作者:柯煜昌 顧問軟體工程師
目前從事 RadonDB 容器化研發,華中科技大學研究生畢業,有多年的資料庫內核開發經驗,
你將 Pick 這些內容:
- 云原生的概念
- 云原生資料庫的概念
- 兩種主流技術路線分析
- 六種云原生資料庫方案和功能介紹
- 云原生資料庫的核心功能和價值
背景
隨著云計算的蓬勃發展,IT 應用轉向云端,云服務出現如下若干特點:
- 提供按需服務;
- 用戶只愿支付運營費用而不愿支付資產費用;
- 云服務提供商集群規模越來越大,甚至遍布全球,集群達到云級規模(Cloud-Scale),
根據以上特點,要求云產品需要提供一定 “彈性”(Elastic),而且達到云級規模;節點故障如同噪聲” 一樣不可避免,這又要求云服務有一定的 “自愈”(Resilience)能力,
起初,通過借助 IaaS,直接將傳統的資料庫 “搬遷” 到云上,于是出現了關系型資料庫服務(RDS),這樣雖然能部分實作 “彈性” 與 “自愈”,但是這種方案存在資源利用率低,維護成本高,可用性低等問題,于是,設計適應云特點的云原生資料庫就至關重要,
RDS 的挑戰
以 MySQL 為例,如果要實作高可用或者讀寫分離集群,則需要搭建 binlog 復制集群,
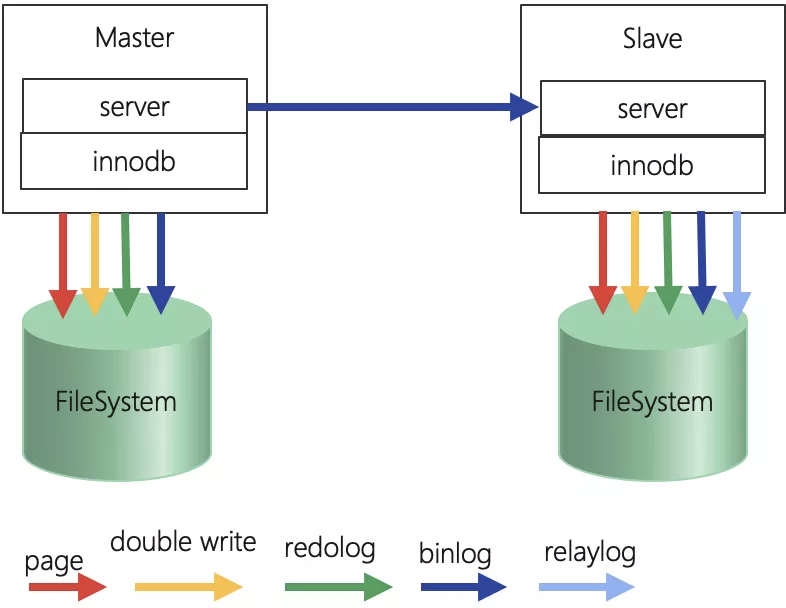
圖 1:MySQL 復制架構
如上圖所示,除了頁寫入與 double write,redo log 寫入操作外,還有 binlog 與 relay log 的寫入,
| 缺陷 | 說明 |
|---|---|
| 寫放大嚴重 | 如果以上架構中,FileSystem 部署在分布式檔案系統中,頁的寫操作,會因為副本復制的機制將 IO 放大,最后 IO 延遲也會放大, |
| 資源浪費嚴重 | 1. binlog 復制是為了適配 MySQL 所有存盤引擎,屬于邏輯復制,本質是將 SQL 在從實體執行(除了沒有主實體的鎖爭用外,其他代價幾乎一樣),效率不高,也浪費了 CPU 與記憶體的資源, 2. 擴展集群的計算能力時,不得不同時擴展存盤空間,導致磁盤資源的浪費, |
| 備份恢復慢 | 無論是物理備份/恢復,還是邏輯備份/恢復,備份操作均會上鎖,影響正常業務進行,并且,備份恢復的時間也隨著存盤容量的增大而線性增長, |
