寫在前面
ELK三劍客(ElasticSearch,Logstash,Kibana)基本上可以滿足日志采集、資訊處理、統計分析、可視化報表等一些日志分析的作業,但是對我們來說……太重了,并且技術堆疊不是一路的,我們的場景是需要采集各個業務部門服務器上面的各個業務系統,所以盡量不要影響到服務器的性能,以侵入性最低的方式進行采集,不做其他多余操作,因而,在前端日志采集這塊,對比其他Logstash、Flume等采集工具之后,決定采用輕量的Filebeat作為日志采集工具,Filebeat采用go開發,運行不需要額外部署環境,相比Flume依賴jdk輕量了不少,且占用記憶體低,
采集鏈路如下所示:Filebeat日志采集、處理轉換之后,推送到kafka,采用Clickhouse的kafka引擎進行消費存盤,因而,我暫且稱之為KFC??組合,

Filebeat部署
采集目標環境:
系統:Window Server 2008 R2 Enterprise
日志類別:IIS日志、業務系統日志
日志路徑:D:/IIS/www.A.com/logs/*.txt 、D:/IIS/www.B.com/logs/*.txt、D:/IIS/www.C.com/logs/*.txt
Filebeat:7.12.1(https://www.elastic.co/cn/downloads/beats/filebeat)
因為采集的是windows作業系統,建議下載Filebeat壓縮包,并以windows服務的方式運行,使用安裝包msi安裝不方便除錯,需要頻繁的卸載、安裝操作,下載之后解壓出來進行對組態檔 filebeat.yml 進行配置,
業務系統日志格式示例:
2021-04-06 11:21:17,940 [39680] DEBUG Zc - time:0ms update XXX set ModifyTime=GETDATE(), [State] = 190, [FuZeRen] = '張三' where [ID] = '90aa9a69-7a33-420e-808c-624693c65aef' and [CompanyID] = '9e52867e-2035-4148-b09e-55a90b3020d5' 2021-04-06 11:21:21,612 [22128] DEBUG Service ModelBase - time:0ms (/api/XXX/XXX/XXX?InfoID=6d43b831-6169-46d2-9518-f7c9ed6fe39c&ValidateStatus=1)更新材料狀態 2021-04-06 11:21:21,612 [22128] DEBUG Zc - time:0ms select ID from XXX where InfoRelationID='6d43b831-6169-46d2-9518-f7c9ed6fe39c' 2021-04-06 11:21:21,612 [22128] DEBUG Zc - time:0ms insert into XXXX(ValidateDate ,[ID],[ValidateState],[ValidateUser],[ValidateUserID],[ValidateUnit],[ValidateUnitID],[ValidateUnitType],[InfoRelationID]) values( GETDATE(),'c77cf4ab-71b5-46c7-b91b-2829d73aa700',1,'XXXX','0387f889-e1d4-48aa-b275-2241da1d2c9e','XXXXX有限公司','2f2a94c8-c23c-4e8a-98b3-c32a9b0487f7',0,'6d43b831-6119-46d2-9518-f7c9ed6fe39c') 2021-04-06 03:25:22,237 [46840] ERROR ASP.global_asax - time:0ms 客戶端資訊:Ip:116.238.55.21, 173.131.245.61 瀏覽器:Chrome 版本:68 作業系統:WinNT服務端錯誤資訊: 頁面:http://www.A.com:803/dbapp_53475dbapp_e524534.php 