos就是掌握統一路口的路由器,其會將客戶端發來的請求準確無誤的路由到集群中的一個或者一組服務器上,同時會把接收到的回應拼裝起來發回到客戶端,
B.保證集群總是可讀寫
MongoDB通過多種途徑來確保集群的可用性和可靠性,將MongoDB的分片和復制集功能結合使用,在確保資料分片到多臺服務器的同時,也確保了每分資料都有相應的備份,可以確保有服務器壞掉時,其他的從庫可以立即接替壞掉的部分繼續作業,
C.使集群易于擴展
當系統需要更多的空間和資源的時候,MongoDB使我們可以按需方便的擴充系統容量,
分片(sharding)的組件
A. Mongos
Mongos作為Sharding Cluster的訪問入口,所有的請求都由mongos來路由、分發、合并,這些動作對客戶端driver透明,用戶連接mongos就像連接mongod一樣使用,Mongos會根據請求型別及shard key將請求路由到對應的Shard,
B.Config Server
Config Server 存盤Sharding Cluster 的所有元資料,所有的元資料都存盤在config資料庫:
*保存每個分片上的chunk的資訊 * 保存chunk上的片鍵范圍,
C.Shard
Shard 存盤應用資料記錄,Chunk size 默認是64M,
(1)分片鍵決定了檔案在集群中的位置;(2)分片鍵必須有索引;(3)分片鍵大小限制在512bytes;(4)MongoDB不接受已進行collection 級分片的collection上插入無分片鍵的檔案(也不支持空值插入);(5) 一旦集合已經分片,就不可以直接修改分片鍵,
分片(sharding)的分割和遷移
