1.HDFS概述
1)資料量越來越多,在一個作業系統管轄的范圍存不下了,那么就分配到更多的作業系統管理的磁盤中,但是不方便管理和維護,因此迫切需要一種系統來管理多臺機器上的檔案,這就 是分布式檔案管理系統,
2)是一種允許檔案通過網路在多臺主機上分享的檔案系統,可讓多機器上的多用戶分享檔案和存盤空間,
3)通透性,讓實際上是通過網路來訪問檔案的動作,由程式與用戶看來,就像是訪問本地的磁盤一般,
4)容錯,即使系統中有某些節點宕機,整體來說系統仍然可以持續運作而不會有資料損失【通過副本機制實作】,
5)分布式檔案管理系統很多,hdfs只是其中一種,不合適小檔案,
2.hdfs架構
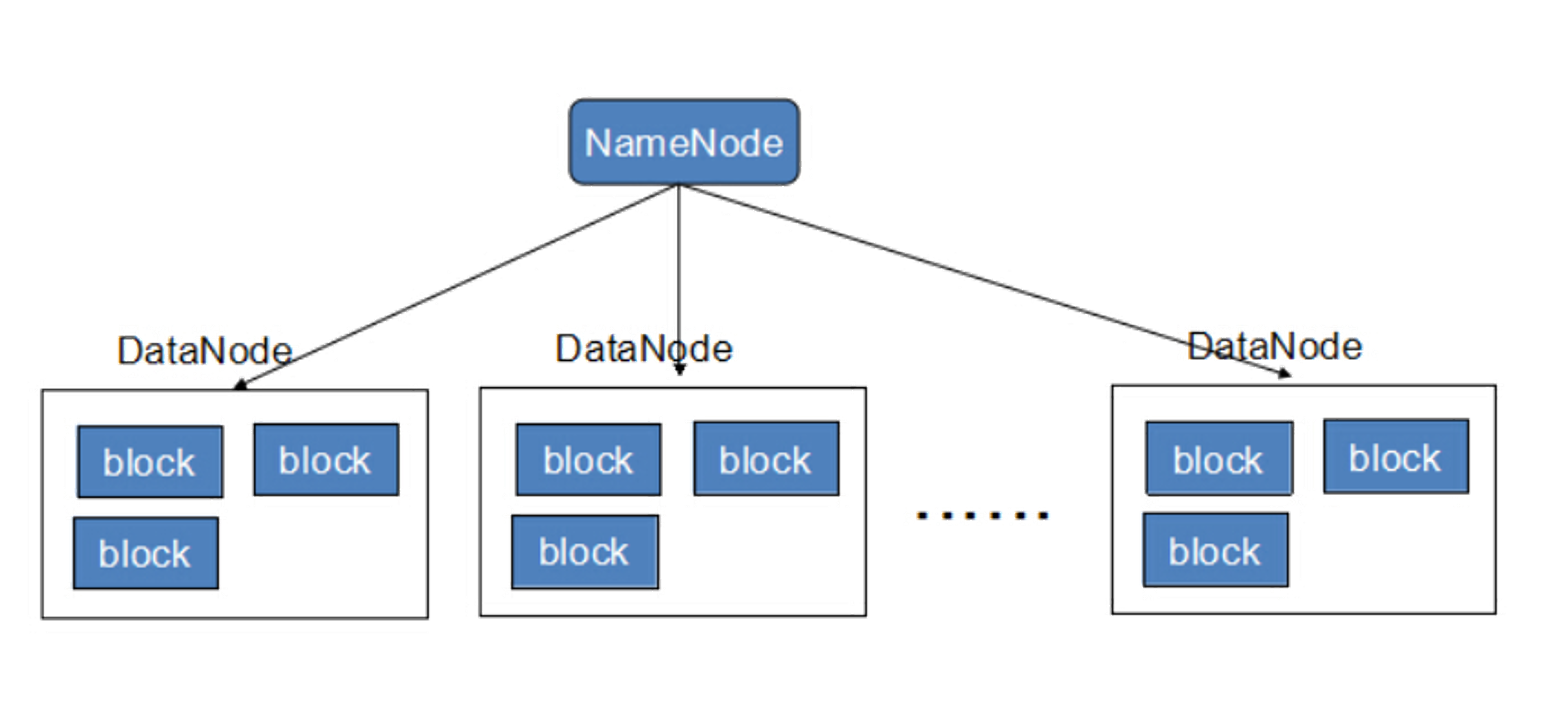
NameNode
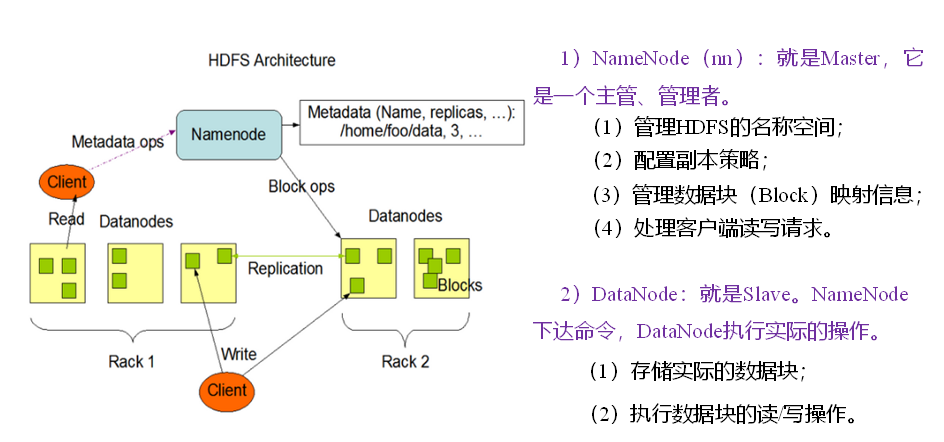
NameNode是整個檔案系統的管理節點,它維護著整個檔案系統的檔案目錄樹,檔案/目錄的元資訊和每個檔案對應的資料塊串列,接收用戶的操作請求,
檔案包括:
fsimage:元資料鏡像檔案,存盤某一時段NameNode記憶體元資料資訊,
edits:操作日志檔案,namenode啟動后一些新增元資訊日志,
fstime:保存最近一次checkpoint的時間
以上這些檔案是保存在linux的檔案系統中,
hdfs-site.xml的dfs.namenode.name.dir屬性
secondary namenode

DataNode
提供真實檔案資料的存盤服務,
