1、checkPoint
(1.1)Flink 中的每個方法或算子都是有狀態的, 狀態化的方法在處理元素/事件的時候存盤資料,使得狀態成為使各個型別的算子重要部分, Flink 通過為狀態添加 checkpoint(檢查點),使狀態具備容錯能力,
(1.2)Flink的CheckPoint機制可以與Stream和State持久化存盤互動的前提條件:
1)持久化的Source,支持在一定時間內重放事件,這種Source的典型例子就是持久化的訊息佇列(如Kafka、RabbitMQ等)或檔案系統(如HDFS、S3等),
2)用于State的持久化存盤介質,比如分布式檔案系統(如HDFS、S3等),
(1.3)Checkpoint 使得 Flink 能夠恢復狀態和在流中的位置,從而向應用提供和無故障執行時一樣的語意,
(1.4)可部分重發的資料源
Flink選擇最近完成的checkPoint,系統重放整個分布式資料流,然后給予每個operator在檢查點快照中的狀態,資料源被設定為從開始位置重新讀取流,eg:在Kafka中,消費者從偏移量開始重新消費,
(1.5)CheckPoint檢查點機制
checkpoint定期觸發產生快照,快照中的內容如下:
- 當前checkPoint開始時資料源(例如Kafka)中訊息的offset;
- 記錄了所有有狀態的operator當前的狀態資訊(中間計算結果),
2、barrier
Flink 使用 Chandy-Lamport algorithm 演算法的一種變體,即異步 barrier 快照(asynchronous barrier snapshotting),當 checkpoint coordinator(job manager 的一部分)指示 task manager 開始 checkpoint 時,它會讓所有 sources 記錄它們的偏移量,并將編號的 checkpoint barriers 插入到它們的流中,這些 barriers 流經 job graph,標注每個 checkpoint 前后的流部分,
這些barrier被注入資料流并與記錄一起作為資料流的一部分向下流動, barriers永遠不會超過記錄,資料流嚴格有序,barrier將資料流中的記錄隔離成一系列的記錄集合,并將一些集合中的資料加入到當前的快照中,而另一些資料加入到下一個快照中,
checkpoint n將包含每個 operator 的 state,這些 state 對應的 operator 消費了嚴格在 checkpoint barrier n 之前的所有事件,并且不包含在此(checkpoint barrier n)后的任何事件后而生成的狀態,
每個barrier都帶有快照的ID,并且barrier之前的記錄都進入了該快照, barriers不會中斷流處理,非常輕量級, 來自不同快照的多個barrier可以同時在流中出現,即多個快照可能并發地發生,
單流的barrier
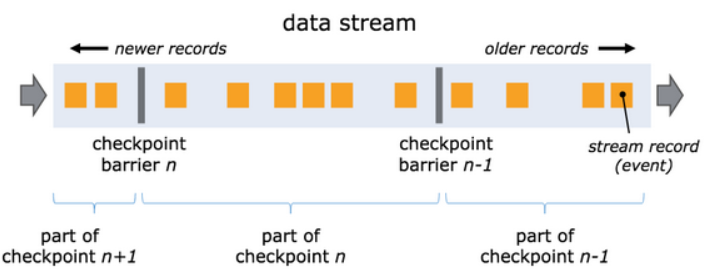
barrier在資料流源處被注入并行資料流中,快照n的barriers被插入的位置(sn)是快照所包含的資料在資料源中最大位置,例如,在Kafka中,此位置將是磁區中最后一條記錄的偏移量, 將該位置Sn報告給checkpoint協調器(Flink的JobManager),
