explain有何用處呢: 為了知道優化SQL陳述句的執行,需要查看SQL陳述句的具體執行程序,以加快SQL陳述句的執行效率,
? 可以使用explain+SQL陳述句來模擬優化器執行SQL查詢陳述句,從而知道mysql是如何處理sql陳述句的,通過查看執行計劃了解執行器是否按照我們想的那樣處理SQL,
? 官網地址: https://dev.mysql.com/doc/refman/5.5/en/explain-output.html
1、執行計劃中包含的資訊
| Column | Meaning |
|---|---|
| id | The SELECT identifier |
| select_type | The SELECT type,查詢型別 |
| table | The table for the output row |
| partitions | The matching partitions |
| type | The join type 訪問型別 |
| possible_keys | The possible indexes to choose |
| key | The index actually chosen |
| key_len | The length of the chosen key |
| ref | The columns compared to the index |
| rows | Estimate of rows to be examined |
| filtered | Percentage of rows filtered by table condition |
| extra | Additional information |
id列
select查詢的序列號(一組數字),表示查詢中執行select子句或者操作表的順序
id號分為三種情況:
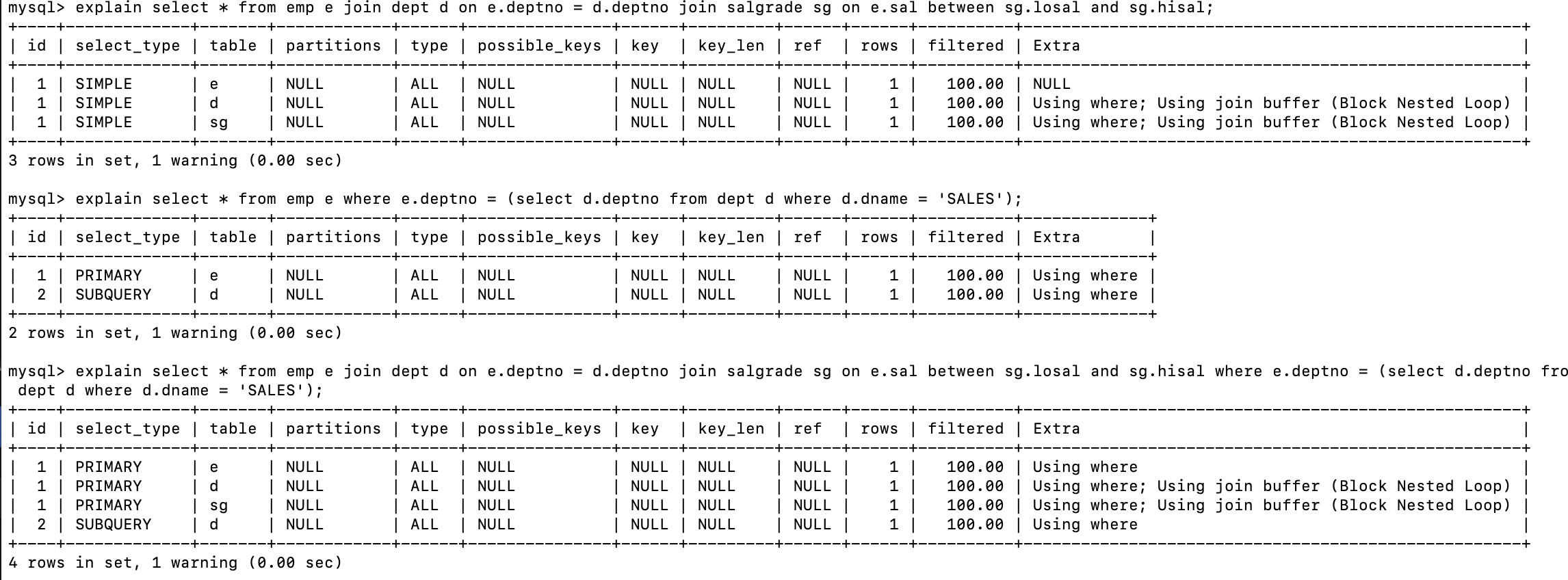
? 1、如果id相同,那么執行順序從上到下
mysql> explain select * from emp e join dept d on e.deptno = d.deptno join salgrade sg on e.sal between sg.losal and sg.hisal;
+----+-------------+-------+------------+...
| id | select_type | table | partitions |...