檔案塊(block):最基本的存盤單位,對于檔案內容而言,一個檔案的長度大小是size,那么從檔案的0偏移開始,按照固定的大小,順序對檔案進行劃分并編號,劃分好的每一個塊稱一個Block,2.0以后HDFS默認Block大小是128MB,以一個256MB檔案,共有256/128=2個Block.
hdfs-site.xml中dfs.blocksize屬性
不同于普通檔案系統的是,HDFS中,如果一個檔案小于一個資料塊的大小,并不占用整個資料塊存盤空間 Replication,多復本,默認是三個,
hdfs-site.xml的dfs.replication屬性

3.HDFS寫資料流程
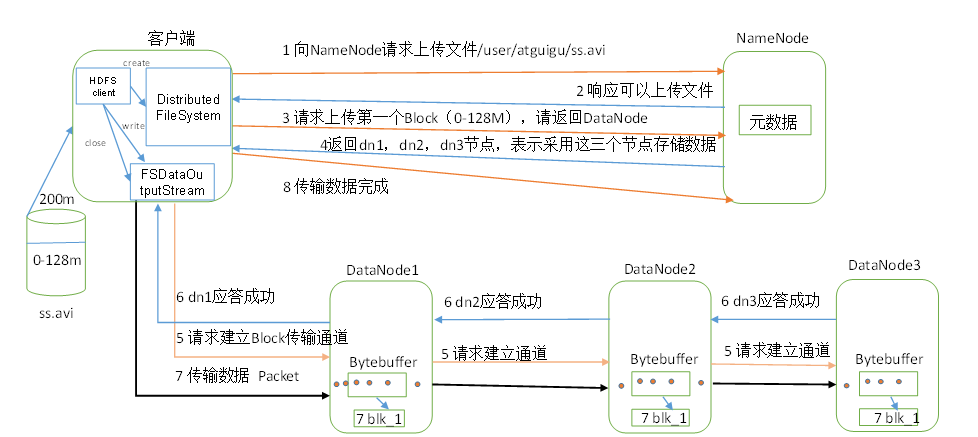
(1)客戶端通過Distributed FileSystem模塊向NameNode請求上傳檔案,NameNode檢查目標檔案是否已存在,父目錄是否存在,
(2)NameNode回傳是否可以上傳,
(3)客戶端請求第一個 Block上傳到哪幾個DataNode服務器上,
(4)NameNode回傳3個DataNode節點,分別為dn1、dn2、dn3,
(5)客戶端通過FSDataOutputStream模塊請求dn1上傳資料,dn1收到請求會繼續呼叫dn2,然后dn2呼叫dn3,將這個通信管道建立完成,
(6)dn1、dn2、dn3逐級應答客戶端,
(7)客戶端開始往dn1上傳第一個Block(先從磁盤讀取資料放到一個本地記憶體快取),以Packet (64K)為單位,dn1收到一個Packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答佇列等待應答,
