?
資料接入
資料的接入可以通過將資料實時寫入Kafka進行接入,不管是直接的寫入還是通過oracle和mysql的實時接入方式,比如oracle的ogg,mysql的binlog
ogg
Golden Gate(簡稱OGG)提供異構環境下交易資料的實時捕捉、變換、投遞,
通過OGG可以實時的將oracle中的資料寫入Kafka中,
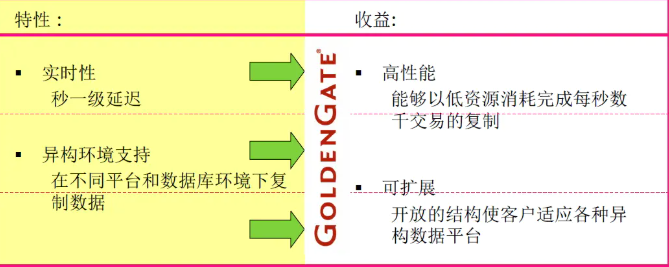
對生產系統影響小:實時讀取交易日志,以低資源占用實作大交易量資料實時復制
以交易為單位復制,保證交易一致性:只同步已提交的資料
高性能
- 智能的交易重組和操作合并
- 使用資料庫本地介面訪問
- 并行處理體系
binlog
MySQL 的二進制日志 binlog 可以說是 MySQL 最重要的日志,它記錄了所有的 DDL 和 DML 陳述句(除了資料查詢陳述句select、show等),以事件形式記錄,還包含陳述句所執行的消耗的時間,MySQL的二進制日志是事務安全型的,binlog 的主要目的是復制和恢復,
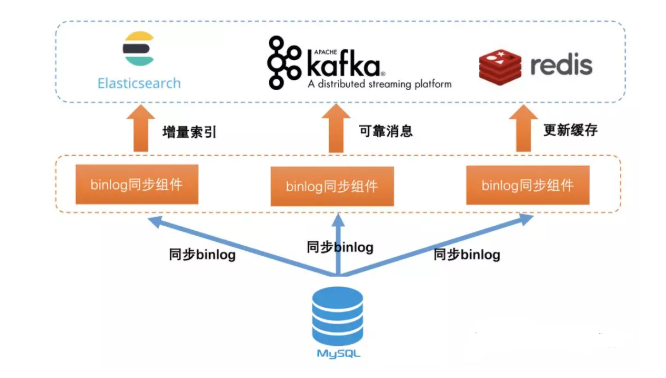
通過這些手段,可以將資料同步到kafka也就是我們的實時系統中來,
Flink接入Kafka資料
Apache Kafka Connector可以方便對kafka資料的接入,
依賴
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.11</artifactId> <version>1.9.0</version></dependency>
構建FlinkKafkaConsumer
必須有的:
1.topic名稱
2.用于反序列化Kafka資料的DeserializationSchema / KafkaDeserializationSchema
3.配置引數:“bootstrap.servers” “group.id” (kafka0.8還需要 “zookeeper.connect”)
val properties = new Properties()properties.setProperty("bootstrap.servers", "localhost:9092")// only required for Kafka 0.8properties.setProperty("zookeeper.connect", "localhost:2181")properties.setProperty("group.id", "test")stream = env .addSource(new FlinkKafkaConsumer[String]("topic", new SimpleStringSchema(), properties)) .print()
時間戳和水印
在許多情況下,記錄的時間戳(顯式或隱式)嵌入記錄本身,另外,用戶可能想要周期性地或以不規則的方式發出水印,
我們可以定義好Timestamp Extractors / Watermark Emitters,通過以下方式將其傳遞給消費者
val env = StreamExecutionEnvironment.getExecutionEnvironment()val myConsumer = new FlinkKafkaConsumer[String](...)myConsumer.setStartFromEarliest() // start from the earliest record possiblemyConsumer.setStartFromLatest() // start from the latest recordmyConsumer.setStartFromTimestamp(...) // start from specified epoch timestamp (milliseconds)myConsumer.setStartFromGroupOffsets() // the default behaviour//指定位置//val specificStartOffsets = new java.util.HashMap[KafkaTopicPartition, java.lang.Long]()//specificStartOffsets.put(new KafkaTopicPartition("myTopic", 0), 23L)//myConsumer.setStartFromSpecificOffsets(specificStartOffsets)val stream = env.addSource(myConsumer)
檢查點
