入門
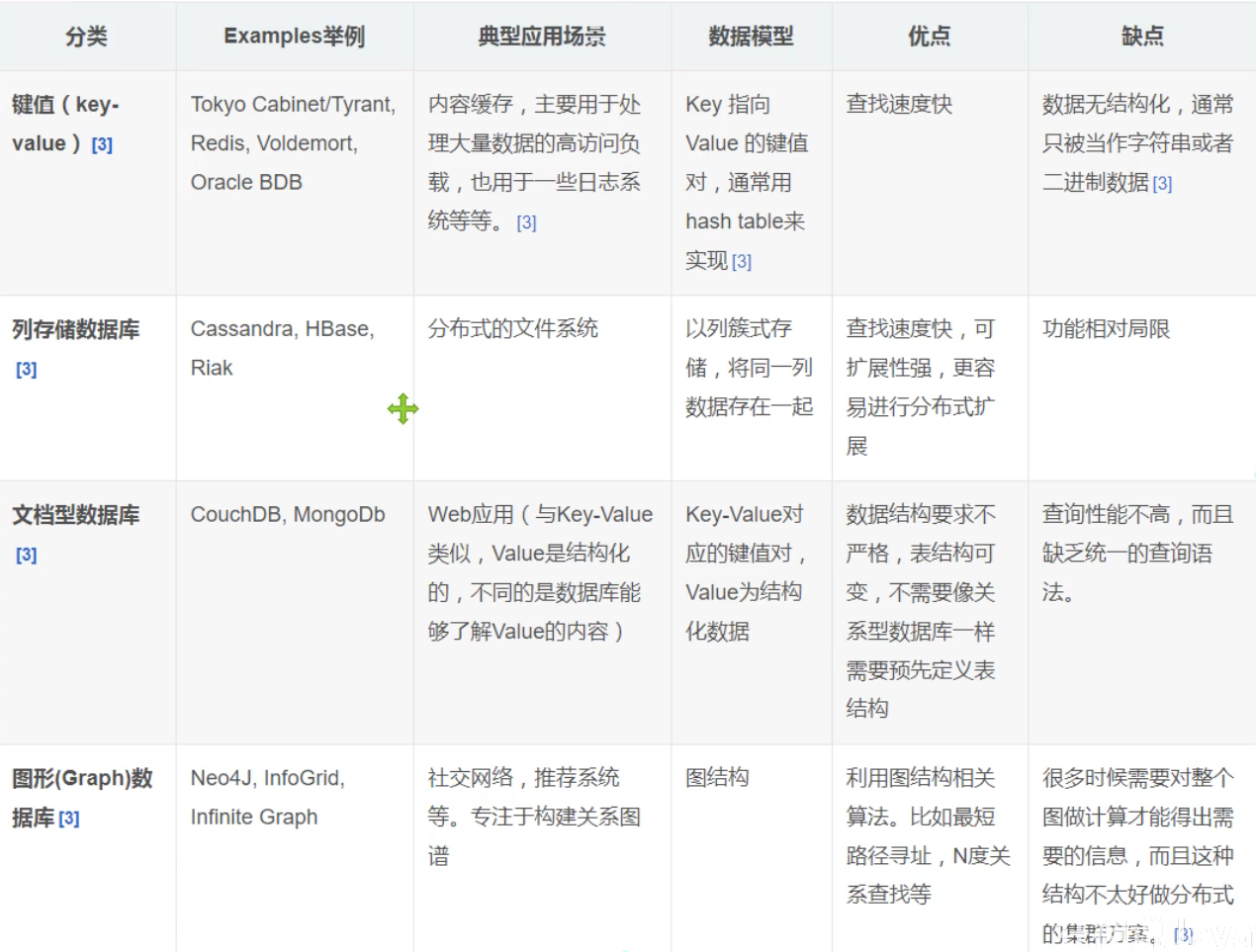
NoSQL的四大分類
入門概述
什么是Redis?
Redis (Remote Dictionary Server ),即遠程字典服務,是一個開源的支持網路、可基于記憶體亦可持久化的日志型、Key-Value資料庫,并提供多種語言的API, 可以用作資料可、快取、訊息中間件
Redis 是一個開源(BSD許可)的,記憶體中的資料結構存盤系統,它可以用作資料庫、快取和訊息中間件,
它支持多種型別的資料結構,如 字串(strings), 散列(hashes), 串列(lists), 集合(sets),
有序集合(sorted sets) 與范圍查詢, bitmaps, hyperloglogs 和 地理空間(geospatial) 索引半徑查詢, Redis 內置了 復制(replication),LUA腳本(Lua scripting), LRU驅動事件(LRU eviction),
事務(transactions) 和不同級別的 磁盤持久化(persistence), 并通過 Redis哨兵(Sentinel)和自動 磁區(Cluster)提供高可用性(high availability),
redis會周期性的把更新的資料寫入磁盤或者把修改操作寫入追加的記錄檔案,并且在此基礎上實作了master-slave(主從)同步,
redis中文官方網站 Redis推薦都是在Linux服務器上搭建的
Redis的作用
- 記憶體存盤、持久化(rdb、aof)
- 效率高,用于高速快取
- 發布訂閱系統
- 地圖資訊分析
- 計數器
- .......
特性
- 多樣的資料型別
- 持久化
- 支持集群、事務等
Windows安裝
-
自行下載解壓 不做詳細說明
-
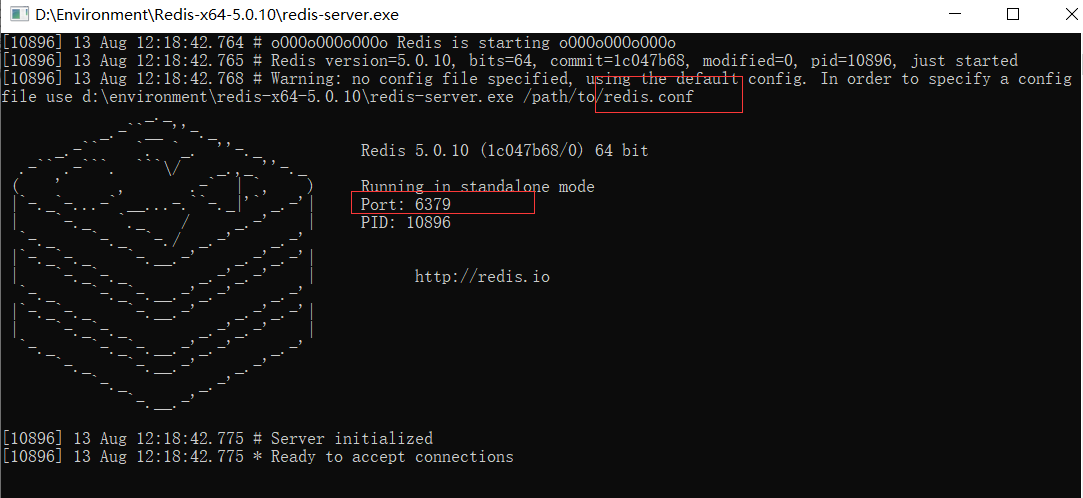
開啟redis 雙擊運行服務 默認埠號為6379
-
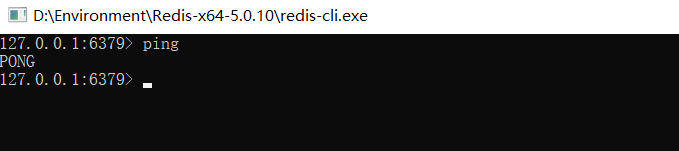
使用redis客戶端進行連接
輸入
ping命令回傳pong表示成功連接
windows下就介紹到此,畢竟企業級的開發都是在redis下開發的
Linux安裝
-
寶塔輕易安裝即可 進入
www/server/redis可以看到redis的配置

-
因為redis的運行需要依賴gcc 進行編譯,所以還要安裝gcc環境
yum install gcc-c++
# 檢查gcc是否成功安裝
gcc -v
# 配置所需要的檔案
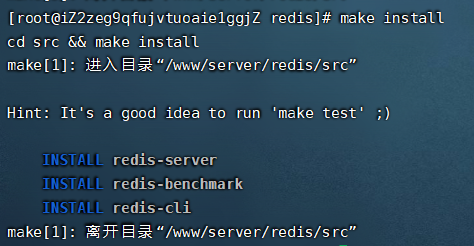
make
# 檢查
make install
-
redis的默認安裝路徑在
usr/local/bin目錄下

-
新建目錄將redis的組態檔移動到當前
# 新建檔案
mkdir qdconfig
# 復制組態檔
cp /www/server/redis/redis.conf qdconfig
? 我們之后用這個組態檔進行啟動
- redis默認不是后臺啟動的,需要修改組態檔
vim redis.conf

6. 以當前配置啟動redis服務
redis-server qdconfig/redis.conf

7. 測驗set

8. 查看服務

9. 關閉服務
shutdown
exit
ok~~安裝至此完成
性能測驗
redis-benchmark 是一個壓力測驗工具,可以通過他測驗性能問題
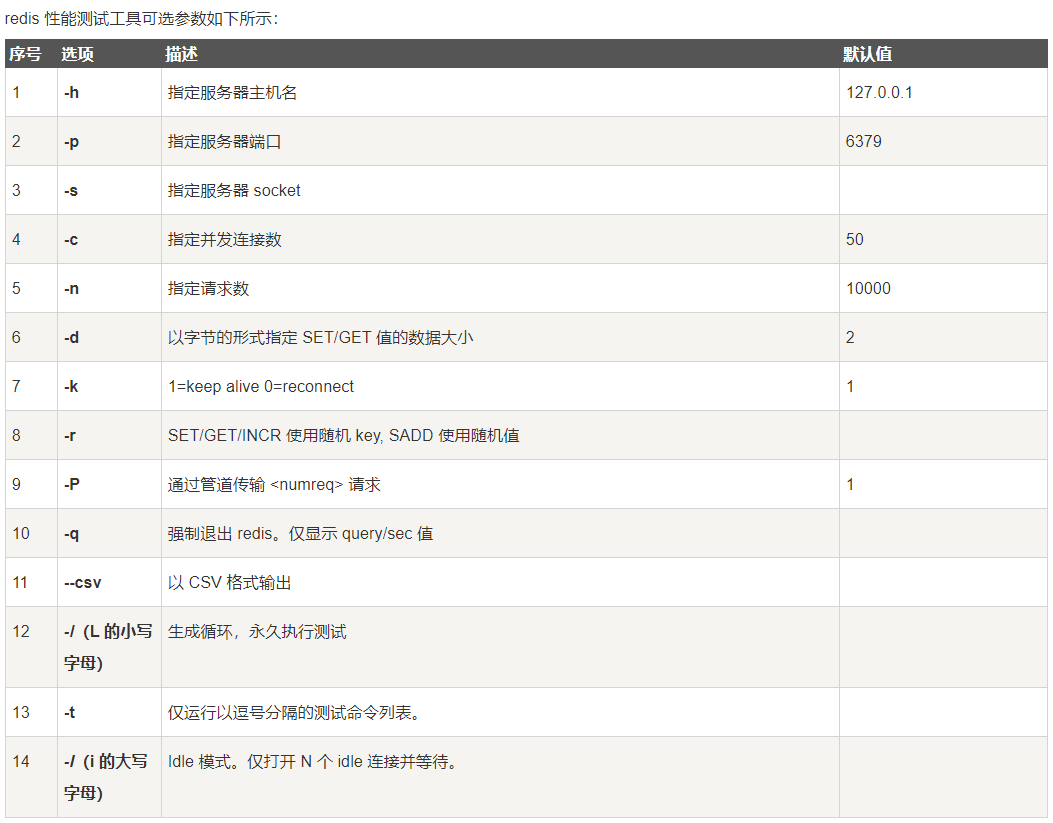
舉個栗子:測驗10個并發,100個請求
redis-benchmark -h localhost -p 6379 -c 10 -n 100

Reids基礎
redis有16個資料庫,默認使用第0個資料庫,可以使用select 切換資料庫 資料不同下標不同
127.0.0.1:6379> SELECT 3 # 切換資料庫
OK
127.0.0.1:6379[3]> DBSIZE # 查看當前資料庫的大小
(integer) 0
127.0.0.1:6379> exists name # 判斷key是否存在
(integer) 0
127.0.0.1:6379> exists name qiandu # 判斷key為qiandu是否存在
(integer) 0 # 回傳1為存在 回傳0為不存在
127.0.0.1:6379> move name 1 # 移除key 1代表當前的資料庫
(integer) 1
127.0.0.1:6379> TYPE name # 查看key的具體型別
string
127.0.0.1:6379> expire name 10 # 設定過期時間
(integer) 1
127.0.0.1:6379> ttl name # 查看剩余時間
127.0.0.1:6379[3]> keys * # 查看所有的key
(empty array)
127.0.0.1:6379> FLUSHdb # 清空當前庫的key
OK
127.0.0.1:6379> FLUSHALL # 清空全部資料庫中的key
OK
更過命令:Redis命令中心
為什么Redis是單執行緒的呢?
Redis是單執行緒的! Redis是基于記憶體操作的,CPU并不是它的瓶頸,Reids的瓶頸是服務器的記憶體以及網路的帶寬,這些可以通過單執行緒來實作
為什么Redis的單執行緒還那么快呢?
Redis是C語言寫的,官方提供的資料為100000+的QPS(每秒查詢率) 不比其他的慢,
另外多執行緒的效率也不一定比單執行緒的效率高,Reids將所有的資料都放入記憶體之中,多次讀寫都在一個cpu進行,多執行緒會使用CPU進行切換背景關系的操作 這是一個耗時的操作,對于系統記憶體如果沒有記憶體的切換效率就是最佳的
基本資料型別
Redis有5大常見資料型別 String List Set Hash Zset 3大特殊資料型別geospatial hyperloglog bitmaps
String
string是最常用的型別了
127.0.0.1:6379> set name qiandu # 設定key與value
OK
127.0.0.1:6379> append name "hello" # 追加字串 如果key不存在 相當于新建
(integer) 11
127.0.0.1:6379> get name # 獲取值
"qianduhello"
127.0.0.1:6379> STRLEN name # 獲取字串的長度
(integer) 11
#========================================================================
127.0.0.1:6379> incr i # 自增 1
(integer) 1
127.0.0.1:6379> decr i # 自減 1
(integer) 0
127.0.0.1:6379> incrby i 2 # 設定步長 指定增量
(integer) 2
127.0.0.1:6379> decrby i 3 # 設定步長 指定減量
(integer) -1
#========================================================================
127.0.0.1:6379> get name
"qianduhello"
127.0.0.1:6379> getrange name 2 4 # 取指定范圍的字串 [2,4]
"and"
127.0.0.1:6379> getrange name 0 -1 # 獲取全部字串
"qianduhello"
127.0.0.1:6379> setrange name 0 w #替換指定位置的字串
(integer) 11
#========================================================================
# setex # 設定過期時間
127.0.0.1:6379> setex key1 10 "qinadu"
OK
# setnx # 不存在再設定 (在分布式鎖中會使用)
127.0.0.1:6379> setnx key2 "study redis"
(integer) 1
#========================================================================
# mset # 批量設定
127.0.0.1:6379> mset k1 v1 k2 v2 # 設定 k1=v1 k2=v2