(8)當一個Block傳輸完成之后,客戶端再次請求NameNode上傳第二個Block的服務器,(重復執行3-7步),
4.HDFS讀資料流程
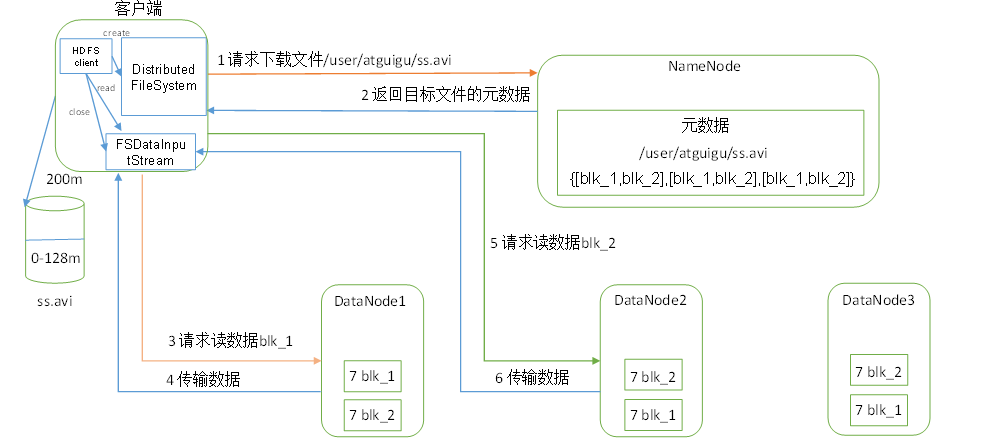
(1)客戶端通過DistributedFileSystem向NameNode請求下載檔案,NameNode通過查詢元資料,找到檔案塊所在的DataNode地址,
(2)挑選一臺DataNode(就近原則,然后隨機)服務器,請求讀取資料,
(3)DataNode開始傳輸資料給客戶端(從磁盤里面讀取資料輸入流,以Packet為單位來做校驗),先讀距離最近的,然后一次讀,串行讀
(4)客戶端以Packet為單位接收,先在本地快取,然后寫入目標檔案,
5. NameNode和SecondaryNameNode作業機制
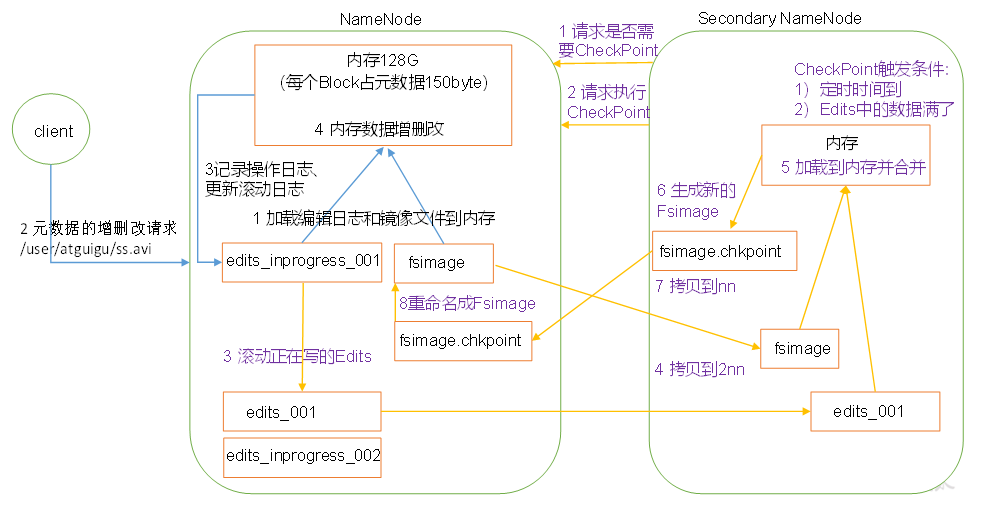
1)第一階段:NameNode啟動
(1)第一次啟動NameNode格式化后,創建Fsimage和Edits檔案,如果不是第一次啟動,直接加載編輯日志和鏡像檔案到記憶體,
(2)客戶端對元資料進行增刪改的請求,
(3)NameNode記錄操作日志,更新滾動日志,
(4)NameNode在記憶體中對元資料進行增刪改,
2)第二階段:Secondary NameNode作業
通常情況下,SecondaryNameNode每隔一小時執行一次,
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