| 擴展代價大 | 1. 新增從實體,首先要從備份中恢復資料,然后應用binlog以達到與主實體一致的狀態,這個程序耗時取決于恢復的時間以及binlog日志應用的時間,資料量大、資料狀態過時的情況下,耗時費力而且不保證正確,彈性能力有限, 2. 存盤容量受限于單機存盤容量,無法自由擴展, |
| 可用性低 | Aurora[1]指出,在高規模的集群環境中,軟體或者硬體故障如同“背景噪聲”那樣不可避免,并且縮短平均故障間隔時間(MTTF)是非常困難的,可行的方法是減少平均恢復的時間(MTTR)從而達到高可用性, 如上所示,RDS 仍然是傳統的備份恢復的方法修復故障,如果資料量大的話,可能是數小時,超過平均故障時間間隔(Aurora 是 10s),出現更多節點故障,可能使得共識演算法無效(超過半數),可用性就大大打折扣, |
| 運維成本高 | 備份/恢復與擴展,均需要專業 DBA 團隊運維,每個步驟出現錯誤需要人工檢查, |
云原生資料庫簡介
為了解決以上問題,需要針對云上服務的特點,改造或者開發新一代云資料庫,這便是云原生資料庫,
| 特點 | 說明 |
|---|---|
| 計算存盤分離 | 對存盤與計算進行解耦合,實作存盤與計算分離, |
| 無狀態 | 計算節點無狀態或較少狀態, |
| 存盤集群靈巧化 | 采用小存盤塊方式組織副本,用以減少平均恢復時間,多副本共識演算法,實作存盤的高可用與故障“自愈”能力, |
通過解耦合與少狀態,計算節點擴展就會很輕量,擴展速度近乎行程啟動的速度,避免擴展計算資源的時候,不得不浪費存盤資源的窘境,
解耦合也使得存盤節點也少了一定的約束,可以使用成熟的分布式存盤技術實作靈巧化,降低運維成本提高可用性,
接下來將介紹目前兩種主流的技術路線和幾種知名的方案,
1 Spanner 類
以 Google 的 Spanner[2] 為代表,基于云原生開發全新的資料庫,受其影響,產生了CockrochDB、TiDB、YugabyteDB 等產品,
1.1 架構
以 TiDB[3] 架構圖為例:
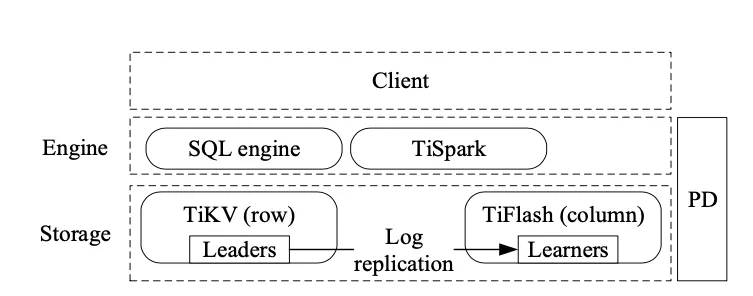
圖 2:TiDB 架構圖
總體來說,此類產品其特點都是在 key-value 存盤基礎上包裝一層分布式 SQL 執行引擎,使用 2PC 提交或者其變種方案實作事務處理能力,計算節點是 SQL 執行引擎,可以徹底實作無狀態,本質是一個分布式資料庫,
