正則運算式(regular expression, RE)是一種字符模式,用于在查找程序中匹配指定的字符,在大多數程式里,正則運算式都被置于兩個正斜杠之間;例如/l[oO]ve/就是由正斜杠界定的正則運算式,它將匹配被查找的行中任何位置出現的相同模式,在正則運算式中,元字符是最重要的概念,
工具:被vim、sed、awk、grep呼叫
場景:mysql、oracle、php、python ,Apache,Nginx... 需要正則
一、元字符
元字符是這樣一類字符,它們表達的是不同于字面本身的含義
1、基本正則運算式元字符
^ 行首定位符
[root@localhost ~]# grep "root" /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost ~]# grep "^root" /etc/passwd //以root開頭的
root:x:0:0:root:/root:/bin/bash$ 行尾定位符
[root@master1 ~]# grep "love$" 1.txt //以love為結尾的
love
ilove. 匹配單個任意字符
[root@localhost ~]# grep abc 1.txt
abc
[root@localhost ~]# grep adc 1.txt
adc
[root@localhost ~]# grep a.c 1.txt
abc
adc* 匹配前導符0到多次
[root@localhost ~]# cat 1.txt
a
ab
abc
abcd
abcde
abcdef
ggg
hhh
iii
[root@localhost ~]# grep "abc*" 1.txt
ab
abc
abcd
abcde
abcdef
[root@localhost ~]# grep "abcd*" 1.txt
abc
abcd
abcde
abcdef.* 任意多個字符
[root@localhost ~]# grep ".*" 1.txt
a
ab
abc
abcd
abcde
abcdef
ggg
hhh
iii[] 匹配指定范圍內的一個字符
[lL]ove //Love和love都可以輸出出來[-] 匹配指定范圍內的一個字符,連續的范圍
[a-z0-9]ove [^] 匹配不在指定組內的字符 (取反)
[root@localhost~]# cat 1.txt
love
1ove
|ove
[root@localhost~]# grep [0-9a-Z]ove 1.txt
love
1ove
[root@localhost ~]# grep [^0-9a-Z]ove 1.txt
|ove\ 用來轉義元字符 ('' "" \),脫意符
[root@localhost ~]# grep "l." 1.txt
love
l.ve
[root@localhost ~]# grep "l\." 1.txt
l.ve\< 詞首定位符 //以什么為詞的開頭
[root@localhost ~]# grep "love" 1.txt
love
iloveyou
[root@localhost ~]# grep "\<love" 1.txt
love\> 詞尾定義符
love\> //以love為詞的結尾() 稍后使用字符的標簽
ps:()為了后面的呼叫, \1呼叫前面()里的內容,
:% s/172.16.130.1/172.16.130.5/
:% s/\(172.16.130.\)1/\15/
:% s/\(172.\)\(16.\)\(130.\)1/\1\2\35/
:3,9 s/\(.*\)/#\1/ 加注釋x\{m\} 字符x重復出現m次
[root@localhost ~]# grep o 1.txt
love
loove
looove
[root@localhost ~]# grep "o\{3\}" 1.txt
looovex\{m,\} 字符x重復m次以上
x\{m,n} 字符出現m到n次
[root@localhost ~]# egrep "o{4,5}" 1.txt
oooo
ooooo
ioooo
ooooi
iooooi
[root@localhost ~]# egrep "o{5,5}" 1.txt
ooooo2、擴展正則運算式元字符
+ 匹配1-n個前導字符
[root@localhost ~]# cat 1.txt
lve
love
loove
[root@localhost ~]# egrep lo+ve 1.txt
love
loove? 匹配0-n個前導字符
ps:lo?ve :?前面的o 有還是沒有,都行!
