Kakfa在大資料訊息引擎領域,絕對是沒有爭議的國民老公,
這是kafka系列的第一篇文章,預計共出20篇系列文章,全部原創,從0到1,跟你一起死磕kafka,
本文盤點了 Kafka 的各種術語并且進行解讀,術語可能比較枯燥,但真的是精髓中的精髓!
了解Kafka之前我們必須先掌握它的相關概念和術語,這對于后面深入學習 Kafka 各種功能將大有裨益,所以,枯燥你也得給我看完!
大概是有這么些東西要掌握,不多不多,預計20分鐘可以吃透:
主題層
主題層有三個兒子,分別叫做:Topic、Partition、Replica,既然我說是三個兒子,那你懂了,是不可分割的整體,
Topic(主題)
Kafka 是分布式的訊息引擎系統,它的主要功能是提供一套完備的訊息(Message)發布與訂閱解決方案,
在 Kafka 中,發布訂閱的物件是主題(Topic),你可以為每個業務、每個應用甚至是每類資料都創建專屬的主題,
一個Topic是對一組訊息的歸納,也可以理解成傳統資料庫里的表,或者檔案系統里的一個目錄,
Partition(磁區)
一個Topic通常都是由多個partition組成的,創建topic時候可以指定partition數量,
?? 磁區優勢
為什么需要將Topic磁區呢?如果你了解其他分布式系統,你可能聽說過分片、磁區域等說法,比如 MongoDB 和 Elasticsearch 中的 Sharding、HBase 中的 Region,其實它們都是相同的原理,
試想,如果一個Topic積累了太多的資料以至于單臺 Broker 機器都無法容納了,此時應該怎么辦呢?
一個很自然的想法就是,能否把資料分割成多份保存在不同的機器上?這不就是磁區的作用嗎?其實就是解決伸縮性的問題,每個partition都可以放在獨立的服務器上,
當然優勢不僅于此,也可以提高吞吐量,kafka只允許單個partition的資料被一個consumer執行緒消費,因此,在consumer端,consumer并行度完全依賴于被消費的磁區數量,綜上所述,通常情況下,在一個Kafka集群中,partition的數量越多,意味著可以到達的吞吐量越大,
?? partition結構
每個partition對應于一個檔案夾,該檔案夾下存盤該partition的資料和索引檔案,
如圖所示,可以看到兩個檔案夾,都對應著一個叫做asd的topic,在該臺服務器上有兩個磁區,0和2,那么1呢?在其他服務器上啦!畢竟是分布式分布的!

我們進去asd-0目錄中看看是什么?有后綴為.index和.log的檔案,他們就是該partition的資料和索引檔案:
現在先不管它們是何方神圣,因為我會在【磁區機制原理】這篇文章中詳細描述,
?? partition順序性
現在,我需要你睜大眼睛看看關于磁區非常重要的一點:
【每個partition內部保證訊息的順序,但是磁區之間是不保證順序的】
這一點很重要,例如kafka中的訊息是某個業務庫的資料,mysql binlog是有先后順序的,10:01分我沒有付款,所以pay_date為null,而10:02分我付款了,pay_date被更新了,
