1.截至 4.0 版本,TiDB 與 MySQL 的區別總結
| 功能 | MySQL | TiDB |
| 隔離級別 | 支持讀未提交、讀已提交、可重復讀、串行化,【默認為可重復讀】 | 樂觀事務支持快照隔離,悲觀事務支持快照隔離和讀已提交 |
| 鎖機制 | 悲觀鎖 | 樂觀鎖、悲觀鎖 |
| 存盤程序 | 支持 | 不支持 |
| 觸發器 | 支持 | 不支持 |
| 事件 | 支持 | 不支持 |
| 自定義函式 | 支持 | 不支持 |
| 視窗函式 | 支持 | 部分支持 |
| JSON | 支持 | 不支持部分 MySQL 8.0 新增的函式 |
| 外鍵約束 | 支持 | 忽略外鍵約束 |
| 字符集 | 只支持 ascii、latin1、binary、utf8、utf8mb4 | |
| 增加/洗掉主鍵 | 支持 | 通過 alter-primary-key 配置開關提供 |
| CREATE TABLE tblName AS SELECT stmt | 支持 | 不支持 |
| CREATE TEMPORARY TABLE | 支持 | TiDB 忽略 TEMPORARY 關鍵字,按照普通表創建 |
| DML affected rows | 支持 | 不支持 |
| AutoRandom 列屬性 | 不支持 | 支持 |
| Sequence 序列生成器 | 不支持 | 支持 |
2.TiDB DDL操作
TiDB 集群中,用戶執行的 DDL 操作分兩類:普通 DDL 操作和加索引操作,
增加欄位
在執行 ADD COLUMN 型別 DDL 時,TIDB并沒有對資料進行回填,而是將最新添加的列的 default 值保存到 schema 的"原始默認值"欄位中,在讀取階段如果 TiKV 發現該列值為 null 并且"原始默認欄位"不為 null,則會使用"原始默認欄位"對該 null 列進行填充,并將填充后的結果從 TiKV 回傳,通過這種優化,該 DDL 操作不需要關心表中實際行數,可以更快的完成 DDL 變更,操作執行時間短,一般秒級就可以執行完成,
增加索引
加索引操作由于需要回填資料,因此執行時間略長,而在回填資料期間,需要將回填的資料寫入 TiKV,對 TiKV 會產生額外的寫入壓力,從而造成一些性能影響,
TiDB 提供了引數 tidb_ddl_reorg_worker_cnt 和 tidb_ddl_reorg_batch_size 用來控制回填資料的速度,通過調整引數,可以在業務訪問高峰到來時降低 DDL 速度,保證對業務的正常訪問無影響;而在業務訪問低峰增加 DDL 速度,從而更快的完成 DDL 任務,
3.Sequence
Sequence 是資料庫系統按照一定規則自增的數字序列,具有唯一和單調遞增的特性,可以實作并發應用需要獲取單調遞增的序列號;通過呼叫不同的Sequence ,在一張表里面需要有多個自增欄位;更新資料表中一列值為連續自增的值,
4.AutoRandom
AutoRandom 是 TiDB 4.0 提供的一種擴展語法,用于解決整數型別主鍵通過 AutoIncrement 屬性隱式分配 ID 時的寫熱點問題,使用 AUTO_RANDOM 功能前,須在 TiDB 組態檔 experimental 部分設定 allow-auto-random = true,
- 唯一性:TiDB 始終保持填充資料在表范圍內的唯一性,
- 高性能:TiDB 能夠以較高的吞吐分配資料,并保證資料的隨機分布以配合
PRE_SPLIT_REGION語法共同使用,避免大量寫入時的寫熱點問題, - 支持隱式分配和顯式寫入:類似列的 AutoIncrement 屬性,列的值既可以由 TiDB Server 自動分配,也可以由客戶端直接指定寫入,該需求來自于使用 Binlog 進行集群間同步時,保證上下游資料始終一致,
5. TiUP
在 TiDB 4.0 的生態系統里,TiUP 作為新的工具,承擔著包管理器的角色,管理著 TiDB 生態下眾多的組件(例如 TiDB、PD、TiKV),用戶想要運行 TiDB 生態中任何東西的時候,只需要執行 TiUP 一行命令即可,相比以前,極大地降低了管理難度,
