本文來自 shopee 技術團隊
摘要
Shopee ClickHouse 是一款基于開源資料庫 ClickHouse 做二次開發、架構演進的高可用分布式分析型資料庫,本文將主要介紹 Shopee ClickHouse 的冷熱分離存盤架構和支持公司業務的實踐,
Shopee ClickHouse 的冷熱分離存盤架構使用 JuiceFS 客戶端 mount 遠端物件存盤到本地機器路徑,通過撰寫 ClickHouse 的存盤策略,如同使用多卷存盤一樣使用遠端物件存盤,因為我們用同一個 ClickHouse DB 集群支持多個團隊的業務,不同團隊甚至相同團隊的不同業務之間對資料的冷熱劃分基準可能都不同,所以在做冷熱分離時策略需要做到 ClickHouse 的表級別,
為了做到表級別的冷熱分離,我們依照提前編輯好的存盤策略,針對存量需要做冷熱隔離的業務表,修改表的存盤策略,對于新的需要做冷熱分離的業務表,建表時指明使用支持資料落在遠端存盤的存盤策略,再通過細化 TTL 運算式判斷資料應該落在本地還是遠端,
冷熱分離存盤架構上線后,我們遇到了一些問題和挑戰,比如:juicefs object request error、Redis 記憶體增長例外、suspicious broken parts 等,本文會針對其中一些問題,結合場景背景關系,并通過原始碼分析來給出解決方案,
總的來說 Shopee ClickHouse 冷熱存盤架構的整體設計思想是:本地 SSD 存盤查詢熱資料,遠端存盤查詢相對不那么頻繁的資料,從而節約存盤成本,支持更多的資料存盤需求,
1. Shopee ClickHouse 集群總架構
ClickHouse 是一款開源的列存 OLAP(在線分析查詢)型資料庫,實作了向量化執行引擎,具有優秀的 AP 查詢性能,Shopee ClickHouse 則是基于 ClickHouse 持續做二次迭代開發和產品架構演進的分析型資料庫,
下圖展示了 Shopee ClickHouse DB 集群的架構:
