根據最新的統計顯示,僅在過去的兩年中,當今世界上90%的資料都是在新產生的,每天創建2.5萬億位元組的資料,并且隨著新設備,傳感器和技術的出現,資料增長速度可能會進一步加快,
從技術上講,這意味著我們的大資料處理將變得更加復雜且更具挑戰性,而且,許多用例(例如,移動應用廣告,欺詐檢測,出租車預訂,病人監護等)都需要在資料到達時進行實時資料處理,以便做出快速可行的決策,這就是為什么分布式流處理在大資料世界中變得非常流行的原因,
如今,有許多可用的開源流框架,有趣的是,幾乎所有它們都是相當新的,僅在最近幾年才開發出來,因此,對于新手來說,很容易混淆流框架之間的理解和區分,在本文中,我將首先大致討論流處理的型別和方面,然后比較最受歡迎的開源流框架:Flink,SparkStreaming,Storm,KafkaStream,我將嘗試(簡要地)解釋它們的作業原理,它們的用例,優勢,局限性,異同,
什么是流/流處理:
流處理的最優雅的定義是:一種資料處理引擎,其設計時考慮了無限的資料集,
與批處理不同,批處理以作業中的開始和結束為界,而作業是在處理有限資料之后完成的,而流處理則是指連續不斷地處理天,月,年和永久到來的無邊界資料,因此,流媒體應用程式始終需要啟動和運行,因此難以實作且難以維護,
流處理的重要方面:
為了理解任何Streaming框架的優點和局限性,我們應該了解與Stream處理相關的一些重要特征和術語:
- 交付保證:
這意味著無論如何,流引擎中的特定傳入記錄都將得到處理的保證,可以是at least once(至少一次)(即使發生故障也至少處理一次),at most once : 至多一次(如果發生故障則可能不處理)或Exactly-once(即使失敗在這種情況下也只能處理一次)),顯然,只處理一次是最好的,但是很難在分布式系統中實作,并且需要權衡性能, - 容錯:
如果發生諸如節點故障,網路故障等故障,框架應該能夠恢復,并且應該從其離開的位置開始重新處理,這是通過不時檢查流向某些持久性存盤的狀態來實作的,例如,從Kafka獲取記錄并對其進行處理后,將Kafka檢查點偏移給Zookeeper, - 狀態管理:在有狀態處理需求的情況下,我們需要保持某種狀態(例如,記錄中每個不重復單詞的計數),框架應該能夠提供某種機制來保存和更新狀態資訊,
- 性能:
這包括延遲(可以多久處理一條記錄),吞吐量(每秒處理的記錄數)和可伸縮性,延遲應盡可能小,而吞吐量應盡可能大,很難同時獲得兩者, - 高級功能:事件時間處理,水印,視窗化
如果流處理要求很復雜,這些是必需的功能,例如,根據在源中生成記錄的時間來處理記錄(事件時間處理), - 成熟度:從采用的角度來看很重要,如果框架已經過大公司的驗證和大規模測驗,那就太好了,更有可能獲得良好的社區支持并在堆疊溢位方面提供幫助,
流處理的兩種型別:
現在了解了我們剛剛討論的術語,現在很容易理解,有兩種方法可以實作Streaming框架:
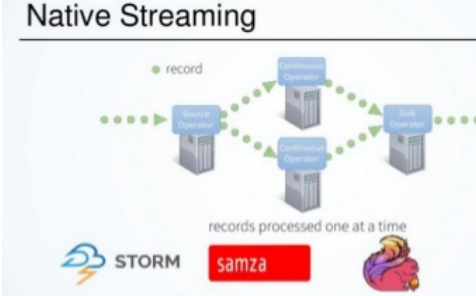
原生流處理:
這意味著每條到達的記錄都會在到達后立即處理,而無需等待其他記錄,有一些連續運行的程序(根據框架,我們稱之為操作員/任務/螺栓),這些程序將永遠運行,每條記錄都將通過這些程序進行處理,示例:Storm,Flink,Kafka Streams,Samza,
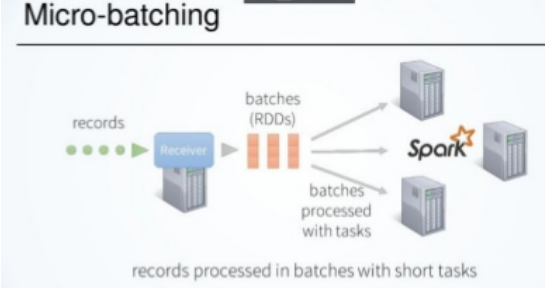
微批處理:
也稱為快速批處理,這意味著每隔幾秒鐘就會將傳入的記錄分批處理,然后以單個小批處理的方式處理,延遲幾秒鐘,例如:Spark Streaming, Storm-Trident,
兩種方法都有其優點和缺點,
原生流傳輸感覺很自然,因為每條記錄都會在到達記錄后立即進行處理,從而使框架能夠實作最小的延遲,但這也意味著在不影響吞吐量的情況下很難實作容錯,因為對于每條記錄,我們都需要在處理后跟蹤和檢查點,而且,狀態管理很容易,因為有長時間運行的行程可以輕松維護所需的狀態,
另一方面,微批處理則完全相反,容錯是免費提供的,因為它本質上是一個批處理,吞吐量也很高,因為處理和檢查點將在一組記錄中一次性完成,但這會花費一定的等待時間,并且感覺不自然,高效的狀態管理也將是維持的挑戰,
流框架對比:
Storm :
Storm是流處理世界的強者,它是最古老的開源流框架,也是最成熟和可靠的框架之一,這是真正的流傳輸,適合基于簡單事件的用例,
優點:
- 極低的延遲,真正的流,成熟和高吞吐量
- 非常適合簡單的流媒體用例
缺點
- 沒有狀態管理
- 沒有高級功能,例如事件時間處理,聚合,開窗,會話,水印等
- 一次保證
