MongoDB概述
MongoDB是一款NoSQL型別的檔案型資料庫,
NoSQL
NoSQL是一種非關系型DMS,不需要固定的架構,可以避免joins鏈接,并且易于擴展,NoSQL資料庫用于具有龐大資料存盤需求的分布式資料存盤,NoSQL用于大資料和實時Web應用程式,
MongoDB特點
- 面向檔案
由于MongoDB是NoSQL型別的資料庫,它不是以關系型別的格式存盤資料,而是將資料存盤在檔案中,這使得MongoDB非常靈活,可以適應實際的業務環境和需求, - 臨時查詢
MongoDB支持按欄位,范圍查詢和正則運算式搜索,可以查詢回傳檔案中的特定欄位, - 索引
可以創建索引以提高MongoDB中的搜索性能,MongoDB檔案中的任何欄位都可以建立索引, - 復制
MongoDB可以提供副本集的高可用性,副本集由兩個或多個mongo資料庫實體組成,每個副本集成員可以隨時充當主副本或輔助副本的角色,主副本是與客戶端互動并執行所有讀/寫操作的主服務器,輔助副本使用內置復制維護主資料的副本,當主副本發生故障時,副本集將自動切換到輔助副本,然后它將成為主服務器, - 負載平衡
MongoDB使用分片的概念,通過在多個MongoDB實體之間拆分資料來水平擴展,MongoDB可以在多臺服務器上運行,以平衡負載或復制資料,以便在硬體出現故障時保持系統正常運行,
MongoDB存盤方式
MongoDB是檔案型資料庫,檔案以BSON格式存盤在硬碟中,
BSON是JSON的一種二進制形式的存盤格式,
注:MongoDB內部執行引擎為JS解釋器,把檔案存盤成bson結構,在查詢時,轉換為JS物件,并可以通過熟悉的JS語法來操作,
MongoDB常用術語
-
_id – 這是每個MongoDB檔案中必填的欄位,_id欄位表示MongoDB檔案中的唯一值,_id欄位類似于檔案的主鍵,如果創建的新檔案中沒有_id欄位,MongoDB將自動創建該欄位,
-
集合 – 這是MongoDB檔案的分組,集合等效于在任何其他RDMS(例如Oracle或MS SQL)中創建的表,集合存在于單個資料庫中,從介紹中可以看出,集合不強制執行任何結構,
-
游標 – 這是指向查詢結果集的指標,客戶可以遍歷游標以檢索結果,
-
資料庫 – 這是像RDMS中那樣的集合容器,其中是表的容器,每個資料庫在檔案系統上都有其自己的檔案集,MongoDB服務器可以存盤多個資料庫,
-
檔案 - MongoDB集合中的記錄基本上稱為檔案,檔案包含欄位名稱和值,
-
欄位 - 檔案中的名稱/值對,一個檔案具有零個或多個欄位,欄位類似于關系資料庫中的列,
MongoDB和RDBMS區別
| SQL術語/概念 | MongoDB術語/概念 | 解釋/說明 |
|---|---|---|
| database | database | 資料庫 |
| table | collection | 資料庫表/集合 |
| row | document | 資料記錄行/檔案 |
| column | field | 資料欄位/域 |
| index | index | 索引 |
| table joins | index | 表連接,MongoDB不支持 |
| primary key | primary key | 主鍵,MongoDB自動將_id欄位設定為主鍵 |
MongoDB聚合操作
Pipline操作
MongoDB的聚合管道(Pipeline)將MongoDB檔案在一個階段(Stage)處理完畢后將結果傳遞給下一個階段(Stage)處理,階段(Stage)操作是可以重復的,
運算式:處理輸入檔案并輸出,運算式是無狀態的,只能用于計算當前聚合管道的檔案,不能處理其他的檔案,
聚合框架中常用的Stages:
-
$project - 修改輸入檔案的結構,可用來重命名,增加或洗掉域,也可以用于創建計算結果及嵌套檔案,
-
$match - 用于過濾資料,只輸出符合條件的檔案,使用MongoDB的標準查詢操作,
-
$limit - 用來限制MongoDB聚合管道回傳的檔案數,
-
$skip - 在聚合管道中跳過指定數量的檔案,并回傳余下的檔案,
-
$unwind - 將檔案中的某一個陣列型別欄位拆分成多條,每條包含陣列中的一個值,
-
$group - 將集合中的檔案分組,可用于統計結果,
-
$sort - 將輸入檔案排序后輸出,
-
$genNear - 輸出接近某一地理位置的有序檔案,
-
$bucket - 分組(分桶)計算,
-
$facet - 多次分組計算,
-
$out - 將結果集輸出,必須是Pipeline最后一個stage,
MongoDB資料邏輯結構
MongoDB資料邏輯結構分為資料庫(database)、集合(collection)、檔案(document)三層:
- 一個mongod實體允許創建多個資料庫
- 一個資料庫中允許創建多個集合(集合相當于關系型資料庫的表)
- 一個集合則是由若干個檔案構成(檔案相當于關系型資料庫的行,是MongoDB中資料的基本單元)
資料庫
一個資料庫中可以創建多個集合,原則上我們通常把邏輯相近的集合都放在一個資料庫中,當然出于性能或者資料量的關系,也可能進行拆分,
在MongoDB中有幾個內建的資料庫:
-
admin - admin庫主要存放有資料庫賬號相關資訊
-
local - local資料庫永遠不會被復制到從節點,可以用來存盤限于本地單臺服務器的任意集合副本集的配置資訊、oplog就存盤在local庫中
(重要的資料不要存盤在local庫,因為沒有冗余副本,如果這個節點故障,存盤在local庫的資料就無法正常使用了) -
config - config資料庫用于分片集群環境,存放了分片相關的元資料資訊
-
test - MongoDB默認創建的一個測驗庫,連接mongod服務時,如果不指定連接的具體資料庫,默認就會連接到test庫
集合
集合由若干條檔案記錄構成
-
集合是schema-less的(無模式或動態模式),這意味著集合不需要在讀寫資料前創建模式就可以使用,集合中的檔案也可以擁有不同的欄位,隨時可以任意增減某個檔案的欄位,
