我試圖通過計算匹配元素的數量來計算集合與集合中所有其他集合的相似程度。獲得計數后,我想對前 X 個(當前為 100 個)相似集(計數最高的那些)對每個集執行進一步的操作。我提供了一個示例輸入和一個輸出,它顯示了針對兩個集合的匹配元素的計數:
輸入
{
"list1": [
"label1",
"label2",
"label3"
],
"list2": [
"label2",
"label3",
"label4"
],
"list3": [
"label3",
"label4",
"label5"
],
"list4": [
"label4",
"label5",
"label6"
]
}
輸出
{
"list1": {
"list1": 3,
"list2": 2,
"list3": 1,
"list4": 0
},
"list2": {
"list1": 2,
"list2": 3,
"list3": 2,
"list4": 1
},
"list3": {
"list1": 1,
"list2": 2,
"list3": 3,
"list4": 2
},
"list4": {
"list1": 0,
"list2": 1,
"list3": 2,
"list4": 3
}
}
我想出了以下代碼,但輸入大約 200,000 組需要幾個小時。集合中元素/標簽的數量各不相同,但平均每個集合中大約有 10 個元素。唯一標簽值的總數約為 300。
input = {}
input['list1'] = ['label1', 'label2', 'label3']
input['list2'] = ['label2', 'label3', 'label4']
input['list3'] = ['label3', 'label4', 'label5']
input['list4'] = ['label4', 'label5', 'label6']
print(json.dumps(input, indent=2))
input = {key: set(value) for key, value in input.items()}
output = {key1: {key2: 0 for key2 in input.keys()} for key1 in input.keys()}
for key1, value1 in input.items():
for key2, value2 in input.items():
for element in value1:
if element in value2:
count = output[key1][key2]
output[key1][key2] = count 1
print(json.dumps(output, indent=2))
有沒有人對如何在集數較大的情況下提高上述代碼的執行時間有任何想法?
感謝您的任何建議!
uj5u.com熱心網友回復:
使用倒排索引來避免與那些交集基數為 0 的集合計算交集:
from collections import defaultdict, Counter
from itertools import chain
from pprint import pprint
data = {
"list1": ["label1", "label2", "label3"],
"list2": ["label2", "label3", "label4"],
"list3": ["label3", "label4", "label5"],
"list4": ["label4", "label5", "label6"]
}
index = defaultdict(list)
for key, values in data.items():
for value in values:
index[value].append(key)
result = {key: Counter(chain.from_iterable(index[label] for label in labels)) for key, labels in data.items()}
pprint(result)
輸出
{'list1': Counter({'list1': 3, 'list2': 2, 'list3': 1}),
'list2': Counter({'list2': 3, 'list1': 2, 'list3': 2, 'list4': 1}),
'list3': Counter({'list3': 3, 'list2': 2, 'list4': 2, 'list1': 1}),
'list4': Counter({'list4': 3, 'list3': 2, 'list2': 1})}
如果嚴格需要,您可以包含具有0交集基數的集合,如下所示:
result = {key: {k: value.get(k, 0) for k in data} for key, value in result.items()}
pprint(result)
輸出
{'list1': {'list1': 3, 'list2': 2, 'list3': 1, 'list4': 0},
'list2': {'list1': 2, 'list2': 3, 'list3': 2, 'list4': 1},
'list3': {'list1': 1, 'list2': 2, 'list3': 3, 'list4': 2},