OK
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
# mget # 批量獲取
127.0.0.1:6379> mget k1 k2 # 獲取key為k1、k2的值
1) "v1"
2) "v2"
127.0.0.1:6379> msetnx k1 v1 k4 v4 # msetnx 原子性操作 一起成功或者失敗
(integer) 0
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
#========================================================================
# 設定物件
127.0.0.1:6379> set user:1 {name:qiandu,age:12}
# 方法2
127.0.0.1:6379> mset user:2:name qiandu user:2:age 3
#========================================================================
# getset #先獲取值,在設定
127.0.0.1:6379> getset name "qiandu666" #如果不存在值 回傳nil
(nil)
127.0.0.1:6379> get name
"qiandu666"
127.0.0.1:6379> getset name "qiandu" # 如果存在 獲取原來的值并且設定新的值
"qiandu666"
127.0.0.1:6379> get name
"qiandu"
String的使用場景:計數器(文章的統計數量等)、物件的快取存盤
List
List是一種的基本的資料型別
# lpush
127.0.0.1:6379> lpush list one # 將值插入串列頭部
(integer) 1
127.0.0.1:6379> lpush list wo
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1 # 通過區間獲取具體的值
1) "three"
2) "wo"
3) "one"
# rpush
127.0.0.1:6379> rpush list four # 將值插入串列尾部
#========================================================================
127.0.0.1:6379> lpop list # 移除頭部
"three"
127.0.0.1:6379> rpop list # 移除尾部
"four"
#========================================================================
# lindex
127.0.0.1:6379> lindex list 1 # 獲取list的第一個值
"one"
# llen
127.0.0.1:6379> llen list # 獲取長度
(integer) 2
# lrem
127.0.0.1:6379> lrem list 1 two # 從list中移除一個值為two的操作
#========================================================================
# rpoplpush 移除串列的最后一個元素并移動到新的串列之中
127.0.0.1:6379> rpoplpush list myList
"one"
127.0.0.1:6379> lrange list 0 -1
(empty array)
127.0.0.1:6379> lrange myList 0 -1
1) "one"
127.0.0.1:6379>
#========================================================================
#lset 將串列中指定下標的值替換為另外一個 不存在串列會報錯
127.0.0.1:6379> lset myList 0 qd
OK
127.0.0.1:6379> lrange myList 0 -1
1) "qd"
#========================================================================
# linsert 插入命令
127.0.0.1:6379> linsert myList after qd qd666
(integer) 2
127.0.0.1:6379> lrange myList 0 -1
1) "qd"
2) "qd666"
小結
- list實際上是一個鏈表
- 如果key不存在,會創建新的鏈表
- 如果key存在,新增內容
- 如果移除了所有值,就是空鏈表,也代表不存在
- 在兩邊插入操作效率更高
- 可以用list實作訊息佇列的功能
Set
set中的值是不能重復的
127.0.0.1:6379> sadd myset qiandu qiandu666 # sadd 添加元素
(integer) 2
127.0.0.1:6379> smembers myset # smembers 獲取指定集合中的元素
1) "qiandu"
2) "qiandu666"
127.0.0.1:6379> sismember myset qiandu # 判斷集合中是否含有指定的值
(integer) 1 # 有回傳1 無回傳0
127.0.0.1:6379> sismember myset qiandua
(integer) 0
127.0.0.1:6379> scard myset # 判斷集合中元素的個數
(integer) 2
127.0.0.1:6379> srem myset qiandu666 # 移除集合中的指定元素
(integer) 1
#========================================================================
127.0.0.1:6379> SRANDMEMBER myset 1 # 隨機獲取元素
1) "qiandu"
127.0.0.1:6379> spop myset # 隨機洗掉元素
"qiandu"
#========================================================================
127.0.0.1:6379> smove myset2 myset qiandu123 # 將指定的元素移動到另一個集合之中
(integer) 1
127.0.0.1:6379> smembers myset
1) "qiandu123"
#========================================================================
127.0.0.1:6379> sdiff myset myset2 # 取myset中myset2沒有的元素
(empty array)
127.0.0.1:6379> sinter myset myset2 # 取交集
1) "qiandu123"
127.0.0.1:6379> SUNION myset myset2 # 取并集
1) "qiandu123"
2) "qiandu888"
小結
set集合中存放的是無序的、不可重復的資料、實際應用場景:共同關注、好友推薦
Hash
hash,我們當作一個map集合對待就簡單了 存放的是map集合 本質與String沒有太大的區別
127.0.0.1:6379> hset myhash field qiandu
(integer) 1
127.0.0.1:6379> hget myhash field
"qiandu"
127.0.0.1:6379> hmset myhash field1 qiandu field2 hello # 設定多個值
OK
127.0.0.1:6379> hmget myhash field1 field2 # 獲取多個值
1) "qiandu"
2) "hello"
127.0.0.1:6379> hgetall myhash # 獲取所有的key與value
1) "field"
2) "qiandu"
127.0.0.1:6379> hdel myhash field # 洗掉欄位