-
在集合上可用對檔案進行增刪改查以及進行聚合操作
-
在集合上還可以對檔案中的欄位創建索引
-
除了一般的集合外,還可以創建一種叫做"定容集合"型別的集合,這種集合與一般集合主要的區別是,它可以限制集合的容量大小,在資料寫滿的時候,又可以從頭開始覆寫最開始的檔案進行回圈寫入,
-
副本集就是利用這種型別的集合作為oplog,記錄primary節點上的寫操作,并且同步到從節點重放,以實作主副節點資料復制的功能
檔案
檔案是MongoDB中資料的基本存盤單元,它以一種叫做BSON檔案的結構表示,BSON,即Binary JSON,多個鍵及其關聯的值有序地存放在其中,類似映射,散列或字典,
-
檔案中的鍵/值對是有序的,不同序則是不同檔案,并且鍵是區分大小寫的,否則也為不同檔案
-
檔案的鍵是字串,而值除了字串,還可以是int,long,double,boolean,子檔案,陣列等多種型別
-
檔案中不能有重復的鍵
-
每個檔案都有一個默認的_id值,它相當于關系型資料庫中的主鍵,這個鍵的值在同一個集合中必須是唯一的,_id鍵值默認是ObjectId型別
在插入檔案的時候,如果用戶不設定檔案的_id值的話,MongoDB會自動生成一個唯一的ObjectId值進行填充
MongoDB引擎-WiredTiger
WiredTiger(以下簡稱WT)是一個優秀的單機資料庫存盤引擎,它擁有諸多的特性,既支持BTree索引,也支持LSM Tree索引,支持行存盤和列存盤,實作ACID級別事務、支持大到4G的記錄等,
WT的產生不是因為這些特性,而是和計算機發展的現狀息息相關,
現代計算機近20年來CPU的計算能力和記憶體容量飛速發展,但磁盤的訪問速度并沒有得到相應的提高,WT就是在這樣的一個情況下研發出來,
它設計了充分利用CPU并行計算的記憶體模型的無鎖并行框架,使得WT引擎在多核CPU上的表現優于其他存盤引擎,
針對磁盤存盤特性,WT實作了一套基于BLOCK/Extent的友好的磁盤訪問演算法,使得WT在資料壓縮和磁盤I/O訪問上優勢明顯,
實作了基于snapshot技術的ACID事務,snapshot技術大大簡化了WT的事務模型,摒棄了傳統的事務鎖隔離又同時能保證事務的ACID,
WT根據現代記憶體容量特性實作了一種基于Hazard Pointer 的LRU cache模型,充分利用了記憶體容量的同時又能擁有很高的事務讀寫并發,
存盤引擎及常用資料結構
存盤引擎要做的事情無外乎是將磁盤上的資料讀到記憶體并回傳給應用,或者將應用修改的資料由記憶體寫到磁盤上,
目前大多數流行的存盤引擎是基于B-Tree或LSM(Log Strctured Merge)Tree這兩種資料結構來設計的,
B-Tree
像Oracle、SQL Server、DB2、MySQL(InnoDB)和PostgreSQL這些傳統的關系資料庫依賴的底層存盤引擎是基于B-Tree開發的,
B-Tree可以在查找資料的程序中減少磁盤I/O的次數
LSM Tree
像Cassandra、Elasticsearch (Lucene)、Google Bigtable、Apache HBase、LevelDB和RocksDB這些當前比較流行的NoSQL資料庫存盤引擎是基于LSM開發的,
插件式兼容上述兩種
當然有些資料庫采用了插件式的存盤引擎架構,實作了Server層和存盤引擎層的解耦,可以支持多種存盤引擎,如MySQL既可以支持B-Tree結構的InnoDB存盤引擎,還可以支持LSM結構的RocksDB存盤引擎,
對于MongoDB來說,也采用了插件式存盤引擎架構,底層的WiredTiger存盤引擎還可以支持B-Tree和LSM兩種結構組織資料,但MongoDB在使用WiredTiger作為存盤引擎時,目前默認配置是使用了B-Tree結構,
B-Tree資料結構
在整個B-Tree中,從上往下依次為Root結點、內部結點和葉子結點,
每個結點就是一個Page,資料以Page為單位在記憶體和磁盤間進行調度,每個Page的大小決定了相應結點的分支數量,
每條索引記錄會包含一個資料指標,指向一條資料記錄所在檔案的偏移量
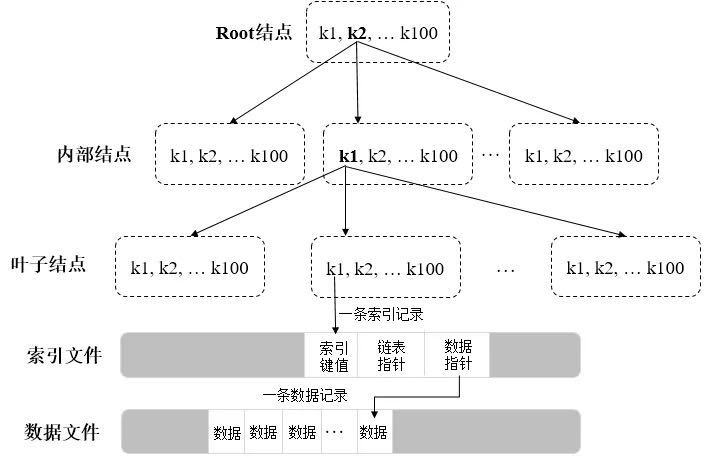
WiredTiger在磁盤上的基礎資料結構
對于WiredTiger存盤引擎來說,集合所在的資料檔案和相應的索引檔案都是按B-Tree結構來組織的,
不同之處在于資料檔案對應的B-Tree葉子結點上除了存盤鍵名外(keys),還會存盤真正的集合資料(values),所以資料檔案的存盤結構也可以認為是一種b+ Tree
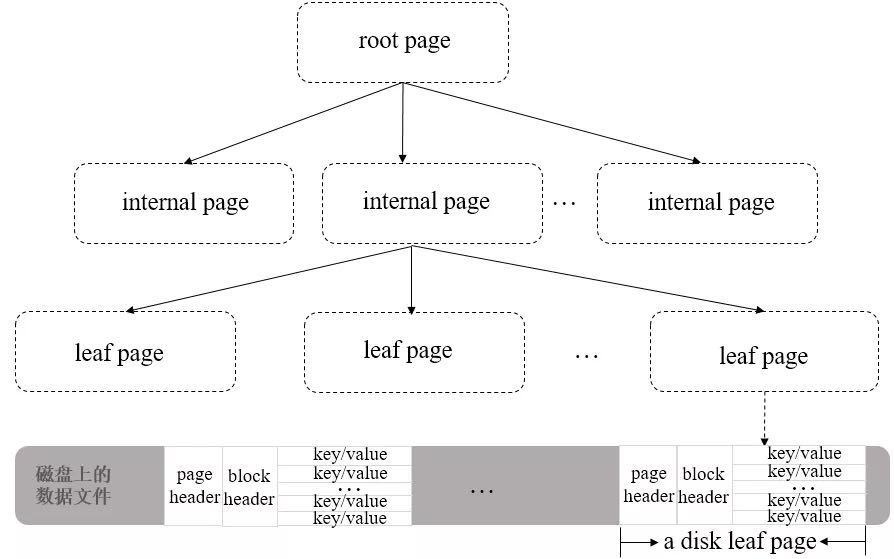
從上圖可以看到,B+ Tree中的leaf page包含一個頁頭(page header)、塊頭(block header)和真正的資料(key/value)
其中頁頭定義了頁的型別、頁中實際載荷資料的大小、頁中記錄條數等資訊;塊頭定義了此頁的checksum、塊在磁盤上的尋址位置等資訊
WiredTiger有一個塊設備管理的模塊,用來為page分配block,如果要定位某一行資料(key/value)的位置,可以先通過block的位置找到此page(相對于檔案起始位置的偏移量),再通過page找到行資料的相對位置,最后可以得到行資料相對于檔案起始位置的偏移量offsets,由于offsets是一個8位元組大小的變數,所以WiredTiger磁盤檔案的大小,其最大值可以非常大(264bit)
WiredTiger在記憶體上的基礎資料結構
WiredTiger會按需將磁盤的資料以Page為單位加載到記憶體,同時在記憶體會構造相應的B-Tree來存盤這些資料,
為了高效的支撐CRUD等操作以及將記憶體里面發生變化的資料持久化到磁盤上,WiredTiger也會在記憶體里面維護其它幾種資料結構:
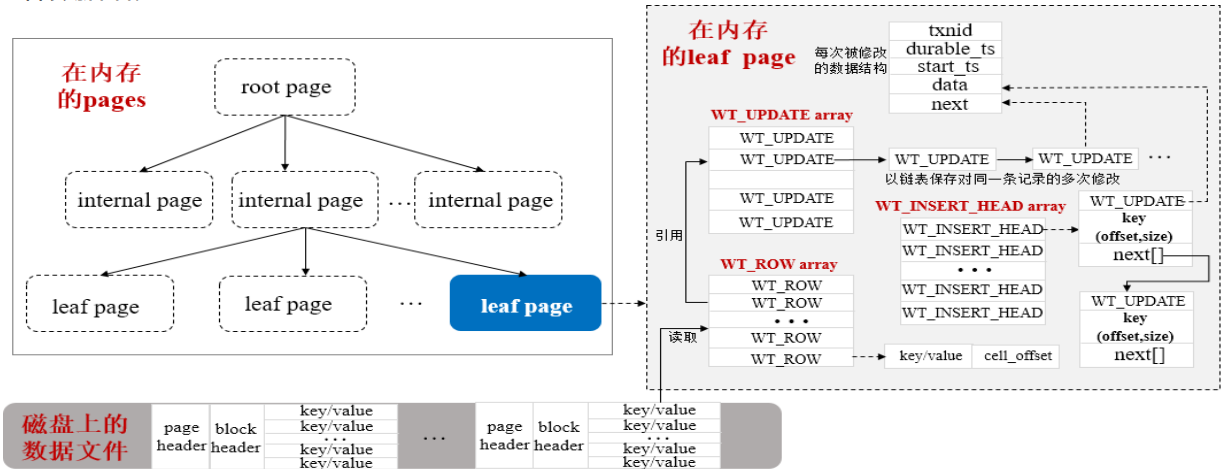
-