??然后barriers向下游流動,當一個中間操作算子從其所有輸入流中收到快照n的barriers時,它會為快照n發出barriers進入其所有輸出流中, 一旦sink操作算子(流式DAG的末端)從其所有輸入流接收到barriers n,它就向checkpoint協調器確認快照n完成,在所有sink確認快照后,意味著快照著已完成,一旦完成快照n,job將永遠不再向資料源請求sn之前的記錄,因為此時這些記錄(及其后續記錄)將已經通過整個資料流拓撲,也即是已經被處理結束,
當 job graph 中的每個 operator 接收到 barriers 時,它就會記錄下其狀態,擁有兩個輸入流的 Operators(例如 CoProcessFunction)會執行 barrier 對齊(barrier alignment) 以便當前快照能夠包含消費兩個輸入流 barrier 之前(但不超過)的所有 events 而產生的狀態,
Flink 的 state backends 利用寫時復制(copy-on-write)機制允許當異步生成舊版本的狀態快照時,能夠不受影響地繼續流處理,只有當快照被持久保存后,這些舊版本的狀態才會被當做垃圾回收,
多流的barrier:
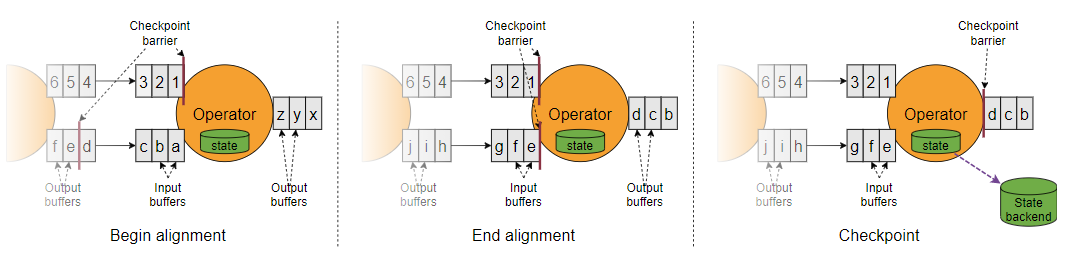
接收多個輸入流的運算子需要基于快照barriers上對齊(align)輸入流, 上圖說明了這一點:
- 一旦操作算子從一個輸入流接收到快照barriers n,它就不能處理來自該流的任何記錄,直到它從其他輸入接收到barriers n為止, 否則,它會搞混屬于快照n的記錄和屬于快照n + 1的記錄,
- barriers n所屬的流暫時會被擱置, 從這些流接收的記錄不會被處理,而是放入輸入緩沖區,可以看到1,2,3會一直放在Input buffer,直到另一個輸入流的快照到達Operator,
- 一旦從最后一個流接收到barriers n,操作算子就會發出所有掛起的向后傳送的記錄,然后自己發出快照n的barriers,
- 之后,它恢復處理來自所有輸入流的記錄,在處理來自流的記錄之前優先處理來自輸入緩沖區的記錄,
3、state
(3.1)state一般指一個具體的task/operator的狀態,Flink中包含兩種基礎的狀態:Keyed State和Operator State,
??Keyed State,就是基于KeyedStream上的狀態,這個狀態是跟特定的key系結的,對KeyedStream流上的每一個key,可能都對應一個state,
??Operator State與Keyed State不同,Operator State跟一個特定operator的一個并發實體系結,整個operator只對應一個state,相比較而言,在一個operator上,可能會有很多個key,從而對應多個keyed state,eg:Flink中的Kafka Connector,就使用了operator state,它會在每個connector實體中,保存該實體中消費topic的所有(partition, offset)映射,
?? Keyed State和Operator State,可以以兩種形式存在:原始狀態和托管狀態(Raw and Managed State),托管狀態是由Flink框架管理的狀態,如ValueState, ListState, MapState等,而raw state即原始狀態,由用戶自行管理狀態具體的資料結構,框架在做checkpoint的時候,使用byte[]來讀寫狀態內容,通常在DataStream上的狀態推薦使用托管的狀態,當實作一個用戶自定義的operator時,會使用到原始狀態,
? (3.2)State-Keyed State
