1、Hive完整建表
1 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name(
2 [(col_name data_type [COMMENT col_comment], ...)]
3 )
4 [COMMENT table_comment]
5 [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
6 [CLUSTERED BY (col_name, col_name, ...)
7 [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
8 [
9 [ROW FORMAT row_format]
10 [STORED AS file_format]
11 | STORED BY 'storage.handler.class.name' [ WITH SERDEPROPERTIES (...) ] (Note: only available starting with 0.6.0)
12 ]
13 [LOCATION hdfs_path]
14 [TBLPROPERTIES (property_name=property_value, ...)] (Note: only available starting with 0.6.0)
15 [AS select_statement] (Note: this feature is only available starting with 0.5.0.)
注意:
[]:表示可選
EXTERNAL:外部表
(col_name data_type [COMMENT col_comment],...:定義欄位名,欄位型別
COMMENT col_comment:給欄位加上注釋
COMMENT table_comment:給表加上注釋
PARTITIONED BY (col_name data_type [COMMENT col_comment],...):磁區 磁區欄位注釋
CLUSTERED BY (col_name, col_name,...):分桶
SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS:設定排序欄位 升序、降序
ROW FORMAT row_format:指定設定行、列分隔符(默認行分隔符為\n)
STORED AS file_format:指定Hive儲存格式:textFile、rcFile、SequenceFile 默認為:textFile
LOCATION hdfs_path:指定儲存位置(默認位置在hive.warehouse目錄下)
TBLPROPERTIES (property_name=property_value, ...):跟外部表配合使用,比如:映射HBase表,然后可以使用HQL對hbase資料進行查詢,當然速度比較慢
AS select_statement:從別的表中加載資料 select_statement=sql陳述句
2、使用默認方式建表
1 create table students01
2 (
3 id bigint,
4 name string,
5 age int,
6 gender string,
7 clazz string
8 )
9 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
注意:
分割符不指定,默認不分割
通常指定列分隔符,如果欄位只有一列可以不指定分割符:
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
3、建表2:指定location
1 create table students02
2 (
3 id bigint,
4 name string,
5 age int,
6 gender string,
7 clazz string
8 )
9 ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
10 LOCATION 'data';
4、建表3:指定存盤格式
1 create table student_rc
2 (
3 id bigint,
4 name string,
5 age int,
6 gender string,
7 clazz string
8 )
9 ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
10 STORED AS rcfile;
注意:
指定儲存格式為rcfile,inputFormat:RCFileInputFormat,outputFormat:RCFileOutputFormat,如果不指定,默認為textfile
注意:
除textfile以外,其他的存盤格式的資料都不能直接加載,需要使用從表加載的方式,



5、建表4:從其他表中加載資料
格式:
create table xxxx as select_statement(SQL陳述句) (這種方式比較常用)
例子:
create table students4 as select * from students2;
6、建表5:從其他表中獲取表結構
格式:
create table xxxx like table_name 只想建表,不需要加載資料
例子:
create table student04 like students;

7.Hive加載資料
1、使用```hadoop dfs -put '本地資料' 'hive表對應的HDFS目錄下

2、使用 load data inpath(是對hdfs的檔案移動,移動,移動,不是復制)
3、使用load data local inpath(經常使用,從本地檔案中上傳)

// overwrite 覆寫加載
// 實際上就是hadoop執行了rmr然后put操作
例如:load data local inpath'/usr/local/data/students.txt' overwrite into table student01;

方式1和方式2的區別:
1.上傳資料到hdfs目錄和hive表沒有任何關系(不需要資料格式進行匹配,hive讀取資料還是需要資料格式的匹配)
2.上傳資料到hive表和hive表有關系(需要資料格式進行匹配)
8. 清空表
truncate table student01;
注意: 清空代表清空資料,不是洗掉表