1.2 存盤高可用性
Spanner 將表拆分為 tablet,以 tablet 為單位使用多副本 + Paxos 演算法 實作,
TiDB 為 Region 為單位使用多副本 + Multi-Raft 演算法,而 CockroachDB 則采用 Range 為單位進行多副本,共識演算法也是使用 Raft,
Spanner 中 key-value 持久化方案,邏輯上仍然是基于日志復制的狀態機模型(log-replicated state machines)上再加共識演算法實作,
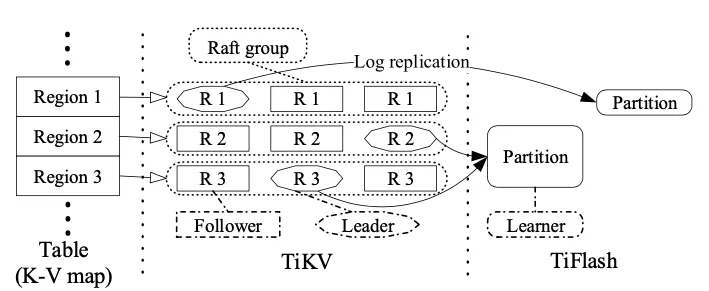
圖 3:multi-Raft 存盤架構
1.3 優缺點
| 說明 | |
|---|---|
| 優點 | 1. 徹底的 Share-Nothing 2. 號稱全球部署 3. 使用 key-value 結構與 LSM 樹,以及日志復制自動機機制,天然無寫放大效應 4. 不需要人為分庫分表,有很好的橫向擴展能力 |
| 缺點 | 1. 全新開發作業量大,技術不算成熟 2. 性能不佳 3. 事務處理能力有限 ?3.1 在記憶體中處理事務沖突,有沖突的需要讀寫等待或者提交等待, ?3.2 如:Spanner 對有沖突的事務 TPS 能力最大只有 125 4. SQL 支持能力有限 ?4.1 如:YugabyteDB 不支持 Join 陳述句 |
2 Aurora 類
Aurora 是亞馬遜推出的云原生資料庫,與 Google 的技術路線不同,Aurora 是傳統的 MySQL(PostgreSQL)等資料庫進行計算與存盤分離改造,進而實作云原生的需求,但其本質仍然是單體資料庫的讀寫分離集群,
Aurora 論文對 Spanner 的事務處理能力并不滿意,認為它是為 Google 重讀(read-heavy)負載定制的資料庫系統[1] ,這種方案得到一些資料庫廠商的認同,出現了微軟 Socrates、阿里PolarDB、騰訊 CynosDB、極數云舟 ArkDB 以及華為 TarusDB 云原生資料庫等,
2.1 架構
Aurora 架構如下:
圖 4:Aurora 架構
下圖綠色部分為日志流向,
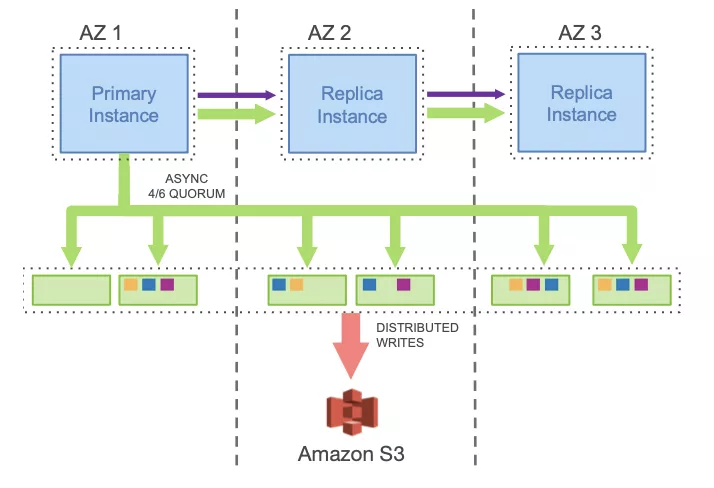