但到了kafka那,由于是分布式的,多磁區的,可就不一定能保證順序了,也許10:02分那條先來,這樣可就會引發嚴重生產問題了,因此,一般我們需要按表+主鍵來磁區,保證同一主鍵的資料發送到同一個磁區中,
如果你想要 kafka 中的所有資料都按照時間的先后順序進行存盤,那么可以設定磁區數為 1,
Replica (副本)
每個partition可以配置若干個副本,Kafka 定義了兩類副本:領導者副本(Leader Replica)和追隨者副本(Follower Replica),只能有 1 個領導者副本和 N-1 個追隨者副本,
為啥要用副本?也很好理解,反問下自己為什么重要的檔案需要備份多份呢?備份機制(Replication)是實作高可用的一個手段,
需要注意的是:僅Leader Replica對外提供服務,與客戶端程式進行互動,生產者總是向領導者副本寫訊息,而消費者總是從領導者副本讀訊息,而Follower Replica不能與外界進行互動,它只做一件事:向領導者副本發送請求,請求領導者把最新生產的訊息發給它,保持與領導者的同步,
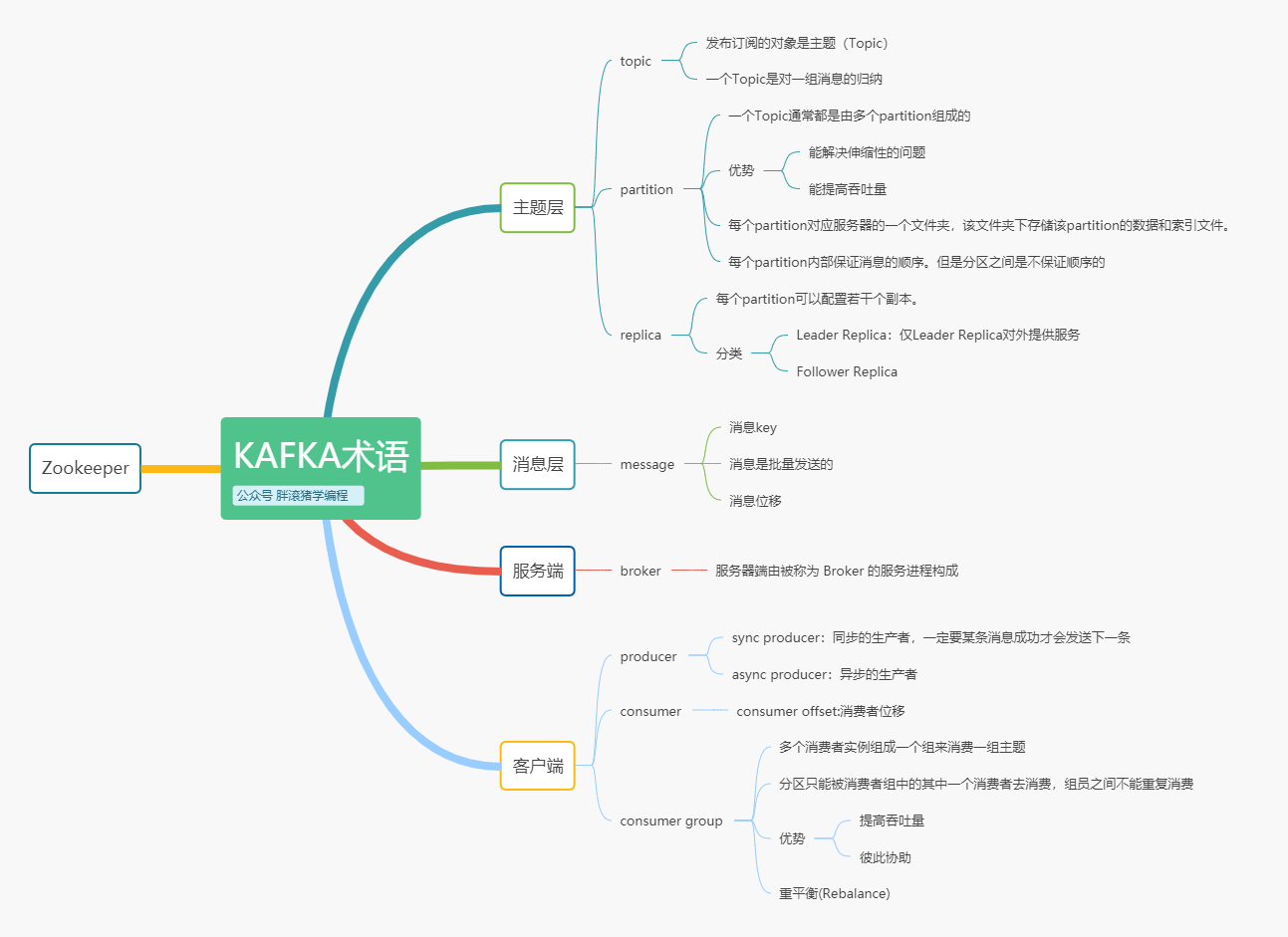
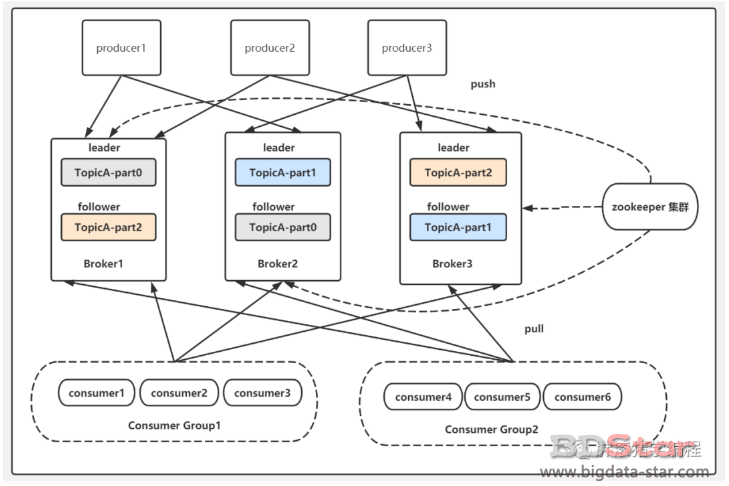
如果對于剛剛所說的主題、磁區、副本還有疑惑,那么結合下面這張圖再思考一下,我相信你就可以玩轉它了:
下圖所示,TopicA,具有三個partition,每個partion都有1 個leader副本和 1 個follower者副本,為了保證高可用性,一臺機器宕機不會有影響,因此leader副本和follower副本必然分布在不同的機器上,
訊息層
Kafka的官方定義是message system,由此我們可以知道Kafka 中最基本的資料單元無疑是訊息message,它可理解成資料庫里的一條行或者一條記錄,訊息是由字符陣列組成,關于訊息你必須知道這幾件事:
?? 訊息key
發送訊息的時候指定 key,這個 key 也是個字符陣列,key 用來確定訊息寫入磁區時,進入哪一個磁區,你可以用有明確業務含義的欄位作為key,比如用戶號,這樣就可以保證同一個用戶號進入同一個磁區,
?? 批量寫入
為了提高效率, Kafka 以批量batch的方式寫入,
一個 batch 就是一組訊息的集合, 這一組的資料都會進入同一個 topic 和 partition(這個是根據 producer 的配置來定的) ,
每一個訊息都進行一次網路傳輸會很消耗性能,因此把訊息收集到一起再同時處理就高效的多,
當然,這樣會引入更高的延遲以及吞吐量:batch 越大,同一時間處理的訊息就越多,batch 通常都會進行壓縮,這樣在傳輸以及存盤的時候效率都更高一些,
?? 位移
生產者向磁區寫入訊息,每條訊息在磁區中的位置資訊由一個叫位移(Offset)的資料來表征,磁區位移總是從 0 開始,假設一個生產者向一個空磁區寫入了 10 條訊息,那么這 10 條訊息的位移依次是 0、1、2、…、9,