記憶體里面B-Tree包含三種型別的page,即rootpage、internal page和leaf page,前兩者包含指向其子頁的page index指標,不包含集合中的真正資料,leaf page包含集合中的真正資料即keys/values和指向父頁的home指標
-
記憶體上的leaf page會維護一個WT_ROW結構的陣列變數,將保存從磁盤leaf page讀取的keys/values值,每一條記錄還有一個cell_offset變數,表示這條記錄在page上的偏移量
-
記憶體上的leaf page會維護一個WT_UPDATE結構的陣列變數,每條被修改的記錄都會有一個陣列元素與之對應,如果某條記錄被多次修改,則會將所有修改值以鏈表形式保存
-
記憶體上的leaf page會維護一個WT_INSERT_HEAD結構的陣列變數,具體插入的data會保存在WT_INSERT_HEAD結構中的WT_UPDATE屬性上,且通過key屬性的offset和size可以計算出此條記錄待插入的位置;同時,為了提高尋找待插入位置的效率,每個WT_INSERT_HEAD變數以跳轉鏈表的形式構成,(通過跳轉鏈表的資料結構能夠提升插入操作的效率)
page的其它資料結構
對于一個面向行存盤的leaf page來說,包含的資料結構除了上面提到的WT_ROW(keys/values)、WT_UPDATE(修改資料)、WT_INSERT_HEAD(插入資料)外,還有如下幾種重要的資料結構:
-
WT_PAGE_MODIFY - 保存page上事務、臟資料位元組大小等與page修改相關的資訊
-
read_gen - page的read generation值作為evict page時使用,具體來說對應page在LRU佇列中的位置,決定page被evict server選中淘汰出去的先后順序
-
WT_PAGE_LOOKASIDE - page關聯的lookasidetable資料,當對一個page進行reconcile時,如果系統中還有之前的讀操作正在訪問此page上修改的資料,則會將這些資料保存到lookasidetable;當page再被讀時,可以利用lookasidetable中的資料重新構建記憶體page
-
WT_ADDR - page被成功reconciled后,對應的磁盤上塊的地址,將按這個地址將page寫到磁盤,塊是最小磁盤上檔案的最小分配單元,一個page可能有多個塊
-
checksum - page的校驗和,如果page從磁盤讀到記憶體后沒有任何修改,比較checksum可以得到相等結果,那么后續reconcile這個page時,不會將這個page的再重新寫入磁盤
Page生命周期
資料以page為單位加載到cache、cache里面又會生成各種不同型別的page及為不同型別的page分配不同大小的記憶體、eviction觸發機制和reconcile動作都發生在page上、page大小持續增加時會被分割成多個小page,所有這些操作都是圍繞一個page來完成的,
Page的典型生命周期如下:
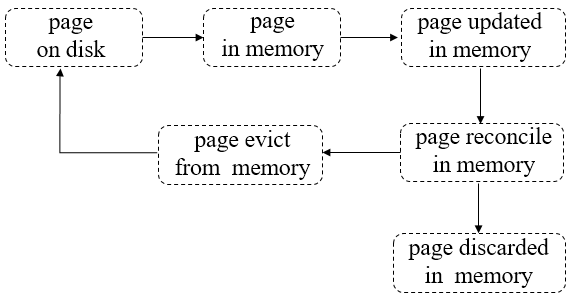
第一步:pages從磁盤讀到記憶體
第二步:pages在記憶體中被修改
第三步:被修改的臟pages在記憶體被reconcile(page被淘汰到底發生了什么),完成后將discard這些pages
第四步:pages被選中,加入淘汰佇列,等待被evict(Page被淘汰的時機)執行緒淘汰出記憶體
第五步:evict執行緒會將“干凈“的pages直接從記憶體丟棄(因為相對于磁盤page來說沒做任何修改),將經過reconcile處理后的磁盤映像寫到磁盤再丟棄“臟的”page
pages的狀態是在不斷變化的,因此,對于讀操作來說,它首先會檢查pages的狀態是否為WT_REF_MEM,然后設定一個hazard指標指向要讀的pages,如果重繪后,pages的狀態仍為WT_REF_MEM,讀操作才能繼續處理,
與此同時,evict執行緒想要淘汰pages時,它會先鎖住pages,即將pages的狀態設為WT_REF_LOCKED,然后檢查pages上是否有讀操作設定的hazard指標,如有,說明還有執行緒正在讀這個page則停止evict,重新將page的狀態設定為WT_REF_MEM;如果沒有,則pages被淘汰出去,
Page的各種狀態
針對一頁page的每一種狀態,詳細描述如下:
-
WT_REF_DISK - 初始狀態,page在磁盤上的狀態,必須被讀到記憶體后才能使用,當page被evict后,狀態也會被設定為這個
-
WT_REF_DELETED - page在磁盤上,但是已經從記憶體B-Tree上洗掉,當我們不在需要讀某個leaf page時,可以將其洗掉
-
WT_REF_LIMBO - page的映像已經被加載到記憶體,但page上還有額外的修改資料在lookasidetable上沒有被加載到記憶體
-
WT_REF_LOOKASIDE - page在磁盤上,但是在lookasidetable也有與此page相關的修改內容,在page可讀之前,也需要加載這部分內容
當對一個page進行reconcile時,如果系統中還有之前的讀操作正在訪問此page上修改的資料,則會將這些資料保存到lookasidetable;當page再被讀時,可以利用lookasidetable中的資料重新構建記憶體page, -
WT_REF_LOCKED - 當page被evict時,會將page鎖住,其它執行緒不可訪問
-
WT_REF_MEM - page已經從磁盤讀到內存,并且能正常訪問
-
WT_REF_READING - page正在被某個執行緒從磁盤讀到記憶體,其它的讀執行緒等待它被讀完,不需要重復去讀
-
WT_REF_SPLIT - 當page變得過大時,會被split,狀態設為WT_REF_SPLIT,原來指向的page不再被使用
Page的大小引數
無論將資料從磁盤讀到記憶體,還是從記憶體寫到磁盤,都是以page為單位調度的,但是在磁盤上一個page到底多大?是否是最小分割單元?以及記憶體里面各種page的大小對存盤引擎的性能是否有影響?