圖 5:Aurora 網路 IO
由于傳統資料庫持久化最小單位是一個物理頁,哪怕修改一行,持久化仍然是一個頁,加上需要寫 redo 日志與 undo 記錄,本身就存在一定的寫放大問題,如果機械的將檔案系統替換成使用分布式檔案系統,并且為了實作高可用采用多副本,則寫放大效應進一步放大,導致存盤網路成為瓶頸而性能無法接受,
Aurora 繼承了 Spanner 的日志持久化的思想,甚至激進提出“日志即資料庫”的口號,其核心思想是存盤網路盡量傳輸日志流,對于讀操作,存盤網路傳輸資料頁在所難免,但是計算節點可以通過 buffer pool 來優化,
它對傳統資料庫進行了如下改造:
- 資料庫主實體變成計算節點,資料庫主實體不再進行刷臟頁動作,僅僅向存盤寫日志,存盤應用日志實作持久化,即日志應用下沉到存盤,資料庫主實體沒有后臺寫動作,沒有 cache 強制刷臟替換,沒有檢查點;
- 資料庫復制實體獲取日志內容,通過日志應用更新自身的 buffer/cache 等記憶體物件;
- 主實體與復制實體共享存盤;
- 將崩潰恢復,備份、恢復、快照功能下放到存盤層,
并且,以原有 S3 存盤系統為基礎,對存盤進行如下改造:
- 將存盤分段(Segment),以 10G 作為分段單位大小, 每個分段共六個副本,部署于三個可用區(Available Zone),每個可用區兩個副本,Aurora 將這六個分段稱為一個保護組(Protection Group,PG),實作高可用,
- 存盤節點能接收日志記錄應用來實作資料庫物理頁的持久化,并且使用 Gossip 協議同步各個副本間的日志,
存盤能提供多版本物理頁,用以適配多個復制實體的延遲,并且后臺有歷史版本頁面回收執行緒,
持久化頁存盤流程圖如下:
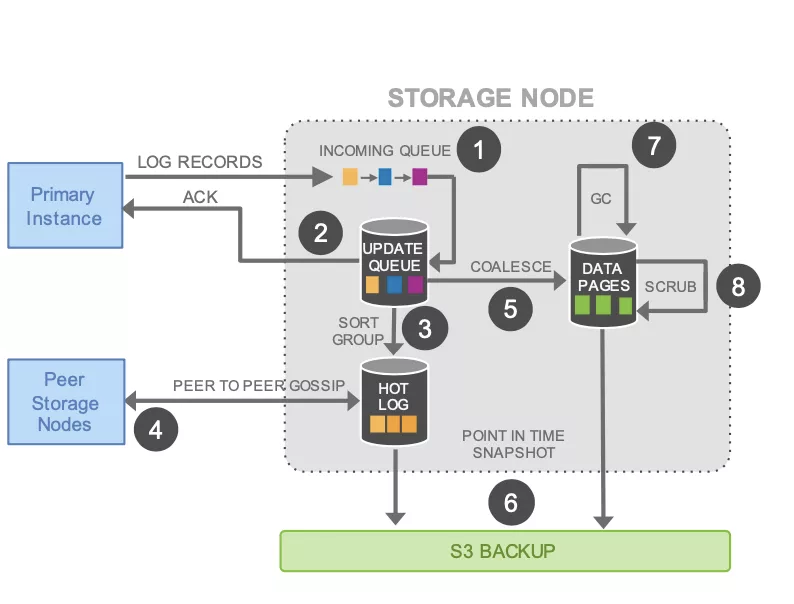
圖 6:持久化存盤流程
2.2 高可用
Aurora 采用仲裁協議(Quorum)多數派投票方式來檢測故障節點,這種高可用的前提是,10G 分段恢復時間為 10 秒,而 10 秒內出現第二個節點故障的可能性幾乎為 0,
它采用 3 個可用區,可以形成 4/6 仲裁協議(6 個節點,寫需 4 個投票,讀需 3 個投票),最壞情況是某個可用區出現災害(地震,水災,恐怖襲擊等)時,同時隨機出現一個節點故障,此時仍然有 3 個副本,可以使用 2/3 仲裁協議(3 個節點,寫需 2 個投票,讀需 2 個投票)繼續保持高可用性(AZ+1 高可用),