11. insert into table xxxx SQL陳述句 (沒有as) 傳輸給別的格式的hive table
例如:
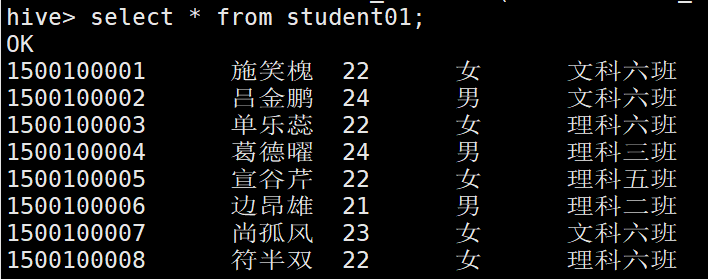
insert into table student04 select * from student01;
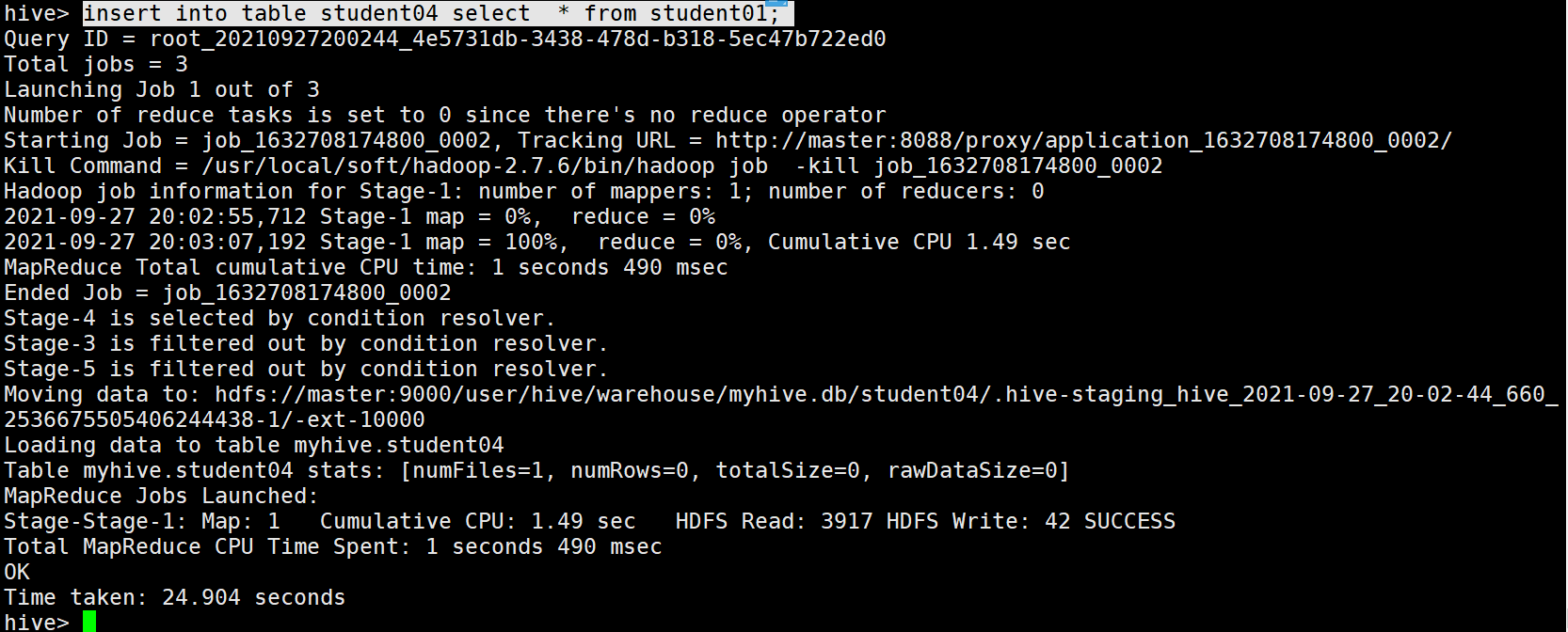
覆寫插入 把into 換成 overwrite
例如:
insert overwrite table student04 select * from student01;
9、Hive 內部表(Managed tables)vs 外部表(External tables)
區別:
內部表洗掉資料跟著洗掉
外部表只會洗掉表結構,資料依然存在
注意:
公司中實際應用場景為外部表,為了避免表意外洗掉資料也丟失
不能通過路徑來判斷是目錄還是hive表(是內部表還是外部表)
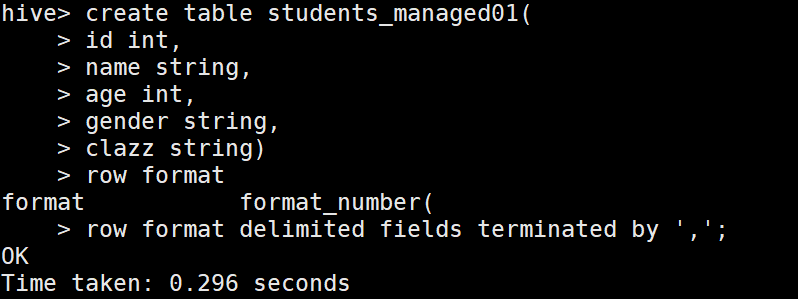
建表:
1 內部表
2 create table students_managed01
3 (
4 id bigint,
5 name string,
6 age int,
7 gender string,
8 clazz string
9 )
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
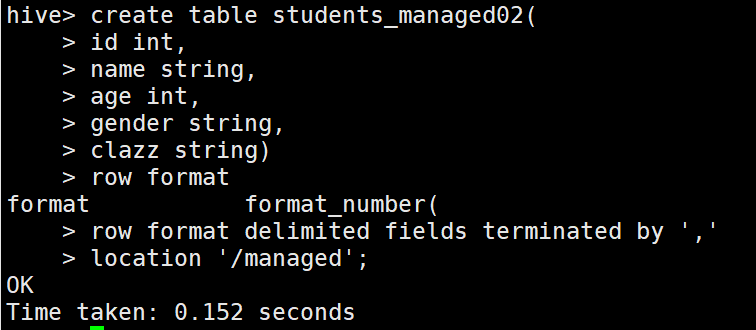