參考以上問題,page大小涉及的相關引數如下:
| 引數名稱 | 默認配置值 | 含義 |
|---|---|---|
| allocation_size | 4kb | 磁盤上最小分配單元 |
| memory_page_max | 5mb | 記憶體中允許的最大page值 |
| internal_page_max | 4kb | 磁盤上允許的最大internal page 值 |
| leaf_page_max | 32kb | 磁盤上允許的最大leaf page 值 |
| internal_key_max | 1/10*internal_page | internal page 上允許的最大key值 |
| leaf_key_max | 1/10*leaf_page | leaf page上允許的最大key值 |
| leaf_key_value | 1/2*leaf_page | leaf page上允許的最大value值 |
| split_pct | 75% | reconciled的page的分割百分比 |
詳細說明如下:
-
allocation_size
MongoDB磁盤檔案的最小分配單元(由WiredTiger自帶的塊管理模塊來分配),一個page的可以由一個或多個這樣的單元組成;默認值是4KB,與主機作業系統虛擬記憶體頁的大小相當,大多數場景下不需要修改這個值, -
memory_page_max
WiredTigerCache里面一個記憶體page隨著不斷插入修改等操作,允許增長達到的最大值,默認值為5MB,當一個記憶體page達到這個最大值時,將會被split成較小的記憶體pages且通過reconcile將這些pages寫到磁盤pages,一旦完成寫到磁盤,這些記憶體pages將從記憶體移除,
需要注意的是:split和reconcile這兩個動作都需要獲得page的排它鎖,導致應用程式在此page上的其它寫操作會等待,因此設定一個合理的最大值,對系統的性能也很關鍵,
如果值太大,雖然spilt和reconcile發生的機率減少,但一旦發生這樣的動作,持有排它鎖的時間會較長,導致應用程式的插入或修改操作延遲增大; 如果值太小,雖然單次持有排它鎖的時間會較短,但是會導致spilt和reconcile發生的機率增加, -
internal_page_max
磁盤上internalpage的最大值,默認為4KB,隨著reconcile進行,internalpage超過這個值時,會被split成多個pages,
這個值的大小會影響磁盤上B-Tree的深度和internalpage上key的數量,如果太大,則internalpage上的key的數量會很多,通過遍歷定位到正確leaf page的時間會增加;如果太小,則B-Tree的深度會增加,也會影響定位到正確leaf page的時間, -
leaf_page_max
磁盤上leaf page的最大值,默認為32KB,隨著reconcile進行,leaf page超過這個值時,會被split成多個pages,
這個值的大小會影響磁盤的I/O性能,因為我們在從磁盤讀取資料時,總是期望一次I/O能多讀取一點資料,所以希望把這個引數調大;但是太大,又會造成讀寫放大,因為讀出來的很多資料可能后續都用不上, -
internal_key_max
internalpage上允許的最大key值,默認大小為internalpage初始值的1/10,如果超過這個值,將會額外存盤,導致讀取key時需要額外的磁盤I/O, -
leaf_key_max
leaf page上允許的最大key值,默認大小為leaf page初始值的1/10,如果超過這個值,將會額外存盤,導致讀取key時需要額外的磁盤I/O, -
leaf_value_max
leaf page上允許的最大value值(保存真正的集合資料),默認大小為leaf page初始值的1/2,如果超過這個值,將會額外存盤,導致讀取value時需要額外的磁盤I/O, -
split_pct
記憶體里面將要被reconciled的 page大小與internal_page_max或leaf_page_max值的百分比,默認值為75%,如果記憶體里面被reconciled的page能夠裝進一個單獨的磁盤page上,則不會發生spilt,否則按照該百分比值*最大允許的page值分割新page的大小,
WiredTired Cache分配規則(Page淘汰前置原因)
WiredTired啟動的時候會向作業系統申請一部分記憶體給自己使用,這部分內容我們稱為Internal Cache,如果主機上只運行MongoDB相關的服務行程,則剩下的記憶體可以作為檔案系統的快取(File System Cache)并由作業系統負責管理
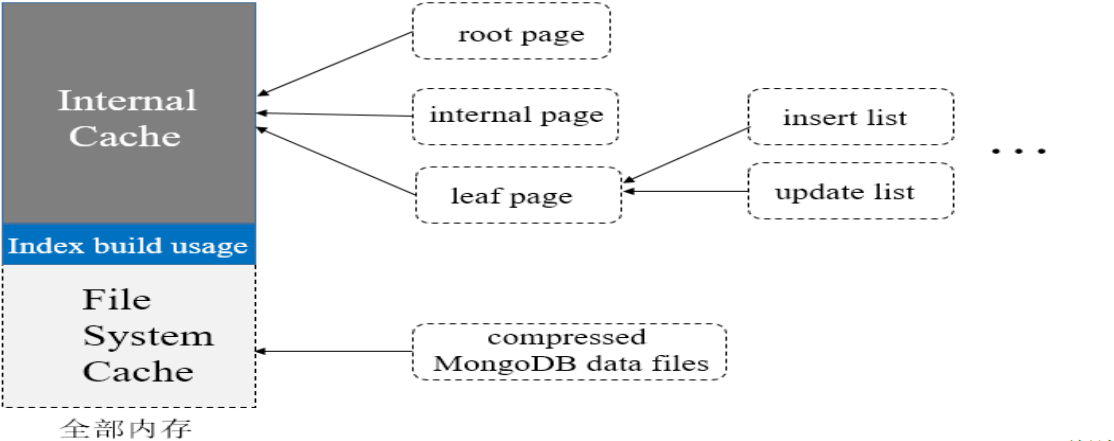
MongoDB啟動時,首先從整個主機記憶體中切一大塊出來分給WiredTiger的Internal Cache,用于構建B-Tree中的各種page以及基于這些page的增刪改查等操作,
從MongoDB3.4版本開始,默認的Internal Cache大小由下面的規則決定:比較50% of (RAM – 1 GB)和256MB的大小,取其中較大者,例如,假設主機記憶體為10GB,則Internal Cache取值為50% of (10GB – 1 GB),等于4.5GB;
如果主機記憶體為1.2GB,則Internal Cache取值為256MB,
然后,會從主機記憶體再額外劃一小塊給MongoDB創建索引專用,默認最大值為500MB,這個規則適用于所有索引的構建,包括多個索引同時構建時,
最后,會將主機剩余的記憶體(排除其它行程的使用)作為檔案系統快取,供MongoDB使用,這樣MongoDB可將壓縮的磁盤檔案也快取到記憶體中,從而減少磁盤I/O,
為了節省磁盤空間,集合和索引在磁盤上的資料是被壓縮的,默認情況下集合采取的是塊壓縮演算法,索引采取的是前綴壓縮演算法,因此,同一份資料在磁盤、檔案系統快取和Internal Cache三個位置的格式是不一樣的,如下描述:
-
所有資料在File System Cache中的格式和在磁盤上的格式是一致的,將資料先加載到檔案系統快取,不但可以減少磁盤I/O次數,還能減少記憶體的占用;
-
索引資料加載到WiredTiger的Internal Cache后,格式與磁盤上的格式不一樣,但仍能利用其前綴壓縮的特性(即去掉索引欄位上重復的前綴)減少對記憶體的占用;
-
集合資料加載到WiredTiger的Internal Cache后,其資料必須解壓后才能被后續各種操作使用,因此格式與磁盤上和File System Cache都不一樣,
Page被淘汰的時機-Page淘汰機制(Page eviction)
當cache里面的"臟頁"達到一定比例或cache使用量達到一定比例時就會觸發相應的evict page執行緒來將pages(包含干凈的pages和臟pages)按一定的演算法(LRU佇列)淘汰出去,以便騰挪出記憶體空間,保障后面新的插入或修改等操作,