| 說明 | |
|---|---|
| 優點 | 1. 在成熟的資料庫系統進行改造,技術相對成熟穩定、作業量小 2. 事務處理能力,性能能保持傳統資料庫的優勢 |
| 缺點 | 1. 本質仍然是改良的讀寫分離集群 2. 有修改一行寫一個頁的寫放大問題,需要小心處理 3. 需要 proxy 等組件才能支持分布式事務 |
3 CynosDB 方案
CynosDB[9] 幾乎復刻了 Aurora 的實作方式,但是有其自身的特點:
- 存盤多副本之間用 Raft 演算法保證高可用,Raft 演算法包含了 Quorum 仲裁演算法,而且更加靈活;
- 與 Aurora 一樣,主從計算節點通過網路傳輸 redo 日志,同步雙方的 buffer cache 以及其他記憶體物件,
4 PolarDB 方案
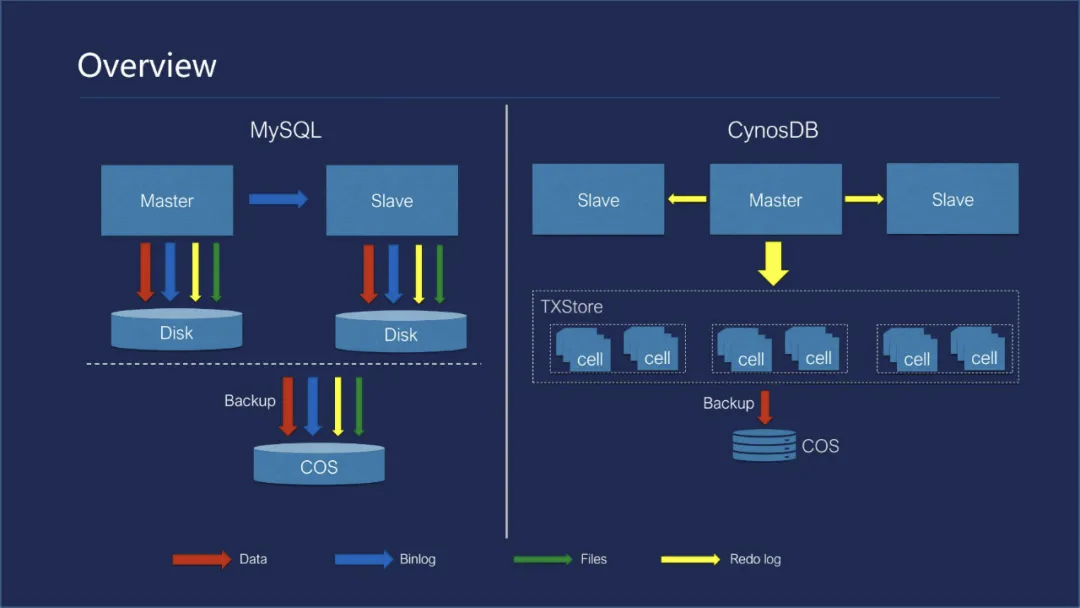
圖 7:PolarDB 架構
PolarDB[5] 也是存盤與計算分離架構,但與 Aurora 最大的不同,就是沒有將 redo 日志下放到存盤進行處理,計算節點仍然要向存盤寫物理頁,僅主實體與復制實體之間使用 redo 日志進行物理復制同步 buffer pool [4]、事務等其他記憶體物件,使用現有的分布式檔案系統,不對其進行改造,
PolarDB 目前集中于分布式檔案系統優化(PolarFS),以及查詢加速優化(FPGA 加速),
5 Socrates 方案
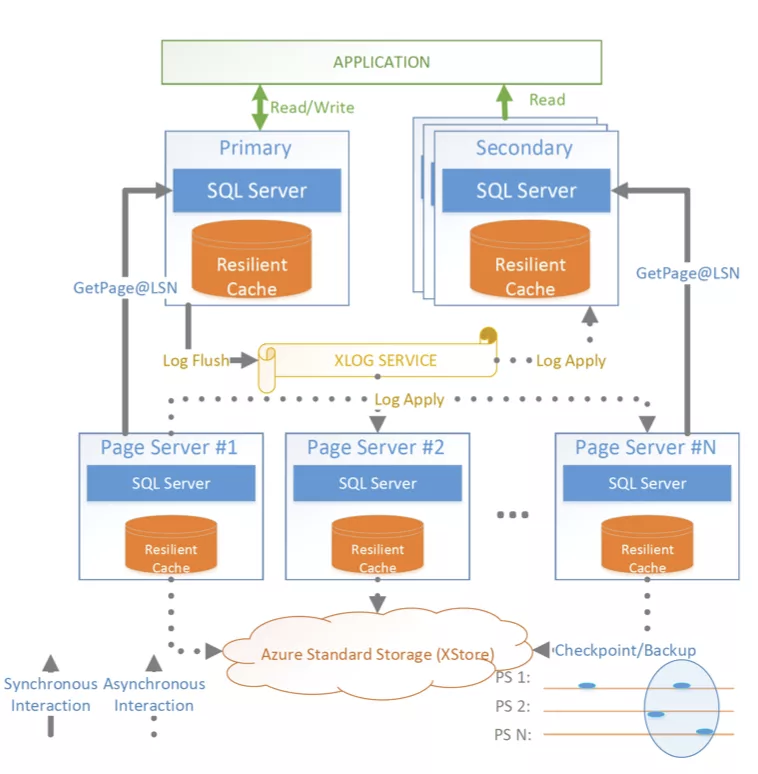
圖 8:Socrates 架構
Socrates[7] 是微軟新研發的 DaaS 架構,與 Aurora 類似,使用存盤與計算分離架構,強調日志的作用,但是 Socrates 采用的復用已有 SQL Server 組件:
- SQL Server 為了支持 Snapshot 隔離級,提供了多版本資料頁(Page Version Store)的功能;
- 使用 SSD 存盤作為 buffer pool 的擴展(Reslilient Cache),可以加速故障崩潰恢復程序;
- RBIO Protocol 是擴展的網路協議,用以進行遠程資料頁讀取;
