這里介紹的幾種常用基于密度聚類演算法包括:DBSCAN、OPTICS、DENCLUE,
1. DBSCAN
DBSCAN (Density Based Spatial Clustering of Application with Noise)[1] 演算法的核心思想是,對于一個簇(cluster)內的點,要求在給定半徑 ε 的鄰域包含的點數——也稱為基數(cardinality)——必須不小于一個最小值MInPts,這些滿足要求點成為“核心點”(core points),所以這里一個點的密度就是以其關于 ε 和 MInPts 的基數來代表的,而為了讓每個簇中的那些“邊緣點”(border points)——不滿足最小值要求但在核心點的鄰域范圍內的點——不被忽略掉,演算法遞進地給出了"密度直達"(directly density-reachable)、“密度可達”(density-reachable)、“密度相連”(density-connected)的概念,所有彼此之間關于給定引數 ε 和 MInPts 密度相連的資料點組成一個簇,沒有包含在任何一個簇內的點就屬于噪聲(noise),其實在具體實作時時不必在意所謂“密度相連”的概念的,只需要迭代地將“核心點”鄰域中的所有點——即密度直達的點——包含進來即可,這樣最終形成的簇其內的所有點必定是密度相連的,
對于DBSCAN中的兩個全域引數 ε 和 MInPts,可以通過一個引數 K 來啟發式地得到它們,資料集中一個點的第 K 鄰近點與它的距離稱為 k_dist,當我們畫出所有點排序后的 k_dist 圖之后,可以確定一個”界限“(threshold),在界限之下的所有點就是核心點,界限值就是所需的 ε 值,K 值就是 MInPts 值,界限一般在 k_dist 突然變化的地方,或者根據先驗知識確定(事先知道資料集中噪聲的比例),

Tips
使用統計的方法,通過統計 k_dist 變化率 Δk_dist 可以形成一種自動找出 k_dist 突變處的方法,
2. OPTICS