| 引數名稱 | 默認配置值 | 含義 |
|---|---|---|
| eviction_target | 80% | 當cache的使用量達到80%時觸發work thread 淘汰page |
| eviction_trigger | 90% | 當cache的使用量達到90%時觸發application thread 和 work thread 淘汰page |
| eviction_dirty_target | 5% | 當臟資料所占cache比例達到5%時觸發work thread 淘汰 page |
| eviction_dirty_trigger | 20% | 當臟資料所占cache比例達到20%時觸發applicationthread和 work thread 淘汰page |
第一種情況:當cache的使用量占比達到引數eviction_ target設定值時(默認為80%),會觸發后臺執行緒執行page eviction,此時應用執行緒未阻塞,讀寫操作仍在正常進行;
如果使用量繼續增長達到eviction_trigger引數設定值時(默認為90%),應用執行緒支撐的讀寫操作等請求將被阻塞,應用執行緒也參與到頁面的淘汰中,加速淘汰記憶體中pages,
第二種情況:當cache里面的“臟資料”達到引數eviction_dirty_target設定值時(默認為5%),會觸發后臺執行緒執行page eviction,此時應用執行緒未阻塞,讀寫操作仍在正常進行;
如果“臟資料”繼續增長達到引數eviction_dirty_trigger設定值(默認為20%),同時會觸發應用執行緒來執行page eviction,應用執行緒支撐的讀寫操作等請求將被阻塞,
還有一種特性情況:當在page上不斷進行插入或更新時,如果頁上內容占用記憶體空間的大小大于系統設定的最大值(memory_page_max),則會強制觸發page eviction動作,
先通過將此大的page拆分為多個小的page,再通過reconcile將這些小的pages保存到磁盤上,一旦reconcile寫入磁盤完成,這些pages就能從cache中淘汰出去,從而為后面更多的寫入操作騰出空間,
默認情況下WiredTiger只使用一個后臺執行緒來完成page eviction,為了提升eviction的性能,我們可以通過引數threads_min和threads_max來設定evict server啟動的后臺執行緒數,
通過設定合理值,加速頁面淘汰,避免淘汰不及時導致應用執行緒也被迫加入到淘汰任務中來,造成應用執行緒對其它正常請求操作的阻塞,
淘汰一個page時,會先鎖住這個page,再檢查這個page上是否有其它執行緒還在使用(判斷是否有hazard point指標指向它),如有則不會evict這個page,
page被淘汰到底發生了什么(Page reconcile)
資料從磁盤page加載到記憶體后被查詢和修改,被修改的資料和新插入的資料也需要從記憶體寫到磁盤進行保存
WiredTiger實作了一個叫reconcile模塊來完成將記憶體里面的修改的資料生成相應磁盤映像(與磁盤上的page格式匹配),然后再將這些磁盤映像寫到磁盤上,
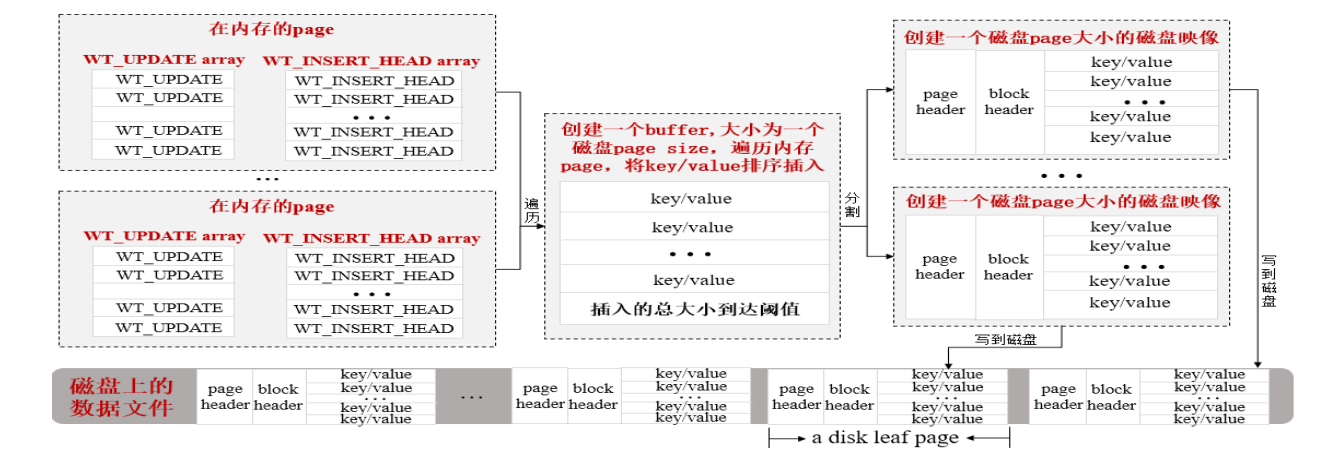
checkpoint原理
Checkpoint主要有兩個目的
一是將記憶體里面發生修改的資料寫到資料檔案進行持久化保存,確保資料一致性;
二是實作資料庫在某個時刻意外發生故障,再次啟動時,縮短資料庫的恢復時間,
WiredTiger存盤引擎中的Checkpoint模塊就是來實作這個功能的,
本質上來說,checkpoint相當于一個日志,記錄了上次Checkpoint后相關資料檔案的變化
一個CheckPoint包含關鍵資訊如下圖所示:
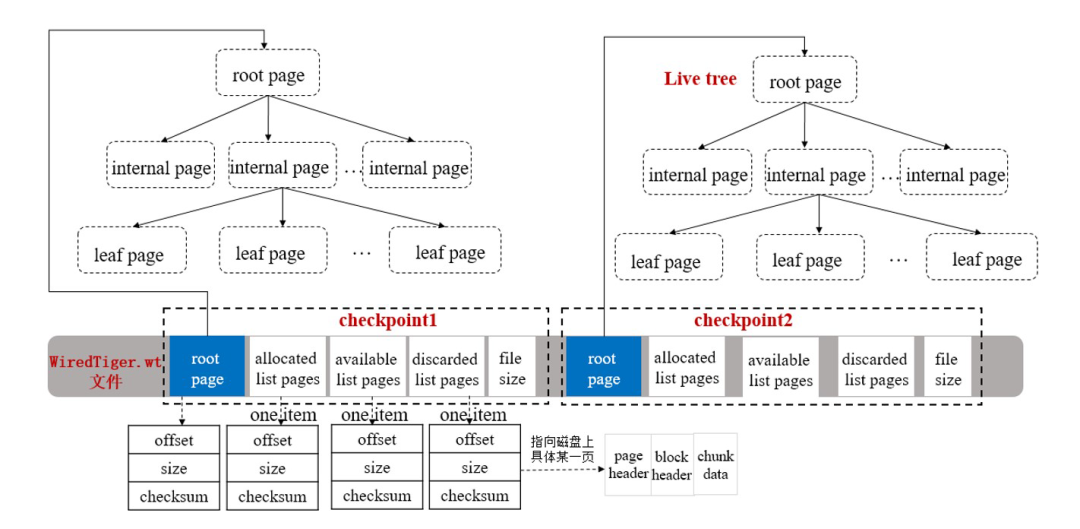
每個checkpoint包含一個root page、三個指向磁盤具體位置上pages的串列以及磁盤上檔案的大小,
詳細欄位資訊描述如下:
root page
包含rootpage的大小(size),在檔案中的位置(offset),校驗和(checksum),創建一個checkpoint時,會生成一個新root page,
allocated list pages
用于記錄最后一次checkpoint之后,在這次checkpoint執行時,由WiredTiger塊管理器新分配的pages,會記錄每個新分配page的size,offset和checksum,
discarded list pages
用于記錄最后一次checkpoint之后,在這次checkpoint執行時,丟棄的不在使用的pages,會記錄每個丟棄page的size,offset和checksum,
available list pages
在這次checkpoint執行時,所有由WiredTiger塊管理器分配但還沒有被使用的pages;當洗掉一個之前創建的checkpoint時,它所附帶的可用pages將合并到最新的這個checkpoint的可用串列上,也會記錄每個可用page的size,offset和checksum,
file size
在這次checkpoint執行后,磁盤上資料檔案的大小,
Checkpoint執行的完整流程
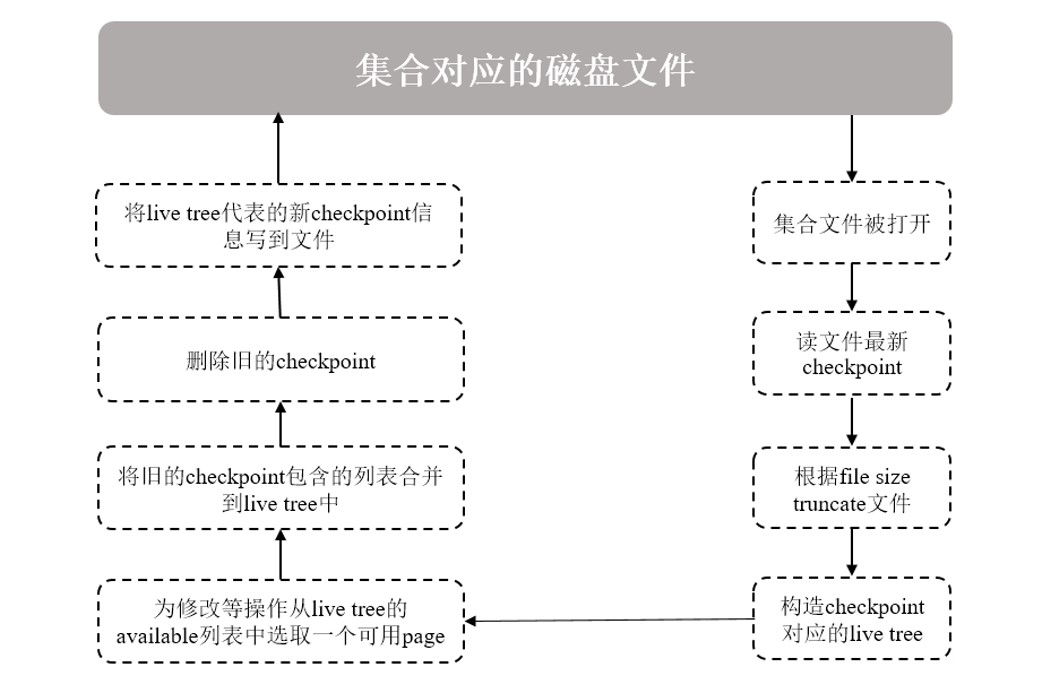
流程描述如下:
-
查詢集合資料時,會打開集合對應的資料檔案并讀取其最新checkpoint資料
-
集合檔案會按checkponit資訊指定的大小(file size)被truncate掉,所以系統發生意外故障,恢復時可能會丟失checkponit之后的資料(如果沒有開啟Journal)
-
在記憶體構造一棵包含root page的live tree,表示這是當前可以修改的checkpoint結構,用來跟蹤后面寫操作引起的檔案變化;其它歷史的checkpoint資訊只能讀,可以被洗掉
-
記憶體里面的page隨著增刪改查被修改后,寫入并需分配新的磁盤page時,將會從livetree中的available串列中選取可用的page供其使用,隨后,這個新的page被加入到checkpoint的allocated串列中
-
如果一個checkpoint被洗掉時,它所包含的allocated和discarded兩個串列資訊將被合并到最新checkpoint的對應串列上;任何不再需要的磁盤pages,也會將其參考添加到live tree的available串列中
-
當新的checkpoint生成時,會重新重繪其allocated、available、discard三個串列中的資訊,并計算此時集合檔案的大小以及rootpage的位置、大小、checksum等資訊,將這些資訊作checkpoint元資訊寫入檔案