錯誤源:System.Web.Mvc 堆疊跟蹤: at System.Web.Mvc.DefaultControllerFactory.GetControllerInstance(RequestContext requestContext, Type controllerType) at System.Web.Mvc.DefaultControllerFactory.CreateController(RequestContext requestContext, String controllerName) at System.Web.Mvc.MvcHandler.ProcessRequestInit(HttpContextBase httpContext, IController& controller, IControllerFactory& factory) at System.Web.Mvc.MvcHandler.BeginProcessRequest(HttpContextBase httpContext, AsyncCallback callback, Object state) at System.Web.HttpApplication.CallHandlerExecutionStep.System.Web.HttpApplication.IExecutionStep.Execute() at System.Web.HttpApplication.ExecuteStep(IExecutionStep step, Boolean& completedSynchronously)
FileBeat配置:
max_procs: 2
queue:
mem:
events: 2048
flush.min_events: 2048
# ============================== Filebeat inputs ===============================
filebeat.inputs:
# 管理系統
- type: log
enabled: true
encoding: GB2312
paths:
- D:/IIS/www.A.com/logs/*.txt
multiline.pattern: '^\d{4}-\d{1,2}-\d{1,2}'
multiline.negate: true
multiline.match: after
fields:
topic: 'dlbZcZGBSyslogs'
fields_under_root: true
# 單位系統
- type: log
enabled: true
encoding: GB2312
paths:
- D:/IIS/www.B.com/logs/*.txt
### Multiline options
multiline.pattern: '^\d{4}-\d{1,2}-\d{1,2}'
multiline.negate: true
multiline.match: after
fields:
topic: 'dlbZcDWSyslogs'
fields_under_root: true
# 個人系統
- type: log
enabled: true
encoding: GB2312
paths:
- D:/IIS/www.C.com/logs/*.txt
### Multiline options
multiline.pattern: '^\d{4}-\d{1,2}-\d{1,2}'
multiline.negate: true
multiline.match: after
fields:
topic: 'dlbZcMySyslogs'
fields_under_root: true
# 除錯輸出
#output.console:
# pretty: true
#output.file:
# path: "D:/bigData"
# filename: filebeat.log
# -------------------------------- Kafka Output --------------------------------
output.kafka:
# Boolean flag to enable or disable the output module.
enabled: true
hosts: ["192.168.1.10:9092"]
# The Kafka topic used for produced events. The setting can be a format string
# using any event field. To set the topic from document type use `%{[type]}`.
topic: '%{[topic]}'
# Authentication details. Password is required if username is set.
#username: ''
#password: ''
# The number of concurrent load-balanced Kafka output workers.
worker: 2
max_message_bytes: 10000000
# ================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
- script:
lang: javascript
id: my_filter
tag: enable
source: >
function process(event) {
var str = event.Get("message");
var sp = str.split(" ");
var log_datetime = sp.slice(0,2).join(" ");
var regEx = /^\d{4}-\d{2}-\d{2}$/;
var prefix_date = log_datetime.substring(0, 10);
if(prefix_date.match(regEx) != null)
{
event.Put("server","221");
log_datetime = log_datetime.replace(",",".");
log_datetime = log_datetime.replace("'","");
regEx = /^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3}$/;
if(log_datetime.match(regEx) != null)
{
event.Put("log_datetime",log_datetime);
event.Put("log_index",sp.slice(2,3).join(" ").replace("[","").replace("]",""));
event.Put("log_level",sp.slice(3,4).join(" "));
if(str.match(/(?<=time:)\S*(?=ms)/)!=null)
{
var spTime= str.split("time:");
var spPre = spTime[0].split(" ");
var spNext = spTime[1].split(" ");
event.Put("log_class",spPre.slice(4).join(" "));
var log_execTime= spNext.slice(0,1).join(" ").replace("ms","");
regEx = /^(\-|\+)?\d+(\.\d+)?$/;
if(regEx.test(log_execTime))
{
event.Put("log_execTime",log_execTime);
}
else
{
event.Put("log_execTime","-1");
}
event.Put("log_message",spNext.slice(1).join(" "));
}
else
{
event.Put("log_class",sp.slice(4,5).join(" "));
event.Put("log_execTime","-1");