服務端
Kafka 的服務器端由被稱為 Broker 的服務行程構成,即一個 Kafka 集群由多個 Broker 組成,Kafka支持水平擴展,broker數量越多,集群吞吐量越高,在集群中每個broker都有一個唯一brokerid,不得重復,Broker 負責接收和處理客戶端發送過來的請求,以及對訊息進行持久化,
一般會將不同的 Broker 分散運行在不同的機器上,這樣如果集群中某一臺機器宕機,kafka可以自動選舉出其他機器上的 Broker 繼續對外提供服務,這其實就是 Kafka 提供高可用的手段之一,
?? controller
Kafka集群中會有一個或者多個broker,其中有且僅有一個broker會被選舉為控制器(Kafka Controller),它負責管理整個集群中所有磁區和副本的狀態,
當某個磁區的leader副本出現故障時,由控制器負責為該磁區選舉新的leader副本,當檢測到某個磁區的ISR集合發生變化時,由控制器負責通知所有broker更新其元資料資訊,當為某個topic增加磁區數量時,同樣還是由控制器負責磁區的重新分配,
這幾句話可能會讓你覺得困惑不要方 只是突出下控制器的職能很多,而這些功能的具體細節會在后面的文章中做具體的介紹,
Kafka中的控制器選舉的作業依賴于Zookeeper,成功競選為控制器的broker會在Zookeeper中創建/controller這個臨時(EPHEMERAL)節點,此臨時節點的內容參考如下:
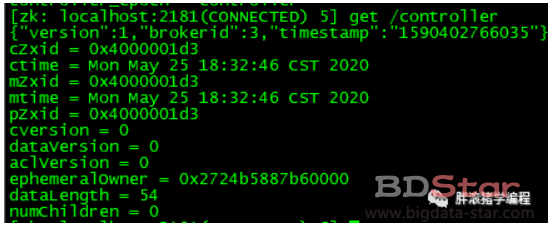
其中version在目前版本中固定為1,brokerid表示稱為控制器的broker的id編號,timestamp表示競選稱為控制器時的時間戳,
兩種客戶端
Kafka有兩種客戶端,生產者和消費者,我們把生產者和消費者統稱為客戶端(Clients),
向主題Topic發布訊息Message的客戶端應用程式稱為生產者(Producer),生產者程式通常持續不斷地向一個或多個主題發送訊息,
而訂閱這些主題訊息的客戶端應用程式就被稱為消費者(Consumer),和生產者類似,消費者也能夠同時訂閱多個主題的訊息,
Producer
Producer 用來創建Message,在發布訂閱系統中,他們也被叫做 Publisher 發布者或 writer 寫作者,
通常情況下,會發布到特定的Topic,并負責決定發布到哪個磁區(通常簡單的由負載均衡機制隨機選擇,或者通過key,或者通過特定的磁區函式選擇磁區,)
Producer分為Sync Producer 和 Aync Producer,
Sync Producer同步的生產者,即一定要某條訊息成功才會發送下一條,所以它是低吞吐率、一般不會出現資料丟失,
Aync Producer異步的生產者,有個佇列的概念,是直接發送到佇列里面,批量發送,高吞吐率、可能有資料丟失的,
Consumer 和 Consumer Group
