一、redis簡介
一般學習,最好先去官網,之所以建議看官網,是因為這是一手的學習資料,其他資料都最多只能算二手,一手資料意味著最權威,準確性最高,https://redis.io/topics/introduction,如果像我一樣,英語不好的童鞋,不要緊,咋們用Chrome瀏覽器,翻譯成中文,Eumm,,,來看看官網給的解釋:“redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.” ,第一句就告訴我們,redis是什么:redis是一個開源的,基于記憶體的資料結構存盤,可用作于資料庫、快取、消息中間件,
1.1、為什么使用redis?
由官網可知:redis是基于記憶體,常用于快取的一種技術,并redis存盤方式是以 Key-value 的形式,等等?Key-value??這個不就是Java中Map容器的特性嗎?那為什么還用redis呢?
- Java實作的Map是本地快取,只能存在創建他的程式中,最主要的特點是輕量以及快速,而且實體多的情況下,每個實體都需要各自保存一份快取,快取不具有一致性,
- redis實作的是分布式快取,如果有多個實體機器,每個實體共享一份快取,快取具有一致性,
- Java中Map不是專業做快取的,JVM記憶體太大容易掛掉,所以一般用來做容器存盤臨時資料,快取隨著JVM銷毀而結束,
- redis是專門做快取的,快取可以持久化,可以將快取的資料保存在硬碟中,redis重啟之后就可以恢復,但是Map是記憶體物件,程式重啟資料就沒有了,
- redis可以處理每秒百萬級的并發,Map只是一個普通的物件,
1.2、為什么要用快取
如果我們的網站出現了性能問題(訪問時間慢),一般是由于資料庫扛不住了,因為一般的資料庫的讀寫都是經過磁盤的,磁盤的讀寫相當于記憶體來說非常慢了,參考資料:讓CPU告訴你硬碟和網路到底有多慢:https://cizixs.com/2017/01/03/how-slow-is-disk-and-network/,用過Mybatis和Hibernate的同學都知道,他們有一級快取、二級快取這樣的功能(實質就是本地快取),目的就是為了不用每次讀取資料的時候,都去資料庫查詢,
二、redis的物件和資料結構
注:本篇博文不講述redis命令的使用方式,具體的使用請查看API.(redis命令參考:http://doc.redisfans.com/)
【物件】
redis使用物件來表示資料庫中的鍵和值,每次在redis中新建一個鍵值對的時候,至少會創建出兩個物件,一個物件用作鍵值對的鍵(鍵物件),一個物件用作鍵值對的(值物件),redis中的每種物件都由物件結構(redisObject) 與對應編碼的 資料結構 組合而成,redis支持5種物件型別,分別是字串(string)、串列(list)、哈希(hash)、集合(set)、有序集合(zset),而每種物件型別至少對應兩種編碼方式,不同的編碼方式所對應的底層資料結構是不同的,
每個物件會用到的編碼以及對應的資料結構詳見下表:
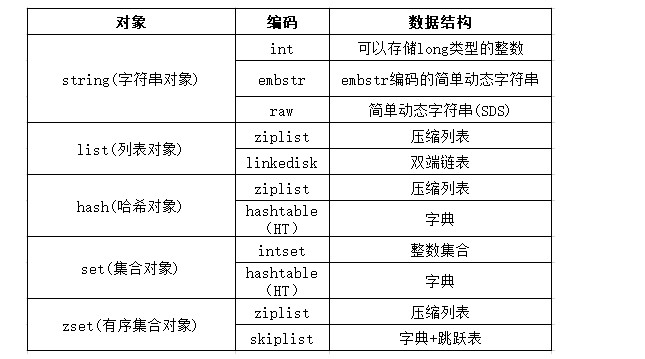
每種物件對應兩至三種編碼,除skiplist編碼需要用到兩種資料結構(字典+跳躍表)外,其余編碼均用到一種底層的資料結構,同一個物件型別,在不同的場景下用到的編碼(資料結構)不同,redis支持8種編碼以及8種底層的資料結構,這種方式更加靈活,可以幫助redis獲得更高的性能以及盡量占用更少的記憶體,比如如果字串物件中要存盤的字串內容所占位元組較小,會用embstr編碼的格式,如果要存盤的內容所占位元組較大,會用raw編碼的格式,具體細節后文會詳細說明,