基于key/value的狀態介面,這些狀態只能用于keyedStream之上,keyedStream上的operator操作可以包含window或者map等算子操作,這個狀態是跟特定的key系結的,對KeyedStream流上的每一個key,都對應一個state,
??key/value下可用的狀態介面:
ValueState: 狀態保存的是一個值,可以通過update()來更新,value()獲取,
ListState: 狀態保存的是一個串列,通過add()添加資料,通過get()方法回傳一個Iterable來遍歷狀態值,
ReducingState: 這種狀態通過用戶傳入的reduceFunction,每次呼叫add方法添加值的時候,會呼叫reduceFunction,最后合并到一個單一的狀態值,
MapState:即狀態值為一個map,用戶通過put或putAll方法添加元素,
(3.3)state backend
由 Flink 管理的 keyed state 是一種分片的鍵/值存盤,每個 keyed state 的作業副本都保存在負責該鍵的 taskmanager 本地中,另外,Operator state 也保存在機器節點本地,Flink 定期獲取所有狀態的快照,并將這些快照復制到持久化的位置,例如分布式檔案系統,
如果發生故障,Flink 可以恢復應用程式的完整狀態并繼續處理,就如同沒有出現過例外,
Flink 管理的狀態存盤在 state backend 中,Flink 有兩種 state backend 的實作 – 一種基于 RocksDB 內嵌 key/value 存盤將其作業狀態保存在磁盤上的,另一種基于堆的 state backend,將其作業狀態保存在 Java 的堆記憶體中,這種基于堆的 state backend 有兩種型別:FsStateBackend,將其狀態快照持久化到分布式檔案系統;MemoryStateBackend,它使用 JobManager 的堆保存狀態快照,
| 名稱 | Working State | 狀態備份 | 快照 |
|---|---|---|---|
| RocksDBStateBackend | 本地磁盤(tmp dir) | 分布式檔案系統 | 全量 / 增量 |
|
|||
| FsStateBackend | JVM Heap | 分布式檔案系統 | 全量 |
|
|||
| MemoryStateBackend | JVM Heap | JobManager JVM Heap | 全量 |
|
|||
當使用基于堆的 state backend 保存狀態時,訪問和更新涉及在堆上讀寫物件,但是對于保存在 RocksDBStateBackend 中的物件,訪問和更新涉及序列化和反序列化,所以會有更大的開銷,但 RocksDB 的狀態量僅受本地磁盤大小的限制,還要注意,只有 RocksDBStateBackend 能夠進行增量快照,這對于具有大量變化緩慢狀態的應用程式來說是大有裨益的,
所有這些 state backends 都能夠異步執行快照,這意味著它們可以在不妨礙正在進行的流處理的情況下執行快照,
4、CheckPoint引數說明及調優
Checkpoint 屬性包括:
-
精確一次(exactly-once)對比至少一次(exactly-once):可以選擇向
enableCheckpointing(long interval, CheckpointingMode mode)方法中傳入一個模式, 對于大多數應用來說,exactly-once是較好的選擇,exactly-once可能與某些延遲超低(始終只有幾毫秒)的應用的關聯較大, -
