西北望鄉何處是,東南見月幾回圓,
月亮又慢悠悠的掛上了天空,趁著睡前夢囈,我就帶領各位可愛的讀者們探索MySql最后的子查詢部分,
說明:有些查詢結果出來結果截圖與題目要求不一樣會出現多余的欄位是為了方便展示結果的可讀性,實際操作的讀者可以洗掉SELECT后面多余的欄位得到正確的結果,
#WHERE或HAVING后面
#1.標量子查詢(單行子查詢)
#2.列子查詢(多行子查詢)
#3.行子查詢(多列多行)
#特點:
# ①子查詢放在小括號內
# ②子查詢一般放在條件的右側
# ③標量子查詢:一般搭配著單行運算子使用
# 單行運算子: > < >= <= <> !-
# 列子查詢,一般搭配著多行運算子使用
# IN,ANY/SOME(任意),ALL
# ④子查詢的執行優先與主查詢執行,主查詢的條件用到了子查詢的結果,
#1.標量子查詢
#案例1:誰的工資比Abel高?
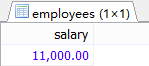
#①查詢Abel的工資
SELECT salary
FROM employees
WHERE last_name = 'Abel';
#②查詢員工的資訊,滿足Salary>①結果
SELECT *
FROM employees
WHERE salary>(SELECT salary FROM employees WHERE last_name='Abel');
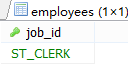
#案例2.回傳job_id與141號員工相同,salary比143號員工多的員工姓名,job_id,工資,
#①查141員工的job_id
SELECT job_id
FROM employees
WHERE employee_id='141';
#②查143員工的salary
SELECT salary
FROM employees
WHERE employee_id='143';
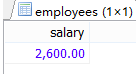
#③最后合并結果 SELECT CONCAT(last_name,first_name) AS 姓名, job_id AS 工種編號, salary AS 工資 FROM employees WHERE job_id=( SELECT job_id FROM employees WHERE employee_id='141' ) AND salary>( SELECT salary FROM employees WHERE employee_id='143' );
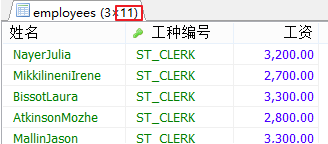
#案例3.回傳公司工資最少的員工的last_name,job_id和salary,
SELECT MIN(salary)
FROM employees;
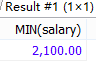
SELECT
last_name AS 姓,
salary AS 工資,
job_id AS 工種編號
FROM employees
WHERE salary=(
SELECT MIN(salary)
FROM employees
);
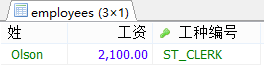
#案例4.查詢最低工資大于50號部門最低工資的部門id和其最低工資,
#①查50部門的最低工資
SELECT MIN(salary)
FROM employees
WHERE department_id=50;
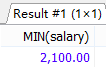
#分組后,篩選條件①.【不用排除沒有部門的所以不篩選部門編號】
SELECT department_id AS 部門編號,
MIN(salary) AS 月薪
FROM employees
#WHERE department_id
GROUP BY department_id
HAVING 月薪>(
SELECT MIN(salary)
FROM employees
);
#2.列子查詢(多行子查詢)
#回傳多行
#使用多行比較運算子

#案例1.回傳location_id是1400或1700的部門中的所有員工姓名,
#①查詢location_id是1400或1700的部門編號
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700);
#②查詢員工姓名,要求部門號是①串列的某一個
SELECT CONCAT(last_name,first_name) AS 姓名
FROM employees
WHERE department_id IN (
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
用ANY替代IN與上面同樣的結果
SELECT CONCAT(last_name,first_name) AS 姓名
FROM employees
WHERE department_id = ANY(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
#案例.回傳location_id不是1400或1700的部門中的所有員工姓名, SELECT CONCAT(last_name,first_name) AS 姓名 FROM employees WHERE department_id NOT IN( SELECT DISTINCT department_id FROM departments WHERE location_id IN(1400,1700) ); ============================== SELECT CONCAT(last_name,first_name) AS 姓名 FROM employees WHERE department_id <> ALL( SELECT DISTINCT department_id FROM departments WHERE location_id IN(1400,1700) );
#案例2.回傳其他工種中比job_id為IT_PROG部門任意一工資低的員工工號,
# 姓名,job_id以及salary
#①把IT_PROG部門中的工資查出來
SELECT DISTINCT salary
FROM employees
WHERE job_id='IT_PROG';
#②把不是IT_PROG部門資訊查出來
SELECT *
FROM employees
WHERE job_id != 'IT_PROG';