上面說過,redis中的鍵和值都是由物件組成的,而物件是由物件結構和資料結構共同組成的,redis中的鍵,都是用字串來存盤的,即對于redis資料庫中的鍵值對來說,鍵總是一個字串物件,而值可以是字串物件、串列物件、哈希物件、集合物件或者有序集合物件中的其中一種,
鍵、值的整體大致結構可以如下圖所示

【物件結構】
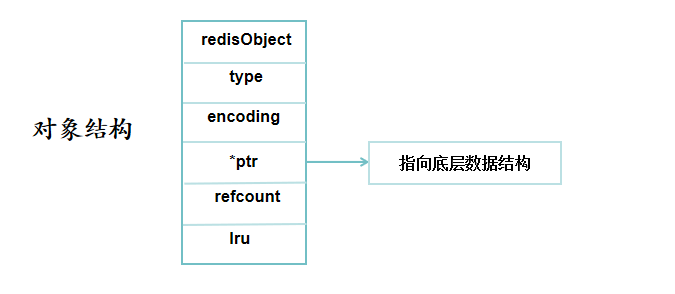
物件結構(redisObject)共有5個屬性,分別是type屬性、encoding屬性、ptr屬性、refcount屬性、lru屬性,
其中type屬性、encoding屬性、ptr屬性和保存資料有關
type屬性:表示該物件的型別是什么
encoding屬性:表示這個物件使用的底層資料結構是什么
ptr屬性:是一個指向底層資料結構的指標
refcount屬性是一個參考計數屬性,可以用于記憶體回收和物件共享
lru屬性,記錄了物件最后一次被命令程式訪問的時間,可以計算出某個鍵的空轉時長
物件結構的邏輯圖如下所示:
【記憶體回收--refcount屬性】
在物件結構中,有refcount這個屬性,該屬性用于記錄物件的參考計數資訊,redis利用參考計數(reference counting)技術實作記憶體回識訓制,通過這一機制,程式可以通過跟蹤物件的參考計數資訊,在適當的時候自動釋放物件并進行記憶體回收,
具體策略:
在創建一個新物件時,參考計數的值會被初始化為1
當物件被一個新程式使用時,它的參考計數值會被增一
當物件不再被一個程式使用時,它的參考計數值會被減一
當物件的參考計數值變為0時,物件所占用的記憶體會被釋放
【物件共享--refcount屬性】
redis會在初始化服務器時,服務器會創建一萬個字串物件,這些物件包含了從0到9999的所有整數值,當服務器、新創建的鍵需要用到值為0到9999的字串物件時,服務器就會使用這些共享物件,而不是新創建物件,
物件結構中,refcount是參考指標屬性,如果有N個鍵共享一個值,refcount對應的值就為N,創建共享字串物件的數量可以通過redis.h/redis_shared_intengers常量來修改,object refcount命令可以查看某個鍵對應的值被參考了多少次,
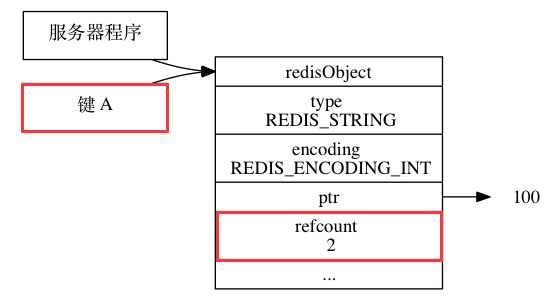
讓多個鍵共享一個值,需要執行以下兩個步驟:
將鍵的值指標,指向被共享的值物件
被共享的值物件的參考計數器加一,即refcount屬性的值加一,參考數為2的共享物件結構圖如下圖所示:
【進一步說明】
當服務器考慮將一個鍵的值參考共享物件時,鍵的值作為目標物件,程式需要先檢查共享物件和目標物件的型別是否完全相同,只有在完全相同的情況下,共享物件才會被參考,而一個共享物件保存的值越復雜,驗證共享物件與目標物件所需的復雜度就會越高,消耗的CPU時間也會越多,
所以共享物件的優點是被其它鍵參考時,可以節省記憶體空間,缺點是被參考時需要進行判斷,這個程序需要消耗CPU,如果共享物件簡單,消耗很小的CPU并節省記憶體空間是值得的,但如果物件很復雜,進行判斷就需要消耗大量CPU,消耗大量CPU去節省記憶體空間是不值得的,因為redis本身的記憶體空間還是很大的,
redis支持5種物件,包括字串物件、串列物件、哈希物件、集合物件以及有序集合物件,而字串物件是redis中的一個基礎物件,其它物件均可以在底層的資料結構內部嵌套字串物件,
物件共享:
1、只有字串物件才能被創建為共享物件,被其它字串鍵使用;
2、用字串物件創建的共享物件,不單單只有字串鍵可以使用,那些在資料結構中嵌套了字串物件的物件(linkedlist編碼的串列物件、hashtable編碼的哈希物件、hashtable編碼的集合物件,以及skiplist編碼的有序集合物件)都可以使用這些字串共享物件,
【物件的空轉時長--lru屬性】