[root@localhost ~]# egrep lo?ve tom.sh
love
lvea|b 匹配a或b
[root@localhost ~]# egrep "o|v" 1.txt
lve
1ove
loove
looove
loeve
love
Love
iloveyou
l.ve
o
oo
ooo
oooo
ooooo
ioooo
ooooi
iooooi() 組字符
[root@localhost ~]# egrep "loveable|rs" 1.txt
rs
loveable
lovers
[root@localhost ~]# egrep "love(able|rs)" 1.txt
loveable
lovers二、grep
1、目的:過濾,查找檔案中的內容
2、分類
① grep
② egrep:擴展支持正則
\w 所有字母與數字,稱為字符[a-zA-Z0-9] 'l[a-zA-Z0-9]*ve' === 'l\w*ve'
\W 所有字母與數字之外的字符,稱為非字符 'love[^a-zA-Z0-9]+' === 'love\W+'
\b 詞邊界 '\<love\>' === '\blove\b
③ fgrep:就不支持正則
[root@localhost ~]# fgrep . 1.txt
l.ve3、回傳值
0 就是找到了,表示成功,
1 是沒有,表示在所提供的檔案無法找到匹配的pattern(模板),
2 找到的地不對,
## grep 'root' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
## echo $?
0
## grep 'root1' /etc/passwd #用戶root1并不存在
## echo $?
1
## grep 'root' /etc/passwd1 #這里的/etc/passwd1檔案并不存在
grep: /etc/passwd1: No such file or directory
## echo $?
24、引數
grep -q 靜默 (輸出的結果不在螢屏上顯示)
[root@localhost ~]# grep "5\.." 1.txt
5.1
5.2
5.a
5.b
5..
5...
5.aaa
[root@localhost ~]# grep -q "5\.." 1.txt
[root@localhost ~]# echo $?
0grep -v 取反
grep -R 可以查目錄下面的檔案
[root@localhost ~]# grep xulei /home/
grep: /home/: 是一個目錄
[root@localhost ~]# grep -R xulei /home/
/home/xulei/.cache/gdm/session.log
/home/xulei/.cache/imsettings/log [HOME=/home/xulei/.config/imsettings]
匹配到二進制檔案 /home/xulei/.cache/tracker/meta.db
匹配到二進制檔案 /home/xulei/.cache/tracker/meta.db-walgrep -o 只找到這個關鍵詞就可以
[root@localhost ~]# grep "a" 1.txt
5.a
5.aaa
a
ab
abc
abcd
abcde
abcdef
loveable
ldfadasfsdave[root@localhost ~]# grep -o "a" 1.txt
a
a
a
a
a
a
a
a
a
a
a
a
a
agrep -B2 前兩行
grep -A2 后兩行
grep -C2 上下兩行
egrep -l 只要檔案名
[root@localhost ~]# egrep -l 'root' /etc/passwd
/etc/passwdegrep -n 帶行號
[root@localhost ~]# egrep -n 'xulei' /etc/passwd
43:xulei:x:1000:1000::/home/xulei:/bin/bash示例:
grep -E 或egrep使用
egrep 'NW' datafile :在datafile檔案中,找NW
egrep 'NW' d*:找NW,檔案只要是d開頭的就可以
egrep '^n' datafile:以n開頭的行
egrep '4$' datafile:以4結尾的行
egrep TB Savage datafile:找TB,在savage里找,在datafile里找
egrep 'TB Savage' datafile:找TB Savage
egrep '5\..' datafile:找5點后面是任意一個字符
egrep '\.5' datafile:找點五
egrep '^[we]' datafile:找w或e開頭的
egrep '[^0-9]' datafile:找不是0-9的
egrep '[A-Z][A-Z] [A-Z]':找兩個大寫,一個空格,在有一個大寫的行
egrep 'ss*' datafile:找s開頭,0到多個s
egrep '[a-z]{9}' datafile:找小寫字母出現9次的
egrep '\<north' datafile:找以nourth為單詞開頭的
egrep '\<north\>' datafile:就找這個詞
egrep '\<[a-r].*n\>' datafile:a或r開頭,中間任意,n結尾
三、sed
前言:
Stream EDitor:流編輯
sed 是一種在線的、非互動式的編輯器,它一次處理一行內容,處理時,把當前處理的行存盤在臨時緩沖區中,稱為“模式空間”(pattern space),接著用sed命令處理緩沖區中的內容,處理完成后,把緩沖區的內容送往螢屏,接著處理下一行,這樣不斷重復,直到檔案末尾,檔案內容并沒有改變,除非你使用重定向存盤輸出,Sed主要用來自動編輯一個或多個檔案;簡化對檔案的反復操作;