checkpoint 超時:如果 checkpoint 執行的時間超過了該配置的閾值,還在進行中的 checkpoint 操作就會被拋棄,
-
checkpoints 之間的最小時間:該屬性定義在 checkpoint 之間需要多久的時間,以確保流應用在 checkpoint 之間有足夠的進展,如果值設定為了 5000, 無論 checkpoint 持續時間與間隔是多久,在前一個 checkpoint 完成時的至少五秒后會才開始下一個 checkpoint,
往往使用“checkpoints 之間的最小時間”來配置應用會比 checkpoint 間隔容易很多,因為“checkpoints 之間的最小時間”在 checkpoint 的執行時間超過平均值時不會受到影響(例如如果目標的存盤系統忽然變得很慢),
注意這個值也意味著并發 checkpoint 的數目是一,
-
并發 checkpoint 的數目: 默認情況下,在上一個 checkpoint 未完成(失敗或者成功)的情況下,系統不會觸發另一個 checkpoint,確保了拓撲不會在 checkpoint 上花費太多時間,從而影響正常的處理流程, 不過允許多個 checkpoint 并行進行是可行的,對于有確定的處理延遲(例如某方法所呼叫比較耗時的外部服務),但是仍然想進行頻繁的 checkpoint 去最小化故障后重跑的 pipelines 來說,是有意義的,
注:該選項不能和 “checkpoints 間的最小時間”同時使用,
-
externalized checkpoints: 配置周期存盤 checkpoint 到外部系統中,Externalized checkpoints 將他們的元資料寫到持久化存盤上并且在 job 失敗的時候不會被自動洗掉, 這種方式下,如果 job 失敗,將會有一個現有的 checkpoint 去恢復,
上面呼叫enableExternalizedCheckpoints設定為ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION,表示一旦Flink處理程式被cancel后,會保留Checkpoint資料,以便根據實際需要恢復到指定的Checkpoint處理,
??ExternalizedCheckpointCleanup 可選項如下:
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION: 取消作業時保留檢查點,請注意,在這種情況下,您必須在取消后手動清理檢查點狀態,ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 取消作業時洗掉檢查點,只有在作業失敗時,檢查點狀態才可用,
-
在 checkpoint 出錯時使 task 失敗或者繼續進行 task:他決定了在 task checkpoint 的程序中發生錯誤時,是否使 task 也失敗,使失敗是默認的行為, 或者禁用它時,這個任務將會簡單的把 checkpoint 錯誤資訊報告給 checkpoint coordinator 并繼續運行,
-
優先從 checkpoint 恢復(prefer checkpoint for recovery):該屬性確定 job 是否在最新的 checkpoint 回退,即使有更近的 savepoint 可用,這可以減少恢復時間(checkpoint 恢復比 savepoint 恢復更快),