-
生成的checkpoint默認名稱為WiredTigerCheckpoint,如果不明確指定其它名稱,則新check point將自動取代上一次生成的checkpoint
Checkpoint執行的觸發時機
觸發checkpoint執行,通常有如下幾種情況:
-
按一定時間周期:默認60s,執行一次checkpoint
-
按一定日志檔案大小:當Journal日志檔案大小達到2GB(如果已開啟),執行一次checkpoint
-
任何打開的資料檔案被修改,關閉時將自動執行一次checkpoint, 注意:checkpoint是一個相當重量級的操作,當對集合檔案執行checkpoint時,會在檔案上獲得一個排它鎖,其它需要等待此鎖的操作,可能會出現EBUSY的錯誤
WiredTired事務實作
WT在實作事務的時使用主要是使用了三個技術:snapshot(事務快照)、MVCC (多版本并發控制)和redo log(重做日志),為了實作這三個技術,它還定義了一個基于這三個技術的事務物件和全域事務管理器,
事務物件描述如下
wt_transaction{
transaction_id: 本次事務的**全域唯一的ID**,用于標示事務修改資料的版本號
snapshot_object: 當前事務開始或者操作時刻其他正在執行且并未提交的事務集合,用于事務隔離
operation_array: 本次事務中已執行的操作串列,用于事務回滾,
redo_log_buf: 操作日志緩沖區,用于事務提交后的持久化
state: 事務當前狀態
}
WT的事務快照
事務開始或者進行操作之前對整個WT引擎內部正在執行或者將要執行的事務進行一次截屏,保存當時整個引擎所有事務的狀態,確定哪些事務是對自己見的,哪些事務都自己是不可見,
WT引擎中的snapshot_oject是有一個最小執行事務snap_min、一個最大事務snap max和一個處于[snap_min, snap_max]區間之中所有正在執行的寫事務序列組成,
WT的多版本并發控制
WT中的MVCC是基于key/value中value值的鏈表,這個鏈表單元中存盤有當先版本操作的事務ID和操作修改后的值,
描述如下
wt_mvcc{
transaction_id: 本次修改事務的ID
value: 本次修改后的值
}
WT中的資料修改都是在這個鏈表中進行append操作,每次對值做修改都是append到鏈表頭上,每次讀取值的時候讀是從鏈表頭根據值對應的修改事務transaction_id和本次讀事務的snapshot來判斷是否可讀,如果不可讀,向鏈表尾方向移動,直到找到讀事務能都的資料版本,
全域事務管理器
要創建整個系統事務的快照截屏,就需要一個全域的事務管理來進行事務截屏時的參考,
wt_txn_global{
current_id: 全域寫事務ID產生種子,一直遞增
oldest_id: 系統中最早產生且還在執行的寫事務ID
transaction_array: 系統事務物件陣列,保存系統中所有的事務物件
scan_count: 正在掃描transaction_array陣列的執行緒事務數,用于建立snapshot程序的無鎖并發
}
transaction_array保存的是正在執行事務的區間的事務物件序列,在建立snapshot時,會對整個transaction_array做掃描,確定snap_min/snap_max/snap_array這三個引數和更新oldest_id,在掃描的程序中,凡是transaction_id不等于WT_TNX_NONE都認為是在執行中且有修改操作的事務,直接加入到snap_array當中,整個程序是一個無鎖操作程序,這個程序如下:
創建snapshot截屏的程序在WT引擎內部是非常頻繁,尤其是在大量自動提交型的短事務執行的情況下,由創建snapshot動作引起的CPU競爭是非常大的開銷,所以這里WT并沒有使用spin lock ,而是采用了上圖的一個無鎖并發設計,這種設計遵循了我們開始說的并發設計原則,
從WT引擎創建事務snapshot的程序中現在可以確定,snapshot的物件是有寫操作的事務,純讀事務是不會被snapshot的,因為snapshot的目的是隔離mvcc list中的記錄,通過MVCC中value的事務ID與讀事務的snapshot進行版本讀取,與讀事務本身的ID是沒有關系,在WT引擎中,開啟事務時,引擎會將一個WT_TNX_NONE( = 0)的事務ID設定給開啟的事務,當它第一次對事務進行寫時,會在資料修改前通過全域事務管理器中的current_id來分配一個全域唯一的事務ID,這個程序也是通過CPU的CAS_ADD原子操作完成的無鎖程序,
MongoDB副本集及分片集群
MongoDB副本集
為什么要引入復制集
保證資料在生產部署時的冗余和可靠性,通過在不同機器上保存副本來保證資料不會因為單點損失而丟失,能夠隨時應對資料丟失,機器損壞帶來的風險,
在MongoDB中就是復制集(replica set): 一組復制集就是一組mongodb實體掌管同一個資料集,實體可以在不同的機器上面,實體中包含一個主導,接受客戶端所有的寫入操作,其他都是副本實體,從主服務器上獲得資料并保持同步,
副本集是一組維護相同資料集合的mongod實體,副本集包含多個資料承載節點和一個可選的仲裁節點,在資料承載節點中,有且僅有一個成員為主節點,其他節點為副本節點,
主節點接收所有的寫操作,一個副本集僅有一個主節點能夠用寫關注點級別來確認寫操作,雖然在某些情況下,另一個mongod的實體也可以暫時認為自己是主節點,
復制集成員:
主節點(Primary)
包含了所有的寫操作的日志,但是副本服務器集群包含所有的主服務器資料,因此當主服務器掛掉了,就會在副本服務器上重新選取一個成為主服務器,
從節點(Seconary)
正常情況下,復制集的Seconary會參與Primary選舉(自身也可能會被選為Primary),并從Primary同步最新寫入的資料,以保證與Primary存盤相同的資料,
Secondary可以提供讀服務,增加Secondary節點可以提供復制集的讀服務能力,同時提升復制集的可用性,另外MongoDB支持對復制集的Secondary節點進行靈活的配置,以適應多種場景的需求,
仲裁節點(Arbiter)
Arbiter節點只參與投票,不能被選為Primary,并且不從Primary同步資料,
仲裁節點永遠只能是仲裁節點,但在選舉程序中主節點也許會降級成為副本節點,副本節點也可能會升級成主節點,
復制集是如何保證資料高可用的
- 選舉機制
- 故障轉移期間的回滾
選舉機制
復制集通過選舉機制來選擇主節點
如何選出Primary主節點的?
假設復制集內能夠投票的成員數量為N,則大多數為N/2 + 1,當復制集記憶體活成員數量不足大多數時,整個復制集將無法選舉出Primary,復制集將無法提供寫服務,處于只讀狀態,
在什么情況下會觸發選舉機制?