1 //內部表指定location
2 create table students_managed02
3 (
4 id bigint,
5 name string,
6 age int,
7 gender string,
8 clazz string
9 )
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
11 LOCATION '/managed';
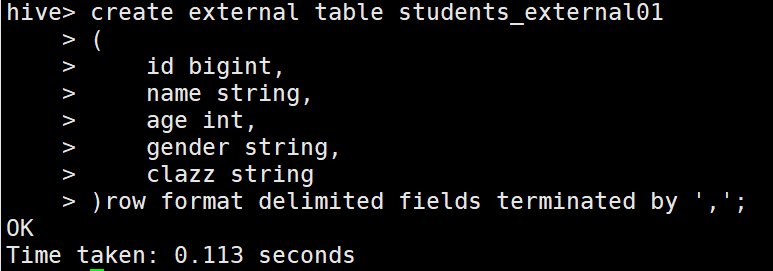
1 // 外部表
2 create external table students_external01
3 (
4 id bigint,
5 name string,
6 age int,
7 gender string,
8 clazz string
9 )
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
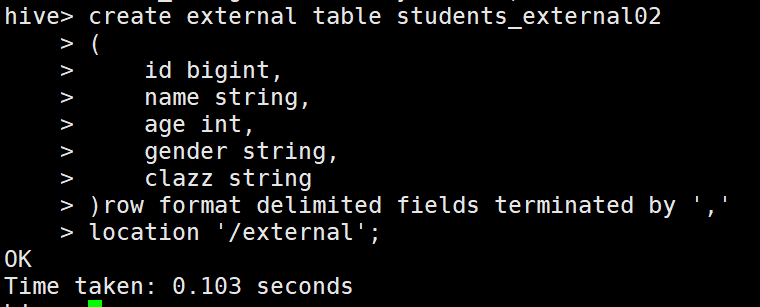
1 // 外部表指定location
2 create external table students_external02
3 (
4 id bigint,
5 name string,
6 age int,
7 gender string,
8 clazz string
9 )
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