+----+-------------+-------+------------+...
| 1 | SIMPLE | e | NULL |...
| 1 | SIMPLE | d | NULL |...
| 1 | SIMPLE | sg | NULL |...
+----+-------------+-------+------------ ...
? 2、如果id不同,如果是子查詢,id的序號會遞增,id值越大優先級越高,越先被執行
mysql> explain select * from emp e where e.deptno = (select d.deptno from dept d where d.dname = 'SALES');
+----+-------------+-------+------------+...
| id | select_type | table | partitions |...
+----+-------------+-------+------------+...
| 1 | PRIMARY | e | NULL |...
| 2 | SUBQUERY | d | NULL |...
+----+-------------+-------+------------ ...
? 3、id相同和不同的,同時存在:相同的可以認為是一組,從上往下順序執行,在所有組中,id值越大,優先級越高,越先執行
mysql> explain select * from emp e join dept d on e.deptno = d.deptno join salgrade sg on e.sal between sg.losal and sg.hisal where e.deptno = (select d.deptno from dept d where d.dname = 'SALES');
+----+-------------+-------+------------+...
| id | select_type | table | partitions |...
+----+-------------+-------+------------+...
| 1 | PRIMARY | e | NULL |...
| 1 | PRIMARY | d | NULL |...
| 1 | PRIMARY | sg | NULL |...
| 2 | SUBQUERY | d | NULL |...
+----+-------------+-------+------------ ...
select_type列
主要用來分辨查詢的型別,是普通查詢還是聯合查詢還是子查詢
select_type Value |
Meaning |
|---|---|
| SIMPLE | 不包含子查詢或者 UNION |
| PRIMARY | 查詢中若包含任何復雜的子部分,最外層查詢被標記為 PRIMARY |
| UNION | 在union,union all和子查詢中的第二個和隨后的select被標記為union |
| DEPENDENT UNION | 在包含UNION或者UNION ALL的大查詢中,如果各個小查詢都依賴于外層查詢的話,那除了最左邊的那個小查詢之外,其余的小查詢的select_type的值就是DEPENDENT UNION |
| UNION RESULT | 從union中獲取結果 |
| SUBQUERY | 子查詢中的第一個select(不在from子句中) |
| DEPENDENT SUBQUERY | 子查詢中的第一個select(不在from子句中),而且取決于外面的查詢 |
| DERIVED | 在FROM串列中包含的子查詢被標記為DERIVED |
| UNCACHEABLE SUBQUERY | 一個子查詢的結果不能被快取,必須重新評估外鏈接的第一行對于外層的主表,子查詢不可被物化,每次都需要計算(耗時操作) |
| UNCACHEABLE UNION | UNION操作中,內層的不可被物化的子查詢(類似于UNCACHEABLE SUBQUERY) |
--sample:簡單的查詢,不包含子查詢和union
mysql> explain select * from emp;
+----+-------------+-------+------------+...
| id | select_type | table | partitions |...
+----+-------------+-------+------------+...
| 1 | SIMPLE | emp | NULL |...
+----+-------------+-------+------------ ...
--primary:查詢中若包含任何復雜的子查詢,最外層查詢則被標記為Primary
mysql> explain select * from emp e where e.deptno = (select d.deptno from dept d where d.dname = 'SALES');
+----+-------------+-------+------------+...
| id | select_type | table | partitions |...
+----+-------------+-------+------------+...
| 1 | PRIMARY | e | NULL |...
| 2 | SUBQUERY | d | NULL |...
+----+-------------+-------+------------ ...
--union:在union,union all和子查詢中的第二個和隨后的select被標記為union
mysql> explain select * from emp where deptno = 10 union select * from emp where sal >2000;
+------+--------------+------------+...
| id | select_type | table |...
+------+--------------+------------+...
| 1 | PRIMARY | emp |...
| 2 | UNION | emp |...
| NULL | UNION RESULT | <union1,2> |...
+----+--------------+------------+...
--dependent union:在包含UNION或者UNION ALL的大查詢中,如果各個小查詢都依賴于外層查詢的話,那除了最左邊的那個小查詢之外,其余的小查詢的select_type的值就是DEPENDENT UNION
mysql> explain select * from emp e where e.empno in ( select empno from emp where deptno = 10 union select empno from emp where sal >2000)
+------+--------------------+------------+...
| id | select_type | table |...