物件結構的lru屬性,記錄了物件最后一次被命令程式訪問的時間
空轉時長:當前時間減去鍵的值物件的lru時間,就是該鍵的空轉時長,Object idletime命令可以列印出給定鍵的空轉時長
如果服務器打開了maxmemory選項,并且服務器用于回收記憶體的演算法為volatile-lru或者allkeys-lru,那么當服務器占用的記憶體數超過了maxmemory選項所設定的上限值時,空轉時長較高的那部分鍵會優先被服務器釋放,從而回收記憶體,
2.1、字串物件
2.11、字串物件介紹
字串物件可以存盤整數、浮點數、字串,具體策略是:
當存盤整數時,用到的編碼是int,底層的資料結構可以用來存盤long型別的整數
當存盤字串時,如果字串的長度小于等于32位元組,那么將用編碼為embstr的格式來存盤;如果字串的長度大于32位元組,將用編碼為raw的SDS格式來存盤
當存盤浮點數時會先將浮點數轉換為字串,如果轉換后的字串長度小于32位元組就用編碼為embstr的格式來存盤,否則用編碼為raw的SDS格式來存盤
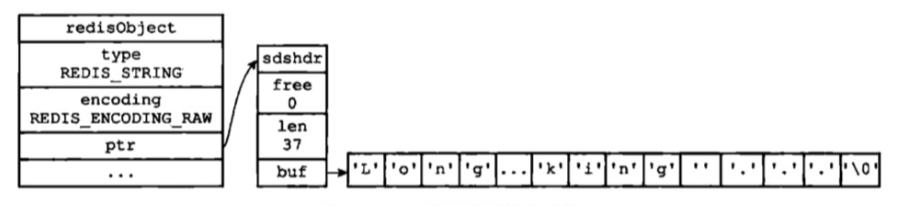
下圖是以raw編碼的字串物件結構圖,最左側是物件結構,中間跟右側合起來是raw編碼的SDS資料結構(sdshdr),示例圖:
2.12、raw編碼,簡單動態字串(simple dynamic string-SDS)
雖然redis由C語言撰寫,但是redis用的并不是C語言傳統的字串,而是自己構建了簡單動態字串(simple dynamic string,SDS),當redis列印日志資訊或輸出報錯資訊,這些輸出的字串是不會被修改的字串字面量(sting literal),此時用的是C語言傳統的字串來存盤這些資訊的,當redis需要存盤的是可以被修改的字串時,就會使用SDS結構,除了用來保存資料庫中的字串值之外,SDS還被用作緩沖區(buffer):AOF模塊中的AOF緩沖區,以及客戶端狀態中的輸入緩沖區,都是由SDS實作的,
redis使用sdshdr結構來表示一個SDS的值,SDS結構示意圖如下:
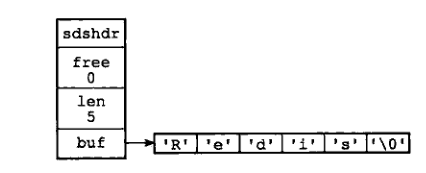
sdshdr是該資料結構的名稱即SDS,其中:
buf屬性,是一個位元組陣列,用來保存字串,后面箭頭對應的就是實際保存的字串內容,最后以’\0’空字串結尾
len屬性,記錄的是buf陣列中實際已使用的位元組數量,等于SDS所保存字串的長度
free屬性,記錄的是buf陣列中未存盤內容的空余大小,單位位元組
2.1.3、使用SDS的好處
一、可以用O(1)的復雜度獲取到字串長度
SDS的len屬性記錄了字串的長度,而傳統C字串要想知道長度需要遍歷整個字串,相比于傳統C字串,redis獲取字串長度所需的復雜度從O(N)降低到了O(1),
即使對非常長的字串反復執行STRLEN命令(獲取字串長度),也不會造成過多的性能消耗,
二、杜絕緩沖區溢位
在傳統的C字串中,如果要修改字串的內容,但修改后字串的長度超過原先的長度就會發生溢位現象,詳見下圖:

在SDS中,當需要對buf位元組陣列中存盤的內容進行修改(增添或洗掉)時,API會先通過free和len屬性檢查SDS的空間是否足夠,如果不夠的話,SDS會自動擴展空間再對內容進行修改,關于自動擴展空間的策略見下方“空間預分配”的內容,
三、減少修改字串長度時所需的記憶體重分配次數
對于傳統C字串:
如果執行的是增長字串的操作,如拼接操作(append),那么在執行命令之前,程式需要先通過記憶體重分配來擴展底層資料的空間大小——否則會產生緩沖區溢位,
如果執行的是縮短字串的操作,如截斷操作(trim),那么在執行這個操作之后,程式需要通過記憶體重分配來釋放字串不再使用的空間——否則會產生記憶體泄漏,