Spark Streaming :
Spark已成為批處理中hadoop的真正繼任者,并且是第一個完全支持Lambda架構的框架(在該框架中,實作了批處理和流傳輸;實作了正確性的批處理;實作了流傳輸的速度),它非常受歡迎,成熟并被廣泛采用,Spark Streaming是隨Spark免費提供的,它使用微批處理進行流媒體處理,在2.0版本之前,Spark Streaming有一些嚴重的性能限制,但是在新版本2.0+中,它被稱為結構化流,并具有許多良好的功能,例如自定義記憶體管理(類似flink),水印,事件時間處理支持等,另外,結構化流媒體更加抽象,在2.3.0版本以后,可以選擇在微批量和連續流媒體模式之間進行切換,連續流模式有望帶來像Storm和Flink這樣的子延遲,但是它仍處于起步階段,操作上有很多限制,
優點:
- 支持Lambda架構,Spark免費提供
- 高吞吐量,適用于不需要亞延遲的許多使用情況
- 由于微批量性質,默認情況下具有容錯能力
- 簡單易用的高級API
- 龐大的社區和積極的改進
- 恰好一次
缺點
-
不是真正的流,不適合低延遲要求
-
要調整的引數太多,很難做到正確,
-
天生無國籍
-
在許多高級功能方面落后于Flink
Flink :
Flink也來自類似Spark這樣的學術背景,Spark來自加州大學伯克利分校,而Flink來自柏林工業大學,像Spark一樣,它也支持Lambda架構,但是實作與Spark完全相反,雖然Spark本質上是一個批處理,其中Spark流是微批處理,并且是Spark Batch的特例,但Flink本質上是一個真正的流引擎,將批處理視為帶邊界資料流的特例,盡管這兩個框架中的API都是相似的,但是它們在實作上沒有任何相似性,在Flink中,諸如map,filter,reduce等的每個函式都實作為長時間運行的運算子(類似于Storm中的Bolt)
Flink看起來像是Storm的真正繼承者,就像Spark批量繼承了hadoop一樣,
優點:
- 開源流媒體領域創新的領導者
- 具有所有高級功能(例如事件時間處理,水印等)的第一個True流框架
- 低延遲,高吞吐量,可根據要求進行配置
- 自動調整,無需調整太多引數
- 恰好一次
- 被Uber,阿里巴巴等大型公司廣泛接受,
缺點
-
起步較晚,最初缺乏采用
-
社區不如Spark大,但現在正在快速發展
Kafka Streams :
與其他流框架不同,Kafka Streams是一個輕量級的庫,對于從Kafka流式傳輸資料,進行轉換然后發送回kafka很有用,我們可以將其理解為類似于Java Executor服務執行緒池的庫,但具有對Kafka的內置支持,它可以與任何應用程式很好地集成,并且可以立即使用,
由于其重量輕的特性,可用于微服務型別的體系結構,Flink在性能方面沒有匹配之處,而且不需要運行單獨的集群,非常方便并且易于部署和開始作業,
Kafka Streams的一個主要優點是它的處理是完全精確的端到端,可能是因為來源和目的地均為Kafka以及從2017年6月左右發布的Kafka 0.11版本開始,僅支持一次,要啟用此功能,我們只需要啟用一個標志即可使用,
優點:
- 重量很輕的庫,適合微服務,IOT應用
- 不需要專用集群
- 繼承卡夫卡的所有優良特性
- 支持流連接,內部使用rocksDb維護狀態,
- 恰好一次(從Kafka 0.11開始),
缺點
- 與卡夫卡緊密結合,在沒有卡夫卡的情況下無法使用
- 嬰兒期還很新,尚待大公司測驗
- 不適用于繁重的作業,例如Spark Streaming,Flink,
Samza :
簡短介紹一下Samza,(Samza)看上去就像是(Kafka Streams),有很多相似之處,這兩個框架都是由同一位開發人員開發的,這些開發人員在LinkedIn上實作了Samza,然后在他們創建Kafka Streams的地方成立了Confluent,這兩種技術都與Kafka緊密結合,從Kafka獲取原始資料,然后將處理后的資料放回Kafka,使用相同的Kafka Log哲學,Samza是Kafka Streams的縮放版本,Kafka Streams是一個用于微服務的庫,而Samza是在Yarn上運行的完整框架集群處理,
優點 :
- 使用rocksDb和kafka日志可以很好地維護大量資訊狀態(適合于連接流的用例),
- 使用Kafka屬性的容錯和高性能
- 如果已在處理管道中使用Yarn和Kafka,則要考慮的選項之一,
- 低延遲,高吞吐量,成熟并經過大規模測驗
缺點:
- 與Kafka和Yarn緊密結合,如果這些都不在您的處理管道中,則不容易使用,