6.資料訂閱復制同步工具 CDC
TiCDC(TiDB Change Data Capture)是用來識別、捕捉和輸出 TiDB/TiKV 集群上資料變更的工具系統,它既可以作為 TiDB 增量資料同步工具,將 TiDB 集群的增量資料同步至下游資料庫,也提供開放資料協議,支持把資料發布到第三方系統,相較于 TiDB Binlog,TiCDC 不依賴 TiDB 事務模型保證資料同步的一致性,系統可水平擴展且天然支持高可用,在 TiCDC 工具出現之前,資料同步功能是由 TiDB-Tools 工具中的 TiDB-Binlog 來實作的,TiDB-Binlog 通過收集各個 TiDB 實體產生的 binlog,并按照事務提交的時間排序后同步到下游,
7.資料匯入工具 Lightning
TiDB Lightning 是一個將全量資料高速匯入到 TiDB 集群的工具,速度可達到傳統執行 SQL 匯入方式的 3 倍以上、大約每小時 300 GB,Lightning 有以下兩個主要的使用場景:一是大量新資料的快速匯入、二是全量資料的備份恢復,目前,Lightning 支持 Mydumper 或 CSV 輸出格式的資料源,
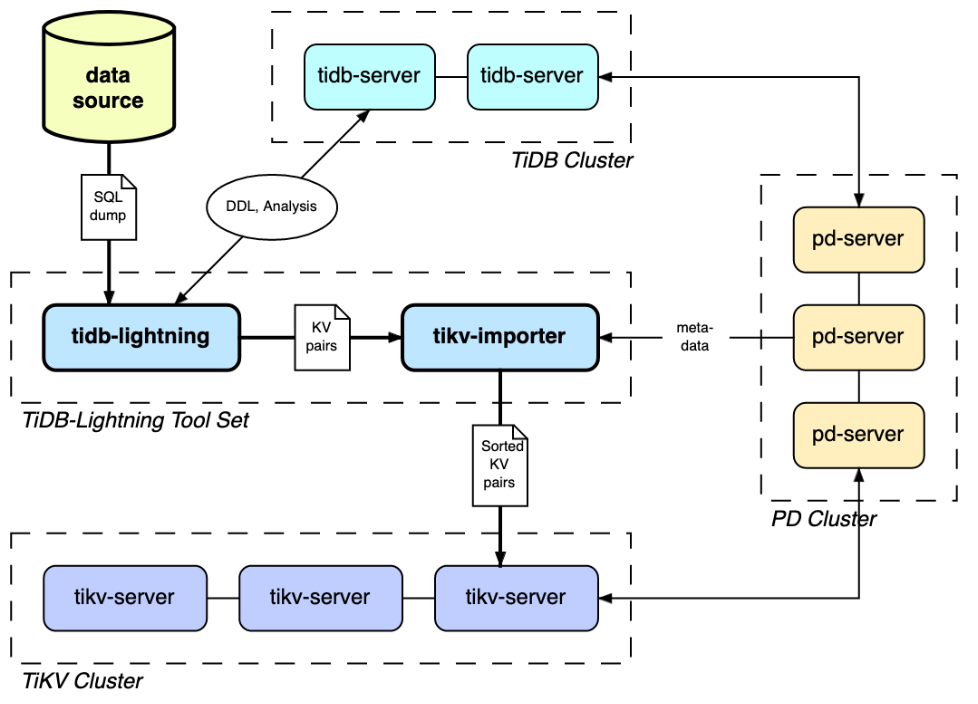
注意事項:一旦目標 TiKV 集群切換到匯入模式,整個資料匯入階段該集群將被 tidb-lightning 獨占,無法對外提供正常服務,資料匯入完成后,tidb-lightning 會自動把 TiKV 集群切換回“普通模式”,
8.備份恢復工具 BR
BR(https://github.com/pingcap/br) 是分布式備份恢復工具,分布式意味著可以通過 BR 可以驅動集群中所有 TiKV 節點進行備份恢復作業,相比起 SQL dump 形式,這種分布式備份恢復的效率會有極大的提升,
注意(1)增量的實作也是全表掃,同樣有性能問題,這個和傳統資料庫的增量不一樣;(2)恢復耗時要高于備份耗時,
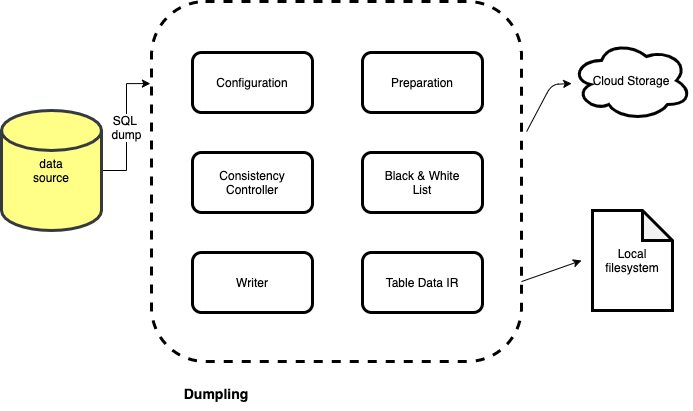
9.匯出工具Dumpling
Dumpling 將提供以下幾個特性:
- 完全采用 Golang,與 TiDB 生態集成度高
- 能夠提供 Mydumper 類似的功能,且支持并發高速匯出 MySQL 協議兼容資料庫資料
- 提供 SQL、CSV 等多種資料輸出格式,以便于快速匯出及匯入
- 支持直接匯出資料到云存盤系統,比如 S3
10.限制 SQL 記憶體使用和執行時間
限制SQL記憶體使用和執行時間主要是為限制消耗系統資源多的SQL,防止某條SQL造成OOM或影響到集群的整體性能,
類別 |
引數 |
說明 |
限制SQL記憶體使用 |
mem-quota-query |
單條 SQL 陳述句可以占用的最大記憶體閾值,【默認值32G】 |
| tidb_mem_quota_query | 設定一條查詢陳述句的記憶體使用閾值,【默認值32G】 | |
| tidb_mem_quota_hashjoin | 設定 HashJoin 算子的記憶體使用閾值,【默認值32G】 |
|
| tidb_mem_quota_mergejoin | 設定 MergeJoin 算子的記憶體使用閾值,【默認值32G】 |
|
| tidb_mem_quota_sort | 設定 Sort 算子的記憶體使用閾值,【默認值32G】 | |
| tidb_mem_quota_topn | 設定 TopN 算子的記憶體使用閾值,【默認值32G】 | |
| tidb_mem_quota_indexlookupreader | 設定 IndexLookupReader 算子的記憶體使用閾值,【默認值32G】 |
|
| tidb_mem_quota_indexlookupjoin | 設定 IndexLookupJoin 算子的記憶體使用閾值,【默認值32G】 |
|
| tidb_mem_quota_nestedloopapply | 設定 NestedLoopApply 算子的記憶體使用閾值,【默認值32G】 |