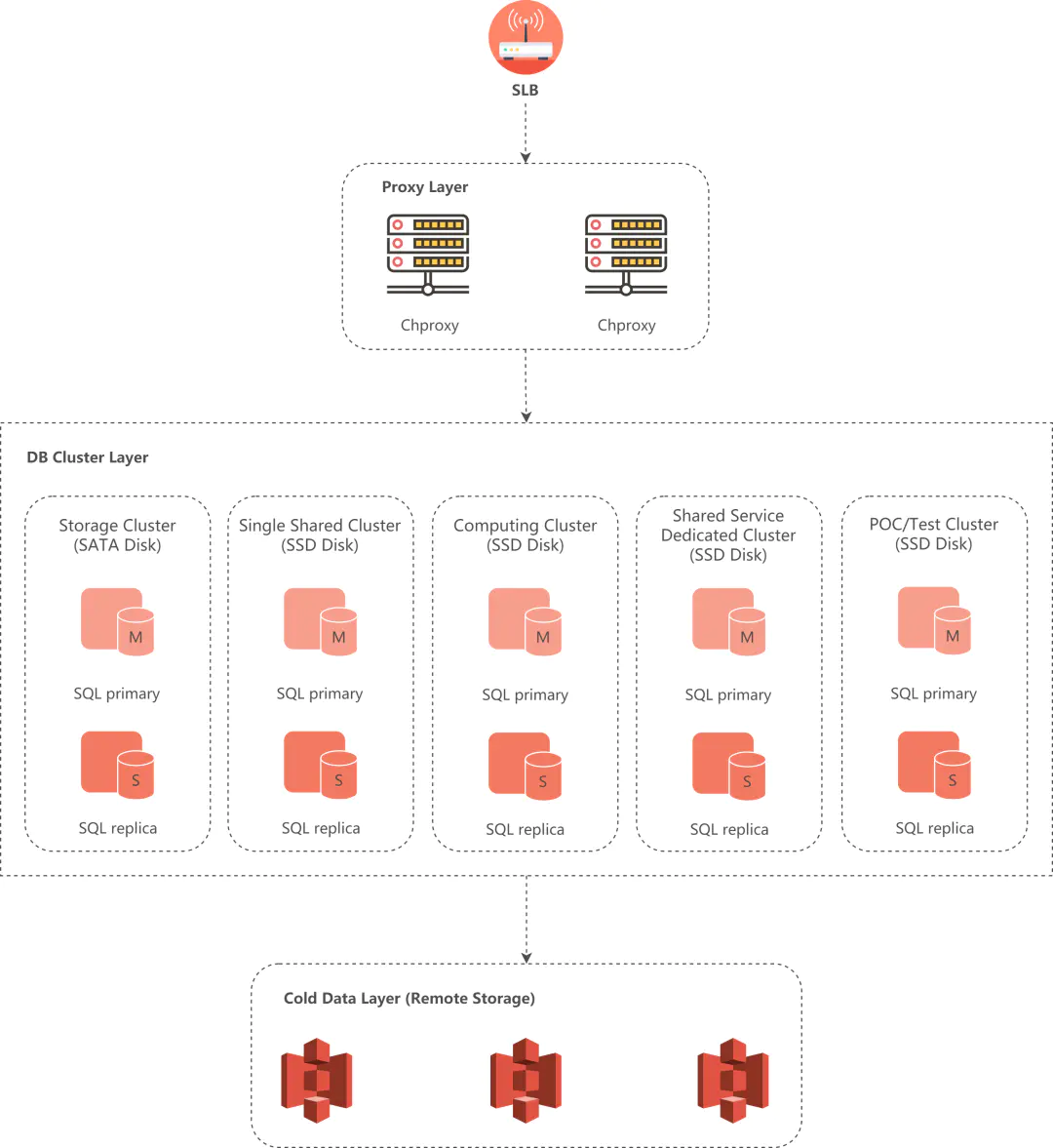
從上到下依次是用戶請求介入 SLB、Proxy 層、ClickHouse DB 集群層,最下方是遠端物件存盤,這里我們用的是 Shopee STO 團隊提供的 S3,
其中,SLB 提供用戶請求路由;Proxy 層提供了查詢路由,請求會根據用戶連接串中的集群名,路由到對應的集群中,也提供了部分寫入 balance 和查詢路由的能力;ClickHouse DB 集群層是由 Shopee ClickHouse 資料庫組成的分布式集群,目前有以 SSD 磁盤作為熱資料存盤介質的計算型分布式集群,和計算型單節點集群,還有以 SATA Disk 作為存盤介質的存盤型分布式集群;最下方的遠端存盤則用作冷資料存盤介質,
2. 冷熱分離存盤架構方案
用戶希望資料可以存盤得更多更久,查詢速度更快,但是通常資料存盤得越多,在相同查詢條件下,回傳延時就會越高,
從資源利用率上來說,我們希望存盤在 Shopee ClickHouse 上的資料可以被更多地訪問和利用,為業務提供更廣泛的支持,所以,起初我們要求業務方存盤到 Shopee ClickHouse 資料庫中的資料是用戶的業務熱資料,
但是這樣也帶來了一些問題,比如:用戶有時候需要查詢時間相對久一點的資料做分析,這樣就得把那部分不在 ClickHouse 的資料匯入后再做分析,分析結束后還要洗掉這部分資料,再比如:一些通過日志服務做聚合分析和檢索分析的業務,也需要相對久一點的日志服務資料來幫助監管和分析日常業務,
基于此類需求,我們一方面希望資源的最大化利用,一方面希望支持更多的資料存盤量,同時不影響用戶熱資料的查詢速度,所以使用冷熱資料分離的存盤架構就是一個很好的選擇,
通常,冷熱分離方案的設計需要考慮以下幾個問題:
- 如何存盤冷資料?
- 如何高效穩定簡單地使用冷存介質?
- 熱資料如何下沉到冷存介質?
- 架構的演進如何不影響現有的用戶業務?
