我正在嘗試使用Selenium刮取Facebook頁面進行分析。
http://www.facebook.com/123439757700947。
查看頁面原始碼,我發現了我需要的標簽:
<title>Tzipi Hotovely - ???? ???????</title>
我使用的方法是:
politician_name = driver.find_element_by_tag_name('title'/span>)
politician_name.text
其中回傳:
''。
我還想從下面的字典項中得到喜歡該網頁的人數:
我想從下面的字典項中得到喜歡該網頁的人數:
"page_likers":{"global_likers_count":92987}。
這是在<script>標簽下:
我希望得到一些幫助......
我希望得到一些幫助。
我正在嘗試建議的解決方案:
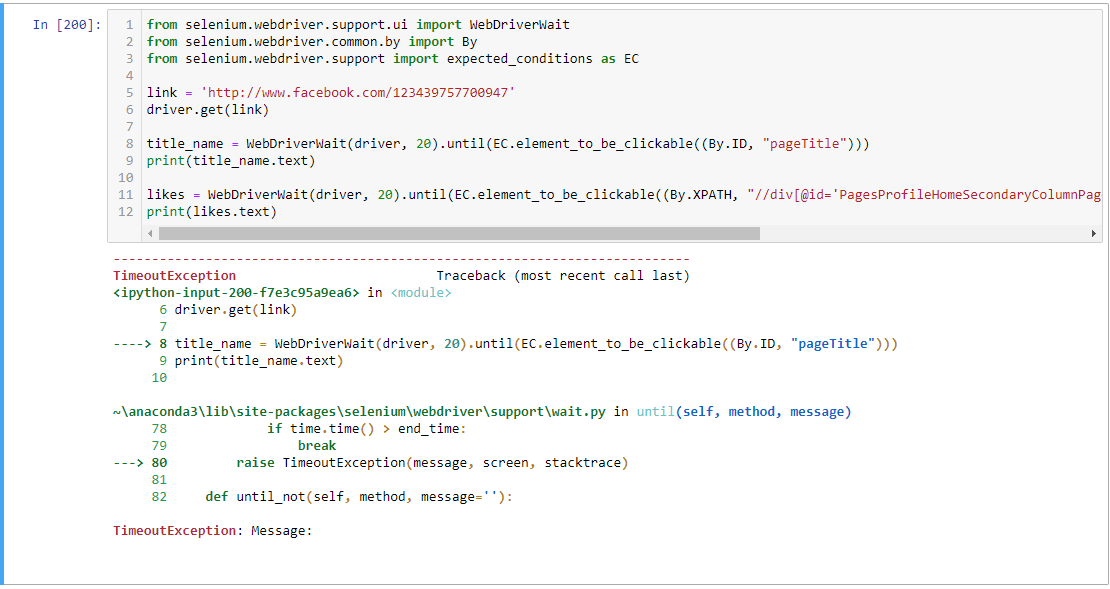
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
link = 'http://www.facebook.com/123439757700947'/span>
driver.get(link)
title_name = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.ID, "pageTitle") )
print(title_name.text)
likes = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By. XPATH, "//div[@id='PagesProfileHomeSecondaryColumnPagelet']//descendant::div[contains(@class,'clearfix')]/div[2]/div"/span>))
print(likes.text)
得到TimeoutException
 uj5u.com熱心網友回復:
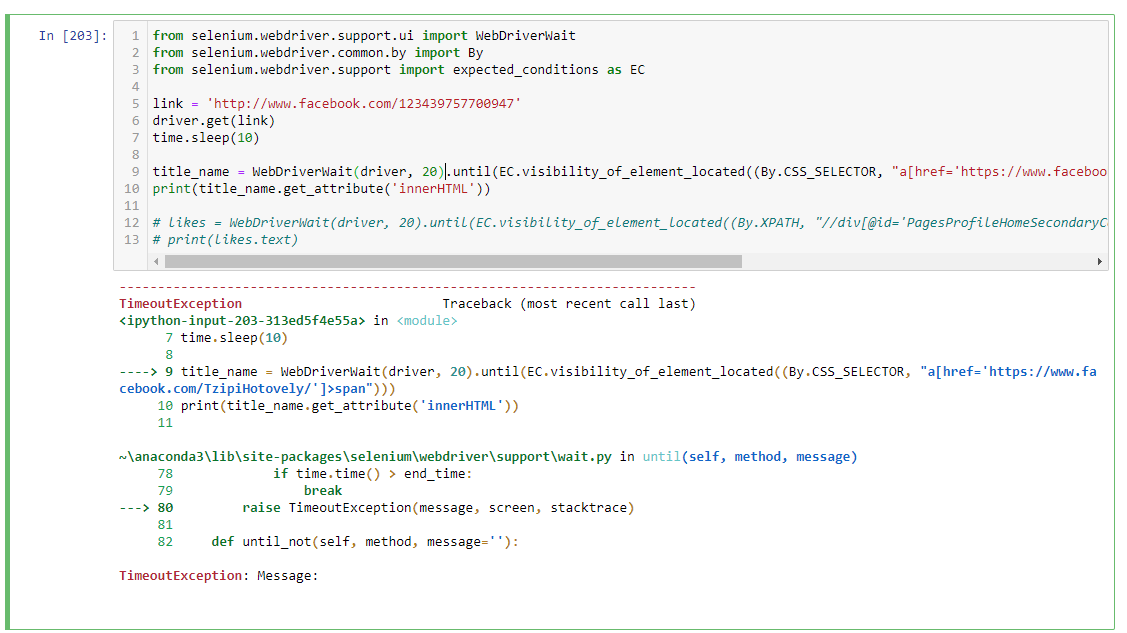
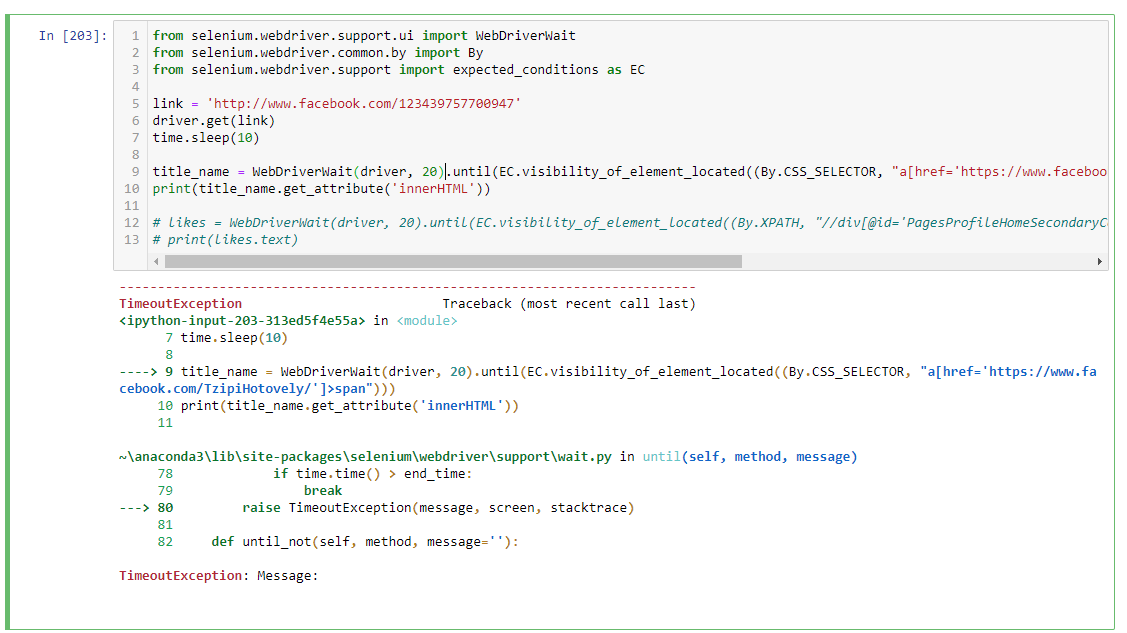
uj5u.com熱心網友回復:你必須誘導明確的等待。
我看到這個id pageTitle在HTMLDOM中是唯一的。
link = 'http://www.facebook.com/123439757700947'/span>
driver.get(link)
title_name = WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "a[href='https://www.facebook.com/TzipiHotovely/']>span")
print(title_name.get_attribute('innerHTML')
likes = WebDriverWait(driver, 20).until(EC.visible_of_element_located((By. XPATH, "//div[@id='PagesProfileHomeSecondaryColumnPagelet']//descendant::div[contains(@class,'clearfix')]/div[2]/div"/span>))
print(likes.text)
匯入:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
uj5u.com熱心網友回復:
好的,這段代碼涵蓋了大多數情況
76個page_ids中只有14個回傳空白
politicains_dict = {}.
BASE_LINK = 'http://www.facebook.com/'/span>
# time.sleep(5)/span>
for id in page_ids_list:
link = BASE_LINK str(id) '/')
driver.get(link)
time.sleep(10)
try:
politician_name = driver.find_element_by_xpath("/html/body/div[1]/div/div[1]/div/div[3]/div/div[1]/div[1]/div[2]/div/div/div[2]/h2/span/span")
likes = 驅動程式。 find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div[1]/div[4]/div[2]/div/div[1]/div[2]/div/div[2]/div[3]/div[1]/div/div/div[2]/div/span/span[1]')
followers = driver. find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div[1]/div[1]/div[4]/div[2]/div/div[1]/div[2]/div/div/div[2]/div/div/span/span')
politicains_dict[id] = [politician_name.text, likes.text, followers.text)
except:
try:
politician_name = driver.find_element_by_xpath("/html/body/div[1]/div/div[1]/div/div[3]/div/div[1]/div/div[1]/div/div[2]/div/div/div[2]/div/div/h1"/span>)
followers = driver. find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div[1]/div/div[4]/div[2]/div/div[1]/div[2]/div/div/div[1]/div/div/ul/div[1]/div/div/span/a')
politicains_dict[id] = [politician_name.text, ''/span>, followers.text] 。
except:
try:
politician_name = driver.find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div[1]/div[1]/div[2]/div/div/div[2]/h2/span/span')
likes = 驅動程式。 find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div[1]/div[4]/div[2]/div/div[1]/div[2]/div[1]/div/div/div[2]/div[3]/div[1]/div/div[2]/div/div/span/span[1]')
followers = driver. find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div[1]/div[1]/div[4]/div[2]/div/div[1]/div/div/div[2]/div/div/span/span')
politicains_dict[id] = [politician_name.text, likes.text, followers.text)
except:
politicains_dict[id] = [""/span>, ""/span>, ""/span>]
繼續 繼續
uj5u.com熱心網友回復:
嘗試下面的xpath來提取title。它可能有效。
//div[contains(@aria-label,'Send Message')]//parent::div//parent::div//parent::div//parent::div//h2/span/span
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/309748.html
標籤:
上一篇:我在一個網站上發現了一個跨度,但這個跨度是不可見的,我無法將其刮除!為什么?為什么?
下一篇:沒有考慮到設定錯誤日志的位置