|
限制SQL執行時間 |
max_execution_time |
把查詢的執行時間限制在指定的 N 毫秒以內,超時后服務器會終止這條陳述句的執行, 【單位為:ms】 |
11.利用 GC 快照讀恢復資料
TiDB 事務的實作采用了 MVCC(多版本并發控制)機制,當更新/洗掉資料時,不會做真正的資料洗掉,只會添加一個新版本資料,并以時間戳來區分版本,當然歷史資料不會永久保留,超過一定時間的歷史資料將會被徹底洗掉,以減小空間占用,同時避免因歷史版本過多引起的性能開銷,
TiDB 使用周期性運行的 GC(Garbage Collection,垃圾回收)來進行清理,默認情況下每 10 分鐘一次,每次 GC 時,TiDB 會計算一個稱為 safe point 的時間戳(默認為上次運行 GC 的時間減去 10 分鐘),接下來 TiDB 會在保證在 safe point 之后的快照都能夠讀取到正確資料的前提下,洗掉更早的過期資料,
TiDB 的 GC 相關的配置存盤于 mysql.tidb 系統表中,可以通過 SQL 陳述句對這些引數進行查詢和更改,
讀取歷史版本資料前,需設定一個系統變數: tidb_snapshot ,這個變數是 Session 范圍有效級別,可以通過標準的 Set 陳述句修改其值,當這個變數被設定后,TiDB 會用這個時間戳建立 Snapshot(沒有開銷,只是創建資料結構),之后所有的查詢操作都會在這個 Snapshot 上讀取資料,當讀取歷史版本資料操作結束后,可以結束當前 Session 或者是通過 Set 陳述句將 tidb_snapshot 變數的值設為 “",即可讀取最新版本的資料,
12.利用 Recover/Flashback 命令秒恢復誤刪表
Recover
TiDB 在洗掉表時,實際上只洗掉了表的元資訊,并將需要洗掉的表資料范圍(行資料和索引資料)寫一條資料到 mysql.gc_delete_range 表,TiDB 后臺的 GC Worker 會定期從 mysql.gc_delete_range 表中取出超過 GC lifetime 相關范圍的 key 進行洗掉,所以,RECOVER TABLE 只需要在 GC Worker 還沒洗掉表資料前,恢復表的元資訊并洗掉 mysql.gc_delete_range 表中相應的行記錄就可以了,恢復表的元資訊可以用 TiDB 的快照讀實作,TiDB 中表的恢復是通過快照讀獲取表的元資訊后,再走一次類似于 CREATE TABLE 的建表流程,所以 RECOVER TABLE 實際上也是一種 DDL,
recover table 的一些使用限制:
- 只能用來恢復誤洗掉表的 DDL 操作,例如 truncate table,delete 操作沒有辦法恢復,
- 只能在 GC 回收資料之前完成,超過 GC 時間后會報錯無法成功恢復,
- 如果在使用 binlog 的情況下,上游執行 recover table 可能會出現一些非預期的結果,例如下游是 MySQL 資料庫,對于這個語法不兼容,上下游的 GC 策略配置不同,再加上復制延遲可能會引起下游的資料在 apply recover table 的時候已經被 GC 了從而導致陳述句執行失敗,
Flashback
Flashback 的原理和 Recover table 比較類似,不過是 recover 的升級版,在覆寫 recover 的所有功能之外,還可以支持 truncate table 的操作,未來也會逐漸取代 recover 命令,
參考學習
1.TiDB In Action: based on 4.0
https://book.tidb.io/
2.走進TiDB社區
https://www.bilibili.com/video/av242591239
3.TiDB 資料庫開發規范
https://asktug.com/t/topic/93819
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/308569.html
標籤:其它
上一篇:無法用Python找出元音的數量