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 每 1000ms 開始一次 checkpoint env.enableCheckpointing(1000); // 高級選項: // 設定模式為精確一次 (這是默認值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 確認 checkpoints 之間的時間會進行 500 ms env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // Checkpoint 必須在一分鐘內完成,否則就會被拋棄 env.getCheckpointConfig().setCheckpointTimeout(60000); // 同一時間只允許一個 checkpoint 進行 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 開啟在 job 中止后仍然保留的 externalized checkpoints env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
默認情況下,如果設定了Checkpoint選項,則Flink只保留最近成功生成的1個Checkpoint,而當Flink程式失敗時,可以從最近的這個Checkpoint來進行恢復,如果希望保留多個Checkpoint,并能夠根據實際需要選擇其中一個進行恢復,這樣會更加靈活,比如,發現最近4個小時資料記錄處理有問題,希望將整個狀態還原到4小時之前,
Flink可以支持保留多個Checkpoint,需要在Flink的組態檔conf/flink-conf.yaml中,添加如下配置,指定最多需要保存Checkpoint的個數:
state.checkpoints.num-retained: 20
Flink checkpoint目錄分別對應的是 jobId,flink提供了在啟動之時通過設定 -引數指定checkpoint目錄, 讓新的jobId 讀取該checkpoint元檔案資訊和狀態資訊,從而達到指定時間節點啟動job,
5、Savepoint
Savepoint 是依據 Flink checkpointing 機制所創建的流作業執行狀態的一致鏡像, 你可以使用 Savepoint 進行 Flink 作業的停止與重啟、fork 或者更新, Savepoint 由兩部分組成:穩定存盤(列入 HDFS,S3,…) 上包含二進制檔案的目錄(通常很大),和元資料檔案(相對較小), 穩定存盤上的檔案表示作業執行狀態的資料鏡像, Savepoint 的元資料檔案以(絕對路徑)的形式包含(主要)指向作為 Savepoint 一部分的穩定存盤上的所有檔案的指標,
從概念上講, Flink 的 Savepoint 與 Checkpoint 的不同之處類似于傳統資料庫中的備份與恢復日志之間的差異, Checkpoint 的主要目的是為意外失敗的作業提供恢復機制, Checkpoint 的生命周期由 Flink 管理,即 Flink 創建,管理和洗掉 Checkpoint - 無需用戶互動, 作為一種恢復和定期觸發的方法,Checkpoint 實作有兩個設計目標:
i)輕量級創建
ii)盡可能快地恢復,
可能會利用某些特定的屬性來達到這個,例如, 作業代碼在執行嘗試之間不會改變, 在用戶終止作業后,通常會洗掉 Checkpoint(除非明確配置為保留的 Checkpoint),