+------+--------------------+------------+...
| 1 | PRIMARY | e |...
| 2 | DEPENDENT SUBQUERY | emp |...
| 3 | DEPENDENT UNION | emp |...
| NULL | UNION RESULT | <union2,3> | ...
+----+--------------------+------------+....
--union result:從union表獲取結果的select
mysql> explain select * from emp where deptno = 10 union select * from emp where sal >2000;
+------+--------------+------------+...
| id | select_type | table |...
+------+--------------+------------+...
| 1 | PRIMARY | emp |...
| 2 | UNION | emp |...
| NULL | UNION RESULT | <union1,2> |...
+------+--------------+------------+...
--subquery:在select或者where串列中包含子查詢(不在from子句中)
mysql> explain select * from emp where sal > (select avg(sal) from emp) ;
+----+-------------+-------+------------+...
| id | select_type | table | partitions |...
+----+-------------+-------+------------+...
| 1 | PRIMARY | emp | NULL |...
| 2 | SUBQUERY | dmp | NULL |...
+----+-------------+-------+------------ ...
--dependent subquery: 子查詢中的第一個select(不在from子句中),而且取決于外面的查詢
mysql> explain select e1.* from emp e1 WHERE e1.deptno = (SELECT deptno FROM emp e2 WHERE e1.empno = e2.empno);
+----+--------------------+------------+...
| id | select_type | table |...
+----+--------------------+------------+...
| 1 | PRIMARY | e1 |...
| 2 | DEPENDENT SUBQUERY | e2 |...
+----+--------------------+------------+....
--DERIVED: from子句中出現的子查詢,也叫做派生類,
mysql> explain select * from ( select emp_id,count(*) from emp group by emp_id ) e;
+----+-------------+------------+...
| id | select_type | table |...
+----+-------------+------------+...
| 1 | PRIMARY | <derived2> |...
| 2 | DERIVED | emp |...
+----+-------------+------------+...
--UNCACHEABLE SUBQUERY:表示使用子查詢的結果不能被快取
mysql> explain select * from emp where empno = (select empno from emp where deptno=@@sort_buffer_size);
+----+----------------------+-------------+...
| id | select_type | table |...
+----+----------------------+-------------+...
| 1 | PRIMARY | emp |...
| 2 | UNCACHEABLE SUBQUERY | emp |...
+----+----------------------+-------------+....
--uncacheable union: 表示union的查詢結果不能被快取(沒找到具體的sql陳述句驗證)
table列
對應行正在訪問哪一個表,表名或者別名,可能是臨時表或者union合并結果集
1、如果是具體的表名,則表明從實際的物理表中獲取資料,當然也可以是表的別名
? 2、表名是derivedN的形式,表示使用了id為N的查詢產生的衍生表
? 3、當有union result的時候,表名是union n1,n2等的形式,n1,n2表示參與union的id
type列
type顯示的是訪問型別,訪問型別表示我是以何種方式去訪問我們的資料,最容易想的是全表掃描,直接暴力的遍歷一張表去尋找需要的資料,效率非常低下,
訪問的型別有很多,效率從最好到最壞依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般情況下,得保證查詢至少達到range級別,最好能達到ref
--all:全表掃描,需要掃描整張表,從頭到尾找到需要的資料行,一般情況下出現這樣的sql陳述句而且資料量比較大的話那么就需要進行優化,
mysql> explain select * from emp;
+----+-------------+-------+------------+------+---------------+
| id | select_type | table | partitions | type | possible_keys |
+----+-------------+-------+------------+------+---------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL |
+----+-------------+-------+------------+------+---------------+
--index:全索引掃描這個比all的效率要好,主要有兩種情況,一種是當前的查詢時覆寫索引,即我們需要的資料在索引中就可以索取,或者是使用了索引進行排序,這樣就避免資料的重排序
mysql> explain select empno from emp;
+----+-------------+-------+------------+------+---------------+
| id | select_type | table | partitions | type | possible_keys |
+----+-------------+-------+------------+------+---------------+
| 1 | SIMPLE | emp | NULL | index| NULL |
+----+-------------+-------+------------+------+---------------+
最后要達到這個級別range
--range:表示利用索引查詢的時候限制了范圍,在指定范圍內進行查詢,這樣避免了index的全索引掃描,適用的運算子: =, <>, >, >=, <, <=, IS NULL, BETWEEN, LIKE, or IN()
mysql> explain select * from emp where empno between 100 and 200;
+----+-------------+-------+------------+------+---------------+
| id | select_type | table | partitions | type | possible_keys |
+----+-------------+-------+------------+------+---------------+
| 1 | SIMPLE | emp | NULL |range | u2 |
+----+-------------+-------+------------+------+---------------+
--index_subquery:利用索引來關聯子查詢,不再掃描全表
mysql> explain select * from emp where deptno not in (select deptno from emp)
+----+--------------------+-------+------------+----------------+---------------+...
| id | select_type | table | partitions | type | possible_keys |...