'list4': {'list1': 0, 'list2': 1, 'list3': 2, 'list4': 3}}
第二種選擇來自觀察,大多數時間都致力于尋找集合的交集,因此更快的資料結構(如咆哮位圖)很有用:
from collections import defaultdict
from pprint import pprint
from pyroaring import BitMap
data = {
"list1": ["label1", "label2", "label3"],
"list2": ["label2", "label3", "label4"],
"list3": ["label3", "label4", "label5"],
"list4": ["label4", "label5", "label6"]
}
# all labels
labels = set().union(*data.values())
# lookup mapping to an integer
lookup = {key: value for value, key in enumerate(labels)}
roaring_data = {key: BitMap(lookup[v] for v in value) for key, value in data.items()}
result = defaultdict(dict)
for k_out, outer in roaring_data.items():
for k_in, inner in roaring_data.items():
result[k_out][k_in] = len(outer & inner)
pprint(result)
輸出
defaultdict(<class 'dict'>,
{'list1': {'list1': 3, 'list2': 2, 'list3': 1, 'list4': 0},
'list2': {'list1': 2, 'list2': 3, 'list3': 2, 'list4': 1},
'list3': {'list1': 1, 'list2': 2, 'list3': 3, 'list4': 2},
'list4': {'list1': 0, 'list2': 1, 'list3': 2, 'list4': 3}})
性能分析
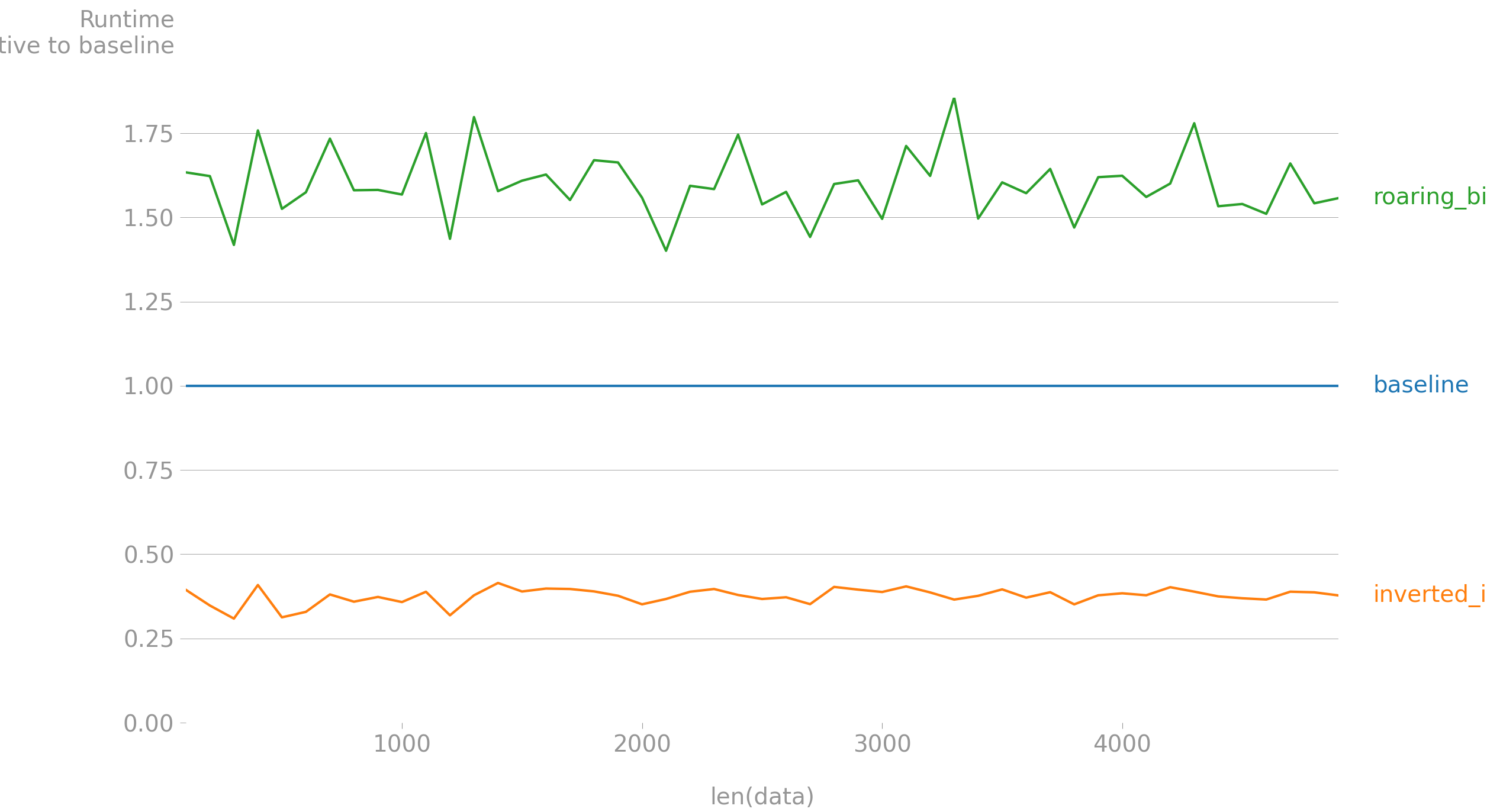
上圖顯示了data長度由x軸的值給出的字典的性能,字典的每個值都是從 100 個群體中隨機采樣的 10 個標簽的串列。 與直覺相反,咆哮位圖的性能比您的解決方案差,而使用倒排索引花費的時間不到一半(大約 40%)。可以在此處找到重現上述結果的代碼
uj5u.com熱心網友回復:
假設大多數串列對沒有交集,下面的代碼應該更快。如果它不夠快,并且近似結果還可以,那么您可以嘗試最小散列(將 k 設定為較低的值以獲得更快的速度,較高的值以獲得更多的召回)。
input = {
"list1": ["label1", "label2", "label3"],
"list2": ["label2", "label3", "label4"],
"list3": ["label3", "label4", "label5"],
"list4": ["label4", "label5", "label6"],
}
import collections
import hashlib
def optional_min_hash(values, k=None):
return (
values
if k is None
else sorted(
hashlib.sha256(str(value).encode("utf8")).digest() for value in values
)[:k]
)
buckets = collections.defaultdict(list)
for key, values in input.items():
for value in optional_min_hash(values):
buckets[value].append(key)
output = collections.defaultdict(dict)
for key1, key2 in {
(key1, key2)
for bucket in buckets.values()
for key1 in bucket
for key2 in bucket
if key1 <= key2
}:
count = len(set(input[key1]) & set(input[key2]))
output[key1][key2] = count
output[key2][key1] = count
print(output)
示例輸出:
defaultdict(<class 'dict'>, {'list2': {'list4': 1, 'list1': 2, 'list2': 3, 'list3': 2}, 'list4': {'list2': 1, 'list4': 3, 'list3': 2}, 'list1': {'list2': 2, 'list3': 1, 'list1': 3}, 'list3': {'list1': 1, 'list2': 2, 'list3': 3, 'list4': 2}})
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/313570.html