啟用Flink的檢查點后,Flink Kafka Consumer將使用主題中的記錄,并以一致的方式定期檢查其所有Kafka偏移以及其他操作的狀態,如果作業失敗,Flink會將流式程式恢復到最新檢查點的狀態,并從存盤在檢查點中的偏移量開始重新使用Kafka的記錄,
如果禁用了檢查點,則Flink Kafka Consumer依賴于內部使用的Kafka客戶端的自動定期偏移提交功能,
如果啟用了檢查點,則Flink Kafka Consumer將在檢查點完成時提交存盤在檢查點狀態中的偏移量,
val env = StreamExecutionEnvironment.getExecutionEnvironment()env.enableCheckpointing(5000) // checkpoint every 5000 msecs
Flink消費Kafka完整代碼:
import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class KafkaConsumer { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); //構建FlinkKafkaConsumer FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties); //指定偏移量 myConsumer.setStartFromEarliest(); DataStream<String> stream = env .addSource(myConsumer); env.enableCheckpointing(5000); stream.print(); env.execute("Flink Streaming Java API Skeleton"); }
這樣資料已經實時的接入我們系統中,可以在Flink中對資料進行處理了,那么如何對標簽進行計算呢? 標簽的計算程序極大的依賴于資料倉庫的能力,所以擁有了一個好的資料倉庫,標簽也就很容易計算出來了,
資料倉庫基礎知識
資料倉庫是指一個面向主題的、集成的、穩定的、隨時間變化的資料的集合,以用于支持管理決策的程序,
(1)面向主題
業務資料庫中的資料主要針對事物處理任務,各個業務系統之間是各自分離的,而資料倉庫中的資料是按照一定的主題進行組織的
(2)集成
資料倉庫中存盤的資料是從業務資料庫中提取出來的,但并不是原有資料的簡單復制,而是經過了抽取、清理、轉換(ETL)等作業,
業務資料庫記錄的是每一項業務處理的流水賬,這些資料不適合于分析處理,進入資料倉庫之前需要經過系列計算,同時拋棄一些分析處理不需要的資料,
(3)穩定
操作型資料庫系統中一般只存盤短期資料,因此其資料是不穩定的,記錄的是系統中資料變化的瞬態,
資料倉庫中的資料大多表示過去某一時刻的資料,主要用于查詢、分析,不像業務系統中資料庫一樣經常修改,一般資料倉庫構建完成,主要用于訪問

OLTP 聯機事務處理
OLTP是傳統關系型資料庫的主要應用,主要用于日常事物、交易系統的處理
1、資料量存盤相對來說不大
2、實時性要求高,需要支持事物
3、資料一般存盤在關系型資料庫(oracle或mysql中)
OLAP 聯機分析處理
OLAP是資料倉庫的主要應用,支持復雜的分析查詢,側重決策支持
1、實時性要求不是很高,ETL一般都是T+1的資料;
2、資料量很大;
3、主要用于分析決策;
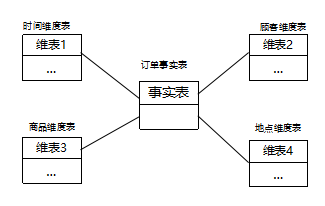
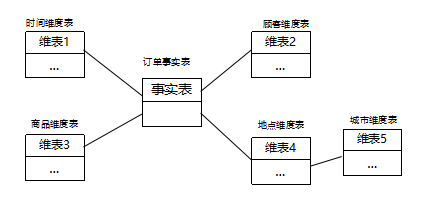
星形模型是最常用的資料倉庫設計結構,由一個事實表和一組維表組成,每個維表都有一個維主鍵,
該模式核心是事實表,通過事實表將各種不同的維表連接起來,各個維表中的物件通過事實表與另一個維表中的物件相關聯,這樣建立各個維表物件之間的聯系
維表:用于存放維度資訊,包括維的屬性和層次結構;
事實表:是用來記錄業務事實并做相應指標統計的表,同維表相比,事實表記錄數量很多
雪花模型是對星形模型的擴展,每一個維表都可以向外連接多個詳細類別表,除了具有星形模式中維表的功能外,還連接對事實表進行詳細描述的維度,可進一步細化查看資料的粒度
例如:地點維表包含屬性集{location_id,街道,城市,省,國家},這種模式通過地點維度表的city_id與城市維度表的city_id相關聯,得到如{101,“解放大道10號”,“武漢”,“湖北省”,“中國”}、{255,“解放大道85號”,“武漢”,“湖北省”,“中國”}這樣的記錄,
星形模型是最基本的模式,一個星形模型有多個維表,只存在一個事實表,在星形模式的基礎上,用多個表來描述一個復雜維,構造維表的多層結構,就得到雪花模型
