sql如下,要1000ms左右:
SELECT
a.`org_code` ,a.`org_name` ,
COUNT(1) AS inspectionCar,
SUM(a.seat_number) AS inspectionPassenger,
COUNT( a.vehicle_id LIKE '鄂%' or null ) AS hubeiCar,
SUM( IF(a.vehicle_id LIKE '鄂%', a.seat_number, 0)) AS hubeiCarPassenger
FROM `t_inspection` a
force index(index_org)
where 1 = 1
and a.created_at between '2020-02-18 11:00:00' and '2020-02-18 12:00:00'
GROUP BY a.`org_code`
ORDER BY a.`org_code`;
索引:
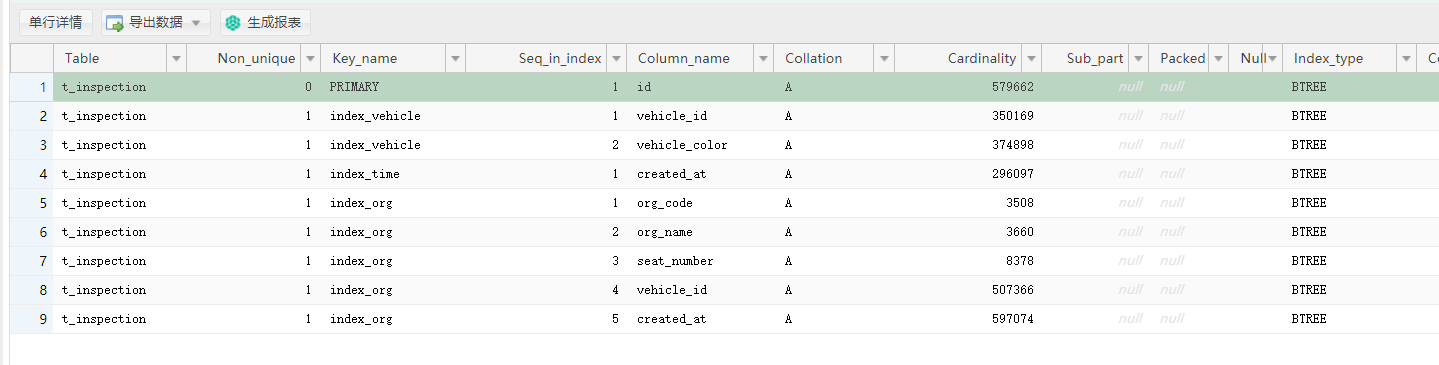
Table Non_unique Key_name Seq_in_index Column_name Collation Cardinality Sub_part Packed Null Index_type Comment Index_comment
t_inspection 0 PRIMARY 1 id A 579803 BTREE
t_inspection 1 index_vehicle 1 vehicle_id A 350254 BTREE
t_inspection 1 index_vehicle 2 vehicle_color A 374989 BTREE
t_inspection 1 index_time 1 created_at A 296169 BTREE
t_inspection 1 index_org 1 org_code A 3509 BTREE
t_inspection 1 index_org 2 org_name A 3661 BTREE
t_inspection 1 index_org 3 seat_number A 8380 BTREE
t_inspection 1 index_org 4 vehicle_id A 507489 BTREE
t_inspection 1 index_org 5 created_at A 597219 BTREE
explain:

id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE a index index_org index_org 935 10000 11.11 Using where; Using index
uj5u.com熱心網友回復:
這個sql應該用index_time 這個indexuj5u.com熱心網友回復:
不加force index的時候就是用的index_time哦,但是還是不行,資料量少的時候sql隨便寫都快,一旦資料量超過某個數,就明顯的變慢了。。。后來在網上說資料量過多的時候會什么回表然后導致索引失效,具體解決辦法也還是沒搞明白
uj5u.com熱心網友回復:
索引失效我解釋下:假設有聯合索引(created_at, org_code)
SELECT * from t_inspection
where created_at = 'xxxxxxxx'
GROUP BY org_code
這條sql可以使用這個聯合索引,where和group by都走索引
SELECT * from t_inspection
where created_at between '2020-02-18 11:00:00' and '2020-02-18 12:00:00'
GROUP BY org_code
created_at范圍查詢后聯合索引只能用到created_at,只有一半
如果你直接用org_code索引,那么就是全表掃描,索引幾乎都用不上
如果直接用created_at索引,至少where走索引,group by不能
uj5u.com熱心網友回復:
把索引 index_org 的順序調整一下:create index_org on t_inspection(created_at, org_code, org_name,seat_number, vehicle_id)
順便把索引 index_time 刪了,冗余了;陳述句中的 force index 也不用了。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/30014.html
標籤:MySQL
下一篇:MySQL資料庫資料表