(integer) 1
127.0.0.1:6379> hlen myhash # 獲取長度
(integer) 2
127.0.0.1:6379> hexists myhash field1 # 判斷指定欄位是否存在
(integer) 1
#========================================================================
127.0.0.1:6379> hkeys myhash # 只獲取key
1) "field1"
2) "field2"
127.0.0.1:6379> hvals myhash # 只獲取value
1) "field2"
2) "hello"
#========================================================================
hincrby myhash field3 5 # 指定增量
小結
可以用hash存放經常變動的資料、或者用戶的資訊
Zset
zset與set只差了一個z 但是zset可以排序
127.0.0.1:6379> zadd zset 1 one # 添加一個值
(integer) 1
127.0.0.1:6379> zadd zset 2 two 3 three # 添加多個值
(integer) 2
127.0.0.1:6379> zrange zset 0 -1 # 取得全部資料
1) "one"
2) "two"
3) "three"
#========================================================================
127.0.0.1:6379> zadd score 100 qiandu 200 xiaohong 300 xiaowang
(integer) 3
127.0.0.1:6379> ZRANGEBYSCORE score -inf +inf # 排序 正(負)無窮
1) "qiandu"
2) "xiaohong"
3) "xiaowang"
127.0.0.1:6379> zrevrange score 0 -1 # 排序 從大到小
#========================================================================
127.0.0.1:6379> zrem score xiaohong # 移除元素
(integer) 1
127.0.0.1:6379> zcard score # 獲取集合的大小
(integer) 2
127.0.0.1:6379> zcount score 1 3 # 獲取指定區間的成員數量
(integer) 0
小結
set可以實作的zset都可以實作還要排序功能 使用場景:權重、排行榜
特殊資料型別
geospatial
這個是提供地理位置的api 比如打車、附近的人、兩地距離都可以用它來實作
geoadd 添加地理位置
# getadd 添加地理位置
# 規則:兩級無法直接添加,我們一般會下載城市資料,直接通過java程式一次性匯入!
# 引數:經度、緯度、名稱
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
geopos 獲取城市的經度與緯度
127.0.0.1:6379> geopos china:city beijing
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
GEODIST 回傳兩個給定位置之間的距離,
如果兩個位置之間的其中一個不存在, 那么命令回傳空值,指定單位的引數 unit 必須是以下單位的其中一個:
- m 表示單位為米, 默認
- km 表示單位為千米,
- mi 表示單位為英里,
- ft 表示單位為英尺,
127.0.0.1:6379> geodist china:city beijing shanghai
"1067378.7564"
# 改變單位
127.0.0.1:6379> geodist china:city beijing shanghai km
"1067.3788"
GEORADIUS :以給定的經緯度為中心,找出某一半徑的所有位置元素,應用場景(附近的人) georadius 命令-----詳情點我
127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km
# 110 30 模擬定位的經緯度 以當前位置查找半徑在1000km以內的城市
GEORADIUSBYMEMBER 中心點是由給定的位置元素決定的
127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 2000 km
1) "shanghai"
2) "beijing"
Hyperloglog
基數:兩個集合中不重復的元素
應用:可以使用它用作網站統計的訪問量,傳統方式是使用set來統計它的元素作為判斷 ,但是僅僅只因為計數還要保存用戶的資訊、浪費記憶體;如果可以忽略容錯,可以使用它完成
127.0.0.1:6379> pfadd set a s f e g y # 添加元素
(integer) 1
127.0.0.1:6379> PFCOUNT set # 獲取元素個數
(integer) 6
127.0.0.1:6379> PFMERGE set1 set set2 # 合并集合
OK
Bitmap
bitmaps(位圖)也是一種資料結構,操作二進制位來進行記錄,只有0與1兩種狀態
使用bitmap的場景有很多:例如 統計(活躍與不活躍)用戶的資訊、是否登錄、打卡......只要是兩個狀態的,都可以使用bitmap解決
# 假設打卡場景 0:星期一 1:星期二 以此類推
127.0.0.1:6379> setbit sign 0 1 # 星期一成功打卡
(integer) 0
127.0.0.1:6379> setbit sign 1 0 # 星期二未打卡
(integer) 0
127.0.0.1:6379> getbit sign 0 # 檢查某天的打卡清空
(integer) 1
127.0.0.1:6379> BITCOUNT sign # 統計打卡記錄
(integer) 1
基本的事務操作
事務我們在MysQL這章節開始了解,事務有4個原則; 在Redis中事務中的所有命令都會被序列化 且會按照順序執行
Redis的事務,不能保證原子性
Redis事務也沒有隔離級別的概念 只有發起執行命令時才會執行
操作步驟:
- 開啟事務(multi)
- 命令入隊
- 執行事務(exec)
執行事務
# 開啟事務
127.0.0.1:6379> multi
OK
# 命令入隊
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
# 執行事務
127.0.0.1:6379(TX)> exec
1) OK
2) OK
取消事務
# 開啟事務
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k2 v2
QUEUED
# 取消事務
127.0.0.1:6379(TX)> DISCARD
OK
# 事務中的命令沒有被執行
127.0.0.1:6379> get k2
(nil)
在事務中出現錯誤情況分為兩種 類比java
- 編譯時例外(命令有誤):事務中的命令是不會被執行的
- 運行時例外:如果事務中出現語意性例外時,其他命令可以正常執行
樂觀鎖
Reids使用watch(監視)來實作樂觀鎖
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money # 監視 money
OK
127.0.0.1:6379> multi #事務正常結束,期間未發生變動、正常結束
OK
127.0.0.1:6379(TX)> decrby money 10
QUEUED
127.0.0.1:6379(TX)> incrby out 10
QUEUED
127.0.0.1:6379(TX)> exec
1) (integer) 90
2) (integer) 10
如果事務執行失敗 先使用unwatch解鎖 然后獲取最新的值再次監視
Jedis
什么是Jedis ?
Redis官方推薦的java連接開發工具!使用lava操作Redis 中間件!如果你要使用java操作redis,那么一定要對Jedis十分的熟悉!