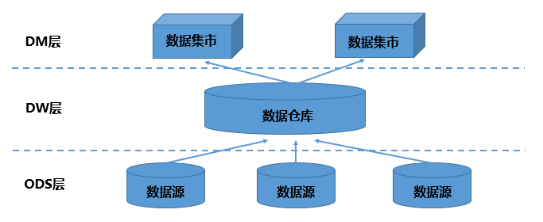
清晰資料結構:每一個資料分層都有它的作用域,這樣我們在使用表的時候能更方便地定位和理解
臟資料清洗:屏蔽原始資料的例外
屏蔽業務影響:不必改一次業務就需要重新接入資料
資料血緣追蹤:簡單來講可以這樣理解,我們最終給業務呈現的是能直接使用的一張業務表,但是它的來源有很多,如果有一張來源表出問題了,我們希望能夠快速準確地定位到問題,并清楚它的危害范圍,
減少重復開發:規范資料分層,開發一些通用的中間層資料,能夠減少極大的重復計算,
把復雜問題簡單化,將一個復雜的任務分解成多個步驟來完成,每一層只處理單一的步驟,比較簡單和容易理解,便于維護資料的準確性,當資料出現問題之后,可以不用修復所有的資料,只需要從有問題的步驟開始修復,
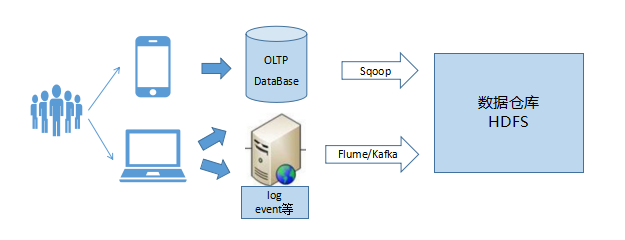
資料倉庫的資料直接對接OLAP或日志類資料,
用戶畫像只是站在用戶的角度,對資料倉庫資料做進一步的建模加工,因此每天畫像標簽相關資料的調度依賴上游資料倉庫相關任務執行完成,
在了解了資料倉庫以后,我們就可以進行標簽的計算了,在開發好標簽的邏輯以后,將資料寫入hive和druid中,完成實時與離線的標簽開發作業,
Flink Hive Druid
flink hive
Flink從1.9開始支持集成Hive,不過1.9版本為beta版,不推薦在生產環境中使用,在最新版Flink1.10版本,標志著對 Blink的整合宣告完成,隨著對 Hive 的生產級別集成,Hive作為資料倉庫系統的絕對核心,承擔著絕大多數的離線資料ETL計算和資料管理,期待Flink未來對Hive的完美支持,
而 HiveCatalog 會與一個 Hive Metastore 的實體連接,提供元資料持久化的能力,要使用 Flink 與 Hive 進行互動,用戶需要配置一個 HiveCatalog,并通過 HiveCatalog 訪問 Hive 中的元資料,
添加依賴
要與Hive集成,需要在Flink的lib目錄下添加額外的依賴jar包,以使集成在Table API程式或SQL Client中的SQL中起作用,或者,可以將這些依賴項放在檔案夾中,并分別使用Table API程式或SQL Client 的-C 或-l選項將它們添加到classpath中,本文使用第一種方式,即將jar包直接復制到$FLINK_HOME/lib目錄下,本文使用的Hive版本為2.3.4(對于不同版本的Hive,可以參照官網選擇不同的jar包依賴),總共需要3個jar包,如下:
- flink-connector-hive_2.11-1.10.0.jar
- flink-shaded-hadoop-2-uber-2.7.5-8.0.jar
- hive-exec-2.3.4.jar
添加Maven依賴
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<scope>provided</scope>
</dependency>
實體代碼
package com.flink.sql.hiveintegration;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.catalog.hive.HiveCatalog;
public class FlinkHiveIntegration {
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() // 使用BlinkPlanner
.inBatchMode() // Batch模式,默認為StreamingMode
.build();
//使用StreamingMode
/* EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() // 使用BlinkPlanner
.inStreamingMode() // StreamingMode
.build();*/
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive"; // Catalog名稱,定義一個唯一的名稱表示
String defaultDatabase = "qfbap_ods"; // 默認資料庫名稱
String hiveConfDir = "/opt/modules/apache-hive-2.3.4-bin/conf"; // hive-site.xml路徑
String version = "2.3.4"; // Hive版本號
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);
