1.概述
在資料庫設計程序中,用戶可能會經常遇到這種問題:是否應該把所有表都按照第三范式來設計?表里面的欄位到底改設定為多大長度合適?這些問題雖然很小,但是如果設計不當則可能會給將來的應用帶來很多的性能問題,本章中將介紹MySQL中一些資料庫物件的優化方法,其中一些方法不僅僅適用于MySQL,也適用于其他型別的資料庫管理系統,
2.優化表的資料型別
表需要使用任何的資料型別,是需要根據應用程式來判斷的,雖然應用程式設計的時候需要考慮欄位的長度留有一定的冗余,但是不推薦讓很多欄位都留有大量的冗余,這樣即浪費磁盤存盤空間,同時在應用程式操作時也浪費物理記憶體,在MySQL中,可以使用函式PROCEDURE ANALYSE()對當前應用的表進行分析,該函式可以對資料表中列的資料型別提出優化建議,用戶可以根據應用的實際情況酌情考慮是否實施優化,以下是函式PROCEDURE ANALYSE()的使用方法:
SELECT * FROM tbl_name PROCEDURE ANALYSE(); SELECT * FROM tbl_name PROCEDURE ANALYSE(16,256);
但是我在8.0以上版本的MySQL上執行這條陳述句是報錯的,具體是8.0版本不支持還是改變語法,這邊就暫時不深究了,有空再查官網資料了解下,
3.通過拆分提高表的訪問效率
這里所說的“拆分”,是指對資料表進行拆分,如果針對MyISAM型別的表進行,那么有兩種拆分方法,
●第一種方法是垂直拆分,即把主鍵和一些列放到一個表,然后把主鍵和另外的列放到另一個表中,
優點:如果一個表中某些列常用,而另外一些列不常用,則可以采用垂直拆分,另外垂直拆分可以使得資料行變小,一個資料頁就能存放更多的資料,在查詢時就會減少I/O次數,
缺點:需要管理冗余列,查詢所有資料需要聯合(JOIN)操作,
●第二種方法是水平拆分,即根據一列或多列資料的值把資料行放到兩個獨立的表中,水平拆分通常在以下幾種情況下使用:
◎表很大,分割后可以降低在查詢時需要讀的資料和索引的頁數,同時也降低了索引的層數,提高查詢速度,
◎表中的資料本來就有獨立性,例如,表中分別記錄各個地區的資料或不同時期的資料,特別是有些資料常用,而另外一些資料不常用,
◎需要把資料存放到多個介質上,例如,移動電話的賬單表就可以分成兩個表或多個表,最近3個月的賬單資料存在一個表中,3個月前的歷史賬單存放在另外一個表中,超過1年的歷史賬單可以存盤到單獨的存盤介質上,這種拆分是最常使用的水平拆分方法,
注:水平拆分會給應用系統增加復雜度,它通常在查詢時需要多個表名,查詢所有資料需要UNION操作,在許多資料庫應用中,這種復雜性會超過它帶來的優點,因為只要索引關鍵字不大,則在索參考于查詢時,表中增加2至3倍資料量,查詢時也就增加讀一個索引層的磁盤次數,所以水平拆分要考慮資料量的增長速度,根據實際情況決定是否需要對表進行水平拆分,
4.逆規范化
●資料庫設計時要滿足規范化這個道理大家都非常清楚,但是否資料的規范化程度越高越好呢?這還是由實際需求來決定,因為規范化越高,那么產生的關系就越多,關系過多的直接結果就是導致表之間的連接操作越頻繁,而表之間的連接操作是性能較低的操作,直接影響到查詢的速度,所以對于查詢較多的應用程式就需要根據實際情況運用逆規范化對資料進行設計,通過逆規范化來提高查詢的性能,
例如,一般電商平臺后臺的庫存串列都會包含商家名稱等資訊,方便管理人員查看,假設商家ID、名字和其他屬性都存放在一個商家資訊表A中,而庫存型號、品牌、庫存量、商家ID和其他屬性都存放在一個庫存資訊表B中,那么我們在庫存串列中要顯示商家名稱等資訊時,就必須要在資料庫中進行表連接,因為庫存資訊表B中并不包含商家資訊表A的商家名稱等資訊,所以必須通過關聯A表把資料取過來,如果在資料庫設計時就考慮到這一點,就可以在B表增加一個冗余欄位存放商家名字資料,這樣在查詢庫存串列時就不用再做表關聯了,這樣也可以使查詢有更好的性能,
