SparkStreaming 連接Flume的兩種方式分別為:Push(推)和Pull(拉)的方式實作,以Spark Streaming的角度來看,Push方式屬于推送(由Flume向Spark推送資料);而Pull屬于拉取(Spark 拉取 Flume的輸出資料);
Flume向SparkStreaming推送資料沒有研究明白,有大佬指點一下嗎?
萬分感謝!
1.Spark拉取Flume資料:
匯入兩個jar包到flume/lib下
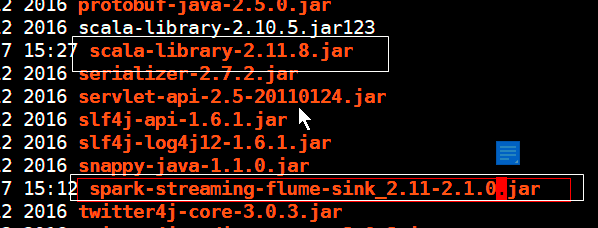
否則拋出這兩個例外:
org.apache.flume.FlumeException: Unable to load sink type: org.apache.spark.streaming.flume.sink.SparkSink, class: org.apache.spark.streaming.flume.sink.SparkSink
java.lang.IllegalStateException: begin() called when transaction is OPEN!
2.撰寫flume 作業檔案:
a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type=spooldir a1.sources.r1.spoolDir=/home/zhuzhu/apps/flumeSpooding a1.sources.r1.fileHeader=true # Describe the sink a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink # 當前主機埠 a1.sinks.k1.hostname = 192.168.137.88 a1.sinks.k1.port = 9999 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
3.撰寫SparkStreaming程式:
package day02
import java.net.InetSocketAddress
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @ClassName: StreamingFlume
* @Description TODO 實時監控flume,統計flume資料產生,是Spark
* @Author: Charon
* @Date: 2021/4/7 13:19
* @Version 1.0
**/
object StreamingFlume {
def main(args: Array[String]): Unit = {
//1.創建SparkConf物件
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamingFlume")
//2.創建SparkContext物件
val sc = new SparkContext(conf)
//設定日志輸出格式,只列印例外日志,在這里設定沒有用
//sc.setLogLevel("WARN")
//3.創建StreamingContext,Seconds(5):輪詢機制,多久執行一次
val ssc = new StreamingContext(sc, Seconds(5))
//4.定義一個flume集合,可以接受多個flume資料,多個用,隔開需要new
val addresses = Seq(new InetSocketAddress("127.0.0.1", 5555))
//5.獲取flume中的資料,
val stream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc, addresses, StorageLevel.MEMORY_AND_DISK_2)
// 6.截取flume資料:{"header":xxxxx "body":xxxxxx}
val lineDstream: DStream[String] = stream.map(x => new String(x.event.getBody.array()))
lineDstream.flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
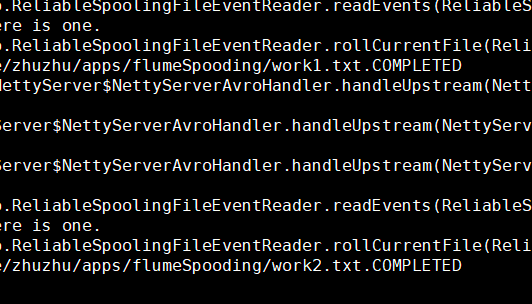
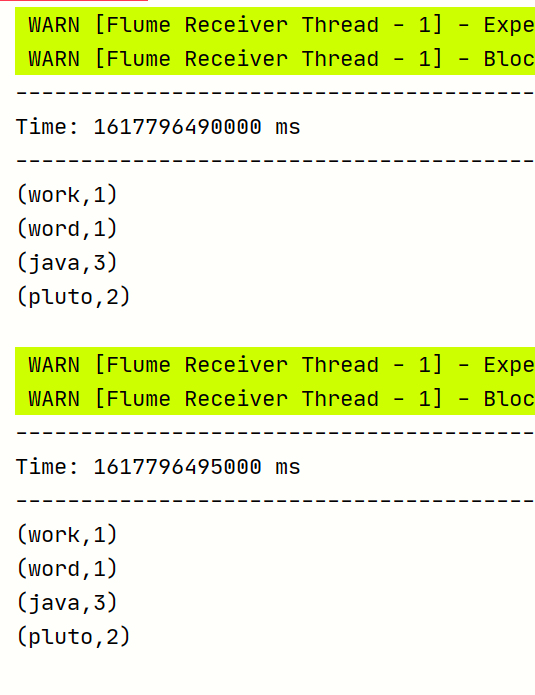
4,開啟flume監控檔案,開啟SparkStreaming程式:
向指定目錄上傳檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/273565.html
標籤:大數據