?? 消費者
Consumer 讀取訊息,在發布訂閱系統中,也叫做 subscriber 訂閱者或者 reader 閱讀者,消費者訂閱一個或者多個主題,然后按照順序讀取主題中的資料,
?? 消費位移
消費者需要記錄消費進度,即消費到了哪個磁區的哪個位置上,這是消費者位移(Consumer Offset),注意,這和上面所說的訊息在磁區上的位移完全不是一個概念,上面的“位移”表征的是磁區內的訊息位置,它是不變的,即一旦訊息被成功寫入到一個磁區上,它的位移值就是固定的了,
而消費者位移則不同,它可能是隨時變化的,畢竟它是消費者消費進度的指示器嘛,通過存盤最后消費的 Offset,消費者應用在重啟或者停止之后,還可以繼續從之前的位置讀取,保存的機制可以是 zookeeper,或者 kafka 自己,
?? 消費者組
ConsumerGroup:消費者組,指的是多個消費者實體組成一個組來消費一組主題,磁區只能被消費者組中的其中一個消費者去消費,組員之間不能重復消費,
為什么要引入消費者組呢?主要是為了提升消費者端的吞吐量,多個消費者實體同時消費,加速整個消費端的吞吐量(TPS),
當然它的作用不僅僅是瓜分訂閱主題的資料,加速消費,它們還能彼此協助,假設組內某個實體掛掉了,Kafka 能夠自動檢測到,然后把這個 Failed 實體之前負責的磁區轉移給其他活著的消費者,這個程序稱之為重平衡(Rebalance),
你務必先把這個詞記住,它是kafka大名鼎鼎的重平衡機制,生產出現的例外問題很多都是由于它導致的,后續我會在【kafka大名鼎鼎又臭名昭著的重平衡】文章中詳細分析,
Zookeeper
zookeeper目前在kafka中扮演著舉重輕重的角色和作用~是kafka不可缺少的一個組件,
目前,Apache Kafka 使用 Apache ZooKeeper 來存盤它的元資料,比如brokers資訊、磁區的位置和主題的配置等資料就是存盤在 ZooKeeper 集群中,
注意我的用詞,我只說是目前,why?在 2019 年社區提出了一個計劃,以打破這種依賴關系,并將元資料管理引入 Kafka 本身,因為擁有兩個系統會導致大量的重復,
在之前的設計中,我們至少需要運行三個額外的 Java 行程,有時甚至更多,事實上,我們經常看到具有與 Kafka 節點一樣多的 ZooKeeper 節點的 Kafka 集群!此外,ZooKeeper 中的資料還需要快取在 Kafka 控制器上,這導致了雙重快取,
更糟糕的是,在外部存盤元資料限制了 Kafka 的可伸縮性,當 Kafka 集群啟動時,或者一個新的控制器被選中時,控制器必須從 ZooKeeper 加載集群的完整狀態,隨著元資料數量的增加,加載程序需要的時間也會增加,這限制了 Kafka 可以存盤的磁區數量,
最后,將元資料存盤在外部會增加控制器的記憶體狀態與外部狀態不同步的可能性,
因此,未來,Kafka 的元資料將存盤在 Kafka 本身中,而不是存盤在 ZooKeeper 之類的外部系統中,可以持續關注kafka社區動態哦!