在以下的情況下會觸發選舉機制:
-
往復制集中新加入節點
-
初始化復制集
-
對復制集進行維護時,比如rs.stepDown()或者 rs.reconfig()操作時
-
從節點失聯時,比如超時(默認是10s)
異步復制及慢操作
副本節點復制主節點的oplog并異步地應用操作到它們的資料集,通過讓副本節點的資料集反映主服務器的資料集,副本集可以在一個或多個成員失敗的情況下繼續運行,
從4.2版本開始(從4.0.6開始也是可行的),副本集的副本成員會記錄oplog中應用時間超過慢操作閾值的慢操作條目,這些慢oplog資訊被記錄在從節點的診斷日志 中,其路徑位于REPL 組件的文本applied op: took ms中,這些慢日志條目僅僅依賴于慢操作閾值,它們不依賴于日志級別(無論是系統還是組件級別)、過濾級別,或者慢操作采樣比例,過濾器不會捕獲慢日志條目,
自動故障轉移
當主節點無法和集群中的其他節點通信的時間超過electionTimeoutMillis配置的期限時(默認10s),一個候選的副本節點會發起選舉來推薦自己成為新主節點,集群會嘗試完成一次新主節點的選舉并恢復正常的操作,
副本集在選舉成功前是無法處理寫操作的,如果讀請求被配置運行在副本節點上,則當主節點下線時,副本集可以繼續處理這些請求,
假設采用默認的副本配置選項,集群選擇新主節點的中間過渡時間通常不應超過12秒,這包括了將主節點標記為unavailable、發起以及完成一次選舉的時間,可以通過修改settings.electionTimeoutMillis 復制配置選項來調整這個時間期限,網路延遲等因素可能會延長完成副本集選舉所需的時間,從而影響集群在沒有主節點的情況下運行的時間,這些因素取決于實際的集群架構情況,
將electionTimeoutMillis復制配置選項從默認的10000(10秒)降低可以更快地檢測主節點故障,然而,由于諸如臨時性的網路延遲等因素,集群可能會更頻繁地發起選舉,即使主節點在其他方面是健康的,這也許會增加w : 1 級別寫操作發生回滾的可能性,
應用程式連接邏輯應該包括對自動故障轉移和后續選舉的容錯處理能力,從MongoDB 3.6開始,MongoDB驅動程式可以探測到主節點的丟失,并自動重試某些寫操作一次,提供額外的自動故障轉移和選舉的內置處理:
MongoDB 4.2兼容的驅動程式默認啟用可重試寫
MongoDB 4.0和3.6兼容的驅動程式必須通過在 連接字串中包含retryWrites=true來顯式地啟用可重試寫,
復制集中的OpLog
oplog(操作日志)是一個特殊的有上限的集合(老的日志會被overwrite),它保存所有修改資料庫中存盤的資料的操作的滾動記錄,
什么是Oplog
MongoDB在主節點上應用資料庫操作,然后將這些操作記錄到optlog中,然后從節點通過異步行程復制和應用(資料同步)這些操作,在local.oplog.rs集合中,所有復制集成員都包含oplog的一個副本用來維護資料庫的當前狀態,
MongoDB 4.4支持以小時為單位指定最小操作日志保留期,其中MongoDB僅在以下情況下洗掉操作日志條目:
-
oplog已達到配置的最大大小
-
oplog條目早于配置的小時數
復制集中的資料同步(重點)
復制集中的資料同步是為了維護共享資料集的最新副本,包括復制集的輔助成員同步或復制其他成員的資料, MongoDB使用兩種形式的資料同步:
-
初始同步(Initial Sync) - 以使用完整的資料集填充新成員, 即全量同步
-
復制(Replication) - 以將正在進行的更改應用于整個資料集, 即增量同步
初始同步(Initial Sync)
從節點當出現如下狀況時,需要先進行全量同步
-
oplog為空
-
local.replset.minvalid集合里_initialSyncFlag欄位設定為true
-
記憶體標記initialSyncRequested設定為true
這3個場景分別對應:
-
新節點加入,無任何oplog,此時需先進行initial sync
-
initial sync開始時,會主動將_initialSyncFlag欄位設定為true,正常結束后再設定為false;如果節點重啟時,發現_initialSyncFlag為true,說明上次全量同步中途失敗了,此時應該重新進行initial sync
-
當用戶發送resync命令時,initialSyncRequested會設定為true,此時會重新開始一次initial sync
Initial Sync流程
-
全量同步開始,設定minvalid集合的_initialSyncFlag
-
獲取同步源上最新oplog時間戳為t1
-
全量同步集合資料 (耗時)
-
獲取同步源上最新oplog時間戳為t2
-
重放[t1, t2]范圍內的所有oplog
-
獲取同步源上最新oplog時間戳為t3
-
重放[t2, t3]范圍內所有的oplog
-
建立集合所有索引 (耗時)
-
獲取同步源上最新oplog時間戳為t4
-
重放[t3, t4]范圍內所有的oplog
-
全量同步結束,清除minvalid集合的_initialSyncFlag
注:
- 重試流程:如果同步期間碰到一些標記為RetriableError的錯誤,則會進行重試,直到重試超過initialSyncTransientErrorRetryPeriodSeconds才會標記為永久性錯誤,這個時候,會進行切換sync source并重試整個initial sync的流程
- Oplog拉取(Oplog Fetching)
-
OplogFetcher從全量開始就啟動拉取oplog
-
全量期間將獲取到oplog快取local.temp_oplog_buffer表
-
穩態復制期間將oplog快取到OplogBuffer
-
OplogFetcher獲取失敗,重新選取同步源
復制(Replication)
initial sync結束后,接下來Secondary就會『不斷拉取主上新產生的optlog并重放』
- producer thread,這個執行緒不斷的從同步源上拉取oplog,并加入到一個BlockQueue的佇列里保存著,
- replBatcher thread,這個執行緒負責逐個從producer thread的佇列里取出oplog,并放到自己維護的佇列里,
- sync執行緒將replBatcher thread的佇列分發到默認16個replWriter執行緒,由replWriter thread來最終重放每條oplog,
問題來了,為什么一個簡單的『拉取oplog并重放』的動作要搞得這么復雜?
性能考慮,拉取oplog是單執行緒進行,如果把重放也放到拉取的執行緒里,同步勢必會很慢;所以設計上producer thread只干一件事,
為什么不將拉取的oplog直接分發給replWriter thread,而要多一個replBatcher執行緒來中轉?
oplog重放時,要保持順序性,而且遇到createCollection、dropCollection等DDL命令時,這些命令與其他的增刪改查命令是不能并行執行的,而這些控制就是由replBatcher來完成的,
優化方案(重點):
-
initial sync單執行緒復制資料,效率比較低,生產環境應該盡量避免initial sync出現,需合理配置oplog,按默認『5%的可用磁盤空間』來配置oplog在絕大部分場景下都能滿足需求,特殊的case(case1, case2)可根據實際情況設定更大的oplog,
-
新加入節點時,可以通過物理復制的方式來避免initial sync,將Primary上的dbpath拷貝到新的節點,直接啟動,這樣效率更高,
-
當Secondary上需要的oplog在同步源上已經滾掉時,Secondary的同步將無法正常進行,會進入RECOVERING的狀態,需向Secondary主動發送resyc命令重新同步,
-
生產環境,最好通過db.printSlaveReplicationInfo()來監控主備同步滯后的情況,當Secondary落后太多時,要及時調查清楚原因,
-
當Secondary同步滯后是因為主上并發寫入太高導致,(db.serverStatus().metrics.repl.buffer.sizeBytes持續接近db.serverStatus().metrics.repl.buffer.maxSizeBytes),可通過調整Secondary上replWriter并發執行緒數來提升,
副本集幫助我們解決讀請求擴展、高可用等問題,那么業務場景進一步增長,會出現以下問題:
-
存盤容量超過單機磁盤容量
-
活躍資料集超出單機記憶體容量:很多讀請求需要從磁盤讀取
-
寫入量超出單機IOPS上限
此時我們需要對MongoDB做分片集群
MongoDB分片集群
分片為應對高吞吐量與大資料量提供了方法,使用分片減少了每個分片需要處理的請求數,因此,通過水平擴展,集群可以提高自己的存盤容量和吞吐量,舉例來說,當插入一條資料時,應用只需要訪問存盤這條資料的分片.