而冷資料存盤介質的選擇一般通過以下幾個要點做對比分析:
- 成本
- 穩定性
- 功能齊全(資料在下沉程序中依然可以被正確查詢,資料庫的資料也可以被正確寫入)
- 性能
- 擴展性
2.1 冷存介質的選擇和 JuiceFS
可以用作冷存盤的介質一般有 S3、Ozone、HDFS、SATA Disk,其中,SATA Disk 受限于機器硬體,不易擴展,可以先淘汰,而 HDFS、Ozone 和 S3 都是比較好的冷存介質,
同時,為了高效簡單地使用冷存介質,我們把目光鎖定在了 JuiceFS 上,JuiceFS 是一種基于 Redis 和云物件存盤構建的開源 POSIX 檔案系統,可以使我們更加便捷和高效地訪問遠端物件存盤,
JuiceFS 使用公有云中已有的物件存盤,如 S3、GCS、OSS 等,用 JuiceFS 做存盤,資料實際上存盤在遠端,而 JuiceFS 重點關注這些存盤在遠端的資料檔案的元資料管理,JuiceFS 選擇 Redis 作為存盤元資料的引擎,這是因為 Redis 存盤都在記憶體中,可以滿足元資料讀寫的低延時和高 IOPS,支持樂觀事務,滿足檔案系統對元資料操作的原子性[1],
JuiceFS 提供了一種高效便捷的遠端存盤訪問方式,只需要通過 JuiceFS 的客戶端,使用 format 和 mount 命令,就可以將遠端存盤 mount 到本地路徑,我們 ClickHouse 資料庫訪問遠端存盤就可以如同訪問本地路徑一樣訪問,
選擇了 JuiceFS 后,我們再把目光轉回冷資料存盤介質的篩選,由于 JuiceFS 主要支持的后臺存盤層為物件存盤類別,余下的選項變成了 S3 和 Ozone,我們設計了一個如下的 benchmark , 使用 ClickHouse TPCH Star Schema Benchmark 1000s(benchmark 詳細資訊可以參照 ClickHouse 社區檔案[2])作為測驗資料,分別測驗 S3 和 Ozone 的 Insert 性能,并使用 Star Schema Benchmark 的 select 陳述句做查詢性能對比,
查詢的資料處于以下三種存盤狀態:
- 一部分在 Ozone/S3,一部分在本機 SSD 磁盤;
- 全部在 Ozone/S3;
- 全部在 SSD 上,
以下是我們的測驗抽樣結果:
(1)Insert 性能抽樣結果
Insert Lineorder 表資料到 Ozone:

Insert Lineorder 表資料到 S3:

可以看出,S3 的 Insert 性能稍微強勢一點,
(2)查詢性能抽樣結果
依照 ClickHouse Star Schema Benchmark,在匯入完畢 Customer、Lineorder、Part、Supplier 表后,需要根據四張表的資料創建一個打平的寬表,
CREATE TABLE lineorder_flat ENGINE = MergeTree PARTITION BY toYear(LO_ORDERDATE) ORDER BY (LO_ORDERDATE, LO_ORDERKEY) AS SELECT l.LO_ORDERKEY AS LO_ORDERKEY, l.LO_LINENUMBER AS LO_LINENUMBER, l.LO_CUSTKEY AS LO_CUSTKEY, l.LO_PARTKEY