總結
一個典型的kafka集群包含若干個producer(向主題發布新訊息),若干consumer(從主題訂閱新訊息,用Consumer Offset表征消費者消費進度),cousumergroup(多個消費者實體共同組成的一個組,共同消費多個磁區),若干broker(服務器端行程),還有zookeeper,
kafka發布訂閱的物件叫主題,每個Topic下可以有多個Partition,Partition中每條訊息的位置資訊又叫做訊息位移(Offset),Partition有副本機制,使得同一條訊息能夠被拷貝到多個地方以提供資料冗余,副本分為領導者副本和追隨者副本,
可以用下面這張圖來形象表達kafka的組成:
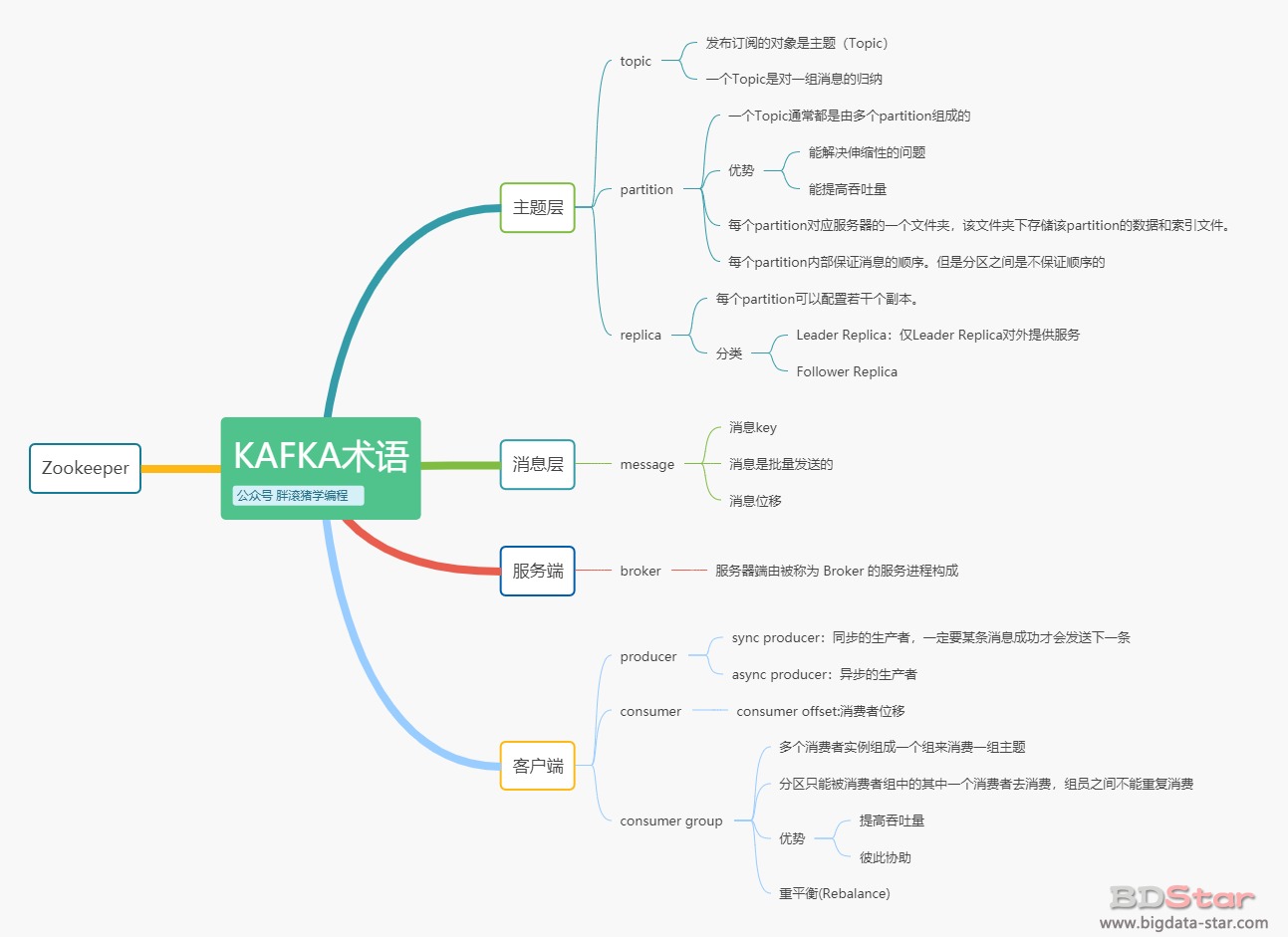
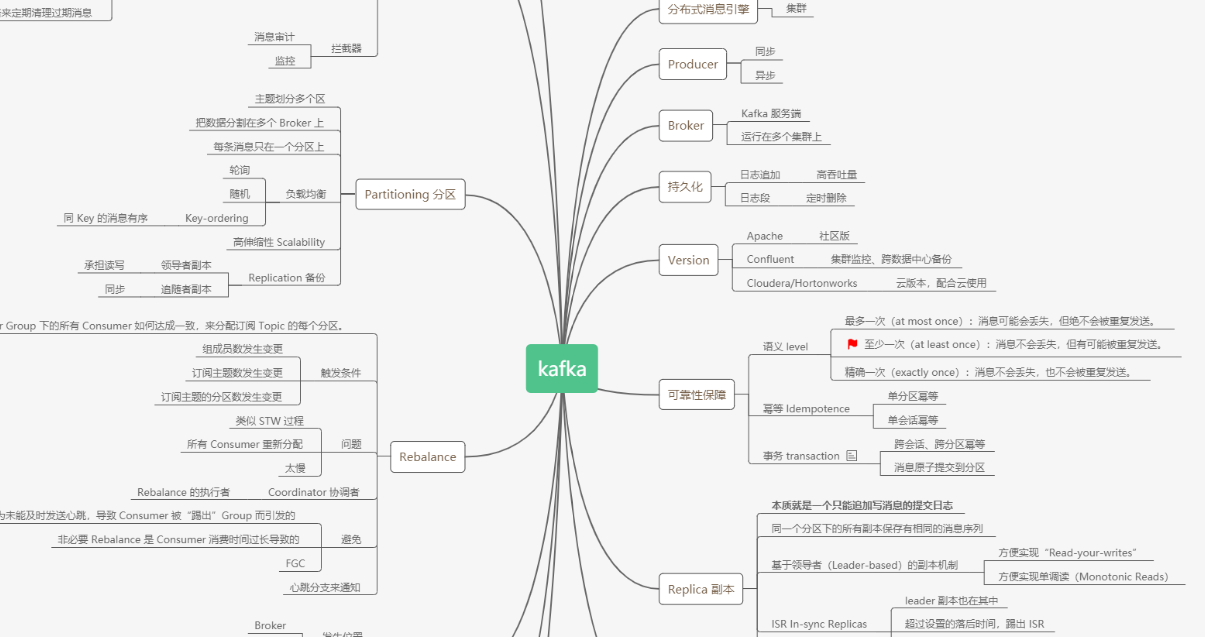
另外,再po一張思維導圖助你回顧本文所述的術語,
重要!!關注【胖滾豬學編程】公眾號發送"kafka",獲取本文所有架構圖以及Kafka全系列思維導圖!

本文來源于公眾號:【胖滾豬學編程】,一枚集顏值與才華于一身,不算聰明卻足夠努力的女程式媛,用漫畫形式讓編程so easy and interesting!求關注!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/3134.html
標籤:大數據
下一篇:大資料技術堆疊,主要有哪些