柯煜昌 顧問軟體工程師
目前從事 RadonDB 容器化研發,華中科技大學研究生畢業,有多年的資料庫內核開發經驗,
| 前言
提及 Redo Log(重做日志)與 LSN(log sequece number)時,經常被問及以下問題:
- MySQL 的 InnoDB 為什么要有 Redo Log?
- LSN 是什么?
- LSN 與 Redo Log 之間有什么相互關系?
- Redo Log 如何輪換?
- ……
基于 MySQL 8.0 的原始碼,以及對 InnoDB 機制一些內部探討與分享,寫了幾篇關于 Redo Log 的文章,本篇先講一下 Redo Log 的日志結構,
什么是頁?
講 Redo Log 之前,先來了解一下 Jeff Dean 對計算機系統中各種存盤系統訪問時間的總結[1]:
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 3,000 ns 3 us
Send 1K bytes over 1 Gbps network 10,000 ns 10 us
Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from disk 20,000,000 ns 20,000 us 20 ms 80x memory, 20X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Credit
------
By Jeff Dean: http://research.google.com/people/jeff/
Originally by Peter Norvig: http://norvig.com/21-days.html#answers
從總結內容可知:記憶體的訪問速度至少是 SSD 的 4 倍、磁盤順序訪問的 80 倍! 磁盤、SSD 順序讀寫明顯要快于隨機讀寫,而且磁盤、SSD 對頻繁的小寫均不友好,因此主流的資料庫采用一次讀寫一個塊,并且使用 buffer/cache 技術盡量減少讀寫次數,InnoDB 稱這種讀寫塊為頁,
寫放大怎么辦?
對于一次事務來說,寫一行資料,對應頁中一個記錄,但是要實作事務的持久化,不光是要往磁盤中寫資料頁,還要寫 Undo 頁,這就是出現了修改一行,需要持久化多個頁到磁盤中,因此性能的損失會比較大,這也就是通常所說的寫放大問題,因此人們提出了先寫日志 WAL(write ahead log) 的方式進行優化,即將 頁 中修改的操作,轉換為重做日志(Redo Log),
在事務提交時,不需要保證修改的頁持久化到磁盤中,只需保證日志已經持久化存盤到磁盤中即可,如果出現掉電或者故障的場景,記憶體的頁雖然丟失,但是可以通過磁盤的頁進行 Redo 重做,恢復更改的記憶體頁,
在絕大部分情況下,Redo Log 資料比資料頁和 Undo 頁要小,而且按順序寫入,性能也比寫放大后的好,由此可以看出,資料庫使用 Redo 對資料的操作,速度上接近記憶體,持久性接近磁盤,
| Redo Log 的實作方式
設計思路
InnoDB 的 Redo Log 是一組檔案的集合,默認是兩個,每個日志檔案又由一組 512 Byte 大小的日志塊組成,

每個日志檔案前 4 個日志塊保留,其中第一個日志檔案里的前 4 塊保存著 Redo 日志的元資料資訊,日志檔案大小在初始化就已經確定,日志塊邏輯上組成一個環,回圈使用,
細心的讀者會發現,日志檔案前 4 個保留日志塊,有 2 個 checkpoint 塊,不免會有如下兩個疑問:
1. 為什么會有兩個 checkpoint 塊?
checkpoint 是崩潰恢復程序中應用日志的起點,如果 checkpoint 塊寫入如果出現故障或者掉電,InnoDB 就無法找到日志的起點,如果兩個 checkpoint 輪換寫入,遇到寫入checkpoint 塊失敗,可以在另一個 checkpoint 塊上取得上次的 checkpoint LSN 作為起點,
2. 會不會兩個 checkpoint 塊都寫壞?