+----+--------------------+-------+------------+----------------+---------------+...
| 1 | PRIMARY | emp | NULL | ALL | NULL |...
| 2 | DEPENDENT SUBQUERY | emp | NULL | index_subquery | u1 |...
+----+--------------------+-------+------------+----------------+---------------+...
但是大多數情況下使用SELECT子查詢時,MySQL查詢優化器會自動將子查詢優化為聯表查詢,因此 type 不會顯示為 index_subquery,而是ref
--unique_subquery:該連接型別類似與index_subquery,使用的是唯一索引
mysql> explain SELECT * from emp where emp_id not in (select emp.emp_id from emp );
+----+--------------------+-------+------------+-----------------+---------------+...
| id | select_type | table | partitions | type | possible_keys |...
+----+--------------------+-------+------------+-----------------+---------------+...
| 1 | PRIMARY | emp | NULL | ALL | NULL |...
| 2 | DEPENDENT SUBQUERY | emp | NULL | unique_subquery | PRIMARY |...
+----+--------------------+-------+------------+-----------------+---------------+...
大多數情況下使用SELECT子查詢時,MySQL查詢優化器會自動將子查詢優化為聯表查詢,因此 type 不會顯示為 index_subquery,而是eq_ref
--index_merge:在查詢程序中需要多個索引組合使用
mysql> 沒有模擬出來
--ref_or_null:對于某個欄位即需要關聯條件,也需要null值的情況下,查詢優化器會選擇這種訪問方式
mysql> 沒模擬出來
--ref:使用了非唯一性索引進行資料的查找
mysql> explain select * from emp where deptno=10;
+----+-------------+-------+------------+------+---------------+...
| id | select_type | table | partitions | type | possible_keys |...
+----+-------------+-------+------------+------+---------------+...
| 1 | SIMPLE | emp | NULL | ref | u1 |...
+----+-------------+-------+------------+------+---------------+...
--eq_ref :當進行等值聯表查詢使用主鍵索引或者唯一性非空索引進行資料查找
> 實際上唯一索引等值查詢type不是eq_ref而是const
mysql> explain select * from salgrade s LEFT JOIN emp e on s.emp_id = e.emp_id;
+----+-------------+-------+------------+--------+---------------+...
| id | select_type | table | partitions | type | possible_keys |...
+----+-------------+-------+------------+--------+---------------+...
| 1 | SIMPLE | s | NULL | ALL | NULL |...
| 1 | SIMPLE | e | NULL | eq_ref | PRIMARY |...
+----+-------------+-------+------------+--------+---------------+...
--const:最多只能匹配到一條資料,通常使用主鍵或唯一索引進行等值條件查詢
mysql> explain select * from emp where empno = 10;
+----+-------------+-------+------------+-------+---------------+...
| id | select_type | table | partitions | type | possible_keys |...
+----+-------------+-------+------------+-------+---------------+...
| 1 | SIMPLE | emp | NULL | const | u2 |...
+----+-------------+-------+------------+-------+---------------+...
--system:表只有一行記錄(等于系統表),這是const型別的特例,平時不會出現,不需要進行磁盤io
mysql> explain SELECT * FROM `mysql`.`proxies_priv`;
+----+-------------+--------------+------------+--------+---------------+...
| id | select_type | table | partitions | type | possible_keys |...
+----+-------------+--------------+------------+--------+---------------+...
| 1 | SIMPLE | proxies_priv | NULL | system | NULL |...