#③合并①與②在員工表中查出來
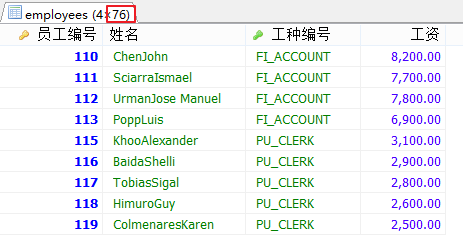
SELECT employee_id AS 員工編號,
CONCAT(last_name,first_name) AS 姓名,
job_id AS 工種編號,
salary AS 工資
FROM employees
WHERE job_id != 'IT_PROG'
AND salary<ANY(
SELECT salary
FROM employees
WHERE job_id='IT_PROG'
);
用MAX代替ANY與上面同樣的效果
SELECT employee_id AS 員工編號,
CONCAT(last_name,first_name) AS 姓名,
job_id AS 工種編號,
salary AS 工資
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary<(
SELECT MAX(salary)
FROM employees
WHERE job_id='IT_PROG'
);
#案例3.回傳其他部門中比job_id為‘IT_PROG’部門所有工資都低的員工
#的員工號,姓名,job_id以及salary,
#①先把IT_PROG部門的工資查出來,
SELECT DISTINCT salary
FROM employees
WHERE job_id='IT_PROG';
SELECT employee_id AS 員工號,
CONCAT(last_name,first_name) AS 姓名,
job_id AS 工種編號,
salary AS 工資
FROM employees
WHERE salary<ALL(
SELECT DISTINCT salary
FROM employees
WHERE job_id='IT_PROG'
)
AND job_id <> 'IT_PROG';
=============================
MIN替代ALL
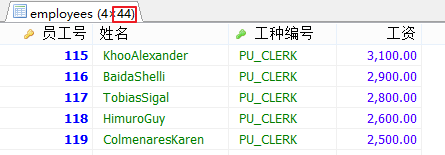
SELECT employee_id AS 員工號,
CONCAT(last_name,first_name) AS 姓名,
job_id AS 工種編號,
salary AS 工資
FROM employees
WHERE salary<(
SELECT MIN(salary)
FROM employees
WHERE job_id='IT_PROG'
)
AND job_id <> 'IT_PROG';
#3.行子查詢(結果集一行多列或者多行多列)
#案例1.查詢員工編號最小并且工資最高的員工資訊.引入
SELECT MIN(employee_id)
FROM employees;
=================
SELECT MAX(salary)
FROM employees;
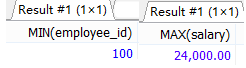
SELECT *
FROM employees
WHERE employee_id = (
SELECT MIN(employee_id)
FROM employees
)
AND salary = (
SELECT MAX(salary)
FROM employees
);