與此相反、Savepoint 由用戶創建,擁有和洗掉, 他們的用例是計劃的,手動備份和恢復, 例如,升級 Flink 版本,調整用戶邏輯,改變并行度等, 當然,Savepoint 必須在作業停止后繼續存在, 從概念上講,Savepoint 的生成,恢復成本可能更高一些,Savepoint 更多地關注可移植性和對前面提到的作業更改的支持,
除去這些概念上的差異,Checkpoint 和 Savepoint 的當前實作基本上使用相同的代碼并生成相同的格式,然而,目前有一個例外,是使用 RocksDB 狀態后端的增量 Checkpoint,他們使用了一些 RocksDB 內部格式,而不是 Flink 的本機 Savepoint 格式,這使他們與 Savepoint 相比,是更輕量級的 Checkpoint 機制的一個實體,
(2)通過手動指定算子Id的方式,從 Savepoint 自動恢復算子
DataStream<String> stream = env. // Stateful source (e.g. Kafka) with ID .addSource(new StatefulSource()) .uid("source-id") // ID for the source operator .shuffle() // Stateful mapper with ID .map(new StatefulMapper()) .uid("mapper-id") // ID for the mapper // Stateless printing sink .print(); // Auto-generated ID
如果不手動指定 ID ,則會自動生成 ID ,只要這些 ID 不變,就可以從 Savepoint 自動恢復,生成的 ID 取決于程式的結構,并且對程式更改很敏感,因此,強烈建議手動分配這些 ID ,
6、Watermark(水位線)
(0)時間機制
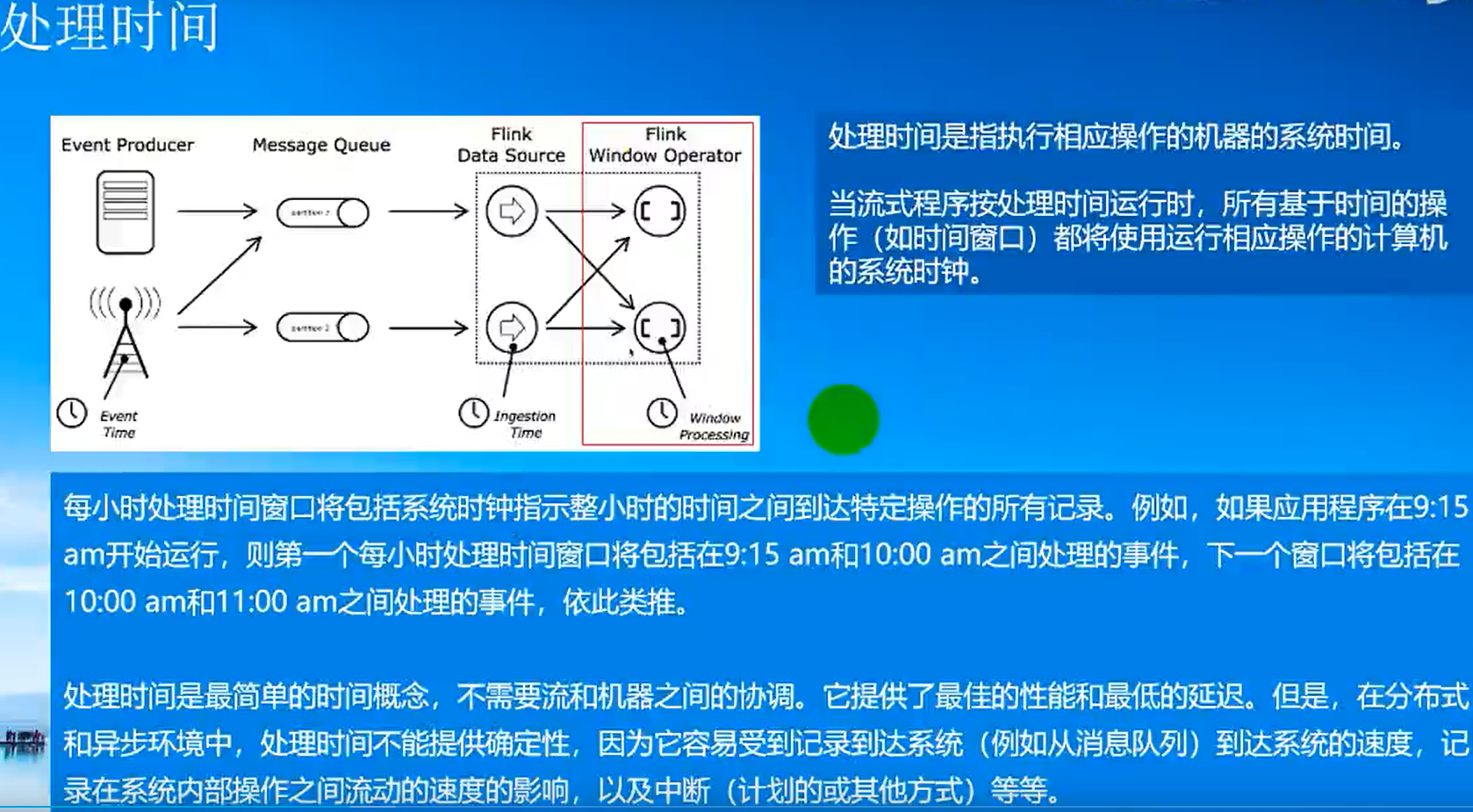
Event Time:事件產生的時間,它通常由事件中的時間戳描述;
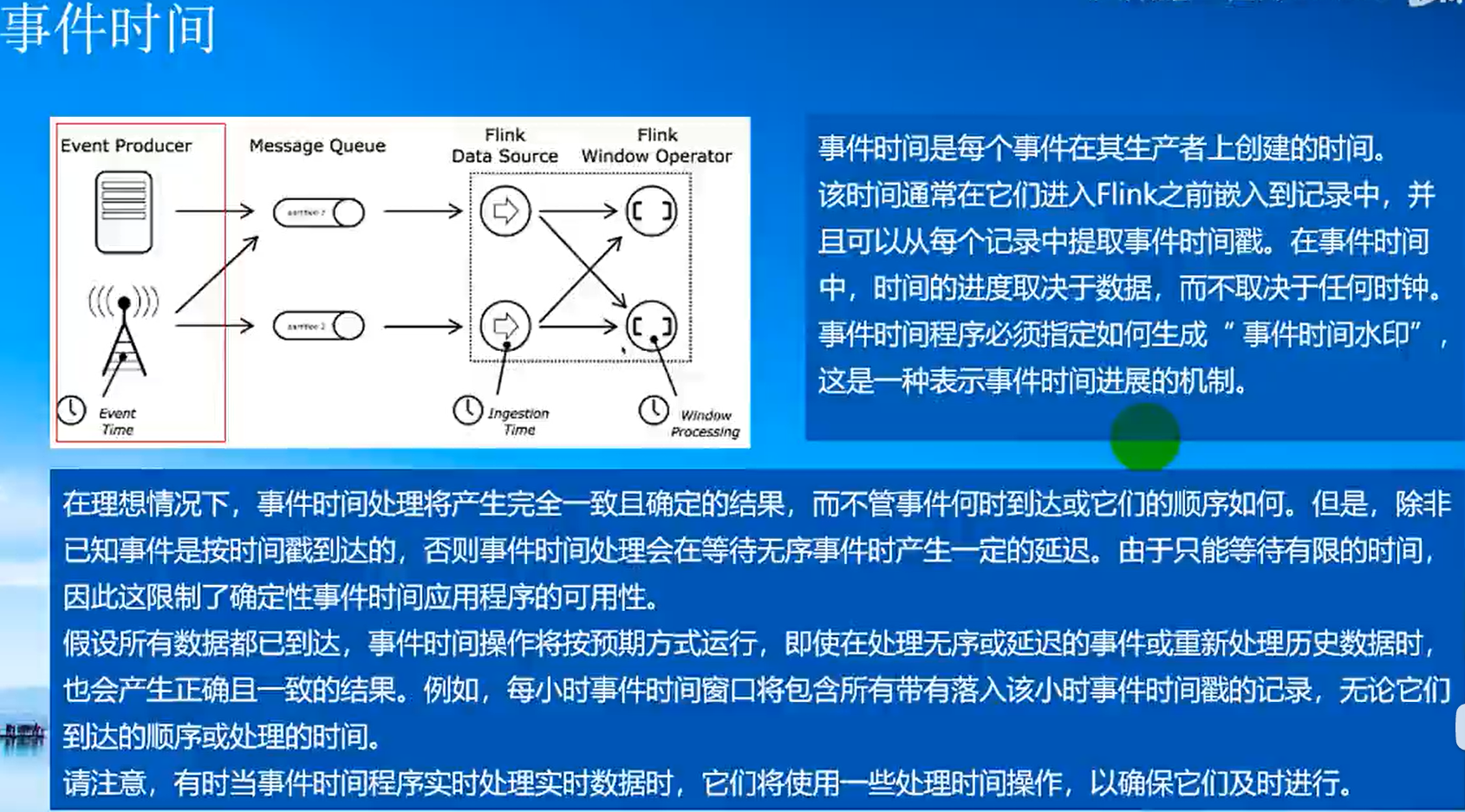
Ingestion Time:事件進入Flink的時間;
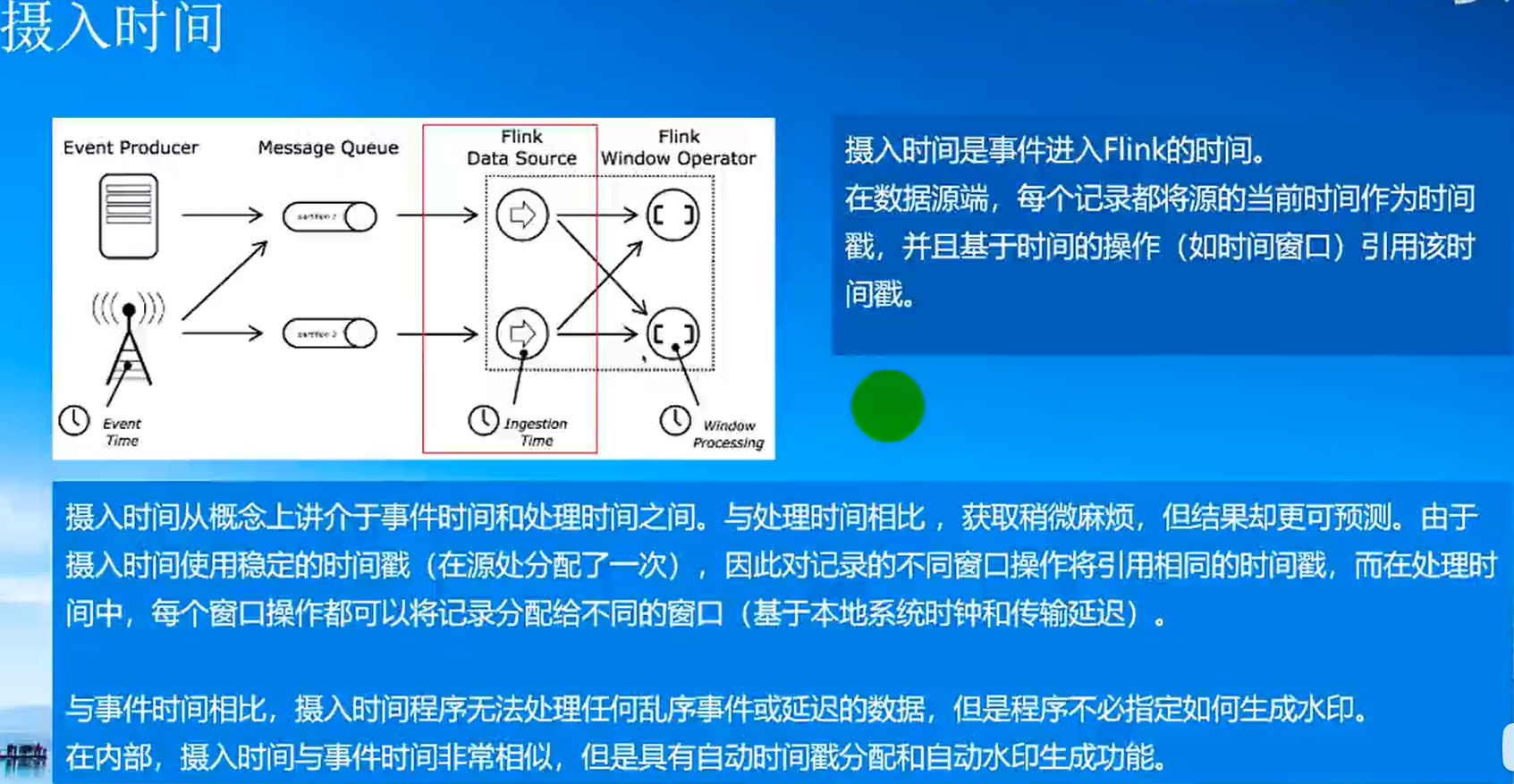
Processing Time:事件被處理時當前系統的時間;
(1)概述
在使用EventTime處理Stream資料的時候會遇到資料亂序的問題,流處理從Event(事件)產生,流經Source,再到Operator,這中間需要一定的時間,雖然大部分情況下,傳輸到Operator的資料都是按照事件產生的時間順序來的,但是也不排除由于網路延遲等原因而導致亂序的產生,特別是使用Kafka的時候,多個磁區之間的資料無法保證有序,因此,在進行Window計算的時候,不能無限期地等下去,必須要有個機制來保證在特定的時間后,必須觸發Window進行計算,這個特別的機制就是Watermark,Watermark是用于處理亂序事件的,
簡單來說 Watermark 是一個時間戳,表示已經收集完畢的資料的最大 event time,即 event time 小于 Watermark 的資料不應該再出現,基于這個前提我們才有可能將 event time 視窗視為完整并輸出結果,Watermark 設計的初衷是處理 event time 和 processing time 之間的延遲問題,
(2)原理
(2.1)waterMark有三種應用場景
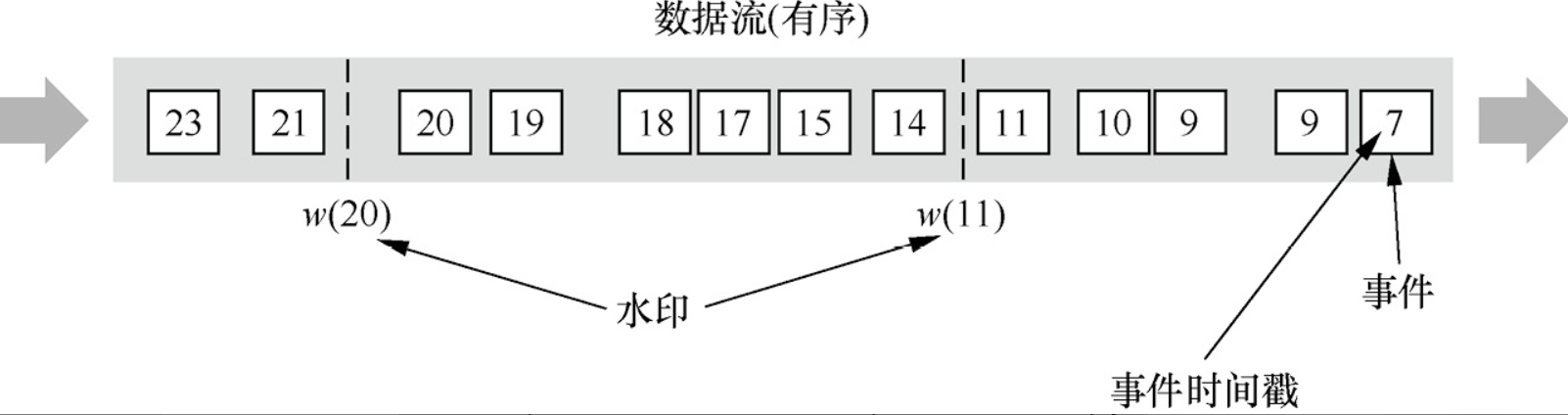