文本檔案->“模式空間”(pattern space)->螢屏
逐行處理
內容未變
格式:
1、sed 選項 命令 檔案
sed [options] 'command' file(s)
2、sed 選項 –f 腳本 檔案
sed [options] -f scriptfile file(s)
回傳值:
都是0,不管對錯,只有當命令存在語法錯誤時,sed的退出狀態才是非0,
sed和正則運算式:與grep一樣,sed在檔案中查找模式時也可以使用正則運算式(RE)和各種元字符,正則運算式是括在斜杠間的模式,用于查找和替換,以下是sed支持的元字符,
使用基本元字符集 ^, $, ., *, [], [^], \< \>,\(\),\{\}
使用擴展元字符集 ?, +, |, ( )
使用擴展元字符的方式:
\+ 轉義
sed -r 加-r
匯總示例
編輯檔案洗掉命令 d:
[root@master1 ~]# sed -r '/root/d' passwd //匹配詞組洗掉,洗掉有root的行
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin[root@master1 ~]# sed -r '3d' passwd //洗掉第三行
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin洗掉第三行:
[root@master1 ~]# sed -r '3{d}' passwd
root:x:0:0:root:/root:/bin/bash 1
bin:x:1:1:bin:/bin:/sbin/nologin 2
adm:x:3:4:adm:/var/adm:/sbin/nologin 4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 5
sync:x:5:0:sync:/sbin:/bin/sync 6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 7
halt:x:7:0:halt:/sbin:/sbin/halt 8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 9
operator:x:11:0:operator:/root:/sbin/nologin 10{存放sed的多個命令} 例如:3{h;d},h暫存空間
[root@master1 ~]# sed -r '3{d;}' passwd
root:x:0:0:root:/root:/bin/bash 1
bin:x:1:1:bin:/bin:/sbin/nologin 2
adm:x:3:4:adm:/var/adm:/sbin/nologin 4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 5
sync:x:5:0:sync:/sbin:/bin/sync 6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 7
halt:x:7:0:halt:/sbin:/sbin/halt 8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 9
operator:x:11:0:operator:/root:/sbin/nologin 10洗掉3行到最后一行'3,$d'
[root@master1 ~]# sed -r '3,$d' passwd
root:x:0:0:root:/root:/bin/bash 1
bin:x:1:1:bin:/bin:/sbin/nologin 2洗掉最后一行:
[root@master1 ~]# sed -r '$d' passwd
root:x:0:0:root:/root:/bin/bash 1
bin:x:1:1:bin:/bin:/sbin/nologin 2
daemon:x:2:2:daemon:/sbin:/sbin/nologin 3
adm:x:3:4:adm:/var/adm:/sbin/nologin 4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 5
sync:x:5:0:sync:/sbin:/bin/sync 6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 7
halt:x:7:0:halt:/sbin:/sbin/halt 8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 9替換命令 s:
[root@master1 ~]# sed -r 's/root/aofa/' passwd
aofa:x:0:0:root:/root:/bin/bash 1
bin:x:1:1:bin:/bin:/sbin/nologin 2
daemon:x:2:2:daemon:/sbin:/sbin/nologin 3
adm:x:3:4:adm:/var/adm:/sbin/nologin 4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 5
sync:x:5:0:sync:/sbin:/bin/sync 6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 7
halt:x:7:0:halt:/sbin:/sbin/halt 8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 9