- Snapshot Backup/Restore 快速備份與恢復;
- 新增 XLogService 模塊,
其特點如下:
- 盡量復用了原有 SQL Server 的特性,使用 SQL Server 組件充當 Page Server,模擬 Aurora 的存盤節點;
- Socrates 有一個很大的創新,日志與頁面存盤分離,它認為持久性(durability)不需要使用快速存盤設備中的副本,而可用性(availability)不需要有固定數量的復制節點,因此 XLog 和 XStore 負責 durability,計算節點和 page server 僅用于可用性(它們失效的時候不會丟資料,僅僅是不可用);
- redo 日志傳遞均借助 Xlog Service,而不是通過主從計算節點通過網路傳輸,主實體節點不需要額外進行日志快取來適應從實體節點,
6 TaurasDB 方案
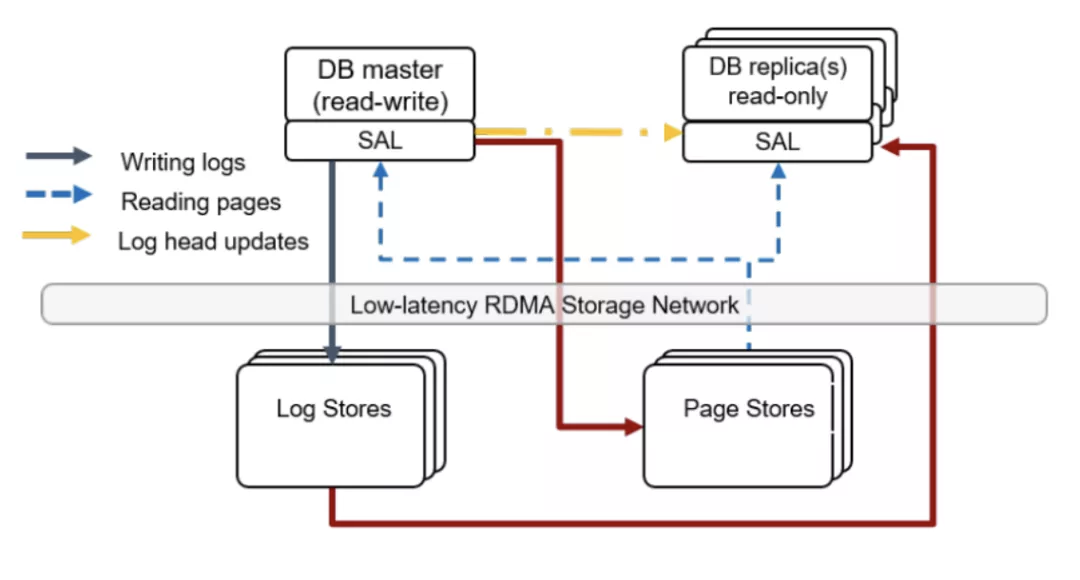
圖 9:TaurasDB 架構
TaurasDB[8] 架構如上圖,它繼承了 Aurora 的日志下沉存盤的思想,也繼承了 Socrates 的日志與頁面存盤分離的思想,并且在計算節點添加了存盤抽象層(SAL),LogStore 與 PageStore 采用與 Aurora 類似的 Quorum 仲裁演算法實作高可用,
總結
云原生資料庫的核心功能
計算與存盤分離,計算節點保持少狀態,甚至無狀態;
基于日志的進行持久化;
存盤分片/分塊,易于擴容;
存盤多副本與共識演算法;
備份、恢復、快照功能下放到存盤層,
知名方案的非核心功能
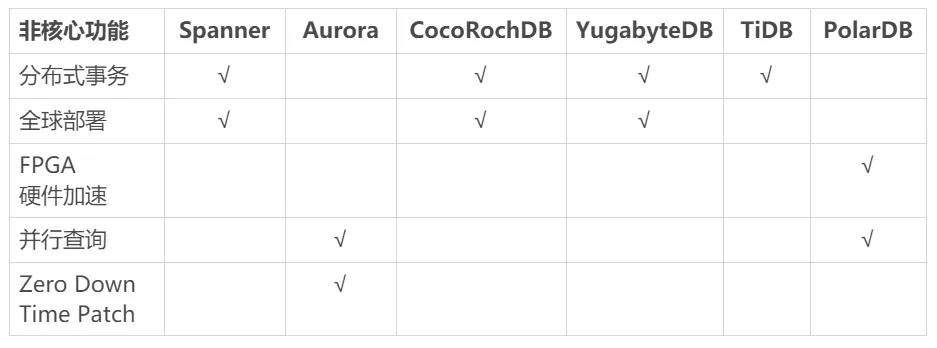
圖 10:非核心性能支持情況
【全球部署】
多機房升級版,需要考慮全球可用性,全球分布式事務能力,以及 GDPR 合規要求的地理磁區(Geo-Partitioning)特性,
由于歐盟出臺通用資料保護條例(GDPR)[6],使得資料不得隨意跨境轉移,違者最高罰款 2000 萬歐元,或者全球營收 4%,原有分布式庫處理技術,例如使用復制表進行 Jion 優化,就存在違規風險,此外,國內以及其他國家均有類似的資料保護法規,合規性將來也會是重要的需求,
云原生資料庫的核心價值
【更高的性能】