OPTICS (Ordering Points To Identify the Clustering Structure)[2] 不直接提供資料集的聚類結果,而是產生一個關于資料集的“増廣排序”(augmented ordering),它反映了資料基于密度的聚類結構,原文中介紹說道OPTICS的作業原理就像是一種擴展的DBSCAN演算法,在演算法程序中會考慮在“生成距離”(generating distance) ε 之下的任何距離引數 ε_i,但這個程序不會生成點的所屬簇,而是保存物件的處理順序和重要資訊,重要的資訊包括兩個:核心距離(core-distance)和可達距離(reachability-distance),核心距離 core_distance_{ε,MinPts}(p) 就是,資料點 p 在給定的生成距離 ε 范圍與一個臨近點的距離,且是能讓 p 成為核心點的最短距離 ε'(若 ε' 超過了 ε,p 不能稱為核心點,那么 p 的核心距離就失去意義),可達距離ReachDist_ε_MinPts(p,o) 是關于核心點來說的,資料點 p 在 ε 范圍內與某一核心點 o 之間的距離,且它不能小于 o 的核心距離(若點 p 的 ε 范圍沒有核心點,則它不存在關于任何點的可達距離),
在生成了資料集相對于 ε 和 MInPts 的增廣聚類排序之后,我們可以從中提取關于 ε'<ε 和 MInPts 的任何基于密度的聚類結果,只需要根據核心距離和可達距離通過簡單的“掃描”得到的排序序列來標記資料點的所屬簇即可,

Tips
生成增廣的聚類排序會保存兩種資訊——核心距離和可達距離,但對于從中提取類似 DBSCAN 的結果而言,通過對提取程式的一些調整,我們只需要可達距離這一種資訊即可實作目的,
3. DENCLUE
DENCLUE (DENsity based CLUstEring)[3] 引入影響函式和密度函式(influence and density function)的概念用以進行基于密度的聚類,空間中的任一點密度是所有資料點在此點產生影響的疊加,一般采用高斯影響函式進行計算,這里需要給定演算法的第一個引數 σ,一般稱為平滑引數(smoothing parameter),演算法又定義了密度吸引點(density attractor)的概念用以進行聚類操作,密度吸引點就是密度函式中的那些區域最大值點,在演算法中可以通過梯度爬山法(climb hill)來得到它們的近似位置,這里需要給定演算法的第二個引數,步進長度 