operator:x:11:0:operator:/aofa:/sbin/nologin 10全域替換
[root@master1 ~]# sed -r 's/root/aofa/g' passwd //全部的root被替換掉了 g:全域替換
aofa:x:0:0:aofa:/aofa:/bin/bash 1
bin:x:1:1:bin:/bin:/sbin/nologin 2
daemon:x:2:2:daemon:/sbin:/sbin/nologin 3
adm:x:3:4:adm:/var/adm:/sbin/nologin 4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 5
sync:x:5:0:sync:/sbin:/bin/sync 6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 7
halt:x:7:0:halt:/sbin:/sbin/halt 8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 9
operator:x:11:0:operator:/aofa:/sbin/nologin 10查找雙數 結尾的詞組
&:替換成 雙數.5
&有查詢結果的含義,
# sed -r 's/[0-9][0-9]$/&.5/' passwd
[root@localhost ~]# sed -r 's/[0-9][0-9]$/&.5/' passwd
root:x:0:0:root:/root:/bin/bash1
bin:x:1:1:bin:/bin:/sbin/nologin2
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10.5
sed -r 's/(mail)/E\1/g' passwd
()括號組合字符,\1呼叫括號
[root@localhost ~]# sed -r 's/(mail)/E\1/g' passwd
Email:x:8:12:Email:/var/spool/Email:/sbin/nologin9sed -r 's#(mail)#E\1#g' passwd
分隔符可以換成#號
讀檔案命令r:
//最后一行,讀取新檔案1.txt
[root@localhost ~]# sed -r '$r 1.txt' passwd
root:x:0:0:root:/root:/bin/bash1
bin:x:1:1:bin:/bin:/sbin/nologin2
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
111111111
2222222
3333333333 sed -r '/root/r 1.txt' passwd
//正則搜尋root,在root后面讀取新檔案ps:在當前檔案中,讀取其他檔案的“部分”內容,
寫檔案內容:w(另存為)
sed -r 'w 111.txt' 1.txt
//把1.txt全部內容寫入111.txtsed -r '/root/w 123.txt' passwd //把passwd里含有root欄位的行寫到123.txt追加命令:a(之后)
sed -r 'a123' passwd //每行后面都加上123sed -r '2a123' passwd //第二行后面加上123
//插入段落,請使用\轉義掉回車,不要忘了分號結束
[root@localhost ~]# sed -r '2a1111\
3333333\
444444' passwd
root:x:0:0:root:/root:/bin/bash1
bin:x:1:1:bin:/bin:/sbin/nologin2
1111
3333333
444444
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10插入命令:i(之前)
//在第二行插入新行aaaaaaaaaa
[root@localhost ~]# sed -r '2iaaaaaaaa' passwd
root:x:0:0:root:/root:/bin/bash1
aaaaaaaa
bin:x:1:1:bin:/bin:/sbin/nologin2
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10替換正行命令:c
//把第二行替換成aaaaaaaaa
[root@localhost ~]# sed -r '2caaaaaaaa' passwd
root:x:0:0:root:/root:/bin/bash1
aaaaaaaa
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10獲取下一行命令:n
//n下一行的意思,
找root行,然后下一行,洗掉
[root@localhost ~]# sed -r '/root/{n;d}' passwd
root:x:0:0:root:/root:/bin/bash1
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
//n:next下一行可以用多次,
[root@localhost ~]# sed -r '/root/{n;n;d}' passwd
root:x:0:0:root:/root:/bin/bash1
bin:x:1:1:bin:/bin:/sbin/nologin2
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
反向選擇:!
下面兩個做對比,一個沒有!,一個有!