分割和遷移 MongoDB底層依賴2個機制來保持集群的平衡:分割和遷移,分割是把一個大的資料塊分割為2個更小的資料塊的程序,遷移就是在分片之間移動資料塊的程序,當某些分片服務器包含的資料塊資料量大大超過其他分片服務器時就會觸發遷移的程序,這個觸發器叫做遷移回合(migration round)
| Number of Chunks Migration | Threshold |
| Less then 20 | 2 |
| 21-80 | 4 |
| Greater than 80 | 8 |
遷移作業誰來做?
自動:3.2 版本里,Mongos有個后臺的Balance任務,該任務不斷來判斷是否需要遷移,如果需要,則發送moveChunk命令到源shard上開始遷移,
手動:用戶能主動觸發資料遷移,還可以手動關停、指定運行時間視窗,
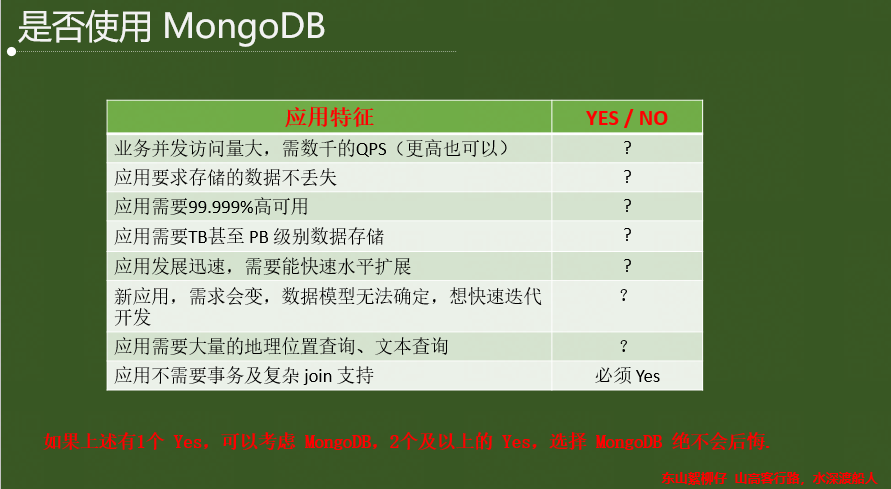
2.4 使用MongoDB的場景
第三部分 基本操作
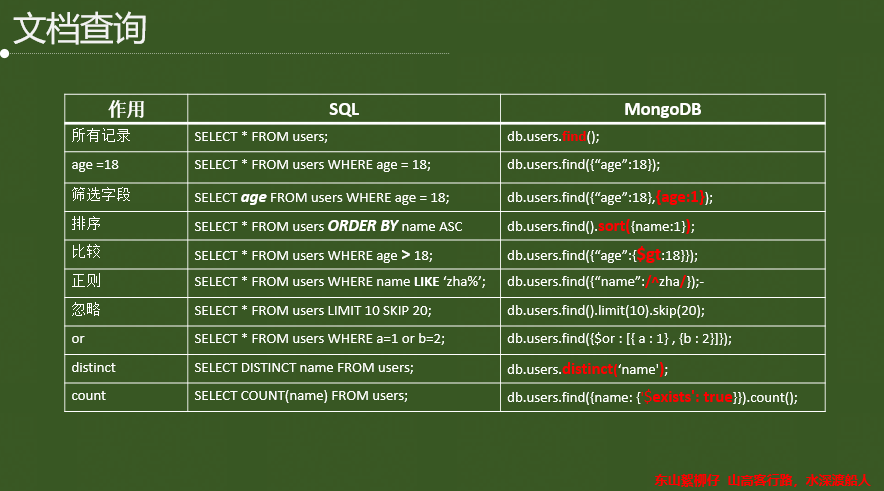
3.1 查詢操作
3.2 插入操作

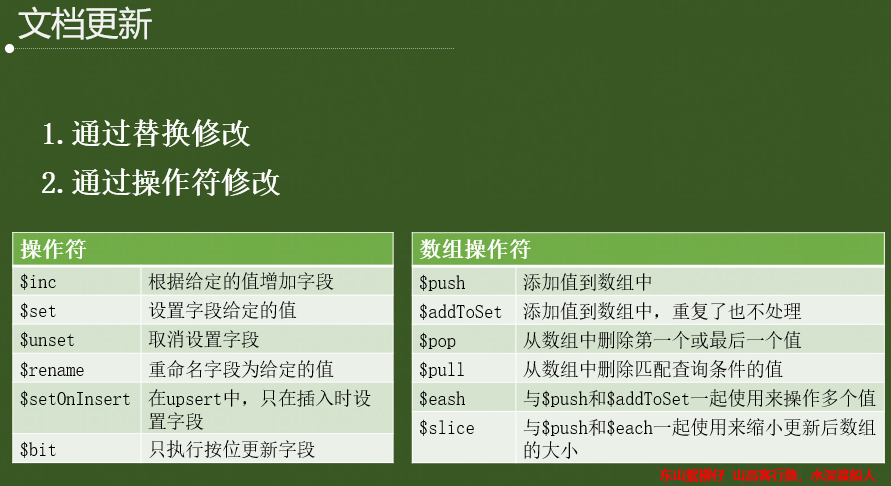
3.3 更新操作
3.4 聚合操作
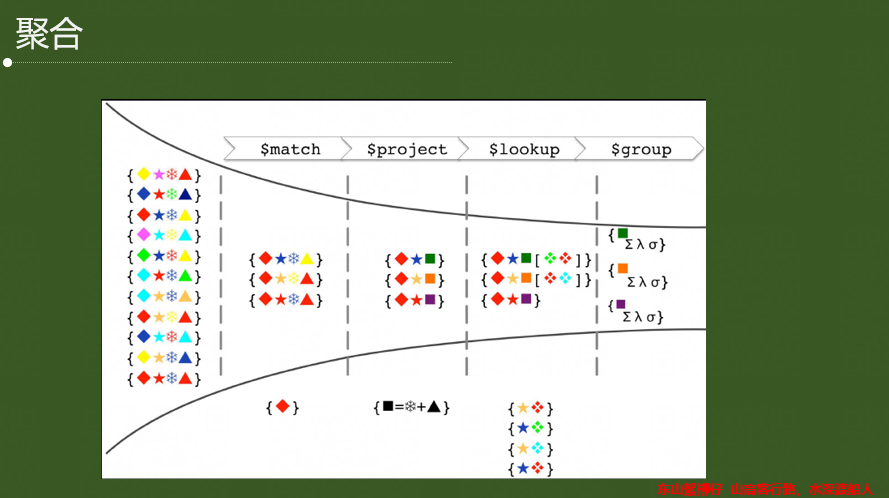
(1)MongoDB提供了兩種內置分析資料的方法:Map Reduce和Aggregation框架,聚合框架,第一在MongoDB2.2 中引入,每一次新版本發布都會更新,MongoDB 2.6 加入了許多更新,框架也相對成熟了,
(2)其他聚合功能:.count() 和.distinct(),