AS LO_PARTKEY, l.LO_SUPPKEY AS LO_SUPPKEY, l.LO_ORDERDATE AS LO_ORDERDATE, l.LO_ORDERPRIORITY AS LO_ORDERPRIORITY, l.LO_SHIPPRIORITY AS LO_SHIPPRIORITY, l.LO_QUANTITY AS LO_QUANTITY, l.LO_EXTENDEDPRICE AS LO_EXTENDEDPRICE, l.LO_ORDTOTALPRICE AS LO_ORDTOTALPRICE, l.LO_DISCOUNT AS LO_DISCOUNT, l.LO_REVENUE AS LO_REVENUE, l.LO_SUPPLYCOST AS LO_SUPPLYCOST, l.LO_TAX AS LO_TAX, l.LO_COMMITDATE AS LO_COMMITDATE, l.LO_SHIPMODE AS LO_SHIPMODE, c.C_NAME AS C_NAME, c.C_ADDRESS AS C_ADDRESS, c.C_CITY AS C_CITY, c.C_NATION AS C_NATION, c.C_REGION AS C_REGION, c.C_PHONE AS C_PHONE, c.C_MKTSEGMENT AS C_MKTSEGMENT, s.S_NAME AS S_NAME, s.S_ADDRESS AS S_ADDRESS, s.S_CITY AS S_CITY, s.S_NATION AS S_NATION, s.S_REGION AS S_REGION, s.S_PHONE AS S_PHONE, p.P_NAME AS P_NAME, p.P_MFGR AS P_MFGR, p.P_CATEGORY AS P_CATEGORY, p.P_BRAND AS P_BRAND, p.P_COLOR AS P_COLOR, p.P_TYPE AS P_TYPE, p.P_SIZE AS P_SIZE, p.P_CONTAINER AS P_CONTAINER FROM lineorder AS l INNER JOIN customer AS c ON c.C_CUSTKEY = l.LO_CUSTKEY INNER JOIN supplier AS s ON s.S_SUPPKEY = l.LO_SUPPKEY INNER JOIN part AS p ON p.P_PARTKEY = l.LO_PARTKEY
再執行這條 SQL 陳述句,當資料全部在 Ozone 上時,發生了如下 Error:
Code: 246. DB::Exception: Received from localhost:9000. DB::Exception: Bad size of marks file '/mnt/jfs/data/tpch1000s_juice/customer/all_19_24_1/C_CUSTKEY.mrk2': 0, must be: 18480
Select 資料一部分在 Ozone,并且此程序中發生了資料從 SSD 磁盤下沉到 Ozone 的情況,
結果:Hang 住,無法查詢,