[root@localhost ~]# sed -r '2,$d' passwd
root:x:0:0:root:/root:/bin/bash1
[root@localhost ~]# sed -r '2,$!d' passwd
bin:x:1:1:bin:/bin:/sbin/nologin2
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10多重編輯:e
在一個命令后加上-e后可以再跟命令
[root@localhost ~]# sed -r -e '1,3d' -e '4s/adm/admin/g' passwd
admin:x:3:4:admin:/var/admin:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
//將一到3行洗掉,將第4行的adm全域替換成admin暫存空間hHGgx :
圖示:
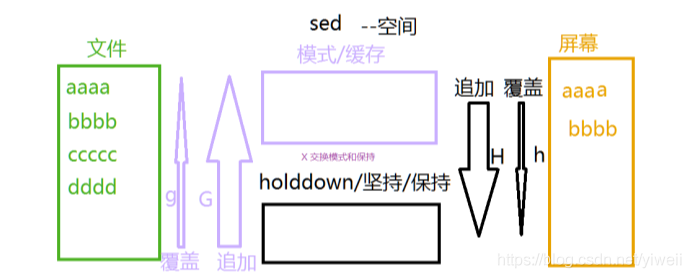
暫存和取用命令,h覆寫暫存空間,H追加暫存空間,g覆寫行,G追加行,
四、AWK
awk 是一種編程語言,用于在linux/unix下對文本和資料進行處理,資料可以來自標準輸入、一個或多個檔案,或其它命令的輸出,它支持用戶自定義函式和動態正則運算式等先進功能,
awk的處理文本和資料的方式是這樣的,它逐行掃描檔案,從第一行到最后一行,尋找匹配的特定模式的行,并在這些行上進行你想要的操作,如果沒有指定處理動作,則把匹配的行顯示到標準輸出(螢屏),awk分別代表其作者姓氏的第一個字母,因為它的作者是三個人,分別是Alfred Aho、Peter Weinberger、 Kernighan,
作業原理:
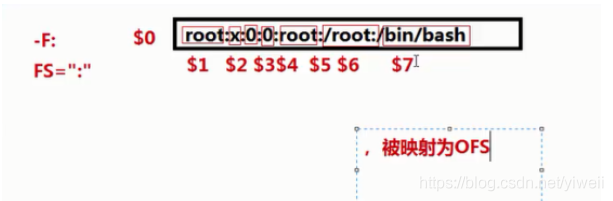
# awk -F: '{print $1,$3}' /etc/passwd
(1)awk使用一行作為輸入,并將這一行賦給內部變數$0,每一行也可稱為一個記錄,以換行符結束(2)然后,行被:(默認為空格或制表符)分解成欄位(或域),每個欄位存盤在已編號的變數中,從$1開始,
最多達100個欄位(3)awk輸出之后,將從檔案中獲取另一行,并將其存盤在$0中,覆寫原來的內容,然后將新的字串分隔
成欄位并進行處理,該程序將持續到所有行處理完畢
圖示:
內部變數
FS:輸入欄位分隔符(默認空格)
[root@slave2 ~]# df -hT
檔案系統 型別 容量 已用 可用 已用% 掛載點
devtmpfs devtmpfs 475M 0 475M 0% /dev
tmpfs tmpfs 487M 0 487M 0% /dev/shm
tmpfs tmpfs 487M 7.6M 479M 2% /run
tmpfs tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 17G 3.1G 14G 19% /
/dev/sda1 xfs 1014M 149M 866M 15% /boot
tmpfs tmpfs 98M 0 98M 0% /run/user/0
[root@slave2 ~]# df -hT | grep /$ | awk '{print $5}'
14G
[root@slave2 ~]# df -hT | grep /$ | awk '{print $5}' | awk 'BEGIN{FS='G'} {print $1}'
1
[root@slave2 ~]# df -hT | grep /$ | awk '{print $5}' | awk 'BEGIN{FS="G"} {print $1}'
14OFS:輸出欄位分隔符 (FS和OFS在一個{}里面)
[root@slave2 ~]# awk 'BEGIN{FS=":";OFS="++++"} {print $1,$2}' /etc/passwd //以++++來作為分隔
root++++x
bin++++x
daemon++++x
adm++++x
lp++++x
sync++++x
shutdown++++x
halt++++x
mail++++x
operator++++x
games++++x
ftp++++xRS:輸入記錄(行)分隔符,默認換行符
[root@slave2 ~]# awk 'BEGIN{RS="a"} {print $0}' 1.txt
1111111111111111111
2222222222222222222
333333333333333
4444444
111111111111111111
22222222222222222222
33333333333333333333
44444444ORS:輸出記錄(行)分隔符,默認換行符
[root@slave2 ~]# awk 'BEGIN{RS="a";ORS="============="} {print $0}' 1.txt
1111111111111111111
2222222222222222222
333333333333333
4444444=============
111111111111111111
22222222222222222222
33333333333333333333
44444444=============
=============FNR:多檔案獨立編號