11 LOCATION '/external';
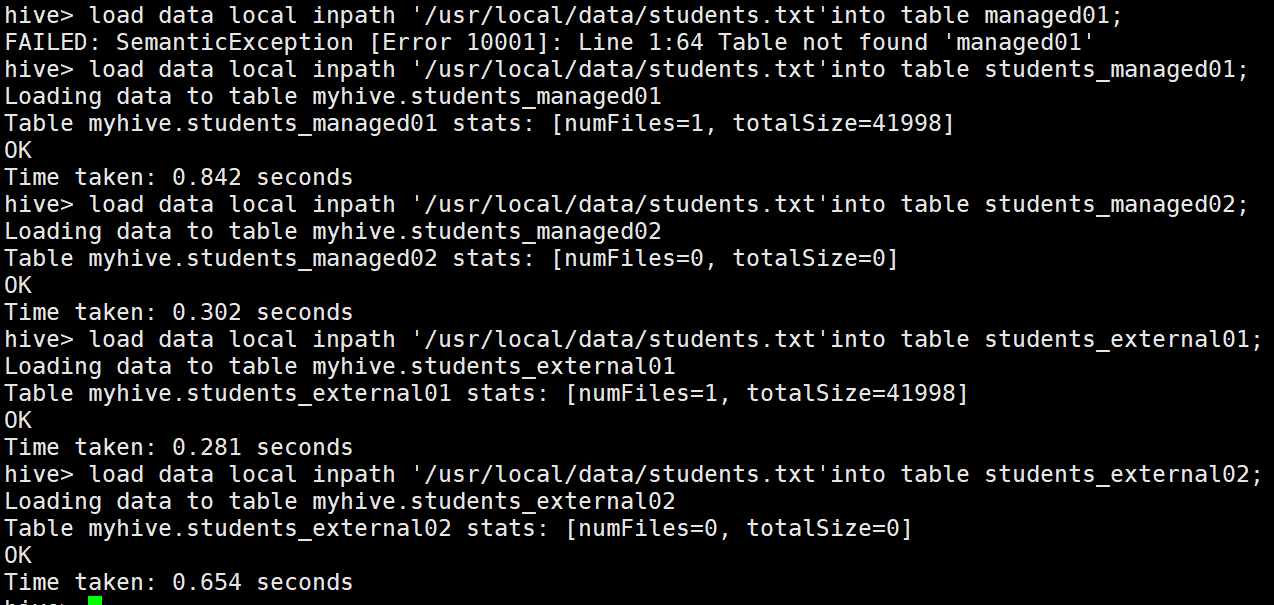
上傳資料:
hive> load data local inpath '/usr/local/data/students.txt'into table students_managed01;hive> load data local inpath '/usr/local/data/students.txt'into table students_managed02;
hive> load data local inpath '/usr/local/data/students.txt'into table students_external01;hive> load data local inpath '/usr/local/data/students.txt'into table students_external02;
洗掉資料:
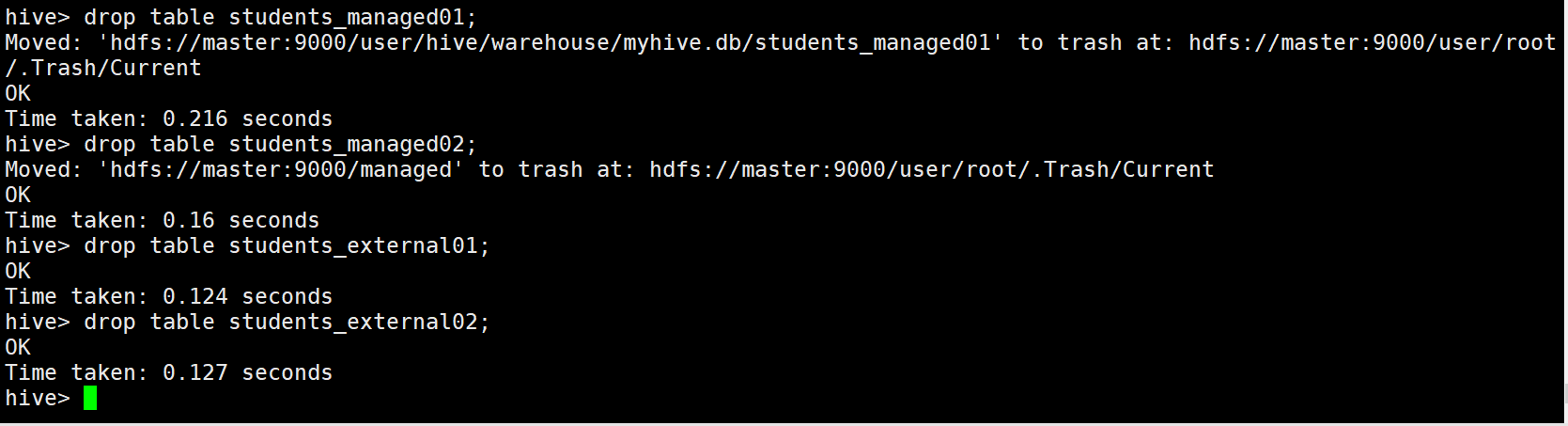
hive> drop table students_managed01;
hive> drop table students_managed02;
hive> drop table students_external01;
hive> drop table students_external02;
外部表與內部表總結:
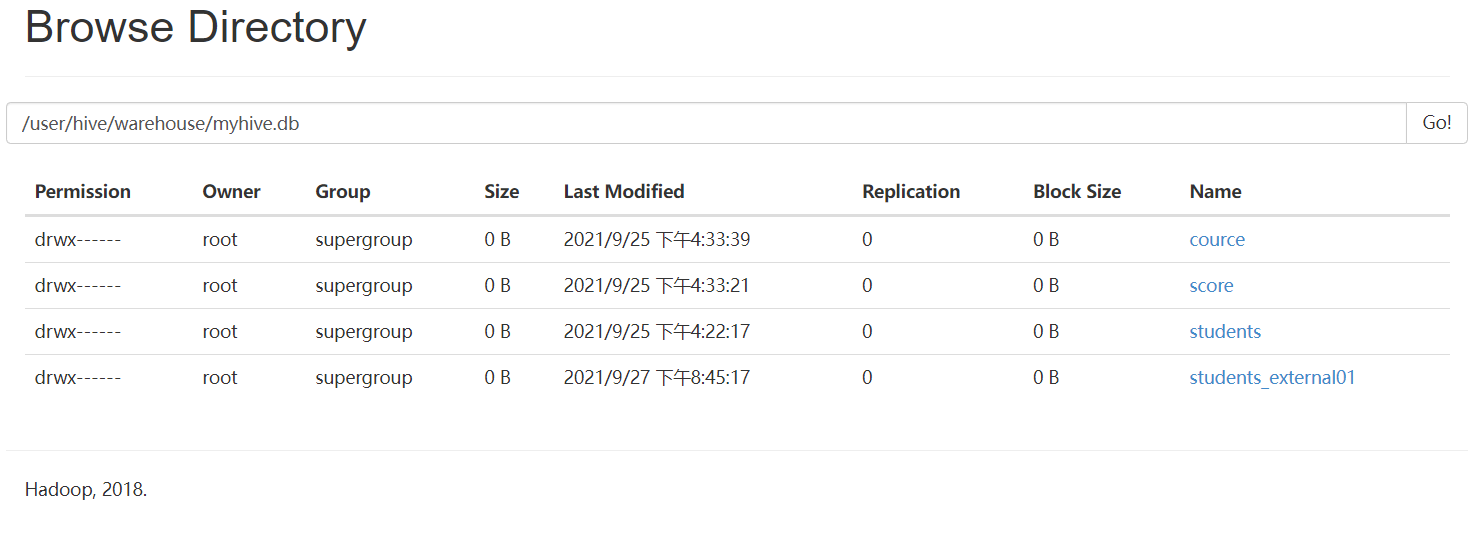
可以看出,洗掉內部表的時候,表中的資料(HDFS上的檔案)會被同表的元資料一起洗掉
洗掉外部表的時候,只會洗掉表的元資料,不會洗掉表中的資料(HDFS上的檔案)
一般在公司中,使用外部表多一點,因為資料可以需要被多個程式使用,避免誤刪,通常外部表會結合location一起使用
外部表還可以將其他資料源中的資料 映射到 hive中,比如說:hbase,ElasticSearch......
設計外部表的初衷就是 讓 表的元資料 與 資料 解耦
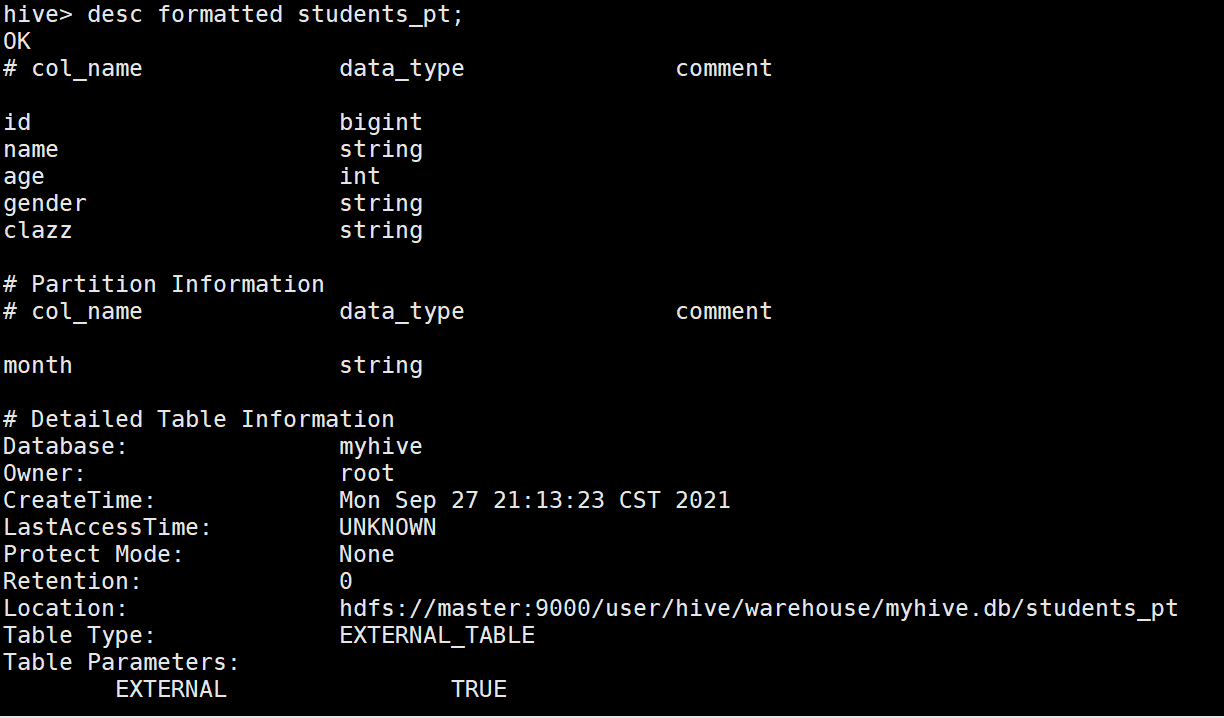
10、Hive建立磁區表
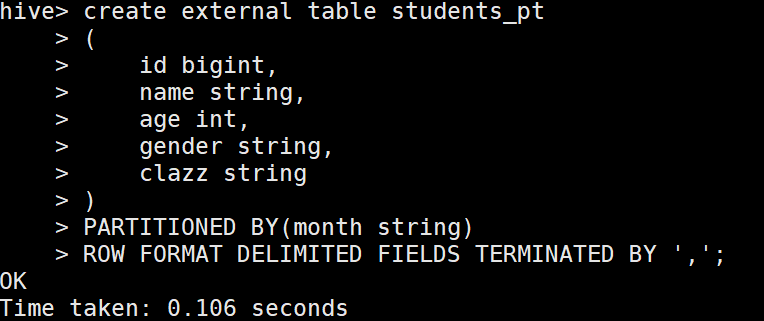
1.創建單級磁區
1 create table students_pt
2 (
3 id bigint,
4 name string,
5 age int,
6 gender string,
7 clazz string
8 )
9 PARTITIONED BY(month string)
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
2.加載資料
load data local inpath '/usr/local/data/students.txt' into table students_pt partition(month='2021-09-26');

3.磁區查詢
單磁區查詢
select * from students_pt where month='2021-09-26';
多磁區查詢
select * from students_pt where month='2021-09-26'or month='2021-09-24';
4.增加磁區
創建單個磁區
alter table students_pt add partition(month='2021-09-25');

創建多個磁區
alter table students_pt add partition(month='2021-09-23') partition(month='2021-09-24');(注意中間沒有逗號分割)

5.洗掉磁區
洗掉單個磁區
alter table students_pt drop partition(month='2021-09-23');

洗掉多個磁區
alter table students_pt drop partition(month='2021-09-24'),partition(month='2021-09-25'); (注意中間有逗號分割)

6.查看磁區表磁區
show partitions students_pt;

7.查看磁區表結構
desc formatted students_pt;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/303500.html
標籤:其他
上一篇:Hive語法及其進階(一)