這種查詢結果使用虛擬欄位,單行運算子必須一致可以使用,查出來與上面同樣的效果, SELECT * FROM employees WHERE (employee_id,salary)=( SELECT MIN(employee_id), MAX(salary) FROM employees );
#二.SELECT子查詢 #僅僅支持標量子查詢,結果是一行一列 #案例1.查詢每個部門的員工個數 SELECT d.*,(SELECT COUNT(*) FROM employees) FROM departments d;
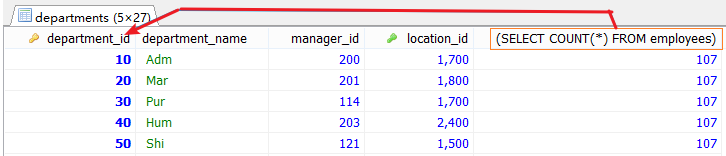
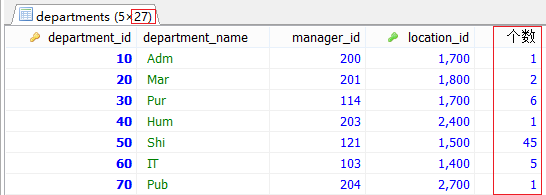
添加條件 SELECT d.*,(SELECT COUNT(*) FROM employees e WHERE e.department_id=d.department_id ) AS 個數 FROM departments d;
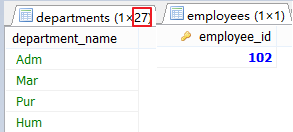
#案例2.查詢員工號=102的部門名,
SELECT department_name
FROM departments;
==============
SELECT employee_id
FROM employees
WHERE employee_id = 102;
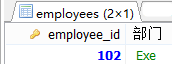
SELECT employee_id,
(
SELECT department_name
FROM departments d
WHERE e.department_id=d.department_id
)
FROM employees e
WHERE employee_id=102;
#三.FROM 后面
注意:將子查詢結果充當一張表,要求必須起別名
#案例:查詢每個部門的平均工資等級,
SELECT ROUND(AVG(salary),2),department_id
FROM employees
GROUP BY department_id;
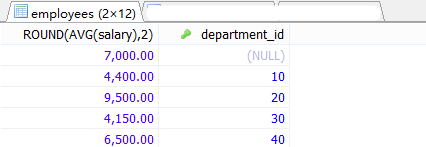
SELECT e.平均工資,j.grade_level
FROM job_grades AS j
,(
SELECT ROUND(AVG(salary),2) AS 平均工資,department_id
FROM employees
GROUP BY department_id
) AS e
WHERE e.平均工資 BETWEEN j.lowest_sal AND j.highest_sal;
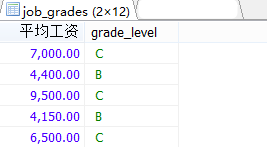
#1999語法,老師答案
SELECT e.*,j.grade_level
FROM (
SELECT ROUND(AVG(salary),2) AS 平均工資,department_id
FROM employees
GROUP BY department_id
) AS e
INNER JOIN job_grades j
ON e.平均工資 BETWEEN j.lowest_sal AND j.highest_sal;
#四.EXISTS后面(相關子查詢)
語法:EXISTS(完整的查詢陳述句)
備注:完整的查詢陳述句可以是一行一列,可以使一行多列
注意:先走外查詢,然后根據某個欄位的值再去過濾
EXISTS 判斷(布爾型別)值存不存在,結果只有兩種:1有,0沒有
#引入
SELECT EXISTS(SELECT employee_id FROM employees);

查詢工資3W的員工資訊
SELECT EXISTS(SELECT * FROM employees WHERE salary=30000);

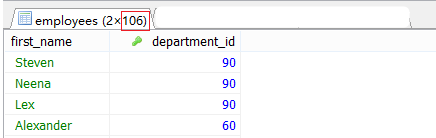
#案例引入.查詢員工名和部門名
#查員工名與部門編號
SELECT first_name,department_id
FROM employees
WHERE department_id;
#查部門名
SELECT department_name
FROM departments;
#查員工名與部門名
SELECT e.first_name,d.department_name
FROM employees e
INNER JOIN ( SELECT department_name,department_id
FROM departments
) AS d
ON e.department_id=d.department_id;
#案例1..查有員工的部門名
SELECT department_name
FROM departments d
WHERE EXISTS(
SELECT *
FROM employees e
WHERE d.department_id=e.department_id
);
使用IN代替EXISTS,同樣是上面的結果
SELECT department_name
FROM departments d
WHERE d.department_id IN(
SELECT department_id
FROM employees
);
#案例2.查詢沒有女朋友的男神資訊
#IN方法
SELECT *
FROM boys bo
WHERE bo.id NOT IN(
SELECT boyfriend_id
FROM beauty be
);
===============
#EXISTS方法
SELECT *
FROM boys bo
WHERE NOT EXISTS(
SELECT boyfriend_id
FROM beauty be
WHERE bo.id=be.boyfriend_id
);
進階9:聯合查詢 UNION 聯合 合并:將多條查詢陳述句的結果合并成一個結果, 語法: 查詢陳述句1 UNION 查詢陳述句2 UNION ... 應用場景: 要查詢的結果來自于多個表,且多個表沒有直接的連接關系, 但查詢資訊一致時, 網頁搜索內容,內容從不同的表中檢索聯合起來回傳給用戶, 特點: 1.要求多條查詢陳述句的查詢列數是一致的, 2.要求多條查詢陳述句的查詢的每一列的型別和順序最好一致, 3.使用UNION關鍵字默認去重,如果使用UNION ALL全部展示,包含重復項
#引入案例1.:查詢部門編號>90或者郵箱包含A的員工資訊
SELECT * FROM employees
WHERE email LIKE '%a%' OR department_id>90;
聯合查詢
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;

感謝能認真讀到這里的伙伴們,MySql查詢部分結束,相信螢屏前的你照著我博客里的模板可以完成一些簡單的SQL查詢陳述句,SQL既然學了,以后還是要多練習一下,SQL1992與1999語法在主流的關系型資料庫都是通用的,后續我會繼續進行對MySql的知識進行擴展,感興趣的同志互相關注一唄!o(^▽^)o
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/3151.html
標籤:MySQL