- 匯入依賴
<!-- jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.6.1</version>
</dependency>
<!--fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.54</version>
</dependency>
- 編碼測驗
- 連接資料庫
- 操作命令
- 關閉連接
測驗連接
public static void main(String[] args) {
//1. new jedis物件
Jedis jedis = new Jedis("127.0.0.1", 6379);
//jedis 所有指令就是上述學的指令
System.out.println(jedis.ping());
}
常用API
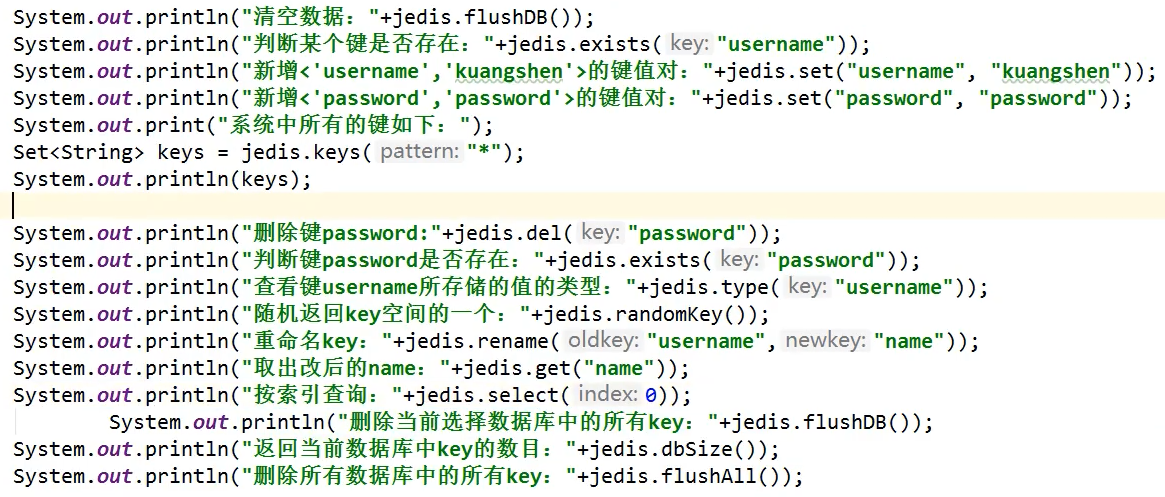
String


List

Set
圖片無法顯示
Hash
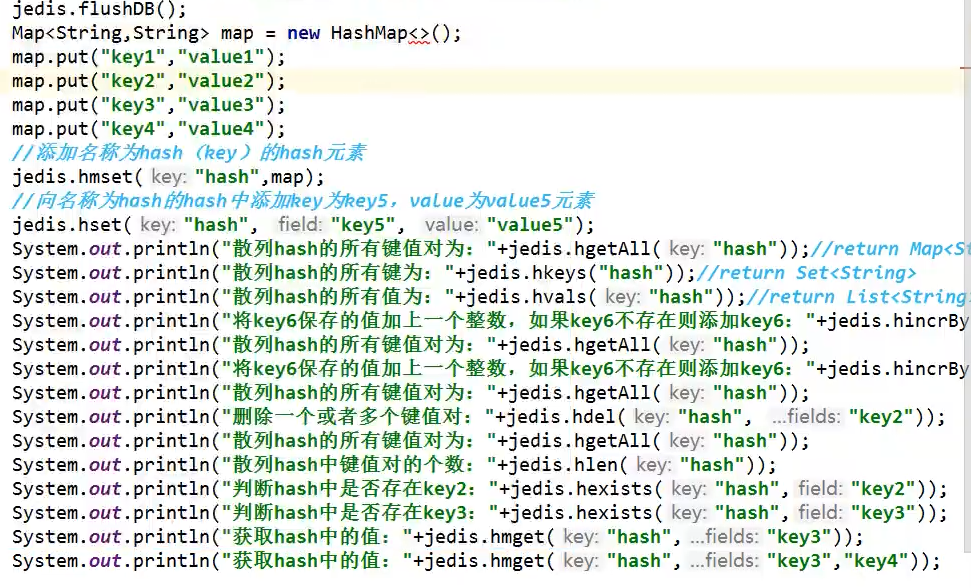
事務
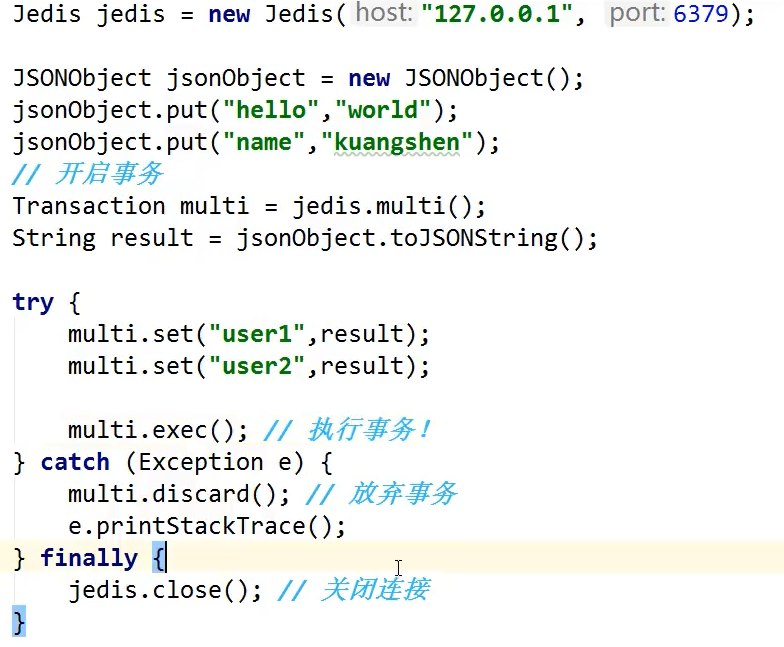
整合SpringBoot
相關配置
- 配置
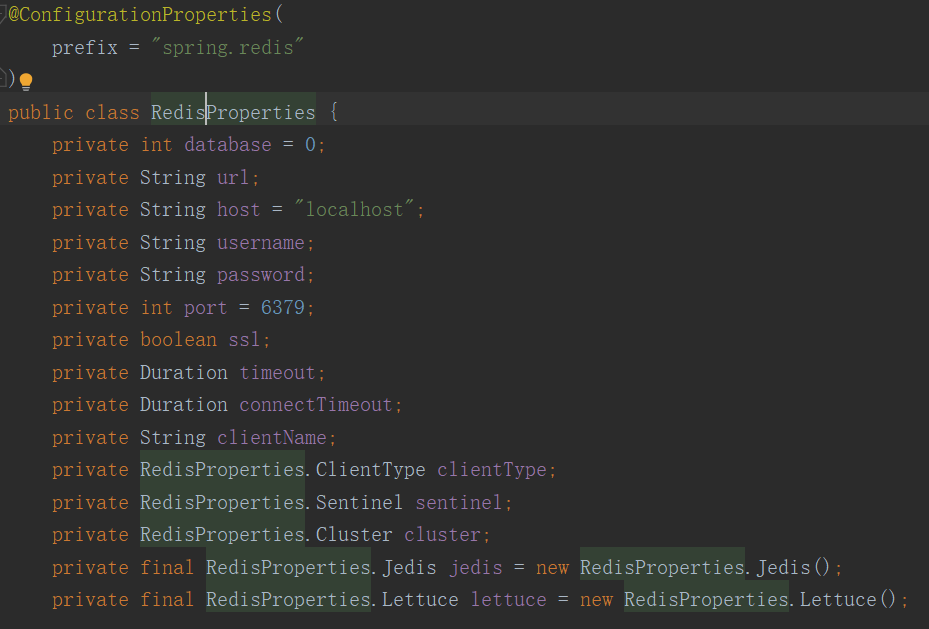
- 原始碼
@Bean
@ConditionalOnMissingBean( name = {"redisTemplate"})
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
//默認的 RedisTemplate 沒有過多的設定,redis物件都是需要序列化!
//兩個泛型都是 object,object的型別,我們后使用需要強制轉換<String,object>
RedisTemplate<Object, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
//由于string 是redis中最常使用的型別,所以說單獨提出來了一個bean !
@Bean
@ConditionalOnMissingBean
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
測驗
- 匯入依賴
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 配置
## redis配置
spring.redis.host=127.0.0.1
spring.redis.port=6379
- 簡單測驗
@Autowired
private RedisTemplate redisTemplate;
@Test
public void test01() {
//操作字串 類似String
redisTemplate.opsForValue().set("key", "qiandu");
System.out.println(redisTemplate.opsForValue().get("key"););
//獲取redis的連接物件 ,用的少
// RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
// connection.flushAll();
}
序列化


它默認的序列化方式是jdk序列化,真實開發一般使用json傳遞資料、我們需要使用json方式序列化,我們可撰寫配置來盡可能的滿足開發
User user = new User(10, "qd666", "123456", 1);
String jsonUser=new ObjectMapper.writeValueAsString(user);
redisTemplate.opsForValue().set("user",jsonUser);
redisTemplate.opsForValue().get("user");
在企業的開發中 pojo類一般都會實作序列化介面
自定義RedisTemplate
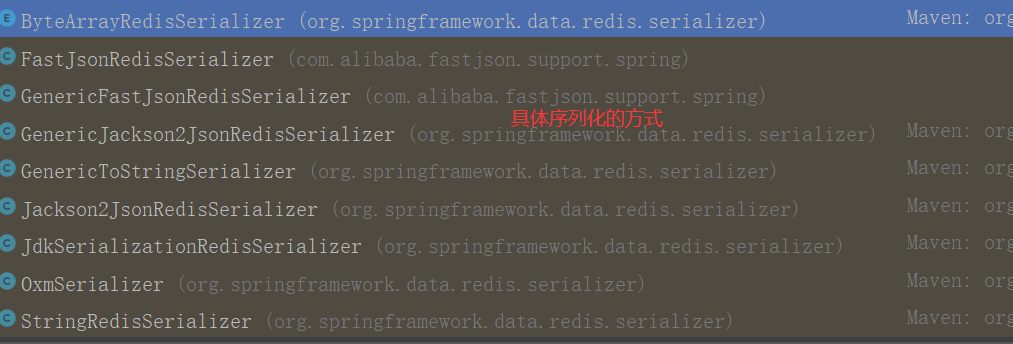
自己撰寫一個模板,可以拿去直接使用
@Configuration
public class ReidsConfig {
//撰寫配置類
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
//json序列化配置
Jackson2JsonRedisSerializer Jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<Object>(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
Jackson2JsonRedisSerializer.setObjectMapper(om);
//String 的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
//key使用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
//hash使用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
//value采用的是Jackson
template.setValueSerializer(Jackson2JsonRedisSerializer);
//hash的value采用的是Jackson
template.setDefaultSerializer(Jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
在開發中,直接使用原生的api太麻煩了,我們可以撰寫RedisUtil來操作
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
@Component
public final class RedisUtil {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// =============================common============================
/**
* 指定快取失效時間
*
* @param key 鍵
* @param time 時間(秒)
*/
public boolean expire(String key, long time) {
try {
if (time > 0) {
redisTemplate.expire(key, time, TimeUnit.SECONDS);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根據key 獲取過期時間
*
* @param key 鍵 不能為null
* @return 時間(秒) 回傳0代表為永久有效
*/
public long getExpire(String key) {
return redisTemplate.getExpire(key, TimeUnit.SECONDS);
}
/**
* 判斷key是否存在
*
* @param key 鍵
* @return true 存在 false不存在
*/
public boolean hasKey(String key) {
try {
return redisTemplate.hasKey(key);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 洗掉快取
*
* @param key 可以傳一個值 或多個
*/
@SuppressWarnings("unchecked")
public void del(String... key) {
if (key != null && key.length > 0) {
if (key.length == 1) {
redisTemplate.delete(key[0]);
} else {
redisTemplate.delete(CollectionUtils.arrayToList(key));
}
}
}
// ============================String=============================
/**
* 普通快取獲取
*
* @param key 鍵
* @return 值
*/
public Object get(String key) {
return key == null ? null : redisTemplate.opsForValue().get(key);
}
/**
* 普通快取放入
*
* @param key 鍵
* @param value 值
* @return true成功 false失敗
*/
public boolean set(String key, Object value) {
try {
redisTemplate.opsForValue().set(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 普通快取放入并設定時間
*
* @param key 鍵
* @param value 值
* @param time 時間(秒) time要大于0 如果time小于等于0 將設定無限期
* @return true成功 false 失敗
*/
public boolean set(String key, Object value, long time) {
try {
if (time > 0) {
redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS);
} else {
set(key, value);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 遞增
*
* @param key 鍵
* @param delta 要增加幾(大于0)
*/
public long incr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("遞增因子必須大于0");
}
return redisTemplate.opsForValue().increment(key, delta);
}
/**
* 遞減
*
* @param key 鍵
* @param delta 要減少幾(小于0)
*/
public long decr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("遞減因子必須大于0");
}
return redisTemplate.opsForValue().increment(key, -delta);
}
// ================================Map=================================
/**
* HashGet
*
* @param key 鍵 不能為null
* @param item 項 不能為null
*/
public Object hget(String key, String item) {
return redisTemplate.opsForHash().get(key, item);
}
/**
* 獲取hashKey對應的所有鍵值
*
* @param key 鍵
* @return 對應的多個鍵值
*/
public Map<Object, Object> hmget(String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* HashSet
*
* @param key 鍵
* @param map 對應多個鍵值
*/
public boolean hmset(String key, Map<String, Object> map) {
try {
redisTemplate.opsForHash().putAll(key, map);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* HashSet 并設定時間
*
* @param key 鍵
* @param map 對應多個鍵值
* @param time 時間(秒)
* @return true成功 false失敗
*/
public boolean hmset(String key, Map<String, Object> map, long time) {
try {
redisTemplate.opsForHash().putAll(key, map);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一張hash表中放入資料,如果不存在將創建
*
* @param key 鍵
* @param item 項
* @param value 值
* @return true 成功 false失敗
*/
public boolean hset(String key, String item, Object value) {
try {
redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一張hash表中放入資料,如果不存在將創建