假設 checkpoint1 掉電損壞,則選擇 checkpoint2 塊選取前一個 checkpoint LSN 做恢復,按照 InnoDB 的輪換演算法,第二次寫入 checkpoint 點的位置仍然是 checkpoint1,再次寫入掉電仍然只會在 checkpoint1 損壞,兩個 checkpoint 塊方法仍然是可靠的,
Header 日志塊
Header 日志塊是描述日志總體資訊的塊,雖然只有第一個日志檔案有內容,但是 InnoDB 每個日志檔案都有 Header 日志塊,
| 宏 | 偏移 | 長度 | 含義 |
|---|---|---|---|
| LOG_HEADER_FORMAT | 0 | 4 | 格式 |
| LOG_HEADER_PAD1 | 4 | 4 | 補齊長度,預留欄位 |
| LOG_HEADER_START_LSN | 8 | 8 | 起始 LSN,最初為固定值 4*k. 如果發現有洗掉 Redo 檔案的動作,則可能是系統表空間第一個頁 page LSN 計算, |
| LOG_HEADER_CREATOR | 16 | 32 | 日志檔案名稱 |
| LOG_HEADER_FLAGS | 48 | 4 | 特殊用途 |
| 其他空間,通常為 0 | 其他空間,通常為 0 | 其他空間,通常為 0 | 其他空間,通常為 0 |
| CHECKSUM | 508 | 4 | 日志塊的 checksum checksum 用來驗證 block 的是否完整和正確, |
checkpoint 日志塊
日志檔案中記錄檢查點資訊的日志塊有兩個,每個 checkpoint 日志塊結構如下:
| 宏 | 偏移 | 長度 | 含義 |
|---|---|---|---|
| LOG_CHECKPOINT_NO | 0 | 8 | checkpoint 序號 |
| LOG_CHECKPOINT_LSN | 8 | 16 | checkpoint LSN |
| LOG_CHECKPOINT_OFFSET | 16 | 8 | checkpoint 的檔案偏移 |
| 其他空間,通常為 0 | 其他空間,通常為 0 | 其他空間,通常為 0 | 其他空間,通常為 0 |
| CHECKSUM | 508 | 4 | 日志塊的 checksum |
普通日志塊
記錄日志記錄資訊的日志塊,頭 12 個位元組與最后 4 個位元組記錄日志的描述資訊,其他空間存盤日志記錄,日志塊結構如下:
| 偏移 | 長度 | 含義 | |
|---|---|---|---|
| LOG_BLOCK_HDR_NO | 0 | 4 | 日志塊的序號 最高位元位是 flushbit |
| LOG_BLOCK_HDR_DATA_LEN | 4 | 2 | 塊內日志長度 包含頭部資訊與 checksum,最高位指示是否加密 |
| LOG_BLOCK_FIRST_REC_GROUP | 6 | 2 | 第一條全新日志開始位置 |
| LOG_BLOCK_CHECKPOINT_NO | 8 | 4 | 本次 checkpoint 的序號 |
| 其他空間,用以存盤日志記錄 | 其他空間,用以存盤日志記錄 | 其他空間,用以存盤日志記錄 | 其他空間,用以存盤日志記錄 |
| CHECKSUM | 508 | 4 | 日志塊的 checksum |
示例
一條日志記錄可以跨多個日志塊,一個日志塊可以包含多個日志記錄,
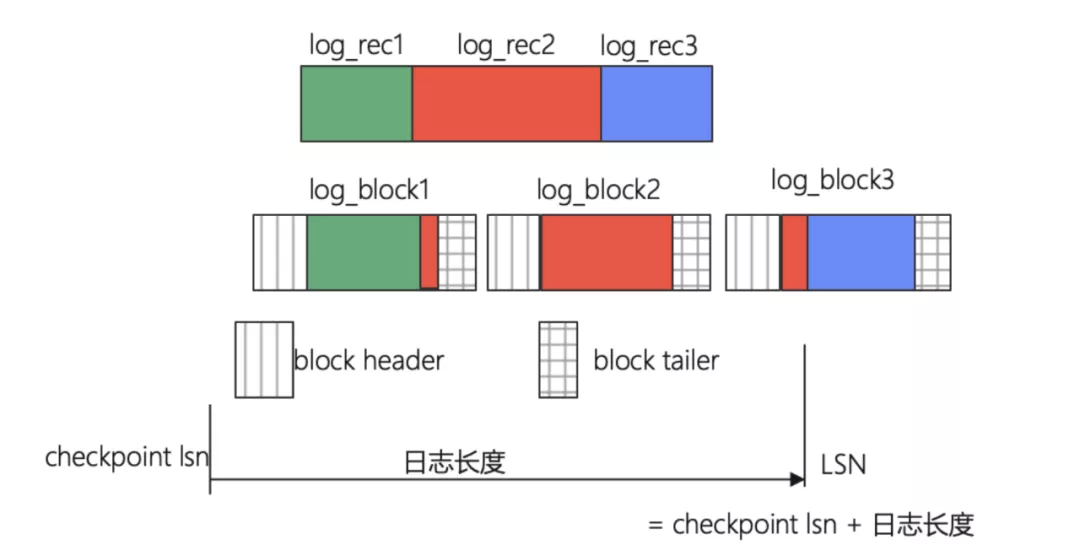
*圖中 block tailer 表示 checksum,
示例結構說明
- 上圖中,三個日志塊的 LOG_BLOCK_HDR_DATA_LEN 值都為 512;
- log block1 的 LOG_BLOCK_FIRST_REC_GROUP 值為 12;
- log block2 無全新日志,則值為 0;
- log block3 值為 12+ 紅色部分的長度;
- 日志塊的塊號依據 LSN 位置換算,
1. checkpoint 的序號是怎么計算的?
假設當前 checkpoint 的序號為 4,InnoDB 推進檢查點時候,寫入到 checkpoint 塊的checkpoint 序號為 4,推進檢查點之后,當前系統的 checkpoint 序號就加 1 變成 5,新寫的日志塊的 check point 需要都是 5,
2. 為什么會有 flushbit?