做這個測驗時,我們使用的 Ozone 是社區版本 1.1.0-SNAPSHOT,此次測驗結果僅說明 Ozone 1.1.0-SNAPSHOT 不是很適合我們的使用場景,
由于 Ozone 1.1.0-SNAPSHOT 在我們的使用場景中有功能性的缺點,所以后續的 Star Schema Benchmark 的性能測驗報告重點放在 SSD 和 S3 的性能對比上(詳細 Query SQL 陳述句可以從 ClickHouse 社區檔案獲取),
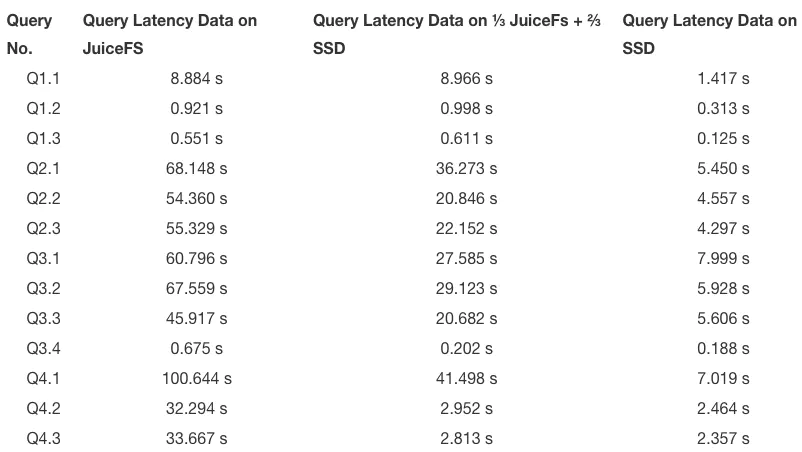
最終,在各個方面的對比下,我們選擇 S3 作為冷存介質,
因此,冷熱存盤分離的方案采用 JuiceFS+S3 實作,下文將簡述實作程序,
2.2 冷熱資料存盤分離的實作
首先,我們通過使用 JuiceFS 客戶端,mount S3 bucket 到本地存盤路徑 /mnt/jfs,然后編輯 ClickHouse 存盤策略配置../config.d/storage.xml 檔案,撰寫存盤策略組態檔時要注意,不要影響到歷史用戶存盤(即保留之前的存盤策略),在這里,default 就是我們的歷史存盤策略,hcs_ck 是冷熱分離的存盤策略,
詳細資訊可以參照下圖:
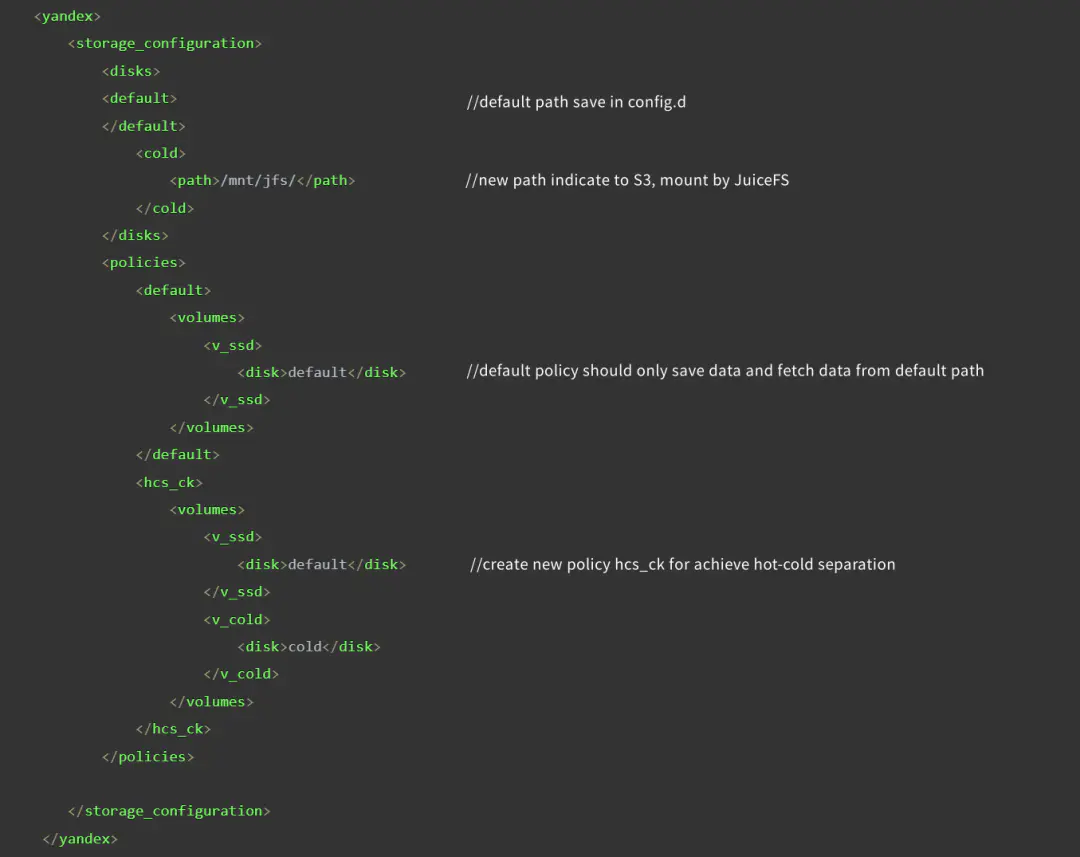
有需要冷熱分離存盤的業務,只需要在建表 Statement 里面寫明存盤策略為 hcs_ck,然后通過 TTL 的運算式來控制冷資料下沉策略,
下面通過一個例子說明使用方式和資料分離程序,表 hcs_table_name 是一個需要冷熱存盤分離的業務日志資料表,以下是建表陳述句:
CREATE TABLE db_name.hcs_table_name
(
.....
`log_time` DateTime64(3),
`log_level` String,
.....
`create_time` DateTime DEFAULT now()
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/db_name.hcs_table_name
', '{replica}')
PARTITION BY toYYYYMMDD(log_time)
ORDER BY (ugi, ip)
TTL toDateTime(log_time) TO VOLUME 'v_ssd',
toDateTime(log_time) + toIntervalDay(7) TO VOLUME 'v_cold',
toDateTime(log_time) + toIntervalDay(14)
SETTINGS index_granularity = 16384,
storage_policy = 'hcs_ck',
parts_to_throw_insert = 1600
通過上面的 TTL 運算式可以看到,hcs_table_name 這個表指明最近 7 天的資料存盤在本地 SSD 磁盤,第 8 到 14 天的資料存盤在遠端 S3,超過 14 天的資料過期洗掉,
大體流程如下圖所示:
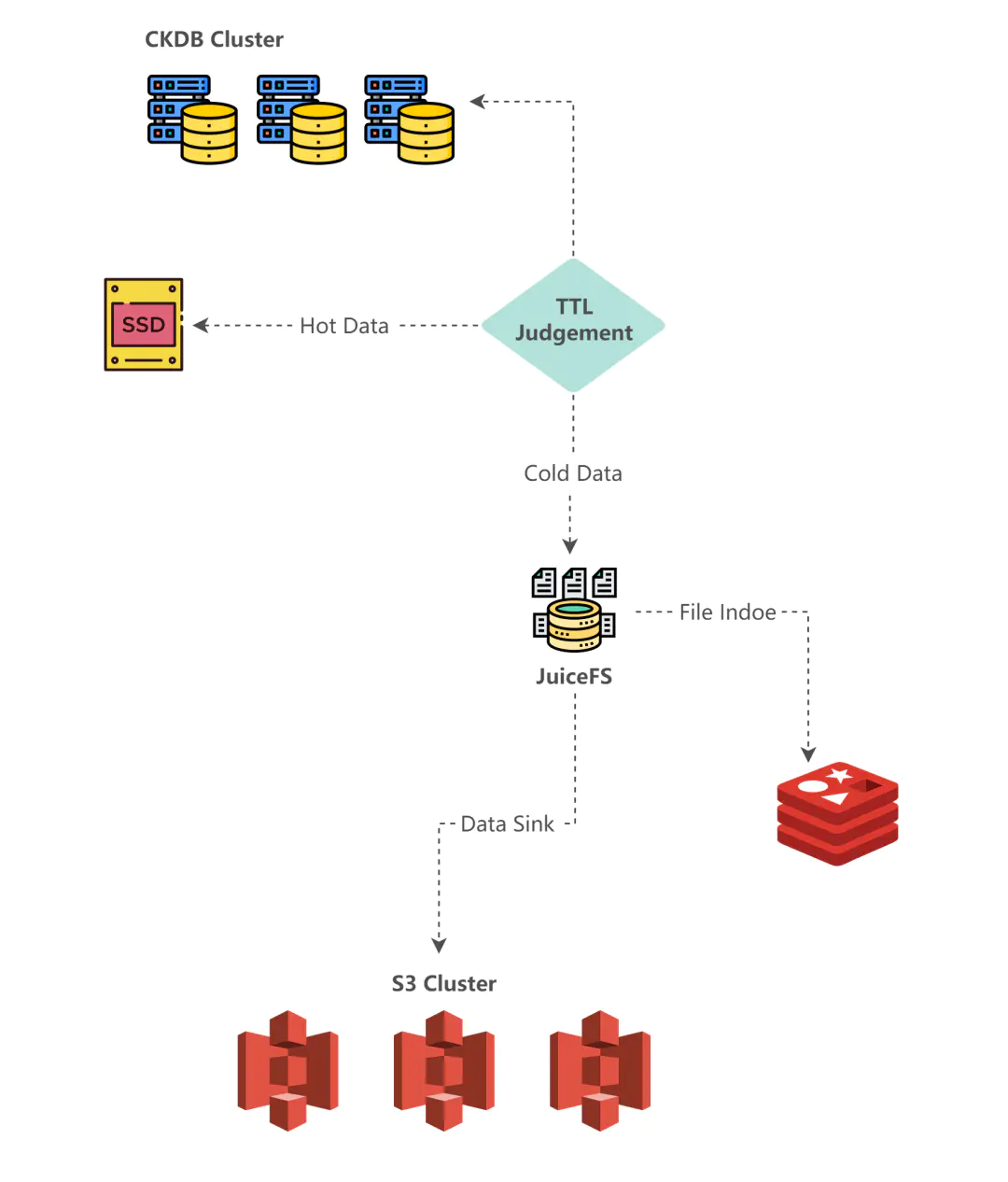