*
* @param key 鍵
* @param item 項
* @param value 值
* @param time 時間(秒) 注意:如果已存在的hash表有時間,這里將會替換原有的時間
* @return true 成功 false失敗
*/
public boolean hset(String key, String item, Object value, long time) {
try {
redisTemplate.opsForHash().put(key, item, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 洗掉hash表中的值
*
* @param key 鍵 不能為null
* @param item 項 可以使多個 不能為null
*/
public void hdel(String key, Object... item) {
redisTemplate.opsForHash().delete(key, item);
}
/**
* 判斷hash表中是否有該項的值
*
* @param key 鍵 不能為null
* @param item 項 不能為null
* @return true 存在 false不存在
*/
public boolean hHasKey(String key, String item) {
return redisTemplate.opsForHash().hasKey(key, item);
}
/**
* hash遞增 如果不存在,就會創建一個 并把新增后的值回傳
*
* @param key 鍵
* @param item 項
* @param by 要增加幾(大于0)
*/
public double hincr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, by);
}
/**
* hash遞減
*
* @param key 鍵
* @param item 項
* @param by 要減少記(小于0)
*/
public double hdecr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, -by);
}
// ============================set=============================
/**
* 根據key獲取Set中的所有值
*
* @param key 鍵
*/
public Set<Object> sGet(String key) {
try {
return redisTemplate.opsForSet().members(key);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 根據value從一個set中查詢,是否存在
*
* @param key 鍵
* @param value 值
* @return true 存在 false不存在
*/
public boolean sHasKey(String key, Object value) {
try {
return redisTemplate.opsForSet().isMember(key, value);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 將資料放入set快取
*
* @param key 鍵
* @param values 值 可以是多個
* @return 成功個數
*/
public long sSet(String key, Object... values) {
try {
return redisTemplate.opsForSet().add(key, values);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 將set資料放入快取
*
* @param key 鍵
* @param time 時間(秒)
* @param values 值 可以是多個
* @return 成功個數
*/
public long sSetAndTime(String key, long time, Object... values) {
try {
Long count = redisTemplate.opsForSet().add(key, values);
if (time > 0)
expire(key, time);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 獲取set快取的長度
*
* @param key 鍵
*/
public long sGetSetSize(String key) {
try {
return redisTemplate.opsForSet().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 移除值為value的
*
* @param key 鍵
* @param values 值 可以是多個
* @return 移除的個數
*/
public long setRemove(String key, Object... values) {
try {
Long count = redisTemplate.opsForSet().remove(key, values);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
// ===============================list=================================
/**
* 獲取list快取的內容
*
* @param key 鍵
* @param start 開始
* @param end 結束 0 到 -1代表所有值
*/
public List<Object> lGet(String key, long start, long end) {
try {
return redisTemplate.opsForList().range(key, start, end);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 獲取list快取的長度
*
* @param key 鍵
*/
public long lGetListSize(String key) {
try {
return redisTemplate.opsForList().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 通過索引 獲取list中的值
*
* @param key 鍵
* @param index 索引 index>=0時, 0 表頭,1 第二個元素,依次類推;index<0時,-1,表尾,-2倒數第二個元素,依次類推
*/
public Object lGetIndex(String key, long index) {
try {
return redisTemplate.opsForList().index(key, index);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 將list放入快取
*
* @param key 鍵
* @param value 值
*/
public boolean lSet(String key, Object value) {
try {
redisTemplate.opsForList().rightPush(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 將list放入快取
*
* @param key 鍵
* @param value 值
* @param time 時間(秒)
*/
public boolean lSet(String key, Object value, long time) {
try {
redisTemplate.opsForList().rightPush(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 將list放入快取
*
* @param key 鍵
* @param value 值
* @return
*/
public boolean lSet(String key, List<Object> value) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 將list放入快取
*
* @param key 鍵
* @param value 值
* @param time 時間(秒)
* @return
*/
public boolean lSet(String key, List<Object> value, long time) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根據索引修改list中的某條資料
*
* @param key 鍵
* @param index 索引
* @param value 值
* @return
*/
public boolean lUpdateIndex(String key, long index, Object value) {
try {
redisTemplate.opsForList().set(key, index, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 移除N個值為value
*
* @param key 鍵
* @param count 移除多少個
* @param value 值
* @return 移除的個數
*/
public long lRemove(String key, long count, Object value) {
try {
Long remove = redisTemplate.opsForList().remove(key, count, value);
return remove;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
}
Redis.conf詳解
這個檔案我們再熟悉不過了,我們啟動reids就需要這個組態檔
單位
組態檔 units單位對大小寫不敏感
包含
# include .\path\to\local.conf
# include c:\path\to\other.conf
可以把多個組態檔配置一起
網路 NETWORK
bind 127.0.0.1 # 系結的IP
protected-mode yes # 保證安全性
port 6379 #埠號
通用配置 GENERAL
daemonized yes #以守護行程的方式運行
pidfile /var/run/redis_6379.pid # 如果以后臺的方式運行,我們就需要指定一個 pid 檔案!
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice # 日志級別
logfile "" # 日志的檔案位置名
databases 16 # 資料庫數量
快照 SNAPSHOTTING
? 持久化,在規定的時間內,執行了多少次操作,則會持久化到檔案.rdb .aof
# 如果900s內,如果至少有一個1 key進行了修改,我們及進行持久化操作
save 900 1
# 如果300s內,如果至少有一個10 key進行了修改,我們及進行持久化操作
save 300 10
# 如果60s內,如果至少有一個10000 key進行了修改,我們及進行持久化操作
save 60 10000
stop-writes-on-bgsave-error yes # 持久化錯誤是否繼續作業
rdbcompression yes # 是否壓縮rdb檔案、需要消耗cpu資源
rdbchecksum yes # 是否校驗rdb檔案
dir ./ # rdb檔案保存目錄
復制 REPLICATION
# slaveof <masterip> <masterport> # 配置主機資訊
# masterauth <master-password> # 主機密碼
安全 SECURITY
# requirepass foobared # 默認沒有密碼
## 設定密碼
## 方式1
requirepass 123456 # 修改組態檔
## 方式2 命令列
config get requirepass # 獲取密碼
config set requirepass 123456 # 設定密碼
auth 123456 # 驗證
限制 LIMITS
# maxclients 10000 # 最大客戶端數
# maxmemory <bytes> # 最大記憶體設定
# maxmemory-policy noeviction # 記憶體上限處理策略 看下圖

APPEND ONLY MODE aof的配置
appendonly no # 默認不開啟
appendfilename "appendonly.aof" # 檔案名
# appendfsync always # 每次修改都會 sync,消耗性能
appendfsync everysec # 每秒執行一次 sync,可能會丟失這1s的資料!