對于redis中的SDS結構:
記憶體重分配設計復雜的演算法,是一個比較耗時的操作,redis作為速度要求嚴苛、資料會被頻繁執行的資料庫,如果每次修改字串都需要進行一次記憶體重分配,會嚴重影響性能,
使用SDS,buf陣列里可以包含未使用的位元組,這些位元組的數量由free屬性記錄,可以減少修改字串長度時所需的記憶體重分配次數,
【空間預分配和惰性空間釋放】
通過SDS中free屬性定義的未使用空間,SDS可以實作空間預分配和惰性空間釋放兩種優化策略:
1、空間預分配策略——可以降低字串增長操作引起的記憶體重分配
當需要修改SDS的內容,且需要進行空間擴展的時候,程式不僅會為SDS分配修改所需的必須空間,還會為SDS分配額外的未使用空間,
其中,額外分配的未使用空間數量由以下公式決定:
如果對SDS進行修改之后,SDS的長度(即len屬性的值)將小于1MB,那么程式將分配和len屬性同樣大小的未使用空間,這時SDS len屬性的值將和free屬性的值相同,
如果對SDS進行修改后,SDS的長度將大于等于1MB,那么程式會分配1MB的未使用空間,
【進一步說明】
如果對一個字串的末尾持續追加內容,當字串整體大小大于1MB時,即使只追加一位元組的字符,程式也會額外分配1MB的空間,當再次追加一位元組的字符時,程式不會再額外分配1MB的空間,而是使用已有的空閑空間,
即在擴展空間之前,會先檢查未使用的空間是否足夠,如果足夠,是不會額外再擴展的
通過空間預分配策略,SDS將連續增長N次字串所需的記憶體重分配次數從必定N次降低為最多N次,
2、惰性空間釋放策略——可以降低字串縮短操作引起的記憶體重分配
當SDS中的字串長度被縮短時,程式并不會立即使用記憶體重分配來回收縮短后多出來的位元組空間,而是使用free屬性將這些位元組的數量記錄起來,以備將來使用,
當然,redis提供了相應的命令來真正釋放這些未使用空間,避免不必要的記憶體浪費,
四、二進制安全
C字串中的字符必須符合某種編碼(比如ASCII),并且除了字串的末尾之外,字串里面不能包含空字符,如果字串除末尾外還有其它空字符,那么最先被程式讀入的空字符將被誤認為是字串結尾,這些限制使得C字串只能保存文本資料,而不能保存圖片、音頻、視頻、壓縮檔案這樣的二進制資料,
為了確保redis可以適用于各種不同的使用場景,SDS的API都是二進制安全的(binary-safe),所有SDS API都會以處理二進制的方式來處理SDS存放buf陣列里的資料,程式不會對其中的資料做任何限制、過濾或者假設,資料在寫入時是什么樣的,它被讀取時就是什么樣,
這也是SDS的buf屬性被稱為位元組陣列的原因——redis不是用這個陣列來保存字符,而是用它來保存一系列二進制資料,
五、兼容部分C字串函式
SDS遵循空字串結尾這一慣例,好處是可以直接重用C字串函式庫里的函式,從而避免了不必要的代碼重復
【embstr編碼】
如果字串物件保存的是長度小于等于32位元組的字串,那么將會使用embstr編碼,embstr編碼是專門用來保存短字串的一種優化編碼方式,embstr編碼與raw編碼對應的字串物件,都是由物件結構(redisObject)和資料結構(sdshdr)組成的,
區別在于用raw編碼的字串物件會呼叫兩次記憶體分配函式來分別創建redisObject結構和sdshdr結構,而embstr編碼則通過呼叫一次記憶體分配函式來分配一塊連續的空間,空間中一次包含redisObject和sdshr兩個結構,embstr編碼的字串物件結構圖如下所示:

兩者的區別
embstr編碼的字串物件在執行命令時,產生的效果和raw編碼的字串物件執行命令時產生的效果是相同的,但使用embstr編碼的字串物件來保存短字串值有以下好處:
1、embstr編碼將創建字串物件所需的記憶體分配次數從raw編碼的兩次降低為一次