有序的Stream中的Watermark(理想情況下,window中的最大時間戳作為水位線watermark)
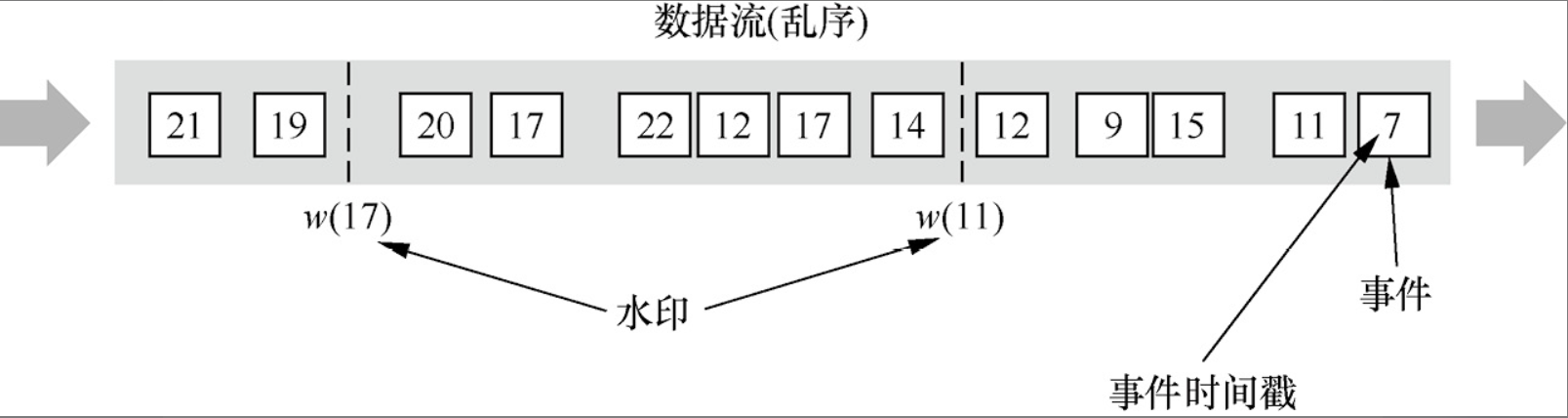
無序的Stream中的Watermark(亂序情況下,需要根據實際情況定義watermark的計算方法,當前window中排除掉早于watermark的資料和過于延遲的資料)
多并行度Stream中的Watermark
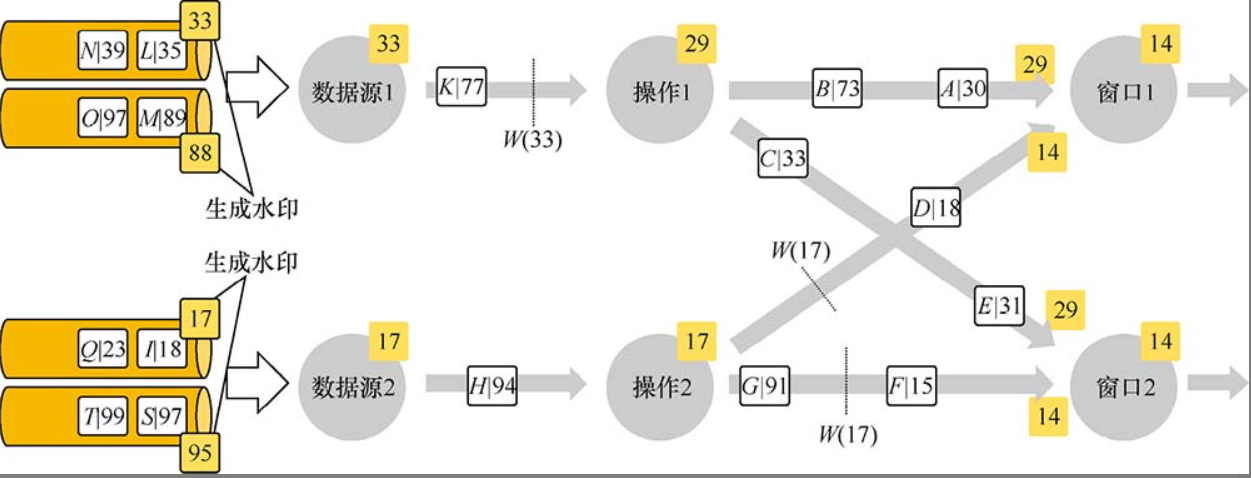
注意:在多并行度的情況下,Watermark會有一個對齊機制,這個對齊機制會取所有Channel中最小的Watermark,圖中的14和29這兩個Watermark的最終取值為14,
(2.2)Watermark 的產生方式
目前Apache Flink 有兩種生產 Watermark 的方式,如下:
-
標點水位線(Punctuated Watermark)- 資料流中每一個遞增的 EventTime 都會產生一個 Watermark(即每接收到一條資料,判斷事件時間,若大于上一次的時間戳,則更新水印為當前點的事件時間),
注意:在實際的生產中 Punctuated 方式在 TPS 很高的場景下會產生大量的 Watermark 在一定程度上對下游算子造成壓力,所以只有在實時性要求非常高的場景才會選擇 Punctuated 的方式進行 Watermark 的生成,
-
定期水位線(Periodic Watermark)- 周期性的(一定時間間隔或者達到一定的記錄條數)產生一個 Watermark,
注意:在實際的生產中 Periodic 的方式必須結合時間和積累條數兩個維度繼續周期性產生 Watermark,否則在極端情況下會有很大的延時,
所以 Watermark 的生成方式需要根據業務場景的不同進行不同的選擇,
(2.3)watermark和window處理亂序問題
1)水位線(WaterMark)是一個時間戳,等于當前到達的訊息最大時間戳減去配置的延遲時間,水位線是單調遞增的,如果有晚到達的早訊息并不會更新水位線,因為訊息最大時間戳沒變
水位線 = 當前收集到的訊息集的最大時間戳 - 配置的延遲時間;
新訊息到達時,會計算新的水位線,如果水位線大于等于視窗的endTime(左閉右開)則觸發視窗計算,反之繼續接收后續訊息;訊息的EventTime大于等于視窗beginTime則保留,反之被丟棄
水位線 >= 視窗的endTime,則關閉視窗,對當前收集到這批資料進行計算;
與window一起使用,可以對亂序到達的訊息排序后再處理;
2) 引入水位線機制的目的是根據實際需要,最大化保留有效資料的同時不因為部分資料的過分延遲而造成性能問題;
3)window關閉視窗,觸發計算的時間可通過代碼配置(即最后判斷是最后一條資料的時間上線),
總結:解決亂序問題,首先想到的是排序,但是對于一個無界資料資料流無法進行排序,由此引入視窗的概念,將有界資料流切分為一個個有界的視窗,在視窗內便于執行排序操作,flink的window機制通過將無界資料流劃分成有界資料流的方式,利用watermark機制排除掉過早到達,或者過于延遲的資料,對符合條件的window中的有界資料進行排序后執行其他操作,
備注:flink處理延遲事件
1). 重新激活已經關閉的視窗并重新計算以修正結果,
2.) 將遲到事件收集起來處理(收集在側流中),
3.) 將遲到事件視為錯誤訊息并丟棄,
flink官方檔案watermark部分鏈接 https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/event_timestamps_watermarks.html