# appendfsync no # 不執行sync,這個時候作業系統自己同步資料,速度最快!
Redis持久化
面試和作業,持久化都是重點!
Redis是記憶體資料庫,如果不將記憶體中的資料庫狀態保存到磁盤,那么一旦服務器行程退出,服務器中的資料庫狀態也會消失,所以Redis提供了持久化功能!
RDB
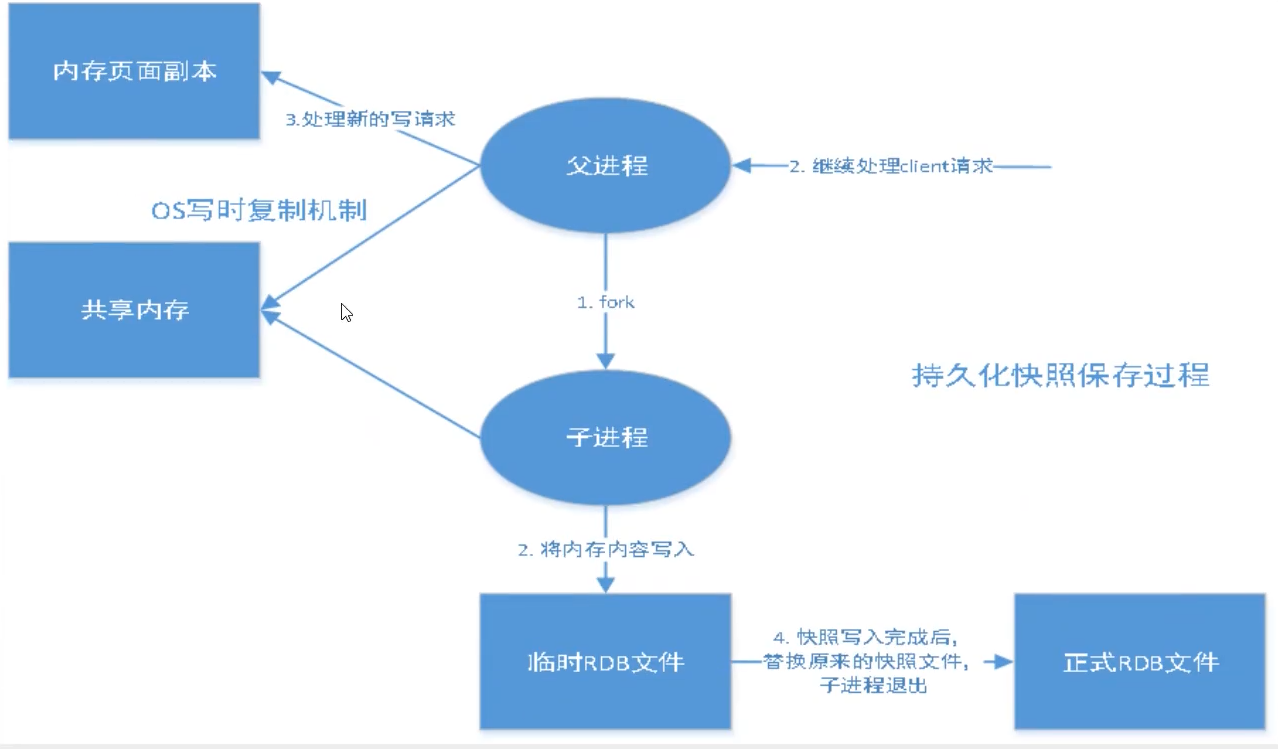
在指定的時間間隔內將記憶體中的資料集快照寫入磁盤,也就是行話講的Snapshot快照,它恢復時是將快照檔案直接讀到記憶體里,
Redis會單獨創建 ( fork )一個子行程來進行持久化,會先將資料寫入到一個臨時檔案中,待持久化程序都結束了,再用這個臨時檔案替換上次持久化好的檔案,整個程序中,主行程是不進行任何I0操作的,這就確保了極高的性能,如果需要進行大規模資料的恢復,且對于資料恢復的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效,RDB的缺點是最后一次持久化后的資料可能丟失,
rdb保存的檔案是dump.rdb 在生產環境我們會將這個檔案進行備份
觸發規則
- save的規則滿足的情況下,會自動觸發rdb規則
- 執行flushall命令,也會觸發我們的rdb規則
- 退出redis,也會產生rdb檔案!
恢復檔案
- 只需要將rdb檔案放在我們redis啟動目錄就可以,redis啟動的時候會自動檢查dump.rdb恢復其中的資料
- 查看需要存在的位置
127.0.0.1:6379> config get dir
1) "dir"
2) "/www/server/redis" # 如果在這個目錄下存在 dump .rdb檔案,啟動就會自動恢復其中的資料
優點
- 適合大規模的資料恢復
- 對資料的完整性要不高
缺點
- 需要一定的時間間隔行程操作!如果redis意外宕機了,這個最后一次修改資料就沒有的了!
- fork行程的時候,會占用一定的內容空間!!
AOF
意為追加檔案,將所有的命令全部記錄下來,恢復的時候將命令全部執行一遍
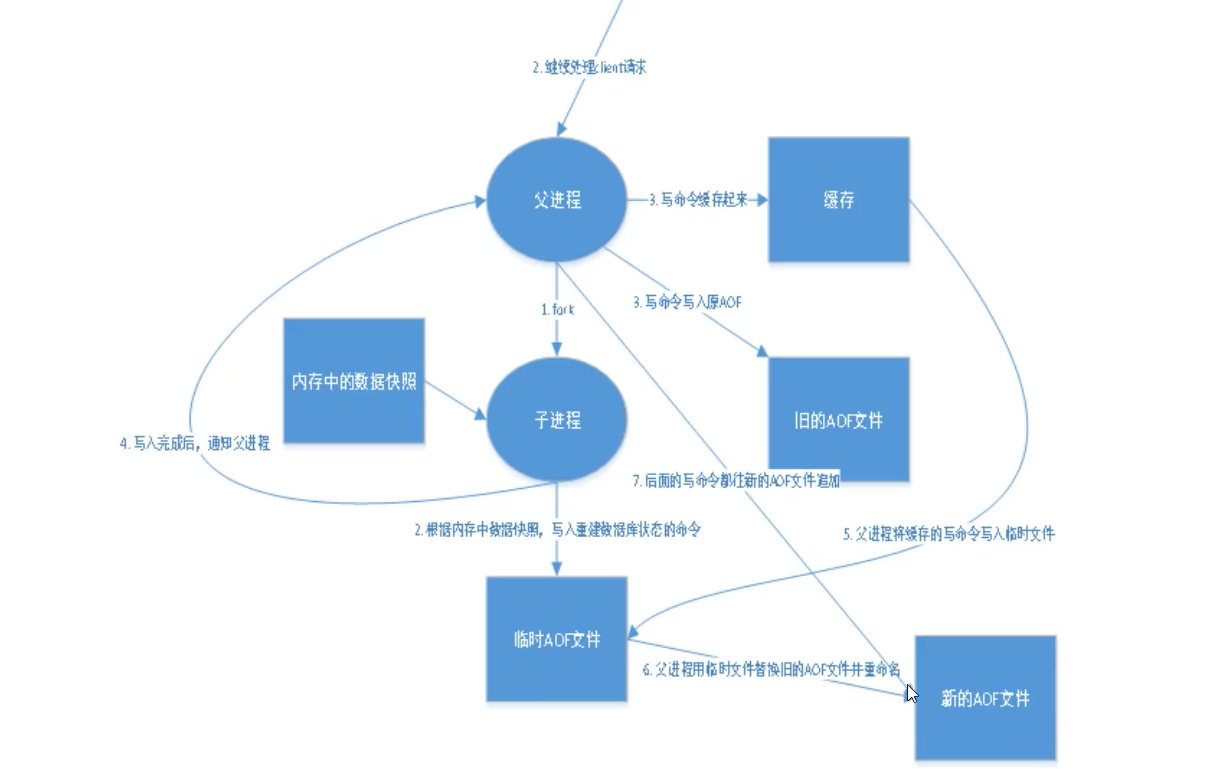
以日志的形式來記錄每個寫操作,將Redis執行過的所有指令記錄下來(讀操作不記錄),只許追加檔案但不可以改寫檔案,redis啟動之扯訓讀取該檔案重新構建資料,換言之,redis重啟的話就根據日志檔案的內容將寫指令從前到后執行一次以完成資料的恢復作業
Aof保存的是appendonly.aof檔案
默認是不開啟的,我們需要手動進行配置!我們只需要將appendorly改為yes就開啟了aof ! 重啟reids即可以生效
如果appendonly.aof 被修改,可以使用以下命令恢復
redis-check-aof - -fix appendonly.aof
優點
- 每次修改都同步,保證完整性
缺點
- 相對于資料檔案來說,aof遠遠大于rdb,修復的速度也比 rdb慢!