(1)Secondary NameNode詢問NameNode是否需要CheckPoint,直接帶回NameNode是否檢查結果,
(2)Secondary NameNode請求執行CheckPoint,
(3)NameNode滾動正在寫的Edits日志,
(4)將滾動前的編輯日志和鏡像檔案拷貝到Secondary NameNode,
(5)Secondary NameNode加載編輯日志和鏡像檔案到記憶體,并合并,
(6)生成新的鏡像檔案fsimage.chkpoint,
(7)拷貝fsimage.chkpoint到NameNode,
(8)NameNode將fsimage.chkpoint重新命名成fsimage,
6 DataNode作業機制
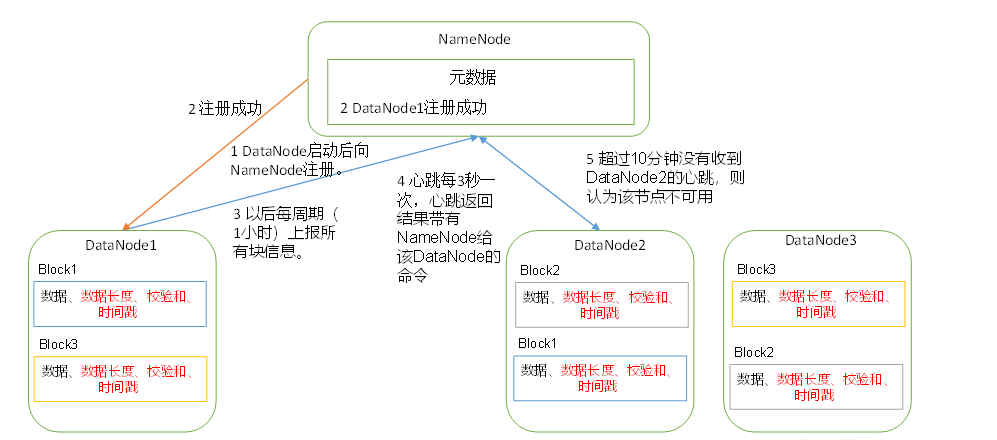
(1)一個資料塊在DataNode上以檔案形式存盤在磁盤上,包括兩個檔案,一個是資料本身,一個是元資料包括資料塊的長度,塊資料的校驗和,以及時間戳,
(2)DataNode啟動后向NameNode注冊,通過后,周期性(1小時)的向NameNode上報所有的塊資訊,
(3)心跳是每3秒一次,心跳回傳結果帶有NameNode給該DataNode的命令如復制塊資料到另一臺機器,或洗掉某個資料塊,如果超過10分鐘沒有收到某個DataNode的心跳,則認為該 節點不可用,
(4)集群運行中可以安全加入和退出一些機器,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/302157.html
標籤:其他