+----+-------------+--------------+------------+--------+---------------+...
possible_keys列
? 顯示可能應用在這張表中的索引,一個或多個,查詢涉及到的欄位上若存在索引,則該索引將被列出,但不一定被查詢實際使用,
key列
? 實際使用的索引,如果為null,則沒有使用索引,查詢中若使用了覆寫索引,則該索引和查詢的select欄位重疊,
key_len
表示索引中使用的位元組數,可以通過key_len計算查詢中使用的索引長度,在不損失精度的情況下長度越短越好,
索引越大占用存盤空間越大,這樣io的次數和量就會增加,影響執行效率
ref列
顯示之前的表在key列記錄的索引中查找值所用的列或者常量
rows列
根據表的統計資訊及索引使用情況,大致估算出找出所需記錄需要讀取的行數,此引數很重要,直接反應的sql找了多少資料,在完成目的的情況下越少越好,
filtered列
針對表中符合某個條件(where子句或者聯接條件)的記錄數的百分比所做的一個悲觀估算,
extra
包含額外的資訊,
--using filesort:說明mysql無法利用索引進行排序,只能利用排序演算法進行排序,會消耗額外的位置
mysql> explain select * from emp order by sal;
...+------+---------------+------+---------+------+------+----------+----------------+
...| type | possible_keys | key | key_len | ref | rows | filtered | Extra |
...+------+---------------+------+---------+------+------+----------+----------------+
...| ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | Using filesort |
...+------+---------------+------+---------+------+------+----------+----------------+
--using temporary:建立臨時表來保存中間結果,查詢完成之后把臨時表洗掉
mysql> explain select name,count(*) from emp where deptno = 10 group by name;
...+------+---------+-------+------+----------+---------------------------------+
...| key | key_len | ref | rows | filtered | Extra |
...+------+---------+-------+------+----------+---------------------------------+
...| u1 | 4 | const | 2 | 100.00 | Using temporary; Using filesort |
...+------+---------+-------+------+----------+---------------------------------+
--using index:這個表示當前的查詢時覆寫索引的,直接從索引中讀取資料,而不用訪問資料表,如果同時出現using where 表名索引被用來執行索引鍵值的查找,如果沒有,表面索引被用來讀取資料,而不是真的查找
mysql> explain select deptno,count(*) from emp group by deptno limit 10;
...+------+---------+------+------+----------+-------------+
...| key | key_len | ref | rows | filtered | Extra |
...+------+---------+------+------+----------+-------------+
...| u1 | 4 | NULL | 2 | 100.00 | Using index |
...+------+---------+------+------+----------+-------------+
--using where:使用where進行條件過濾
mysql> explain select * from emp where name = 1;
--using join buffer:使用連接快取
mysql> explain select * from emp e left join dept d on e.deptno = d.deptno;
...+------+---------+------+------+----------+---------------------------------------+
...| key | key_len | ref | rows | filtered | Extra |
...+------+---------+------+------+----------+---------------------------------------+
...| NULL | NULL | NULL | 2 | 100.00 | NULL |
...| NULL | NULL | NULL | 1 | 100.00 | Using join buffer (Block Nested Loop) |
...+------+---------+------+------+----------+---------------------------------------+
--impossible where:where陳述句的結果總是false
mysql> explain select * from emp where 1=0;
...+------+---------+------+------+----------+------------------+
...| key | key_len | ref | rows | filtered | Extra |
...+------+---------+------+------+----------+------------------+
...| NULL | NULL | NULL | NULL | NULL | Impossible WHERE |
...+------+---------+------+------+----------+------------------+
測驗使用mysql版本5.7, 使用的3個表結構如下
CREATE TABLE `demo`.`emp` (
`emp_id` bigint(20) NOT NULL,
`name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT '姓名',
`empno` int(20) NOT NULL COMMENT '工號',
`deptno` int(20) NOT NULL COMMENT '部門編號',
`sal` int(11) NOT NULL DEFAULT 0 COMMENT '銷售量',
PRIMARY KEY (`emp_id`) USING BTREE,
INDEX `u1`(`deptno`) USING BTREE,
UNIQUE INDEX `u2`(`empno`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
CREATE TABLE `demo`.`dept` (
`id` bigint(20) NOT NULL,
`deptno` int(20) NOT NULL COMMENT '部門編碼',
`dname` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '部門名稱',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `dept_u1`(`deptno`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
CREATE TABLE `demo`.`salgrade` (
`id` bigint(20) NOT NULL,
`losal` int(20) NULL DEFAULT NULL,
`hisal` int(20) NULL DEFAULT NULL,
`emp_id` bigint(20) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
MySQL高級相關更多內容,如事務,鎖,MVCC,讀寫分離,分庫分表等還在持續更新中,歡迎關注催更,
歡迎關注公眾號: 紀先生筆記

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/300399.html
標籤:其他
上一篇:MySQL45講之count操作
下一篇:MySQL45講之count操作