δ,也稱為收斂速率(controlling convergence speed),由這些吸引點可以給出從“中心限定簇”(center-defined cluster)到“任意形狀簇”(arbitrary-shape cluster)的定義,中心限定簇針對每個吸引中心而言,指的是某吸引中心 x* 的密度大于給定的密度閾值 ξ,那么由 x* 所吸引的所有資料點構成一個中心限定簇,任意形狀簇在前者的基礎上延伸得到,只要兩個吸引 x1* 、x2* 中心之間存在一條路徑,該路徑上的密度也大于 ξ,那么由x1* 、x2* 所定義的中心限定簇合并在同一簇內,這樣構成的簇就可以任意形狀的,這里的閾值 ξ 就是演算法需要的第三個引數,也稱為噪聲閾值(noise threshold),
演算法實作程序中需要一些處理技巧,首先是計算密度函式,顯然全域密度函式的計算量隨著資料量的增加是巨大的(O(n^2)),所以我們可以根據高斯函式的 3σ 原則來計算區域密度函式值(local density function),即資料空間中某點的區域密度等于它的 3σ 范圍內資料點的影響疊加,然后為了提高搜索效率,我們可以對資料空間分塊并建立索引,如B+樹、R樹等,
在缺少先驗知識的情況下,設定演算法的三個引數(σ/δ/ξ)是一件困難的事情,而且三個引數之間是互相牽制的,這無疑增大的引數調整的復雜度,另一個問題在于資料過濾操作,這一操作是DENCLUE演算法中多出的一步操作,由于密度閾值 ξ 只針對密度吸引點,那么在原始資料集上的產生的聚類中不能避免地會包含噪聲,這回造成聚類結果噪聲率較低的假象,所以需要對資料提前過濾,去除明顯的噪聲資料,過濾實在資料分塊的基礎上進行的,設定一個過濾閾值 ξ_c ,視分塊中資料量小于 ξ_c 的資料點為噪聲,過濾即讓該資料分塊為空,之后使用過濾后的資料進行聚類,這里的ξ_c原文里的建議值是 ξ/2/ndims , ndims 為資料維度,但是在實驗中發現該建議值并不一定合適,實際上這里又產生了一個引數,需要我們針對資料集的特點進行設定,
DENCLUE在t7_10k.dat上的聚類結果如下,

有過濾操作

無有過濾操作