[root@slave2 ~]# awk '{print FNR,$1}' /etc/passwd 1.txt
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
1 1111111111111111111
2 2222222222222222222
3 333333333333333
4 4444444a
5 111111111111111111
NR:多檔案匯總編號
[root@slave2 ~]# awk '{print NR,$1}' /etc/passwd 1.txt
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 1111111111111111111
7 2222222222222222222
8 333333333333333
9 4444444a
10 111111111111111111
NF:欄位總數
[root@localhost ~]# awk -F: '{print NF, $0}' /etc/passwd
7 root:x:0:0:root:/root:/bin/bash
7 bin:x:1:1:bin:/bin:/sbin/nologin
7 daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@localhost ~]# awk -F: '{print NF, $NF}' /etc/passwd
7 /bin/bash
7 /sbin/nologin
7 /sbin/nologin格式化輸出
print函式
[root@localhost ~]# date |awk '{print "Month: " $2 "\nYear: " $1}'
Month: 11月
Year: 2017年ps:\n換行符,想輸出文字用引號,
[root@localhost ~]# awk -F: '{print "username is: " $1 "\t uid is: " $3}' /etc/passwd | head -1
username is: root uid is: 0[root@localhost ~]# awk -F: '{print "\tusername and uid: " $1,$3 "!"}' /etc/passwd | head -1
username and uid: root 0!printf:
語法
%s 字符型別
%d 數值型別
%f 浮點型,可以定義保留
占15字符
- 表示左對齊,默認是右對齊
printf默認不會在行尾自動換行,加\n
, 逗號,輸出欄位分隔符
[root@slave2 ~]# awk -F: '{printf "%-10s %-10s %-15s\n",$1,$2,$3}' /etc/passwd | head
root x 0
bin x 1
daemon x 2
adm x 3
lp x 4
sync x 5
shutdown x 6
halt x 7
mail x 8
operator x 11 在每一列之間增加|,看的更加清晰,
[root@localhost ~]# awk -F: '{printf "|%-15s| %-10s| %-15s|\n", $1,$2,$3}' /etc/passwd | head
|root | x | 0 |
|bin | x | 1 |
|daemon | x | 2 |
|adm | x | 3 |
|lp | x | 4 |
|sync | x | 5 |
|shutdown | x | 6 |
|halt | x | 7 |
|mail | x | 8 |
|operator | x | 11 |模式(正則表達)和動作
① 概念
任何awk陳述句都由模式和動作組成,模式部分決定動作陳述句何時觸發及觸發事件,如果省略模式部分,動作將時刻保持執行狀態,每一行都會有動作,模式可以是任何條件陳述句或復合陳述句或正則運算式,有模式的話,就是對模式對應的行進行動作,
模式:可以是條件測驗,正則,復合陳述句
動作:可以是列印,計算等,
②字串比較
awk '/^root/' /etc/passwd
awk '$0 ~/^root/' /etc/passwd
awk '$0!~/^root/' /etc/passwd
awk -F: '$1 ~/^root/' /etc/passwd③ 數值比較
目的:比較運算式采用對文本進行比較,只有當條件為真,才執行指定的動作,比較運算式使用關系運算子,用于比較數字與字串,
關系運算子
語法
運算子 含義 示例
< 小于 x<y
<= 小于或等于 x<=y
== 等于 x==y
!= 不等于 x!=y
>= 大于等于 x>=y
> 大于 x>y
示例
# awk -F: '$3 == 0' /etc/passwd
# awk -F: '$3 == 1' /etc/passwd
# awk -F: '$3 < 10' /etc/passwd
== 也可以用于字串判斷
# awk -F: '$7 == "/bin/bash"' /etc/passwd
# awk -F: '$1 == "alice"' /etc/passwd算數 運算
語法
+ - * / %(模) ^(冪2^3)
示例
# awk -F: '$3 * 10 > 500' /etc/passwd
④ 多條件