- Aof運行效率也要比 rdb 慢,所以我們redis默認的配置就是rdb持久化
擴展


Redis主從復制
概念
主從復制,是指將一臺Redis服務器的資料,復制到其他的Redis服務器,前者稱為主節點(masterleader),后者稱為從節點(slave/follower);資料的復制是單向的,只能由主節點到從節點,Master以寫為主,Slave以讀為主,
默認情況下,每臺Redis服務器都是主節點;且一個主節點可以有多個從節點(或沒有從節點),但一個從節點只能有一個主節點,
作用:
- 資料冗余︰主從復制實作了資料的熱備份,是持久化之外的一種資料冗余方式,
- 故障恢復∶當主節點出現問題時,可以由從節點提供服務,實作快速的故障恢復;實際上是一種服務的冗余,
- 負載均衡∶在主從復制的基礎上,配合讀寫分離,可以由主節點提供寫服務,由從節點提供讀服務(即寫Redis資料時應用連接主節點,讀Redis資料時應用連接從節點),分擔服務器負載﹔尤其是在寫少讀多的場景下,通過多個從節點分擔讀負載,可以大大提高Redis服務器的并發量,
- 高可用基石∶除了上述作用以外,主從復制還是哨兵和集群能夠實施的基礎,因此說主從復制是Redis高可用的基礎,
一般來說,要將Redis運用于工程專案中,只使用一臺Redis是萬萬不能的,原因如下︰
1、從結構上,單個Redis服務器會發生單點故障,并且一臺服務器需要處理所有的請求負載,壓力較大;
2、從容量上,單個Redis服務器記憶體容量有限,就算一臺Redis服務器記憶體容量為256G,也不能將所有記憶體用作Redis存盤記憶體,一般來說,單臺Redis最大使用記憶體不應該超過20G,
架構
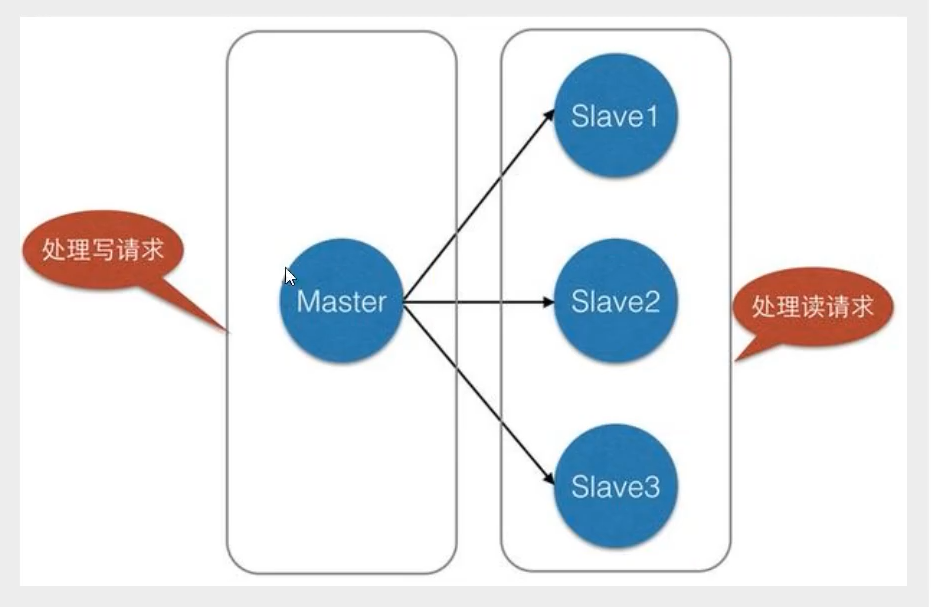
環境配置
查看配置資訊
127.0.0.1:6379> info replication
# Replication
role:master # 角色
connected_slaves:0 # 連接從機的個數
master_failover_state:no-failover
master_replid:3f55769ced26d9c31df8a1568e7653195933bf34
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
配置從機
127.0.0.1:6380> slaveof 127.0.0.1 6379 # 選擇主機
ok
真實的從主配置應該在組態檔中配置,這樣的話是永久的 主機可以寫,從機不能寫只能讀!主機中的所有資訊和資料,都會自動被從機保存
復制原理
Slave啟動成功連接到master后會發送一個sync同步命令
Master接到命令,啟動后臺的存盤行程,同時收集所有接收到的用于修改資料集命令,在后臺行程執行完畢之后,master將傳送整個資料檔案到slave,并完成一次完全同步,
全量復制︰而slave服務在接收到資料庫檔案資料后,將其存盤并加載到記憶體中,
增量復制:Master繼續將新的所有收集到的修改命令依次傳給slave,完成同步
但是只要是重新連接master,一次完全同步(全量復制)將被自動執行
哨兵模式
概述
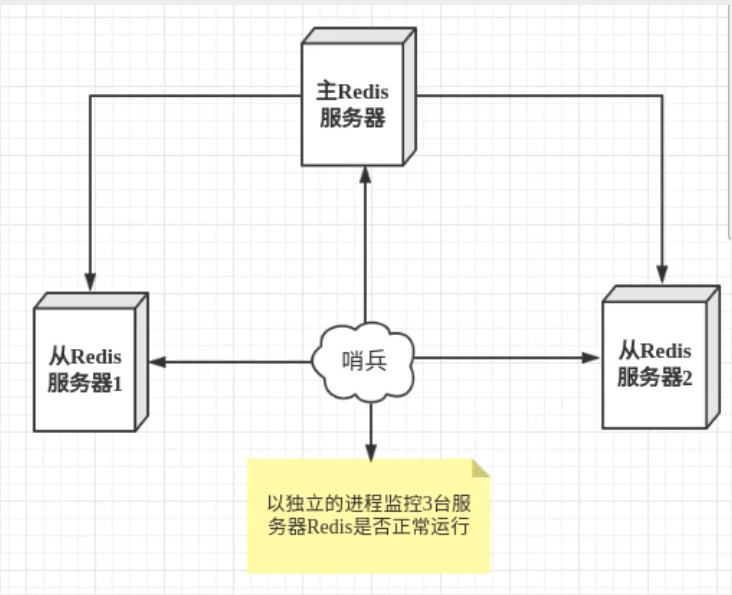
主從切換技術的方法是∶當主服務器宕機后,需要手動把一臺從服務器切換為主服務器,這就需要人工干預,費事費力,還會造成一段時間內服務不可用,這不是一種推薦的方式,更多時候,我們優先考慮哨兵模式,Redis從2.8開始正式提供了Sentinel (哨兵)架構來解決這個問題,
哨兵模式是一種特殊的模式,首先Redis提供了哨兵的命令,哨兵是一個獨立的行程,作為行程,它會獨立運行,其原理是哨兵通過發送命令,等待Redis服務器回應,從而監控運行的多個Redis實體,
基本模型:
這里的哨兵有兩個作用:
- 通過發送命令,讓Redis服務器回傳監控其運行狀態,包括主服務器和從服務器,
- 當哨兵監測到master宕機,會自動將slave切換成master,然后通過發布訂閱模式通知其他的從服務器,修改組態檔,讓它們切換主機,
然而一個哨兵行程對Redis服務器進行監控,可能會出現問題,為此,我們可以使用多個哨兵進行監控,各個哨兵之間還會進行監控,這樣就形成了多哨兵模式,
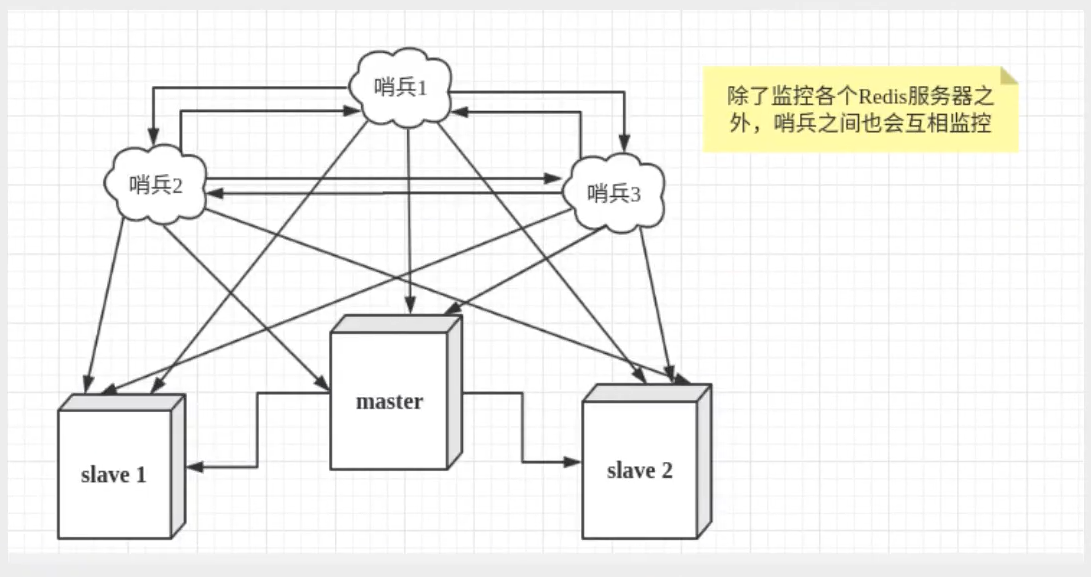
假設主服務器宕機,哨兵1先檢測到這個結果,系統并不會馬上進行failover程序,僅僅是哨兵1主觀的認為主服務器不可用,這個現象成為主觀下線,當后面的哨兵也檢測到主服務器不可用,并且數量達到一定值時,那么哨兵之間就會進行一次投票,投票的結果由一個哨兵發起,進行failover[故障轉移]操作,切換成功后,就會通過發布訂閱模式,讓各個哨兵把自己監控的從服務器實作切換主機,這個程序稱為客觀下線,
配置
- 配置哨兵組態檔
sentinel.conf
# # sentinel monitor 被監控的名稱 host port 1:票數最多的,就會成為主機
sentinel monitor myredis 127.0.0.1 6379 1
- 啟動哨兵
redis-sentinel qdconfig/sentinel.conf
如果主機斷掉了,哨兵會根據它的演算法自動把一個從機變成主機;如果之前的主機恢復了做從機,
優點
- 哨兵集群,基于主從復制模式,所有的主從配置優點,它全有
- 主從可以切換,故障可以轉移,系統的可用性就會更好
- 哨兵模式就是主從模式的升級,手動到自動,更加健壯!