表 hcs_table_name 的 data parts(ClickHouse 的資料存盤以 data part 為基本處理單位)會被后臺任務調度,后臺任務由執行緒 BgMoveProcPool 執行,這個執行緒來自 back_ground_move_pool(注意和 back_ground_pool 不是同一個),
std::optional<BackgroundProcessingPool> background_move_pool; /// The thread pool for the background moves performed by the tables.
后臺任務調度會判斷 data parts 是否需要 move(資料是否需要下沉移動到遠端存盤上)和是否可以 move,如果需要執行 move,后臺 move_pool 會創建一個 move 的 task,這個 task 的核心邏輯是:首先選擇需要 move 的 data parts,然后再 move 這些 data parts 到目的存盤,
在介面:
MergeTreePartsMover::selectPartsForMove
中根據 TTL 運算式獲取ttl_entry,然后根據 data parts 中的ttl_move資訊,選出需要 move 的 data parts,存盤 data parts 的move_entry(包含 IMergeTreeDataPart 指標和需要預留的存盤空間大小)到 vector 中,之后會呼叫介面:
MergeTreeData::moveParts
實作 move 操作,move 的程序簡單來說就是 clone SSD 磁盤上的 data parts 到遠端存盤 S3 上 hcs_table_name 表的 detach 目錄下,然后再從 detach 目錄下把 data parts 移出來,最后這些在 SSD 磁盤上的 data parts 會在 IMergeTreeDataPart 的解構式中被清除,
所以整個 move 程序中,表一直是可查的,因為是 clone 操作,同一時刻下 move 的 data parts 要么在 SSD 磁盤上為 active,要么在遠端存盤上為 active,
關于表 data parts 的 move 資訊,也可以查詢系統表 system.parts 的以下三個欄位:
move_ttl_info.expression; move_ttl_info.min; move_ttl_info.max;
3. 實踐分享
在 Shopee ClickHouse 冷熱資料分離存盤架構上線后,我們總結了一些實踐中遇到的問題,
3.1 Redis 記憶體增長例外
S3 上的資料存盤量并沒有增加太多,Redis 記憶體卻持續高速增長,
JuiceFS 使用 Redis 存盤 S3 上的資料檔案的元資料,所以正常情況下,S3 上的資料檔案越多,Redis 存盤使用量也就越多,一般這種例外情況是因為目標表有很多小檔案沒有 merge 而直接下沉,很容易打滿 Redis,
這也會引入另一個問題:一旦 Redis 記憶體打滿,JuiceFS 就不能再成功寫資料到 S3 上,如果 unmount 掉 JuiceFS 客戶端,也無法再次成功 mount 上去,再次 mount 的時候會拋 Error:
Meta: create session: OOM command not allowed when used memory > 'maxmemory'.