MongoDB分片集群是對資料進行水平擴展的一種方式,
MongoDB使用分片集群支持對大資料集和高吞吐量的業務場景
MongoDB分片集群的基本架構
MongoDB分片集群包括以下組件:
- ShardServer - 每個shard(分片)包含被分片的資料集中的一個子集,每個分片可以被部署為副本集架構,(部署為副本集來保證高可用)
- mongos - mongos充當查詢路由器,作為分片集群的入口,在客戶端應用程式和分片集群之間提供介面,對請求進行路由、分發、合并(部署多個mongos來保證高可用),
- configServer - config servers存盤了分片集群的元資料和配置資訊(部署為副本集來保證高可用),
MongoDB分片集群(Sharded Cluster)通過將資料分散存盤到多個分片(Shard)上,來實作高可擴展性,實作分片集群時,MongoDB引入Config Server來存盤集群的元資料,引入mongos作為應用訪問的入口,mongos從Config Server讀取路由資訊,并將請求路由到后端對應的Shard上,
注:
-
用戶訪問mongos跟訪問單個mongod類似
-
所有mongos是對等關系,用戶訪問分片集群可通過任意一個或多個mongos
-
mongos本身是無狀態的,可任意擴展,集群的服務能力為[Shard服務能力之和]與[mongos服務能力之和]的最小值
-
訪問分片集群時,最好將應用負載均衡的分散到多個mongos上
MongoDB分片集群連接Connection String
Connection String URI: mongodb://[username:password@][host1:port1],[host2:port2],...,[hostN:portN]/[database][?options]
-
mongodb --- // 前綴,代表這是一個Connection String
-
username:password@ --- 如果啟用了鑒權,需要指定用戶密碼
-
hostX:portX --- 多個 mongos 的地址串列
-
/database --- 鑒權時,用戶帳號所屬的資料庫
-
?options --- 指定額外的連接選項
通過Java連接的demo:
MongoClientURI connectionString = new MongoClientURI("mongodb://:****@s-m5e80a9241323604.mongodb.rds.aliyuncs.com:3717,s-m5e053215007f404.mongodb.rds.aliyuncs.com:3717/admin"); // ****替換為root密碼
MongoClient client = new MongoClient(connectionString);
MongoDatabase database = client.getDatabase("mydb");
MongoCollection collection = database.getCollection("mycoll");
在訪問分片集群時,請務必確保 MongoDB URI 里包含2個及以上的mongos地址,來實作負載均衡及高可用
常用連接引數(options):
-
readPreference=secondaryPreferred - 實作讀寫分離,讀請求優先到Secondary節點,從而實作讀寫分離的功能,
-
maxPoolSize=xx - 限制連接數,將客戶端連接池限制在xx以內,
-
w=majority - 保證資料寫入到大多數節點后才回傳,
集合的資料分布
Primary Shard
默認情況下,每個DataBase的集合都是未分片的,存盤在一個固定的Shard上,稱為Primary Shard
當創建一個新的DataBase時,系統會根據各個Shard目前存盤的資料量,選擇一個資料量最小的Shard作為新Database的Primary Shard
MongoDB將資料進行分片支持集合級別,已經被分片的集合被切分成多份保存到Shard上,
集合分片鍵與Chunk管理
chunk
在一個shard server內部,MongoDB還是會把資料分為chunks,每個chunk代表這個shard server內部一部分資料,
chunk的產生,會有以下兩個用途:
- Splitting - 當一個chunk的大小超過配置中的chunk size時,MongoDB的后臺行程會把這個chunk切分成更小的chunk,從而避免chunk過大的情況
- Balancing - 在MongoDB中,balancer是一個后臺行程,負責chunk的遷移,從而均衡各個shard server的負載,系統初始1個chunk,chunk size默認值64M,生產庫上選擇適合業務的chunk size是最好的,MongoDB會自動拆分和遷移chunks,
MongoDB基于ShardKey將Collection拆分為多個子集,每個子集稱為一個chunk
ShardedCollection的資料按照ShardKey劃分為minKey~maxKey的區間
每個chunk有自己負責的一個區間(前閉后開)
存盤ShardedCollection的Shard上有該Collection的一個或多個chunk
chunk分裂
chunk的分裂和遷移非常消耗IO資源;在插入和更新,讀資料不會分裂,
-
伴隨著資料的寫入,當chunk增長到指定大小(默認64MB)時,MongoDB會對chunk進行分裂,稱為chunk split
-
自動觸發:插入&更新時會自動觸發Chunk Split,ChunkSize被調小時不會立即發生CunkSplit
-
手動觸發:sh.splitAt(xxx)/sh.splitFind(xxx)
-
JumboChunk:一個最小的Chunk可以只包含一個唯一的ShardKey,這樣的Chunk不可以再進行分裂,稱為JomboChunk
調整chunkSize
use config;
db.settings.save({_id:"chunksize",value:<sizeInMB>});
chunksize的選擇:
小的chunksize:資料均衡是遷移速度快,資料分布更均勻,資料分裂頻繁,路由節點消耗更多資源,
大的chunksize:資料分裂少,資料塊移動集中消耗IO資源,通常100-200M
chunkSize 對分裂及遷移的影響
-
MongoDB 默認的 chunkSize 為64MB,如無特殊需求,建議保持默認值;
-
chunkSize 會直接影響到 chunk 分裂、遷移的行為, chunkSize 越小,chunk 分裂及遷移越多,資料分布越均衡;反之,chunkSize 越大,chunk 分裂及遷移會更少,但可能導致資料分布不均,
-
chunkSize 太小,容易出現 jumbo chunk(即shardKey 的某個取值出現頻率很高,這些檔案只能放到一個 chunk 里,無法再分裂)而無法遷移;chunkSize 越大,則可能出現 chunk 內檔案數太多(chunk 內檔案數不能超過 250000 )而無法遷移,
-
chunk 自動分裂只會在資料寫入時觸發,所以如果將 chunkSize 改小,系統需要一定的時間來將 chunk 分裂到指定的大小,
-
chunk 只會分裂,不會合并,所以即使將 chunkSize 改大,現有的 chunk 數量不會減少,但 chunk 大小會隨著寫入不斷增長,直到達到目標大小,
chunk遷移
-
為了保證資料負載均衡,MongoDB支持Chunk在Shard間遷移,稱為chunk migration
-
自動觸發 - 當chunk在shard之間分布不均時,Balancer執行緒會自動觸發Chunk遷移(Chunk數量最多的Shard->chunk數量最少的Shard上遷移)
-
手動觸發 - sh.moveChunk(namespace,query,destination)
-
每個Shard同一時間只能有一個chunk在進行遷移
Targeted Operations & Broadcast Operations
特定目標的操作(Targeted Operations) - 根據分片鍵計算出目標Shard(s),發起請求并回傳結果(實作包含分片鍵的查詢操作,基于分片鍵的更新、洗掉、插入操作)
廣播的操作(Broadcast Operations) - 將請求發送給所有Shard,合并查詢結果并回傳給客戶端(實作不包含分片鍵的查詢操作,基于_id欄位的更新、洗掉操作)
MongoDB的分片分為范圍分片及哈希分片
范圍分片 - 根據ShardKey的值進行資料分片,將單個Collection的資料分散存盤在多個shard上,用戶可以指定根據集合內檔案的某個欄位即shard key來進行范圍分片(range sharding),
哈希分片 - 根據ShardKey計算哈希值,基于哈希值進行資料分片,基于哈希片鍵最大的好處就是保證資料在各個節點分布基本均勻,
參考資料
MongoDB教程 - Mongo知識體系詳解 --- @pdai
WiredTiger存盤引擎系列 --- 郭遠威
干貨分享| MongoDB 中文社區2021長沙大會
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/288228.html
標籤:NoSQL
下一篇:MongoDB知識點提要