邏輯運算子和復合模式
語法:
&& 邏輯與 a&&b
|| 邏輯或 a||b
! 邏輯非 !a
# awk -F: '$1~/root/ && $3<=15' /etc/passwd
# awk -F: '$1~/root/ || $3<=15' /etc/passwd
# awk -F: '!($1~/root/ || $3<=15)' /etc/passwd范圍模式:
awk '/從哪里/,/到哪里/' filename
# awk -F: '/adm/,/lpd/' /etc/passwd
從adm到ldp,顯示出來,注意避免匹配重復的欄位,awk腳本編程
① 變數
awk呼叫變數
自定義內部變數 -v
awk -v user=root -F: '$1 == user' /etc/passwd
-v定義變數外部變數 “ ‘ ”
雙引號
# var="bash"
# echo "unix script" | awk "{print "123",\"$var\"}"
123 bash
注意 awk呼叫外部變數時,外部使用雙引號,內部也使用雙引號,但需要轉義內部的雙引號單引號
# var="bash"
# echo "unix script" |awk '{print $1,"'"$var"'"}'
unix bash
注意使用單引號時,內部需要用雙引轉義② 條件和判斷
if陳述句
語法:
{if(運算式){陳述句;陳述句;....}}
需求
如果$3是0,就說他是管理員
awk -F: '{if($3==0) {print $1 " is administrator."}}' /etc/passwdif...else 陳述句
{if(運算式){陳述句;陳述句;...}else{陳述句;陳述句;...}}
{if(){}else{}}
需求
如果第三列是0,列印該行第一列,否則列印第七列,登錄shell
示例
awk -F: '{if($3==0){print $1} else {print $7}}' /etc/passwd 需求
統計管理員和系統用戶數量
示例
awk -F: '{if($3==0){count++} else{i++}} END{print "管理員個數: "count ; print "系統用戶數: "i}' /etc/passwdif...else if...else陳述句
格式
{if(運算式1){陳述句;陳述句;...}else if(運算式2){陳述句;陳述句;...}else if(運算式3){陳述句;陳述句;...}else{陳述句;陳述句;...}}
if (條件){動作}elseif(條件){動作}else{動作}
if(){}else if (){}else if(){}else{}
需求:
顯示出三種用戶的資訊管理員:管理員ID為0,內置用戶:用戶ID<1000,普通用戶: 用戶ID>999
[root@localhost ~]# awk -F: '{if($3==0){print $1," is admin "}else if ($3>999){print $1," is user"}else {print $1, " is sofo user"}}' /etc/passwd
root is admin
bin is sofo user
daemon is sofo user
adm is sofo user
lp is sofo user
sync is sofo user
shutdown is sofo user
halt is sofo user
mail is sofo user
回圈
while
回圈列印10個數字
[root@slave2 ~]# awk 'BEGIN{ while(i<=10){print i;i++}}'
1
2
3
4
5
6
7
8
9
10第一行列印十次
[root@slave2 ~]# awk -F: '{while(i<=9){print $0;i++}}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bashfor
回圈列印5個數字
[root@slave2 ~]# awk 'BEGIN{for(i=1;i<=5;i++){print i}}'
1
2
3
4
5每行列印10次
awk -F: '{ for(i=1;i<=10;i++) {print $0} }' /etc/passwd陣列
定義陣列
將用戶名定義為陣列的值,列印第一個值,
[root@slave2 ~]# awk -F: '{username[++i]=$1} END{print username[1]}' /etc/passwd
root陣列遍歷
按索引遍歷
[root@slave2 ~]# awk -F: '{username[++i]=$1} END{for (i in username) {print i, username[i]}}' /etc/passwd | sort -n //sort排序
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
8 halt
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/28932.html
標籤:其他
下一篇:排障集合————DNS組態檔報錯