●反規范的好處是降低連接操作的需求、降低外鍵和索引的數目,還可能減少表的數目,相應帶來的問題是可能出現資料的完整性問題,加快查詢速度,但會降低修改速度,因此決定做反規范時,一定要權衡利弊,仔細分析應用程式的資料存取需求和實際的性能特點,好的索引和其他方法經常能夠解決性能問題,而不必采用反規范這種方法,
●在進行反規范操作之前,要充分考慮資料的存取需求、常用表的大小、一些特殊的計算(例如合計)、資料的物理存盤位置等,常用的反規范技術有增加冗余列、增加派生列、重新組表和分割表,
◎增加冗余列:指在多個表中具有相同的列,它常用來在查詢時避免連接操作,
◎增加派生列:指增加的列來自其他表中的資料,由其他表中的資料經過計算生成,增加的派生列其作用是在查詢時減少連接操作,避免使用集函式,
◎重新組表:指如果許多用戶需要查看兩個表連接出來的結果資料,則把這兩個表重新組成一個表來減少連接而提高性能,
◎分割表:可以參見3小節“通過拆分提高表的訪問效率”的內容,
●另外,逆規范技術需要維護資料的完整性,無論使用何種反規范技術,都需要一定的管理來維護資料的完整性,常用的方法是批處理維護、應用程式邏輯和觸發器,
◎批處理維護是指對復制列或派生列的修改積累一定的時間后,運行一批處理作業或存盤程序對復制或派生列進行修改,這只能在對實時性要求不高的情況下使用,
◎資料的完整性也可由應用程式邏輯來實作,這就要求必須在同一事務中對所有涉及的表進行增、刪、改操作,用應用程式邏輯來實作資料的完整性風險較大,因為同一邏輯必須在所有的應用程式中使用和維護,容易遺漏,特別是在需求變化時,不易于維護,
◎另一種方式就是使用觸發器,對資料的任何修改立即觸發對復制列或派生列的相應修改,觸發器是實時的,而且相應的處理邏輯只在一個地方出現,易于維護,一般來說,是解決這類問題比較好的辦法,
5.使用中間表提高統計查詢速度
對于資料量較大的表,在其上進行統計查詢通常會效率很低,并且還要考慮統計查詢是否會對在線的應用程式產生負面影響,通常在這種情況下,使用中間表可以提高統計查詢的效率,下面通過對goods_stock庫存表的統計來介紹中間表的使用,goods_stock表記錄了每天庫存匯入記錄,表結構如下:
DESC goods_stock;
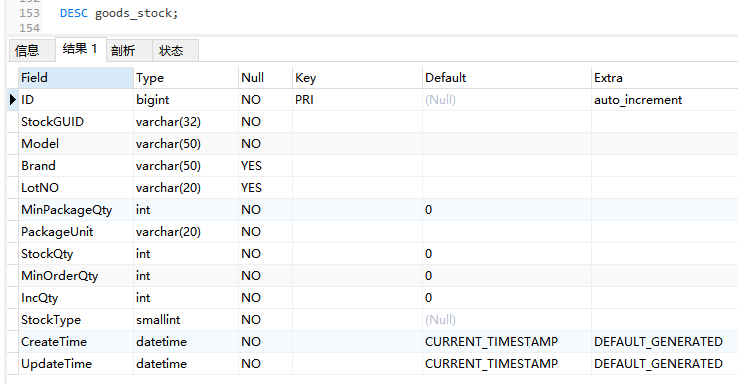
由于每天都會產生大量的庫存匯入記錄,所以goods_stock表的資料量很大,導致分頁查詢庫存匯入資料很慢: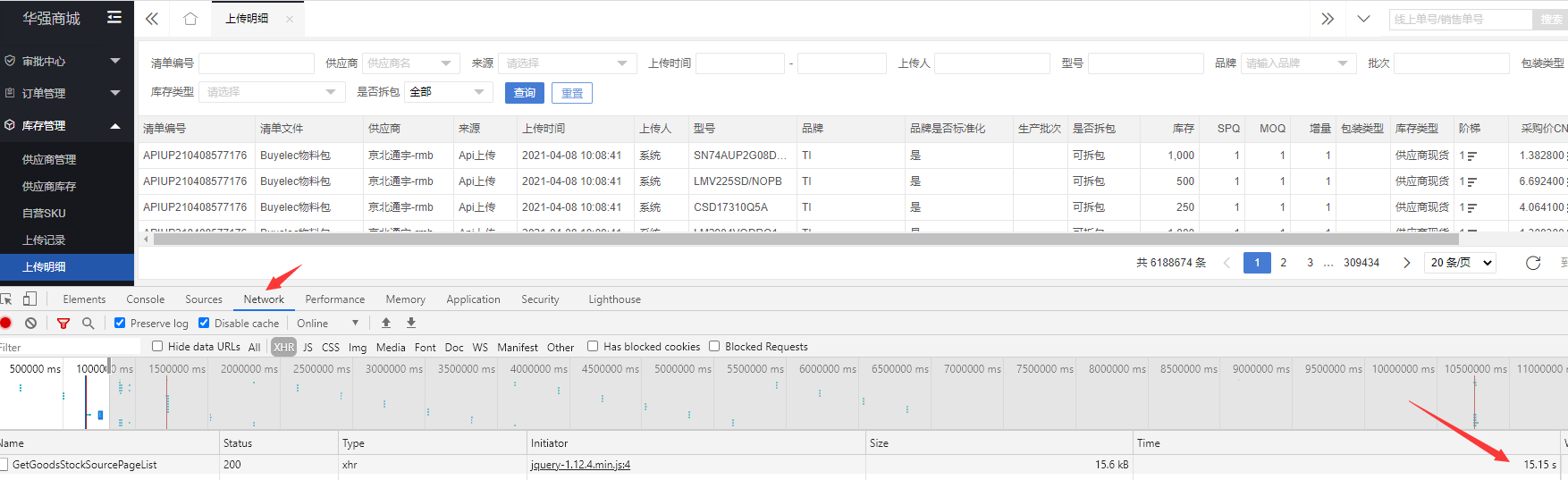
現在業務部門有一具體的需求:希望了解最近30天入庫總庫存量,針對這一需求我們通過兩種方法來得出業務部門想要的結果,
方法1:在goods_stock表上直接進行統計,得出想要的結果:
SELECT SUM(StockQty) AS TotalStockQty FROM goods_stock WHERE CreateTime>ADDDATE(NOW(),-30);

方法2:創建中間表tmp_goods_stock,表結構和源表結構完全相同:
CREATE TABLE `tmp_goods_stock` ( `ID` bigint NOT NULL AUTO_INCREMENT COMMENT '供應商庫存ID', `StockGUID` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '用于與子表對應', `Model` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '型號', `Brand` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT '' COMMENT '品牌,標準名稱', `LotNO` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT '' COMMENT '批次,一般用四位年份+兩位周,如:202024', `MinPackageQty` int NOT NULL DEFAULT 0 COMMENT '最小包裝量', `PackageUnit` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '包裝單位,包裝型別', `StockQty` int NOT NULL DEFAULT 0 COMMENT '庫存量,數量單位:PCS', `MinOrderQty` int NOT NULL DEFAULT 0 COMMENT '最小起訂量', `IncQty` int NOT NULL DEFAULT 0 COMMENT '增量', `StockType` smallint NOT NULL COMMENT '物料型別 10:供應商現貨 20供應商排單 30 云倉現貨', `CreateTime` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0), `UpdateTime` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0), PRIMARY KEY (`ID`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 424449 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '商品庫存資訊,供應商物料庫存' ROW_FORMAT = Dynamic;
轉移要統計的資料到中間表,然后在中間表上進行統計,得出想要的結果:
INSERT INTO tmp_goods_stock SELECT * FROM goods_stock WHERE CreateTime>ADDDATE(NOW(),-30);

SELECT SUM(StockQty) AS TotalStockQty FROM tmp_goods_stock;
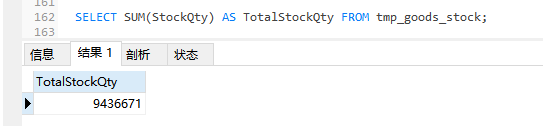
從上面的兩種實作方法上看,在中間表中做統計花費的時間很少(這里不計算轉移資料花費的時間),另外,針對業務部門想了解“希望了解最近30天入庫總庫存量”這一需求,在中間表上給出統計結果更為合適,原因是源資料表(goods_stock表)CreateTime欄位并沒有索引并且源表的資料量較大,所以在按時間進行分時段統計時效率很低,這時可以在中間表上對CreateTime欄位創建單獨的索引來提高統計查詢的速度,中間表在統計查詢中經常會用到,其優點如下:
●中間表復制源表部分資料,并且與源表相“隔離”,在中間表上做統計查詢不會對在線應用程式產生負面影響,
●中間表上可以靈活的添加索引或增加臨時用的新欄位,從而達到提高統計查詢效率和輔助統計查詢作用,
6.總結
本章節介紹了對資料庫物件的優化,資料庫物件設計的好壞是一個資料庫設計的基礎,而且一旦資料庫物件設計完畢并投入使用,將來再進行修改就比較麻煩,因此在進行資料庫設計的時候一定要盡可能地考慮周到,
參考文獻:
深入淺出MySQL大全
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/274018.html
標籤:其他
下一篇:DQL查詢資料語言(MySQL)