DENCLUE2.0 改進的地方在爬山法的方式,它不在采用原始的定步長爬山,而是給出了一種自適應的變步長爬山方式,可以更快的接近吸引點即山頂的位置,并且在理論可以上無限接近吸引點,正因為其會無限度地接近吸引點,所以我們需要給定其停止的條件,直白地說就是,當爬上程序中密度上升不十分明顯時,可以停止繼續爬山,運算式為 (f(x)l-f(x){l-1})/f(x)_l<=γ, γ 不需給太小,這樣反而會讓迭代步驟增加,加大計算量,同時也使爬山終點太過集中于各吸引點附近,不利于簇的合并,容易形成更多分離的簇,本次試驗中的引數為 h=0.01985, γ=0.01, ξ=38, ξ_c=6,無過濾操作對應 ξ_c=0,
DENCLUE2.0在t7_10k.dat上的聚類結果如下,
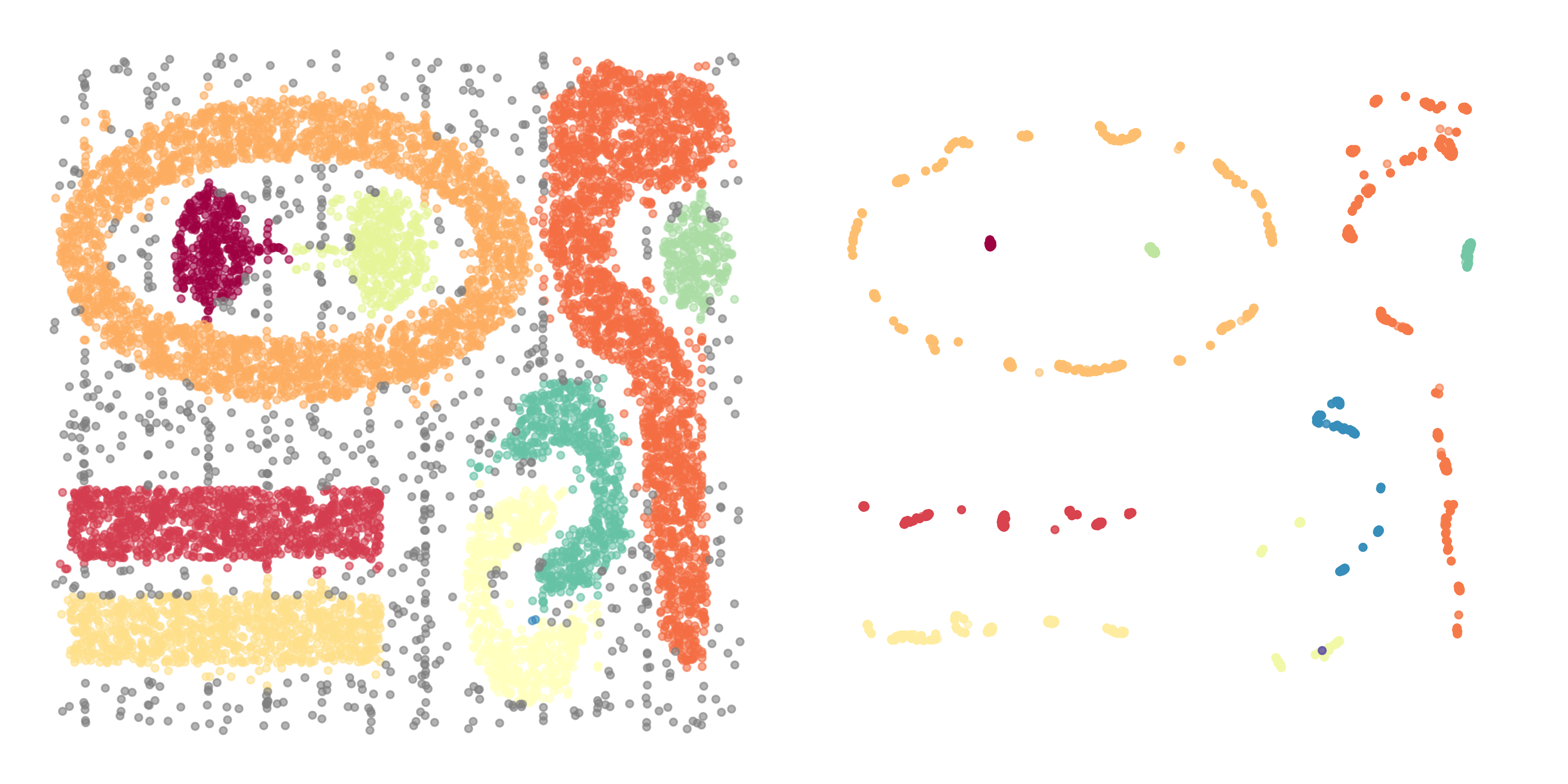
有過濾操作(聚類數=9,噪聲占比=7.410%)
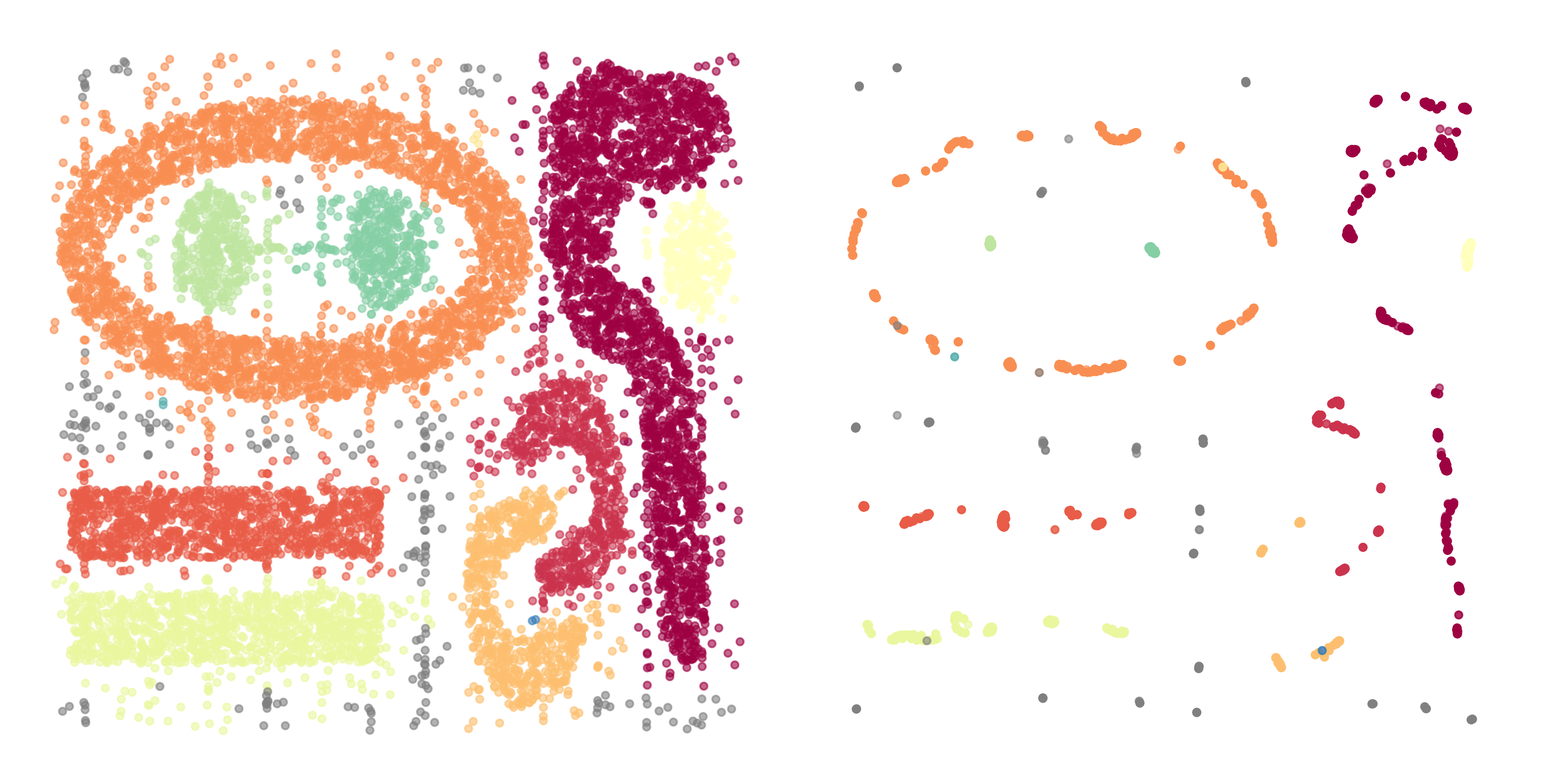
無有過濾操作(聚類數=12,噪聲占比=2.070%)
Tips
通過觀察DENLCUE2.0中爬山終點的聚集程序得到啟發,也許可以直接利用爬山終點提取聚類結果,由此節省許多時間與空間成本,
資料
實驗資料 7_10k.dat 為 Chameleon 論文[5]中所給的DS3資料,資料密度分布圖如下(h=0.01985):
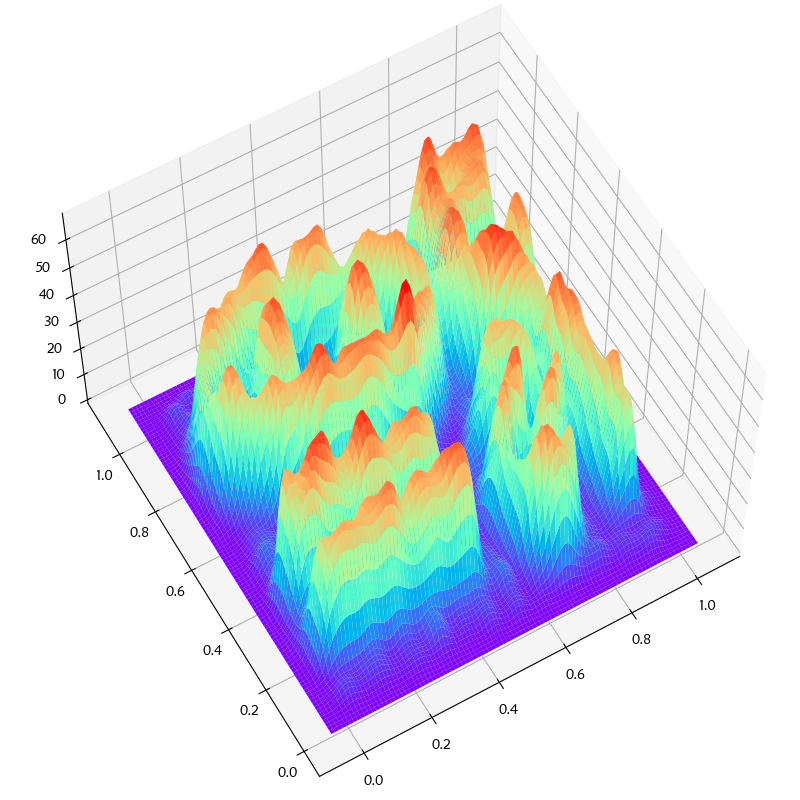
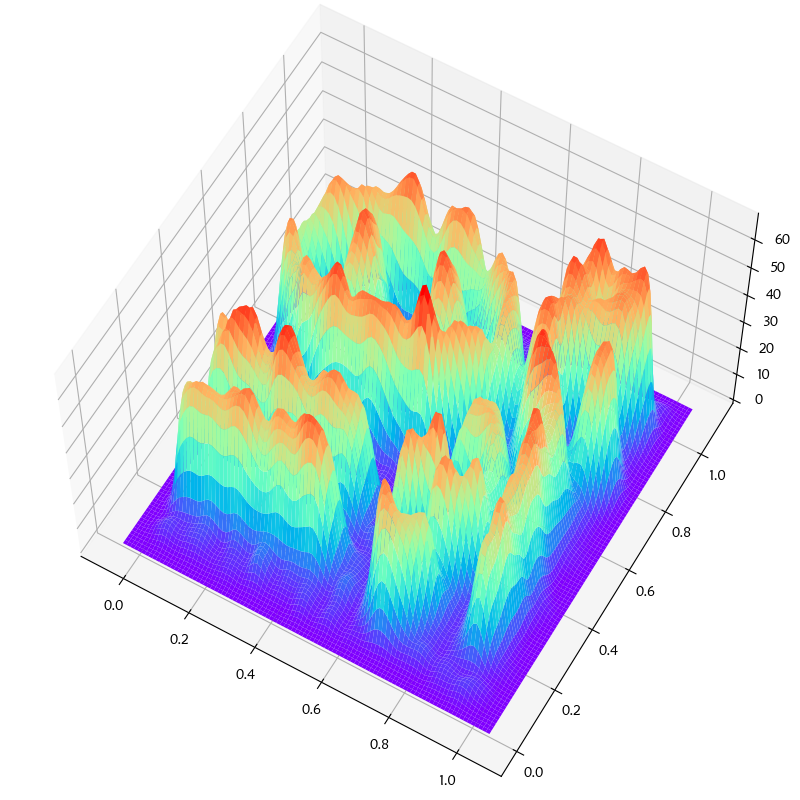
參考
-
Ester M, Kriegel H-P, Sander J, Xu X. A density based algorithm for discovering clusters in large spatial databases with noise[C]. Proceedings of the 2nd ACM In ternational Conference on Knowledge Discovery and Data Mining (KDD), 1996:226-231. https://dl.acm.org/doi/10.5555/3001460.3001507
-
Ankerst M, Breunig MM, Kriegel H-P, Sander J. OPTICS: ordering points to identify the clustering structure[C]. Proceedings of the ACM International Conference on Management of Data (SIGMOD), 1999:49–60. DOI:https://doi.org/10.1145/304181.304187
-
Hinneburg A, Keim DA. An efficient approach to clustering in large multimedia databases with noise[C]. Proceedings of the 4th ACM International Conference on Knowledge Discovery and Data Mining (KDD), 1998:58-65. https://dl.acm.org/doi/10.5555/3000292.3000302
-
Campello, RJGB, Kr?ger, P, Sander, J, Zimek, A. Density‐based clustering[J]. WIREs Data Mining Knowl Discov. 2020, 10(2):e1343. DOI:https://doi.org/10.1002/widm.1343
-
George Karypis, Eui-Hong (Sam) Han, and Vipin Kumar. 1999. Chameleon: Hierarchical Clustering Using Dynamic Modeling[J]. Computer, 1999, 32(8):68–75. DOI:https://doi.org/10.1109/2.781637
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/308475.html
標籤:大數據
上一篇:VMware workstation16 中Centos7下MySQL8.0安裝程序+Navicat遠程連接
下一篇:初識爬蟲