1.ROWNUM:
概念:OORACLE使用ROWNUM是一個偽列,資料庫提取記錄才會生成的數值1,2,3,4 作用是用于實作ORACLE的分頁必須使用子查 詢實作
執行流程(帶條件) : a.查詢EMPLOYEES表,生成EMOLYEES偽列
b.根據分頁條件判斷該ROWNUM是否與該條件匹配
c.條件匹配,取出該條條件
d.生成第二個ROWNUM重復r操作
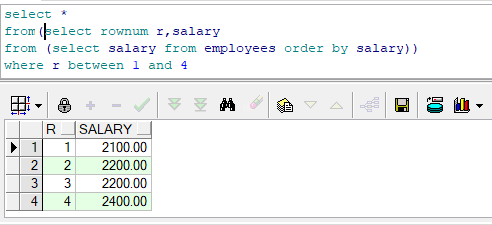
2.別名問題
由于ROWNUM的WHERE判斷執行在SELECT關鍵字之前。當前查詢中的ROWNUM別名不能用于條件做判斷,別名只可以用一外部條件判斷
3.ROWID是資料庫保存記錄時候生成的真實物理地址,唯一不變
作用:資料庫操作記錄使用
索引值→ROWID→將ROWID換成算成一行資料的物理地址→得到一行資料
如:提取員工表的前三行資料
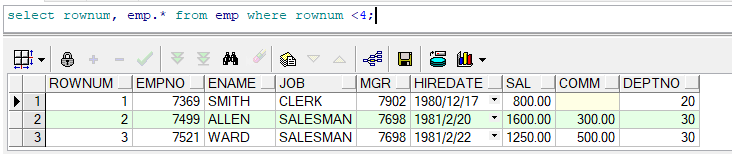
如:提取4行之后的資料
錯誤例子:SELECT ROWNUM,EMP.* FROM EMP WHERE ROWNUM > 3 --錯誤
生成第一個ROWNUM,進行條件判斷是不符合,無法提取結果,結果為NULL
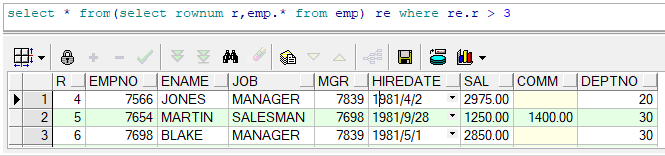
解決方案:先查詢帶ROWNUM的偽表SELECT ROWNUM,EMP.* FROM EMP查詢偽表,選出4條以后的資料SELECT * FROM(SELECT ROWNUM R,EMP.* FROM EMP) RE WHERE RE.R > 3
1.提取工資排行前三的員工
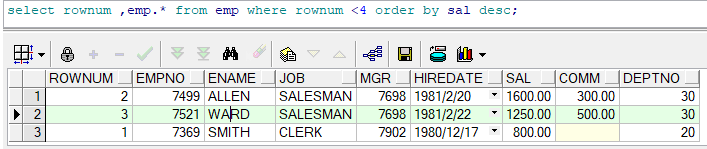
雖然查詢了結果,但是似乎并不是前工資排名前三的員工,
原因分析:WHERE條件的執行在ORACLE BY 之前,頁就是先生成了ROWNUM之后才進行,顯然者時候序號已經生成好
正確的是SELECT * FROM EMP ORACLE BY SALARY DESC先排序,SELECT ROWNUM,E.* FROM (SELECT * FROM EMP ORACLE BY SAL DESC) E WHERE ROWNUM BETWEEN 1 AND 4
2.提取6到10的記錄資料效率
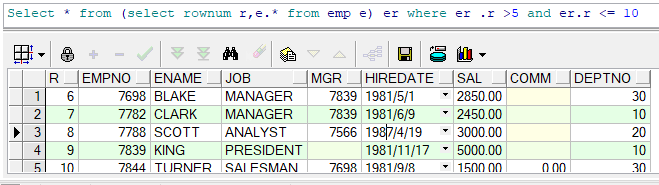
我要提取的資料是6到10之前的資料,把不需要用到的資料過濾掉,提高效率后的寫法,只進行提取分頁(表資料多是效率會極低)。
如圖下。
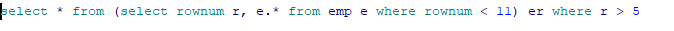
uj5u.com熱心網友回復:
總結的挺好!