要避免這種問題發生,首先應該做好 ClickHouse merge 狀態的監控,clickhouse-exporter會采集一個 merge 指標clickhouse_merge,這個指標會采集到當前正在觸發的 merge 個數(通過查詢 system.metrics 表 metric=‘merge’),每觸發一次 merge 會有一個表的多個 data parts 做合并操作,按照我們的經驗來看,若每三個小時 merge 的平均次數小于 0.5,那么很有可能是這臺機器的 merge 出現了問題,
而 merge 例外的原因可能有很多(例如 HTTPHandler 執行緒、ZooKeeperRecv 執行緒持續占據了大量 CPU 資源等), 這個不是本文的介紹重點,在此不再展開,所以可以設定告警規則,如果三小時內 merge 次數小于 0.5 次,告警給 ClickHouse 的開發運維團隊同學,避免大量小檔案產生,
如果已經有大量小檔案下沉到 S3 應該怎么辦?
首先要阻止資料繼續下沉,可以通過兩種方式找到有大量小檔案下沉的用戶業務表,
第一種方式:查看 ClickHouse 的 Error Log,找到拋 too many parts 的表,再進一步判斷拋 Error 的表是否有冷熱存盤,
第二種方式:通過查詢 system.parts 表,找出 active parts 明顯過多,并且 disk_name 等于冷存的別名的,定位到產生大量小檔案的表后,通過 ClickHouse 系統命令 SQL 停止資料下沉,避免 Redis 記憶體打滿,
SYSTEM STOP MOVES [[db.]merge_tree_family_table_name]
如果表比較小,比如壓縮后小于 1TB(這里的 1TB
是一個經驗值,我們曾經使用 insert into … select * from … 方式導表資料,如果大于 1TB,匯入時間會很久,還有一定的可能性在匯入中途失敗),在確認 merge 功能恢復正常后,可以選擇創建 temp table > insert into this temp table > select * from org table,然后 drop org table > rename temp table to org table,
如果表比較大,確認 merge 功能恢復正常后,嘗試通過系統命令 SQL 喚醒 merge 執行緒:
SYSTEM START MERGES [[db.]merge_tree_family_table_name]
如果 merge 進行緩慢,可以查詢 system.parts 表,找到已經落在 S3 上的 data parts,然后手動執行 Query 將落在 S3 上的小檔案移回到 SSD 上:
ALTER TABLE table_source MOVE PART/PARTITION partition_expr TO volume 'ssd_volume'
因為 SSD 的 IOPS 比 S3 要高很多(即使是通過 JuiceFS 訪問加速后),這樣一方面加快 merge 程序,一方面因為檔案移出 S3,會釋放 Redis 記憶體,3.2 讀寫 S3 失敗
資料下沉失敗,通過 JuiceFS 訪問 S3,無法對 S3 進行讀寫操作,這個時候用戶查詢如果覆寫到資料在 S3 上的,那么查詢會拋 S3 mount 的本地路徑上的資料檔案無法訪問的錯誤,遇到這個問題可以查詢 JuiceFS 的日志,
JuiceFS 的日志在 Linux CentOS 中存盤在 syslog 上,查詢日志可以用方法 cat/var/log/messages|grep 'juicefs',不同作業系統對應的日志目錄可以參照 JuiceFS 社區檔案[3],
我們遇到的問題是 send request to S3 host name certificate expired,后來通過聯系 S3 的開發運維團隊,解決了訪問問題,
那么如何監控這類 JuiceFS 讀寫 S3 失敗的情況呢?可以通過 JuiceFS 提供的指標 juicefs_object_request_errors 監控,如果出現 Error 就告警團隊成員,及時查詢日志定位問題,
3.3 clickhouse-server 啟動失敗
對歷史表需要做冷熱資料存盤分離的復制表(表引擎含有 Replicated 前綴)修改 TTL 時,clickhouse-server 本地 .sql 檔案元資料中的 TTL 運算式和 ZooKeeper 上存盤的 TTL 運算式不一致,這個是我們在測驗程序中遇到的問題,如果沒有解決這個問題而重啟 clickhouse-server 的話,會因為表結構沒有對齊而使 clickhouse-server 啟動失敗,
這是因為對復制表的 TTL 的修改是先修改 ZooKeeper 內的 TTL,然后才會修改同一個節點下的機器上表的 TTL,所以如果在修改 TTL 后,本地機器 TTL 還沒有修改成功,而重啟了 clickhouse-server,就會發生上述問題,
3.4 suspicious_broken_parts
重啟 clickhouse-server 失敗,拋出 Error:
DB::Exception: Suspiciously many broken parts to remove
這是因為 ClickHouse 在重啟服務的時候,會重新加載 MergeTree 表引擎資料,主要代碼介面為:
MergeTreeData::loadDataParts(bool skip_sanity_checks)
在這個介面中會獲取到每一個表的 data parts,判斷 data part 檔案夾下是否有#DELETE_ON_DESTROY_MARKER_PATH也就是delete-on-destroy.txt檔案存在,如果有,將該 part 加入到broken_parts_to_detach,并將suspicious_broken_parts統計個數加 1,
那么在冷熱資料存盤分離的場景下,data parts 通過 TTL 做下沉的時候,在核心介面 move 操作的函式中會有如下的代碼呼叫關系:
MergeTreeData::moveParts->MergeTreePartsMover::swapClonedPart->MergeTreeData::swapActivePart
在最后一個函式中交換 active parts 的路徑指向,也就是上文說的,data parts 在 move 程序中,資料是可查的,要么在 SSD 為 active,要么在 S3 為 active,
void MergeTreeData::swapActivePart(MergeTreeData::DataPartPtr part_copy)
{
auto lock = lockParts();
for (auto original_active_part : getDataPartsStateRange(DataPartState::Committed)) // NOLINT (copy is intended)
{
if (part_copy->name == original_active_part->name)
{
.....