tableEnv.registerCatalog("myhive", hive);
tableEnv.useCatalog("myhive");
// 創建資料庫,目前不支持創建hive表
String createDbSql = "CREATE DATABASE IF NOT EXISTS myhive.test123";
tableEnv.sqlUpdate(createDbSql);
}
}
Flink Druid
可以將Flink分析好的資料寫回kafka,然后在druid中接入資料,也可以將資料直接寫入druid,以下為示例代碼:
依賴
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.8.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.flinkdruid</groupId>
<artifactId>FlinkDruid</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>FlinkDruid</name>
<description>Flink Druid Connection</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
示例代碼
@SpringBootApplication
public class FlinkDruidApp {
private static String url = "http://localhost:8200/v1/post/wikipedia";
private static RestTemplate template;
private static HttpHeaders headers;
FlinkDruidApp() {
template = new RestTemplate();
headers = new HttpHeaders();
headers.setAccept(Arrays.asList(MediaType.APPLICATION_JSON));
headers.setContentType(MediaType.APPLICATION_JSON);
}
public static void main(String[] args) throws Exception {
SpringApplication.run(FlinkDruidApp.class, args);
// Creating Flink Execution Environment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//Define data source
DataSet<String> data = https://www.cnblogs.com/tree1123/p/env.readTextFile("/wikiticker-2015-09-12-sampled.json");
// Trasformation on the data
data.map(x -> {
return httpsPost(x).toString();
}).print();
}
// http post method to post data in Druid
private static ResponseEntity httpsPost(String json) {
HttpEntity requestEntity =
new HttpEntity<>(json, headers);
ResponseEntity response =
template.exchange("http://localhost:8200/v1/post/wikipedia", HttpMethod.POST, requestEntity,
String.class);
return response;
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
標簽的開發作業繁瑣,需要不斷的開發并且優化,但是如何將做好的標簽提供出去產生真正的價值呢? 下一章,我們將介紹用戶畫像產品化,未完待續~
參考文獻
《用戶畫像:方法論與工程化解決方案》
更多實時資料分析相關博文與科技資訊,歡迎關注 “實時流式計算” 獲取用戶畫像相關資料 請關注 “實時流式計算” 回復 “用戶畫像”

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/3127.html
標籤:大數據
上一篇:滴滴HBase大版本滾動升級之旅