uj5u.com熱心網友回復:
加到 100,好招點人過來。
uj5u.com熱心網友回復:
問個問題
下面這個陳述句怎么優化到秒出(假設:emp表上千萬,滿足deptno條件的過五百萬):
SELECT * FROM (SELECT rownum rn, emp.* FROM EMP WHERE DEPTNO='DEVELOPER' ORACLE BY SAL DESC ) WHERE ROWNUM <= 20
uj5u.com熱心網友回復:
那個,拷貝的時候沒注意,where條件后的ORACLE BY應該是ORDER BY……uj5u.com熱心網友回復:
加了 deptno, sal 的聯合索引后,應該很快能出結果。
uj5u.com熱心網友回復:
其實不一定
uj5u.com熱心網友回復:
舉個例子,最好貼一下你的執行程序。
uj5u.com熱心網友回復:
例子可以舉一個,當然比較極端,如果表里有資料同時deptno,sal為空,那么這條索引沒法用到這種分頁SQL中,當然從業務上來講,這個不可能,但是如果這兩個欄位上都沒有not null約束,或者主鍵約束,那么即使業務上資料不可能全為空,oracle還是不會選擇這條索引。
uj5u.com熱心網友回復:
-- 這個實驗結果,你還滿意不
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0
Connected as [email protected]/test
SQL>
SQL> set timing on;
SQL> drop index ix_emp;
drop index ix_emp
ORA-01418: 指定的索引不存在
SQL> select count(*) from emp;
COUNT(*)
----------
14221312
Executed in 2.886 seconds
SQL> select count(*) from emp where deptno is null;
COUNT(*)
----------
819200
Executed in 2.366 seconds
SQL> select count(*) from emp where sal is null;
COUNT(*)
----------
6094848
Executed in 2.861 seconds
SQL> select count(*) from emp where deptno = 'DEV';
COUNT(*)
----------
7700480
Executed in 2.548 seconds
SQL> select count(*) from ind where table_name = 'EMP';
COUNT(*)
----------
0
Executed in 0.037 seconds
SQL> explain plan for SELECT * FROM
2 (SELECT rownum rn, emp.* FROM EMP WHERE DEPTNO='DEV' ORDER BY SAL DESC )
3 WHERE ROWNUM <= 20;
Explained
Executed in 0.015 seconds
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1035293170
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Ti
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20 | 10740 | | 841K (1)| 02
|* 1 | COUNT STOPKEY | | | | | |
| 2 | VIEW | | 6401K| 3278M| | 841K (1)| 02
|* 3 | SORT ORDER BY STOPKEY| | 6401K| 3198M| 4167M| 841K (1)| 02
| 4 | COUNT | | | | | |
|* 5 | TABLE ACCESS FULL | EMP | 6401K| 3198M| | 132K (1)| 00
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(ROWNUM<=20)
3 - filter(ROWNUM<=20)
5 - filter("DEPTNO"='DEV')
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
23 rows selected
Executed in 0.213 seconds
SQL> rollback;
Rollback complete
Executed in 0.002 seconds
SQL> SELECT * FROM
2 (SELECT rownum rn, emp.* FROM EMP WHERE DEPTNO='DEV' ORDER BY SAL DESC )
3 WHERE ROWNUM <= 20;
-- 這里的資料我洗掉了
20 rows selected
Executed in 7.728 seconds
SQL> create index ix_emp on emp(deptno, sal);
Index created
Executed in 16.774 seconds
SQL> exec dbms_stats.gather_table_stats(user,'EMP',cascade => true);
PL/SQL procedure successfully completed
Executed in 16.812 seconds
SQL> explain plan for SELECT * FROM
2 (SELECT rownum rn, emp.* FROM EMP WHERE DEPTNO='DEV' ORDER BY SAL DESC )
3 WHERE ROWNUM <= 20;
Explained
Executed in 0.006 seconds
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 2189114292
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20 | 10740 | 18 (0)|
|* 1 | COUNT STOPKEY | | | | |
| 2 | VIEW | | 20 | 10740 | 18 (0)|
| 3 | COUNT | | | | |
| 4 | TABLE ACCESS BY INDEX ROWID | EMP | 7714K| 1611M| 18 (0)|
|* 5 | INDEX RANGE SCAN DESCENDING| IX_EMP | 20 | | 3 (0)|
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(ROWNUM<=20)
5 - access("DEPTNO"='DEV')
18 rows selected
Executed in 0.194 seconds
SQL> rollback;
Rollback complete
Executed in 0.002 seconds
SQL> SELECT * FROM
2 (SELECT rownum rn, emp.* FROM EMP WHERE DEPTNO='DEV' ORDER BY SAL DESC )
3 WHERE ROWNUM <= 20;
-- 這里的資料我洗掉了
20 rows selected
Executed in 0.364 seconds
SQL>
uj5u.com熱心網友回復:
看上一樓
uj5u.com熱心網友回復:
是我想茬了,因為已經有了where deptno='DEV'這個條件……

uj5u.com熱心網友回復:
關于分頁查詢,有一個必須注意的問題,就是先排序,再取行,否則會有問題。另外,分頁中用到的大于號小于號,有點過時了,應該用BETWEEN。
uj5u.com熱心網友回復:
用between代碼倒是好看了,性能完了。
排序也是,排序了就需要額外的優化手段。如果你說的問題是翻頁后資料重復的問題,那么排序還需要加在唯一性很好的欄位上。
uj5u.com熱心網友回復:
這兩種寫法,幾乎是在同一時間出現的。
從性能上來講,這兩種分頁查詢的差異表現如下:
between 的寫法,查詢每頁的時間是一樣的。
先 小于,再大于的寫法,第一頁的速度是最快的,第二頁要慢一些,第三頁再慢一些,最后一頁的性能和 between是一樣的。
uj5u.com熱心網友回復:
我看視頻測驗結果 用 rowid 時 最快uj5u.com熱心網友回復:
select *from emp
where rowid in (select rid
from (select rownum rn, rid
from (select rowid rid from emp)
where rownum < 5)
where rn > = 2)
uj5u.com熱心網友回復:
分頁的查詢 ,基本上都會有對特定欄位排序的需求。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/31346.html
標籤:基礎和管理
上一篇:ogg抽取延時5-10秒