基于日志進行持久化與復制更輕量,避免寫放大效應,各大廠商均號稱比原版 MySQL 有 5~7 倍性能,
【更好的彈性】
計算節點無狀態或少狀態,計算節點與存盤擴展靈活,
【更好的可用性】
將資料庫持久檔案分片,以小粒度方式副本方式降低 MTTR,以及共識演算法來實作高可用,
【更高的資源利用率】
計算能力與存盤容量按需伸縮,減少資源浪費,
【更小的成本】
更少的資源、更少的浪費、更少的維護,最終達到更小的成本,
云原生資料庫本質是用現有技術組合,實作云原生需求,而且也是資料庫實作 serverless 的必由之路,
參考文獻
[1]: "Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases"
[2]: "Spanner: Google’s Globally-Distributed Database"
[3]: TiDB: A Raft-based HTAP Database
[4]: PolarDB redo replication https://www.percona.com/live/18/sites/default/files/slides/polardb_p18_slides.pdf
[5]: PolarDB Architecture https://www.intel.com/content/dam/www/public/us/en/documents/solution-briefs/alibaba-polardb-solution-brief.pdf5
[6]: GDPR https://gdpr-info.eu/
[7]: "Socrates: The New SQL Server in the Cloud"
[8]: Taurus Database: How to be Fast, Available, and Frugal in the Cloud
[9]: 騰訊云新一代自研資料庫CynosDB技術詳解——架構設計https://cloud.tencent.com/developer/article/1367387
- 文中圖片均來自以上參考鏈接
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/299904.html
標籤:其他
下一篇:SQL-事務