2、釋放embstr編碼的字串物件只需要呼叫一次記憶體釋放函式,而釋放raw編碼的字串物件需要呼叫兩次記憶體釋放函式
3、embstr編碼的字串物件的所有資料都保存在一塊連續的記憶體里,結構更加緊湊,而raw編碼是分散開的,redisObject物件結構和sdshdr資料結構彼此間是用指標相關聯的,embstr編碼的物件比raw編碼的物件能夠更好的利用快取帶來的優勢,
【編碼的轉換】
int編碼的字串物件和embstr編碼的字串物件在條件滿足的情況下,會被轉換成raw編碼的字串物件,encoding命令可以查看鍵對應的值,底層用的是什么編碼,
int轉換為raw:
對于int編碼的字串物件來說,如果我們向物件執行了一些命令,使得這個物件保存的不再是整數值,而是一個字串值,那么字串物件的編碼將從int變為raw
127.0.0.1:6379> set a 100 OK 127.0.0.1:6379> object encoding a "int" 127.0.0.1:6379> append a 'a' (integer) 4 127.0.0.1:6379> get a "100a" 127.0.0.1:6379> object encoding a "raw"
int編碼的字串,存盤的是long型別的整數,范圍是2^63-1(2的63次方減一) ~ -2^63(2的63次方),當存盤的整數在該范圍內時,編碼為int,當值超過該范圍,編碼將轉換為embstr
127.0.0.1:6379> set number1 9223372036854775807 OK 127.0.0.1:6379> object encoding number1 "int" 127.0.0.1:6379> set number1 9223372036854775808 OK 127.0.0.1:6379> object encoding number1 "embstr" 127.0.0.1:6379> set number -9223372036854775808 OK 127.0.0.1:6379> object encoding number "int" 127.0.0.1:6379> set number -9223372036854775809 OK 127.0.0.1:6379> object encoding number "embstr"
embstr轉換為raw:
embstr編碼的字串物件無法被修改(redis沒有為embstr編碼的字串物件撰寫任何回應的修改程式),只有int、raw編碼的字串物件可以被修改,所以embstr編碼的字串實際上是只讀的,
當對embstr編碼的字串物件執行任何修改命令時,程式都會先將物件的編碼從embstr轉換為raw,然后再執行修改命令,所以一旦embstr編碼的字串被修改,它的資料結構就會變成raw編碼的格式,
127.0.0.1:6379> set a 'ab' OK 127.0.0.1:6379> object encoding a "embstr" 127.0.0.1:6379> append a 'c' (integer) 3 127.0.0.1:6379> get a "abc" 127.0.0.1:6379> object encoding a "raw"
串列物件、哈希物件等,請參考學習之Redis(二):https://www.cnblogs.com/wbq1994/p/12031353.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/29500.html
標籤:NoSQL
上一篇:Redis中幾個簡單的概念:快取穿透/擊穿/雪崩,別再被嚇唬了
下一篇:Redis—持久化的兩種方式