String marker_path = original_active_part->getFullRelativePath() + DELETE_ON_DESTROY_MARKER_PATH;
try
{
disk->createFile(marker_path);
}
catch (Poco::Exception & e)
...
}
在這個介面中,舊的 active parts(也就是 replacing parts)內會創建 #DELETE_ON_DESTROY_MARKER_PATH 檔案來把 state 修改為 DeleteOnDestory,用于后期 IMergeTreeDataPart 析構時洗掉該 state 的 data parts,
這也就是在我們的使用場景下會出現 suspicious_broken_parts 的原因,這個值超過默認閾值 10 的時候就會影響 ClickHouse 服務啟動,
解決方案有兩種:第一種,洗掉這個機器上拋出該錯誤的表的元資料 .sql 檔案、存盤資料、ZooKeeper 上的元資料,重啟機器后重新建表,資料會從備份機器上同步過來,第二種,在 ClickHouse /flags 路徑下用 clickhouse-server 行程的運行用戶創建 force_restore_data flag,然后重啟即可,
從上述問題中可以看到,使用 JuiceFS+S3 實作了冷熱資料分離存盤架構后,引入了新的組件(JuiceFS+Redis+S3),資料庫的使用場景更加靈活,相應地,各個方面的監控資訊也要做好,這里分享幾個比較重要的監控指標:
- JuiceFS:
juicefs_object_request_errors:JuiceFS 對 S3 讀寫的健康狀態監控, - Redis:
Memory Usage:監控 Redis 的記憶體使用情況, - ClickHouse:
clickhouse_merge:監控集群中機器的 merge 狀態是否正常,
4. 冷熱存盤架構收益總述
冷熱資料存盤分離后,我們更好地支持了用戶的資料業務,提高了整體集群的資料存盤能力,緩解了各個機器的本地存盤壓力,對業務資料的管理也更加靈活,
冷熱資料分離架構上線前,我們的集群機器平均磁盤使用率接近 85%,上線后,通過修改業務用戶表 TTL,這一資料下降到了 75%,并且整體集群在原有的業務量基礎上,又支持了兩個新的資料業務,如果沒有上線冷熱隔離,我們的集群在擴容前就會因為磁盤用量不足而無法承接新的專案,當前我們下沉到遠端 S3 的資料量大于 90TB(壓縮后),
未來 Shopee ClickHouse 會持續開發更多有用的 feature,也會持續演進產品架構,目前 JuiceFS 在我們生產環境中的使用非常穩定,我們后續會進一步使用 JuiceFS 訪問 HDFS,進而實作 Shopee ClickHouse 存盤計算分離架構,
本文提到的各個產品組件版本資訊如下:
- Shopee ClickHouse:當前基于社區版 ClickHouse 20.8.12.2-LTS version
- JuiceFS:v0.14.2
- Redis:v6.2.2,sentinel model,開啟 AOF(策略為 Every Secs),開啟 RDB(策略為一天一備份)
- S3:由 Shopee STO 團隊提供
- Ozone:1.1.0-SNAPSHOT
本文作者
Teng,畢業于新加坡國立大學,來自 Shopee Data Infra 團隊,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/309048.html
標籤:其他
上一篇:🚴?♂?全套MySQL資料庫教程_Mysql基礎入門教程,零基礎小白自學MySQL資料庫必備教程? #002 # 第二單元 MySQL資料型別、操作表#