有如下資料:
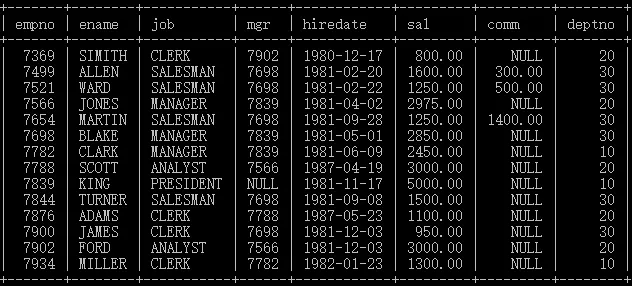
一個簡單的分組查詢的案例
按照部門編號deptno分組,統計每個部門的平均工資,
select deptno,avg(sal) avgs
from emp
group by deptno;
結果如下:
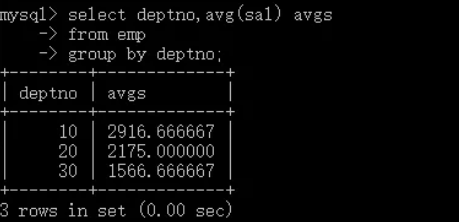
group by關鍵字語法詳解

group by是用于分組查詢的關鍵字,一般是配合sum(),avg(),count(),max(),min()聚合函式使用的,也就是說SQL陳述句中只要有group by,那么在select后面的展示欄位中一般會有聚合函式(5個聚合函式)中的一個或多個函式出現,觀察上圖用表中的欄位A進行分組后,一般就需要對表中的其它欄位,使用聚合函式,這樣意義更大,而不是還對欄位A使用聚合函式,
當SQL陳述句中使用了group by后,在select后面一定有一個欄位使用了聚合函式(5個聚合函式),但是除了這個聚合函式,select后面還可以添加其他什么欄位嗎?
答案肯定是可以的!但是該欄位有一定的限制,并不是什么欄位都可以,也就是說,當SQL陳述句中使用了group by關鍵字后,select后面除了聚合函式,就只能是group by后面出現的欄位,也就是圖中的欄位A,select后面只能存在group by后面的欄位,
分組前篩選和分組后篩選
原始表和結果集的概念
- 原始表指的是資料庫中真正存在的那個表,使用【select * from 表名】查詢出來的就是原始表資訊,
- 結果集指的是在SQL陳述句中,添加其它任何一個限制條件,最終展示給我們表,都是結果集,添加不同的限制條件,查詢出來的結果集也是不同的,
- 原始表只有一個,結果集卻是各種各樣的,
where篩選和having篩選選用
- 只要是需求中,涉及到聚合函式做條件的情況,一定是分組后的篩選
- 能用分組前篩選的,就優先考慮分組前的篩選,(考慮到性能問題)

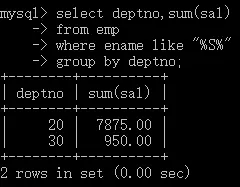
分組前篩選
- 查詢姓名中包含S字符的,每個部門的工資之和,
select deptno,sum(sal)
from emp
where ename like '%S%'
group by deptno;
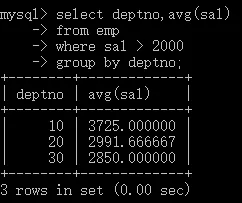
- 查詢工資大于2000的,不同部門的平均工資,
select deptno,avg(sal)
from emp
where sal > 2000
group by deptno;
分組后篩選
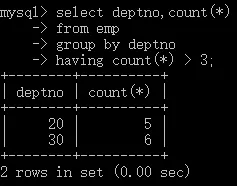
- 查詢部門員工個數大于3的部門編號和員工個數,
select deptno,count(*)
from emp
group by deptno
haveing count(*) > 3;
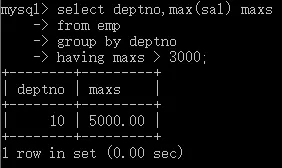
- 查詢每個部門最高工資大于3000的部門編號和最高工資,
select deptno,max(sal) maxs
from emp
group by deptno
having maxs count(*) > 3;
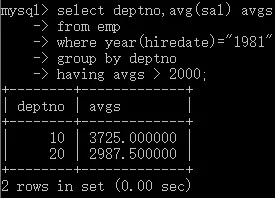
分組前篩選和分組后篩選合用
- 查詢1981年入職的,不同部門間工資的平均值大于2000的部門編號和平均值,
select deptno,avg(sal) avgs
from emp
where year(hiredate) = '1981'
group by deptno
having avgs > 2000;
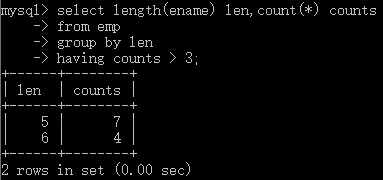
分組查詢(按函式分組)
- 按員工姓名的長度分組,查詢每一組的員工個數,篩選員工個數>3的有哪些?
select length(ename) len, count(*) counts
from emp
group by len
having counts > 3;
分組查詢(按多個欄位分組)
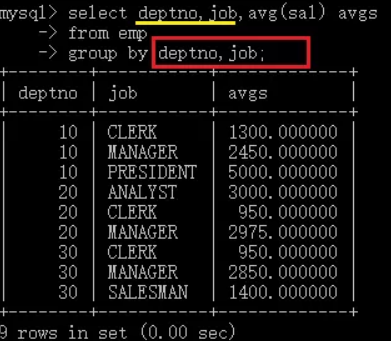
- 查詢每個部門每個工種的員工的平均工資,
select deptno,jop,avg(sal) avgs
from emp
group by deptno,job;
group by和order by
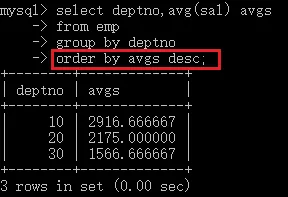
- 查詢每個部門的員工的平均工資,按照平均工資降序,
select deptno,jop,avg(sal) avgs
from emp
group by deptno
order by avgs desc;
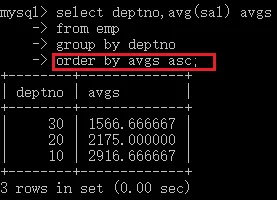
- 查詢每個部門的員工的平均工資,按照平均工資升序,
select deptno,jop,avg(sal) avgs
from emp
group by deptno
order by avgs asc;
總結
- 分組函式做條件,肯定是放在
having子句中, - 能用分組前篩選的,就優先考慮使用分組前篩選,(
where篩選) group by子句支持單個欄位分組,多個欄位分組(多個欄位之間用逗號隔開沒有順序要求),還支持函式分組(用的較少),
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/297240.html
標籤:MySQL