(3)map-reduces是MongoDB提供靈活聚合功能的首次嘗試,使用map-reduce,可以使用JavaScript定義整個處理流程,這提供了很大的靈活性,但是比聚合框架性能要低得多,此外,撰寫map-reduce的程序相對復雜,比聚合框架更加難以理解,
(4)雖然map-reduce提供了JavaScript的靈活性,但是它限制了必須是單執行緒和解釋性的模式,聚合框架是作為原生C++和多執行緒模式執行的,雖然map-reduce沒有被淘汰,但是未來的改進都會在集合框架上進行的,
第四部分 性能優化
4.1 性能診斷

4.2 性能優化之模式設計
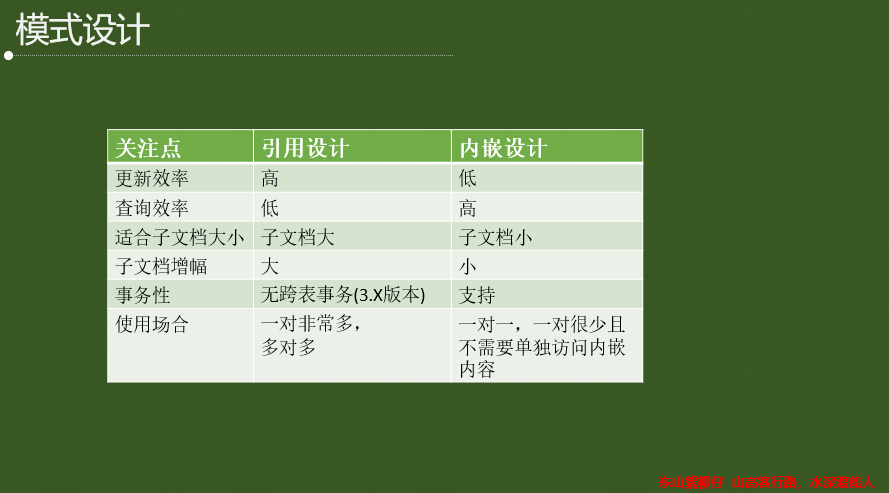
(1)業務驅動,而非資料驅動;
(2)不要按照關系型來設計表結構,建議更多使用內嵌方式;
(3)資料庫集合(collection)的數量不宜太多;
(4)資料冗余是可以接受的,
4.3 性能優化之索引設計

(1)重復率越低越適合做索引;狀態、性別等不適合建立索引;
(2)對于包含多個鍵的查詢,創建包含這些鍵的復合索引是個不錯的解決方案,復合索引的鍵值順序很重要,理解索引最左前綴原則;
(3)有添加盡量匹配覆寫索引;
(4)稀疏索引:不存盤Null資訊的索引,(3.2以上才有,不能當做分片的片鍵);區域索引(稀疏索引進化版);
(5)后臺創建索引;
(6)文本索引一個重要的不同是一個集合只有一個文本索引;
(7)文字搜索索引提供的功能快速單詞搜素的索引、匹配精確欄位、使用特定單詞或者句子排序檔案、支持多語言、基于匹配度對查詢結果打分,
IT打工人,碼字不易,轉載分享請注明出處,謝謝配合!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/271184.html
標籤:其他