通常情況下,log block 的序號最高位都是 1,為 0 的情況,log buffer 中日志塊還未寫完,而 log buffer 已經滿,此時 log buffer 的日志塊都寫入到磁盤中,但是最后一個日志塊肯定是不完整的,此時 flush bit 為 0,表示該日志塊是不完整的,將來 InnoDB 會清空 log buffer,重新將該日志塊寫完整,
| Redo Log 的切換寫入
假設 LSN 起點為 1,每個日志檔案長度為 5,下圖展示了 LSN 增長時如何切換檔案,
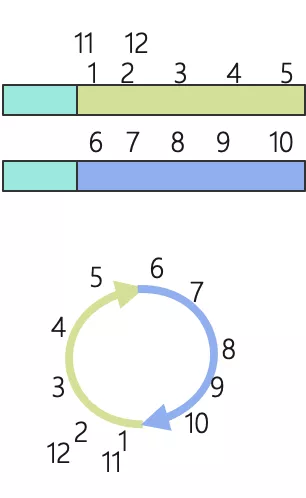
很顯然,LSN 1~5 在第一個檔案,6~10 在第二個檔案,LSN 11 在第一個檔案 LSN 為 1 所在位置,Redo Log 應該寫在哪個檔案,是可以依據 LSN 計算出來的,
那么,Redo Log 是如何將順序寫入的結構實作為一個邏輯的環呢?
| 從 LSN 到 Offset
日志在邏輯上是一個環,checkpoint LSN 表示,LSN 之前的修改的 page 已經成功持久化到磁盤中,相關的 Redo Log 的使命已經結束,作為崩潰恢復的起點,它一定是在某個 MTR 的 END LSN 位置,因此位置可能在某日志塊邊緣,也可能在日志塊中,
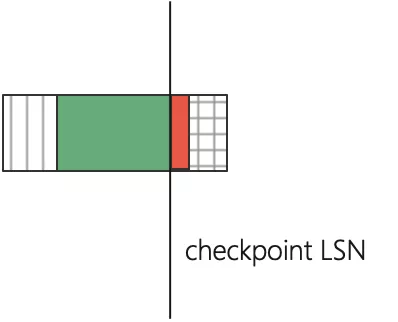
通過前面的內容得知,checkpoint 塊保存的資訊有 checkpoint LSN 與 LOG_CHECKPOINT_OFFSET,checkpoint offset 是 checkpoint LSN 在日志檔案組中的偏移位置,因此 LSN 與 offset 計算公式如下:
size_capacity = log.n_files * (log.file_size - LOG_FILE_HDR_SIZE);
日志的容量是檔案個數乘以日志檔案有效空間(檔案大小減去四個 logblock),
if (lsn >= log.current_file_lsn) {
delta = lsn - log.current_file_lsn;
delta = delta % size_capacity;
} else {
/* Special case because lsn and offset are unsigned. */
delta = log.current_file_lsn - lsn;
delta = size_capacity - delta % size_capacity;
}
在啟動時,current_file_lsn 通常是 checkpoint LSN, current_file_real_offset 通常是 checkpoint offset,LSN 比 checkpoint LSN 大,所以delta = lsn - log.current_file_lsn 表示 LSN 與 checkpoint LSN 的距離,這個距離可能會超過 size_capacity ,因此使用了取余操作,如果 LSN 比 checkpoint LSN 小呢?這說明 LSN 在 checkpoint LSN 前面,checkpoint LSN 是起點,也是終點,checkpoint LSN + size_capacity 的位置,也是checkpoint LSN 所在的位置,所以delta = size_capacity - delta % size_capacity; 與 - delta % size_capacity是等效的,為避免 offset 計算出現負數的情況,可做如下處理:
size_offset = log_files_size_offset(log, log.current_file_real_offset);
size_offset = (size_offset + delta) % size_capacity;
return (log_files_real_offset(log, size_offset));
這個log_files_size_offset是將current_file_real_offset 轉換成日志檔案有效空間的偏移位置,計算公式為:
current_file_real_offset - LOG_FILE_HDR_SIZE*(1 + current_file_real_offset/log.file_size)
將 curren_file_real_offset 減掉檔案頭的 4 個 logblock 大小,無跨檔案就減一次,跨幾個檔案就多減幾次,再加上偏移值,轉換成 file_real_offset 就得到了真實的位置,
| 總結
本文介紹了 Redo Log 與各個日志塊的基本結構,并通過示例說明了 Redo Log 的兩個checkpoint 作用以及 LSN 如何與日志位置對應,
Redo Log 是一個非常重要的組成部分,LSN 通常作為資料庫中資料變更的邏輯時鐘,與 Redo Log 密切不可分,弄清 Redo Log 的作用與機制,就能輕松理解 LSN、資料庫持久化這些概念,
參考
[1]. https://d-k-ivanov.github.io/docs/CheatSheets/Latency_Numbers/
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/296754.html
標籤:MySQL