7、flink高可用
默認情況下,每個Flink集群只有一個JobManager,如果這個JobManager掛了,則不能提交新的任務,并且運行中的程式也會失敗,從而導致單點故障,使用JobManager HA,集群可以從JobManager故障中恢復,從而避免單點故障,用戶可以在Standalone或Flink on Yarn集群模式下配置Flink集群HA(高可用性),
Standalone模式下,JobManager的高可用性的基本思想是,任何時候都有一個MasterJobManager和多個Standby JobManager,Standby JobManager可以在Master JobManager掛掉的情況下接管集群成為Master JobManager,這樣避免了單點故障,一旦某一個StandbyJobManager接管集群,程式就可以繼續運行,Standby JobManagers和Master JobManager實體之間沒有明確區別,每個JobManager都可以成為Master或Standby,(Flink on Yarn的高可用性其實主要利用YARN的任務恢復機制實作),
(2)集群規劃
使用5臺機器實作,其中3臺Master節點(JobManager)和2臺Slave節點(TaskManager),實作HA還需要依賴ZooKeeper和HDFS,因此要有一個ZooKeeper集群和Hadoop集群,ZooKeeper和JobManager部署在相同的機器上(由于本地虛擬機個數有限,因此需要共用機器,生產環境中Zookeeper考慮單獨部署在獨立的服務器上),Hadoop集群也和JobManager部署在相同的機器上,集群節點行程資訊如圖所示,
JobManager節點:hadoop100、hadoop101、hadoop102(一主兩從,通過zookeeper實作分布式協調服務);
TaskManager節點:hadoop103、hadoop104;
ZooKeeper節點:hadoop100、hadoop101、hadoop102;
Hadoop節點:hadoop100、hadoop101、hadoop102;
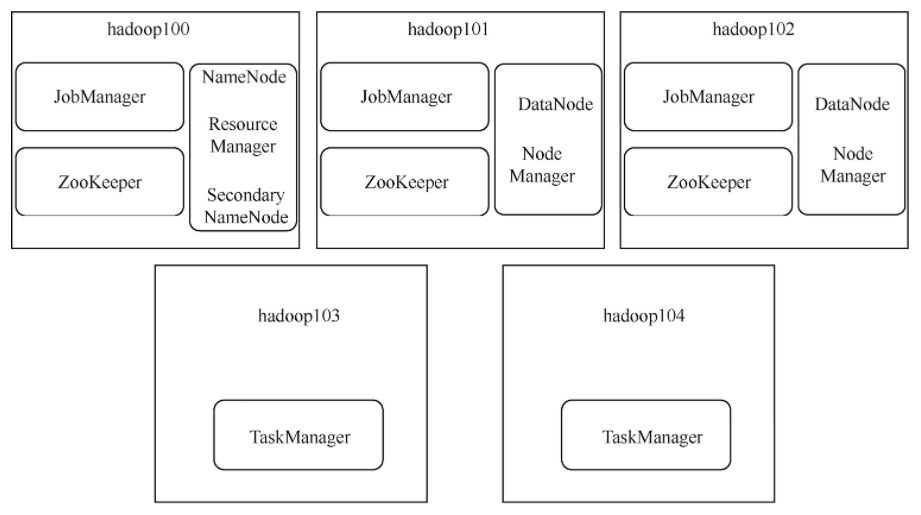
集群節點行程資訊
JobManager:Flink主節點的行程名稱,
TaskManager:Flink從節點的行程名稱,
NameNode:Hadoop中HDFS的主節點行程名稱,
DataNode:Hadoop中HDFS的從節點行程名稱,
SecondaryNameNode:Hadoop中HDFS的輔助節點名稱,
ResourceManager:Hadoop中YARN的主節點行程名稱,
NodeManager:Hadoop中YARN的從節點行程名稱,
ZooKeeper:代表ZooKeeper服務的行程,
flink官方檔案:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/concepts/index.html
借鑒了不少文章,感謝各路大神分享,如需轉載請注明出處,謝謝:https://www.cnblogs.com/huyangshu-fs/p/15062396.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/308472.html
標籤:大數據
上一篇:配置Jetty10/11請求日志
下一篇:Linux基礎——虛擬機的克隆