- 至少一次加工保證,我不確定它是否像Kafka 0.11之后的Kafka Streams現在完全支持一次
- 缺少高級流功能,例如水印,會話,觸發器等
流框架比較:
我們只能將技術與類似產品進行比較,盡管Storm,Kafka Streams和Samza現在對于更簡單的用例很有用,但具有最新功能的重量級產品之間的真正競爭顯而易見:Spark vs Flink

當我們談論比較時,我們通常會問:給我看數字
基準測驗是僅當第三方進行比較時比較的好方法,
例如,但這是在Spark Streaming 2.0之前的某個時期,當時它受RDD的限制,
現在,隨著Structured Streaming 2.0版本的發布,Spark Streaming試圖趕上很多潮流,而且似憾訓會面臨艱巨的挑戰,
最近,基準測驗已成為Spark和Flink之間的一場激烈爭吵,
最好不要相信這些天的基準測驗,因為即使很小的調整也可以完全改變數字,沒有什么比決定之前嘗試和測驗自己更好,
到目前為止,很明顯,Flink在流分析領域處于領先地位,它具有大多數所需的方面,例如精確一次,吞吐量,延遲,狀態管理,容錯,高級功能等,
Flink的一個重要問題是成熟度和采用水平,直到一段時間之前,但是現在像Uber,Alibaba,CapitalOne這樣的公司正在大規模使用Flink流傳輸,證明了Flink Streaming的潛力,
最近,Uber開源了其最新的流分析框架AthenaX,該框架基于Flink引擎構建,
如果您已經注意到,需要注意的重要一點是,所有支持狀態管理的原生流框架(例如Flink,Kafka Streams,Samza)在內部都使用RocksDb,RocksDb從某種意義上說是獨一無二的,它在每個節點上本地保持持久狀態,并且性能很高,它已成為新流系統的關鍵部分,
如何選擇最佳的流媒體框架:
這是最重要的部分,誠實的答案是:這取決于 :
必須牢記,對于每個用例,沒有一個單一的處理框架可以成為萬靈丹,每個框架都有其優點和局限性,盡管如此,根據一些經驗,他們仍然會分享一些有助于做出決定的建議:
- 取決于用例:
如果用例很簡單,那么如果學習和實作起來很復雜,則無需尋求最新,最好的框架,在很大程度上取決于我們愿意投資多少來換取我們想要的回報,例如,如果它是基于事件的簡單IOT事件警報系統,那么Storm或Kafka Streams非常適合使用, - 未來考慮因素:
同時,我們還需要對未來可能的用例進行自覺考慮,將來可能會出現對諸如事件時間處理,聚合,流加入等高級功能的需求嗎?如果答案是肯定的,則最好繼續使用高級流框架(例如Spark Streaming或Flink),一旦對一項技術進行了投資和實施,其變更的困難和巨大成本將在以后改變,例如,在之前的公司中,從過去的兩年開始,Storm管道就已經啟動并運行,并且在要求統一輸入事件并僅報告唯一事件之前,它一直運行良好,現在,這需要狀態管理,而Storm本身并不支持這種狀態管理,雖然我使用基于時間的記憶體哈希表實作,但是在重啟時狀態會消失是有限制的, - 我要提出的觀點是,如果我們嘗試自行實作框架未明確提供的某些內容,則勢必會遇到未知問題,
- 現有技術堆疊:
另一重要點是考慮現有技術堆疊,如果現有堆疊的首尾相連是Kafka,則Kafka Streams或Samza可能更容易安裝,同樣,如果處理管道基于Lambda架構,并且Spark Ba??tch或Flink Batch已經到位,則考慮使用Spark Streaming或Flink Streaming是有意義的,例如,在我以前的專案中,我已經在管道中添加了Spark Ba??tch,因此,當流需求到來時,選擇需要幾乎相同的技能和代碼庫的Spark Streaming非常容易,
簡而言之,如果我們很好地了解框架的優點和局限性以及用例,那么選擇或至少過濾掉可用的選項就更加容易,最后,一旦選擇了幾個選項,畢竟每個人都有不同的選擇,
Streaming的發展速度如此之快,以至于在資訊方面,此帖子可能在幾年后已經過時,目前,Spark和Flink在開發方面是領先的重量級人物,但仍有一些新手可以加入比賽,Apache Apex是其中之一,還有一些我沒有介紹的專有流解決方案,例如Google Dataflow,我的這篇文章的目的是幫助剛接觸流技術的人以最少的術語理解流技術的一些核心概念,以及流行的開源流框架的優點,局限性和用例,希望該文章對您有所幫助,
更多實時資料分析相關博文與科技資訊,歡迎關注 “實時流式計算”

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/3124.html
標籤:大數據