缺點
- Redis不好啊在線擴容的,集群容量一旦到達上限,在線擴容就十分麻煩!
- 實作哨兵模式的配置其實是很麻煩的,里面有很多選擇! 哨兵模式組態檔
Redis快取穿透和雪崩
Redis快取的使用,極大的提升了應用程式的性能和效率,特別是資料查詢方面,但同時,它也帶來了一些問題,其中,最要害的問題,就是資料的一致性問題,從嚴格意義上講,這個問題無解,如果對資料的一致性要求很高,那么就不能使用快取,
另外的一些典型問題就是,快取穿透、快取雪崩和快取擊穿,目前,業界也都有比較流行的解決方案
快取穿透
概念
快取穿透的概念很簡單,用戶想要查詢一個資料,發現redis記憶體資料庫沒有,也就是快取沒有命中,于是向持久層資料庫查詢,發現也沒有,于是本次查詢失敗,當用戶很多的時候,快取都沒有命中,于是都去請求了持久層資料庫,這會給持久層資料庫造成很大的壓力,這時候就相當于出現了快取穿透,
解決方案
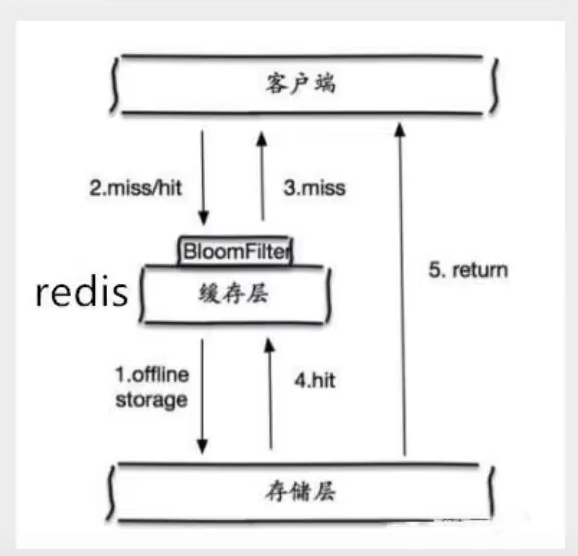
布隆過濾器
布隆過濾器是一種資料結構,對所有可能查詢的引數以hash形式存盤,在控制層先進行校驗,不符合則丟棄,從而避免了對底層存盤系統的查詢壓力﹔
快取空物件
當存盤層不命中后,即使回傳的空物件也將其快取起來,同時會設定一個過期時間,之后再訪問這個資料將會從快取中獲取,保護了后端資料源;
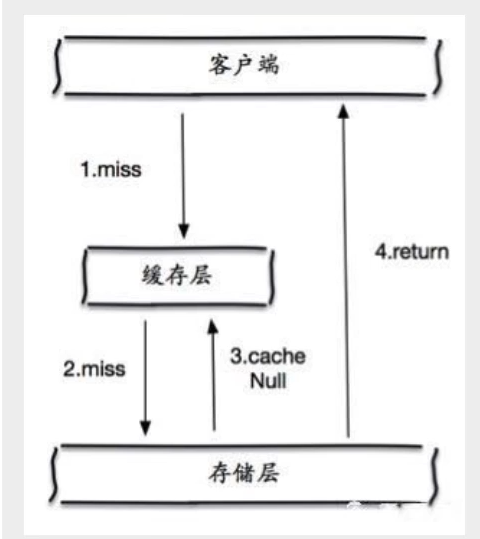
但是這種方法會存在兩個問題:
1、如果空值能夠被快取起來,這就意味著快取需要更多的空間存盤更多的鍵,因為這當中可能會有很多的空值的鍵;
2、即使對空值設定了過期時間,還是會存在快取層和存盤層的資料會有一段時間視窗的不一致,這對于需要保持一致性的業務會有影響,
快取擊穿
概述
這里需要注意和快取擊穿的區別,快取擊穿,是指一個key非常熱點,在不停的扛著大并發,大并發集中對這一個點進行訪問,當這個key在失效的瞬間,持續的大并發就穿破快取,直接請求資料庫,就像在一個屏障上鑿開了一個洞,
當某個key在過期的瞬間,有大量的請求并發訪問,這類資料一般是熱點資料,由于快取過期,會同時訪問資料庫來查詢最新資料,并且回寫快取,會導使資料庫瞬間壓力過大,
解決方案
設定熱點資料永不過期
從快取層面來看,沒有設定過期時間,所以不會出現熱點 key過期后產生的問題,
加互斥鎖
分布式鎖∶使用分布式鎖,保證對于每個key同時只有一個執行緒去查詢后端服務,其他執行緒沒有獲得分布式鎖的權限,因此只需要等待即可,這種方式將高并發的壓力轉移到了分布式鎖,因此對分布式鎖的考驗很大,
快取雪崩
概念
快取雪崩,是指在某一個時間段,快取集中過期失效,比如Redis宕機
產生雪崩的原因之一,比如在寫本文的時候,馬上就要到雙十二零點,很快就會迎來一波搶購,這波商品時間比較集中的放入了快取,假設快取一個小時,那么到了凌晨一點鐘的時候,這批商品的快取就都過期了,而對這批商品的訪問查詢,都落到了資料庫上,對于資料庫而言,就會產生周期性的壓力波峰,于是所有的請求都會達到存盤層,存盤層的呼叫量會暴增,造成存盤層也會掛掉的情況,
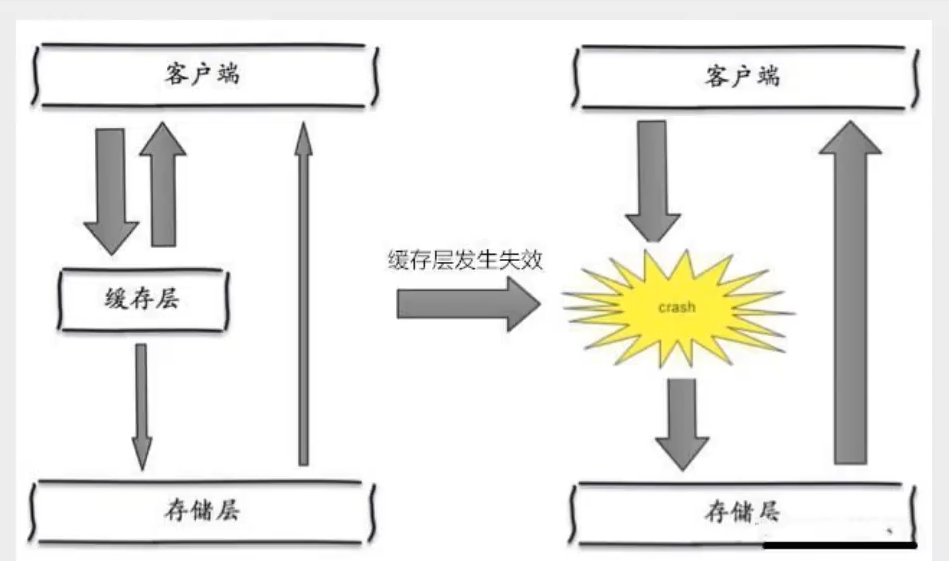
其實集中過期,倒不是非常致命,比較致命的快取雪崩,是快取服務器某個節點宕機或斷網,因為自然形成的快取雪崩,一定是在某個時間段集中創建快取,這個時候,資料庫也是可以頂住壓力的,無非就是對資料庫產生周期性的壓力而已,而快取服務節點的宕機,對資料庫服務器造成的壓力是不可預知的,很有可能瞬間就把資料庫壓垮,
解決方案
redis高可用
這個思想的含義是,既然redis有可能掛掉,那我多增設幾臺redis,這樣一臺掛掉之后其他的還可以繼續作業,其實就是搭建的集群,
限流降級
這個解決方案的思想是,在快取失效后,通過加鎖或者佇列來控制讀資料庫寫快取的執行緒數量,比如對某個key只允許一個執行緒查詢資料和寫快取,其他執行緒等待,
資料預熱
資料加熱的含義就是在正式部署之前,我先把可能的資料先預先訪問一遍,這樣部分可能大量訪問的資料就會加載到快取中,在即將發生大并發訪問前手動觸發加載快取不同的key,設定不同的過期時間,讓快取失效的時間點盡量均勻,
該筆記基于狂神的視頻講解所寫 視頻鏈接:【狂神說Java】Redis_嗶哩嗶哩
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/304225.html
標籤:NoSQL
下一篇:Redis事件機制