event.Put("log_message",sp.slice(6).join(" "));
}
return;
}
}
event.Cancel();
}
- drop_fields:
fields: ["@timestamp", "message", "host", "ecs", "agent", "@metadata", "log", "input"]
以上的配置說明:
max_procs:設定可以同時執行的最大CPU數;
queue :內部佇列資訊;
Filebeat inputs:日志資料源采集的入口;
其他欄位如下說明:
#日志型別
- type: log
#開啟
enabled: true
#編碼格式,有中文必須設定
encoding: GB2312
#路徑
paths:
- D:/IIS/www.A.com/logs/*.txt
#多行匹配前綴
multiline.pattern: '^\d{4}-\d{1,2}-\d{1,2}'
#開啟多行匹配
multiline.negate: true
#開啟多行之后,匹配是合并到上一條資訊
multiline.match: after
#增加一個欄位,用于kafka的topic的識別
fields:
topic: 'dlbZcZGBSyslogs'
# 欄位增加在輸出json的根目錄下
fields_under_root: true
//https://www.cnblogs.com/EminemJK/p/15165961.html
Kafka Output:kafka的配置資訊,主要是 topic: '%{[topic]}' 的設定,因為這里采集多個資料源,對于不同的topic,在資料源輸入的時候,已經設定好欄位如 topic: 'dlbZcZGBSyslogs' ,所以此處使用占位符靈活設定;
Processors:配置處理器,即對采集的日志資訊進行處理,處理是按行處理,當字串處理即可,可以使用js語法進行對字串進行處理;Filebeat的處理器可以多種多樣,具體可以看檔案,
另外,在除錯的時候,可以采用檔案輸出或Console輸出來觀察處理后輸出的資料格式,再進行微調:
output.file: path: "D:/bigData" filename: filebeat.log
IIS的日志也差不多,只是微調處理邏輯就可以了,一通百通,
其他配置可以參考官網檔案:https://www.elastic.co/guide/en/beats/filebeat/current/index.html
Kafka配置
Kafka沒有特別的處理,在這里只是進行訊息的接收,新建好主題就可以,
//個人系統 bin/kafka-topics.sh --create --zookeeper 192.168.1.10:2181 --replication-factor 1 --partitions 3 --topic dlbZcMySyslogs //單位系統 bin/kafka-topics.sh --create --zookeeper 192.168.1.10:2181 --replication-factor 1 --partitions 3 --topic dlbZcDWSyslogs //管理系統 bin/kafka-topics.sh --create --zookeeper 192.168.1.10:2181 --replication-factor 1 --partitions 3 --topic dlbZcZGBSyslogs
partitions 磁區數的大小,取決設定了多少個消費者,這里我們有三臺服務器做了Clickhouse的集群作為消費者,所以磁區數設定為3,一般情況,消費者總數不應該大于磁區數,每個磁區只能分配一個消費者,
Clickhouse配置
Clickhouse三個分片的集群,如果你是單機的,只需要把語法相應的修改一下即可,
在每臺服務器上創建kafka引擎表:
CREATE TABLE kafka_dlb_ZC_My_syslogs ( log_datetime DateTime64, log_index String, log_level String, log_class String, log_message String, log_execTime Float32, server String ) ENGINE = Kafka SETTINGS kafka_broker_list = '192.168.1.10:9092', kafka_topic_list = 'dlbZcMySyslogs', kafka_group_name = 'dlbZcMySyslogs_sys', kafka_format = 'JSONEachRow', kafka_num_consumers = 1;
創建物體表:
CREATE TABLE dlb_ZC_My_syslogs on cluster cluster_3s_1r ( log_datetime DateTime64, log_index String, log_level String, log_class String, log_message String, log_execTime Float32, server String ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/dlb_ZC_My_syslogs', '{replica}') ORDER BY toDate(log_datetime) PARTITION BY toYYYYMM(log_datetime);
//https://www.cnblogs.com/EminemJK/p/15165961.html
物體表是使用集群來創建的,如果是單機請洗掉 on cluster cluster_3s_1r ,修改表引擎即可,如果已經開啟了zookeeper且開啟復制表,在任一一臺服務器運行運行一次即可,
在每臺服務器上創建物化視圖:
CREATE MATERIALIZED VIEW viem_dlb_ZC_My_syslogs_consumer TO dlb_ZC_My_syslogs AS SELECT * FROM kafka_dlb_ZC_My_syslogs;
創建分布式視圖(可選,單機請忽略):
CREATE TABLE Dis_dlb_ZC_My_syslogs ON CLUSTER cluster_3s_1r AS LogsDataBase.dlb_ZC_My_syslogs ENGINE = Distributed(cluster_3s_1r, 'LogsDataBase', 'dlb_ZC_My_syslogs',rand());
分布式表將聚合集群中每個分片的表資訊,進行執行一次,
運行
順便提供一個快速運行Filebeat和卸載的bat腳本:
運行服務:
//windows server2008以上版本的服務器 cd %~dp0 .\install-service-filebeat.ps1 pause //windows server 2008 和以下的服務器 cd %~dp0 PowerShell.exe -ExecutionPolicy RemoteSigned -File .\install-service-filebeat.ps1 pause
卸載服務:
//windows server2008以上版本的服務器 cd %~dp0 .\uninstall-service-filebeat.ps1 pause //windows server2008和以下版本的服務器 cd %~dp0 PowerShell.exe -ExecutionPolicy RemoteSigned -File .\uninstall-service-filebeat.ps1 pause
運行之后,在任務管理器中,將服務設定為運行即可,
查看分布式資料:
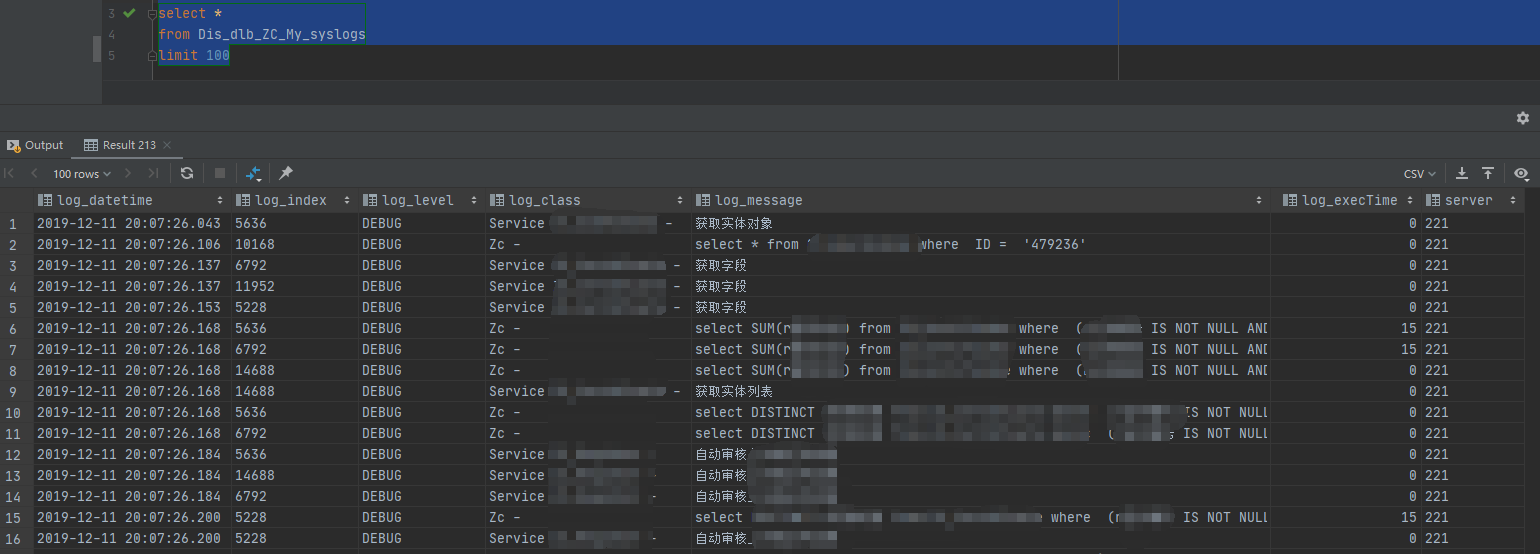
資料采集完畢,完美,
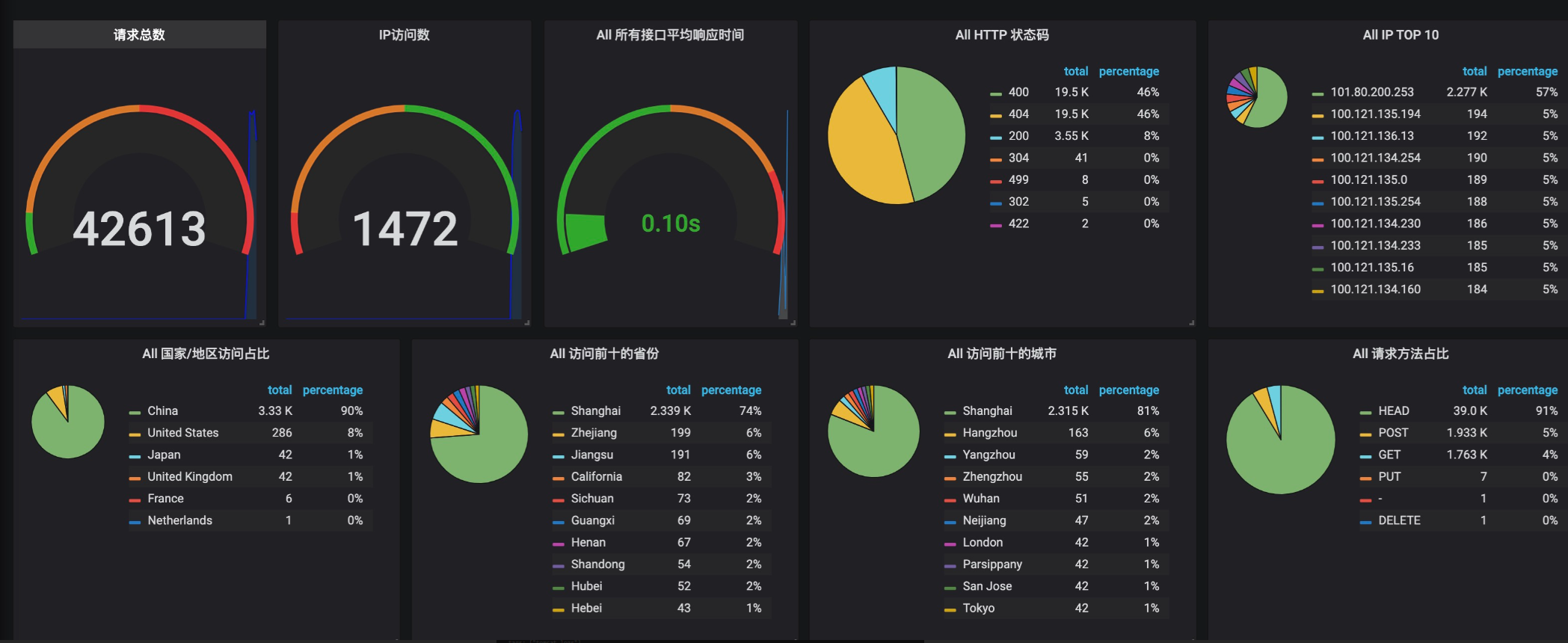
既然資料已經有了,資料可視化方面可以采用多種方式了,以Grafana為例:
最后
下班,周末愉快,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/295063.html
標籤:大數據
下一篇:MySQL JOIN的使用