索引的簡介:
索引分為聚集索引和非聚集索引,資料庫中的索引類似于一本書的目錄,在一本書中通過目錄可以快速找到你想要的資訊,而不需要讀完全書,
索引主要目的是提高了SQL Server系統的性能,加快資料的查詢速度與減少系統的回應時間 ,
但是索引對于提高查詢性能也不是萬能的,也不是建立越多的索引就越好,索引建少了,用 WHERE 子句找資料效率低,不利于查找資料,索引建多了,不利于新增、修改和洗掉等操作,因為做這些操作時,SQL SERVER 除了要更新資料表本身,還要連帶立即更新所有的相關索引,而且過多的索引也會浪費硬碟空間,
索引的分類:
索引就類似于中文字典前面的目錄,按照拼音或部首都可以很快的定位到所要查找的字,
唯一索引(UNIQUE):每一行的索引值都是唯一的(創建了唯一約束,系統將自動創建唯一索引)
主鍵索引:當創建表時指定的主鍵列,會自動創建主鍵索引,并且擁有唯一的特性,
聚集索引(CLUSTERED):聚集索引就相當于使用字典的拼音查找,因為聚集索引存盤記錄是物理上連續存在的,即拼音 a 過了后面肯定是 b 一樣,
非聚集索引(NONCLUSTERED):非聚集索引就相當于使用字典的部首查找,非聚集索引是邏輯上的連續,物理存盤并不連續,
PS:聚集索引一個表只能有一個,而非聚集索引一個表可以存在多個,
什么情況下使用索引:
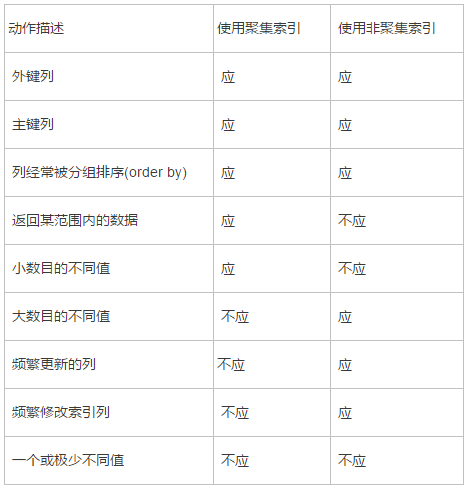
語法:

CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column_name [ ASC | DESC ] [ ,...n ] ) [ WITH <backward_compatible_index_option> [ ,...n ] ] [ ON { filegroup_name | "default" } ] <object> ::= { [ database_name. [ owner_name ] . | owner_name. ] table_or_view_name } <backward_compatible_index_option> ::= { PAD_INDEX | FILLFACTOR = fillfactor | SORT_IN_TEMPDB | IGNORE_DUP_KEY | STATISTICS_NORECOMPUTE | DROP_EXISTING } 引數:
UNIQUE:為表或視圖創建唯一索引, 唯一索引不允許兩行具有相同的索引鍵值, 視圖的聚集索引必須唯一,如果要建唯一索引的列有重復值,必須先洗掉重復值,
CLUSTERED:表示指定創建的索引為聚集索引,創建索引時,鍵值的邏輯順序決定表中對應行的物理順序, 聚集索引的底層(或稱葉級別)包含該表的實際資料行,
NONCLUSTERED:表示指定創建的索引為非聚集索引,創建一個指定表的邏輯排序的索引, 對于非聚集索引,資料行的物理排序獨立于索引排序,
index_name:表示指定所創建的索引的名稱,
database_name:表示指定的資料庫的名稱,
owner_name:表示指定所有者,
table:表示指定創建索引的表的名稱,
view:表示指定創建索引的視圖的名稱,
column:索引所基于的一列或多列, 指定兩個或多個列名,可為指定列的組合值創建組合索引,
[ ASC | DESC]:表示指定特定索引列的升序或降序排序方向, 默認值為 ASC,
on filegroup_name:為指定檔案組創建指定索引, 如果未指定位置且表或視圖尚未磁區,則索引將與基礎表或視圖使用相同的檔案組, 該檔案組必須已存在,
on default:為默認檔案組創建指定索引,
PAD_INDEX = {ON |OFF }:指定是否索引填充,默認為 OFF,
ON 通過指定的可用空間的百分比fillfactor應用于索引中間級別頁,
OFF 或 fillfactor 未指定,考慮到中間級頁上的鍵集,將中間級頁填充到接近其容量的程度,以留出足夠的空間,使之至少能夠容納索引的最大的一行,
PAD_INDEX 選項只有在指定了 FILLFACTOR 時才有用,因為 PAD_INDEX 使用由 FILLFACTOR 指定的百分比,
FILLFACTOR = fillfactor:用于指定在創建索引時,每個索引頁的資料占索引頁大小的百分比,fillfactor 的值為1到100,
SORT_IN_TEMPDB = {ON |OFF }:用于指定創建索引時的中間排序結果將存盤在 tempdb 資料庫中, 默認為 OFF,
ON 用于生成索引的中間排序結果存盤在tempdb, 這可能會降低僅當創建索引所需的時間tempdb位于不同的與用戶資料庫的磁盤集,
OFF 中間排序結果與索引存盤在同一資料庫中,
IGNORE_DUP_KEY = {ON |OFF }:指定在插入操作嘗試向唯一索引插入重復鍵值時的錯誤回應,默認為 OFF,
ON 向唯一索引插入重復鍵值時將出現警告訊息, 只有違反唯一性約束的行才會失敗,
OFF 向唯一索引插入重復鍵值時將出現錯誤訊息, 整個 INSERT 操作將被回滾,
STATISTICS_NORECOMPUTE = {ON |OFF}:用于指定過期的索引統計是否自動重新計算, 默認為 OFF,
ON 不會自動重新計算過時的統計資訊,
OFF 啟用統計資訊自動更新功能,
DROP_EXISTING = {ON |OFF }:表示如果這個索引還在表上就 drop 掉然后在 create 一個新的, 默認為 OFF,
ON 指定要洗掉并重新生成現有索引,其必須具有相同名稱作為引數 index_name,
OFF 指定不洗掉和重新生成現有的索引, 如果指定的索引名稱已經存在,SQL Server 將顯示一個錯誤,
ONLINE = {ON |OFF}:表示建立索引時是否允許正常訪問,即是否對表進行鎖定,默認為 OFF,
ON 它將強制表對于一般的訪問保持有效,并且不創建任何阻止用戶使用索引和/表的鎖,
OFF 對索引操作將對表進行表鎖,以便對表進行完全和有效的訪問,
例子:
創建唯一聚集索引:
-- 創建唯一聚集索引create unique clustered --表示創建唯一聚集索引index UQ_Clu_StuNo --索引名稱on Student(S_StuNo) --資料表名稱(建立索引的列名)with ( pad_index=on, --表示使用填充 fillfactor=50, --表示填充因子為50% ignore_dup_key=on, --表示向唯一索引插入重復值會忽略重復值 statistics_norecompute=off --表示啟用統計資訊自動更新功能)
創建唯一非聚集索引:
-- 創建唯一非聚集索引create unique nonclustered --表示創建唯一非聚集索引index UQ_NonClu_StuNo --索引名稱on Student(S_StuNo) --資料表名稱(建立索引的列名)with ( pad_index=on, --表示使用填充 fillfactor=50, --表示填充因子為50% ignore_dup_key=on, --表示向唯一索引插入重復值會忽略重復值 statistics_norecompute=off --表示啟用統計資訊自動更新功能)
--創建聚集索引create clustered index Clu_Indexon Student(S_StuNo)with (drop_existing=on) --創建非聚集索引create nonclustered index NonClu_Indexon Student(S_StuNo)with (drop_existing=on) --創建唯一索引create unique index NonClu_Indexon Student(S_StuNo)with (drop_existing=on)
PS:當 create index 時,如果未指定 clustered 和 nonclustered,那么默認為 nonclustered,
創建非聚集復合索引:
--創建非聚集復合索引create nonclustered index Index_StuNo_SNameon Student(S_StuNo,S_Name)with(drop_existing=on)
--創建非聚集復合索引,未指定默認為非聚集索引create index Index_StuNo_SNameon Student(S_StuNo,S_Name)with(drop_existing=on)
在 CREATE INDEX 陳述句中使用 INCLUDE 子句,可以在創建索引時定義包含的非鍵列(即覆寫索引),其語法結構如下:
CREATE NONCLUSTERED INDEX 索引名ON { 表名| 視圖名 } ( 列名 [ ASC | DESC ] [ ,...n ] )INCLUDE (<列名1>, <列名2>, [,… n])--創建非聚集覆寫索引create nonclustered index NonClu_Indexon Student(S_StuNo)include (S_Name,S_Height)with(drop_existing=on)--創建非聚集覆寫索引,未指定默認為非聚集索引create index NonClu_Indexon Student(S_StuNo)include (S_Name,S_Height)with(drop_existing=on)
PS:聚集索引不能創建包含非鍵列的索引,
創建篩選索引:
--創建非聚集篩選索引create nonclustered index Index_StuNo_SNameon Student(S_StuNo)where S_StuNo >= 001 and S_StuNo <= 020with(drop_existing=on)--創建非聚集篩選索引,未指定默認為非聚集索引create index Index_StuNo_SNameon Student(S_StuNo)where S_StuNo >= 001 and S_StuNo <= 020with(drop_existing=on)
修改索引:
--修改索引語法ALTER INDEX { 索引名| ALL }ON <表名|視圖名>{ REBUILD | DISABLE | REORGANIZE }[ ; ]REBUILD:表示指定重新生成索引,
DISABLE:表示指定將索引標記為已禁用,
REORGANIZE:表示指定將重新組織的索引葉級,
--禁用名為 NonClu_Index 的索引alter index NonClu_Index on Student disable
洗掉和查看索引:
--查看指定表 Student 中的索引exec sp_helpindex Student --洗掉指定表 Student 中名為 Index_StuNo_SName 的索引drop index Student.Index_StuNo_SName--檢查表 Student 中索引 UQ_S_StuNo 的碎片資訊dbcc showcontig(Student,UQ_S_StuNo)--整理 Test 資料庫中表 Student 的索引 UQ_S_StuNo 的碎片dbcc indexdefrag(Test,Student,UQ_S_StuNo)--更新表 Student 中的全部索引的統計資訊update statistics Student
索引定義原則:
避免對經常更新的表進行過多的索引,并且索引中的列盡可能少,而對經常用于查詢的欄位應該創建索引,但要避免添加不必要的欄位,
在條件運算式中經常用到的、不同值較多的列上建立索引,在不同值少的列上不要建立索引,
在頻繁進行排序或分組(即進行 GROUP BY 或 ORDER BY 操作)的列上建立索引,如果待排序的列有多個,可以在這些列上建立組合索引,
在選擇索引鍵時,盡可能采用小資料型別的列作為鍵以使每個索引頁能容納盡可能多的索引鍵和指標,通過這種方式,可使一個查詢必需遍歷的索引頁面降低到最小,此外,盡可能的使用整數做為鍵值,因為整數的訪問速度最快,
參考:
http://www.cnblogs.com/knowledgesea/p/3672099.html
https://msdn.microsoft.com/zh-cn/library/ms188783.aspx
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/31613.html
標籤:SQL Server
上一篇:將select 轉為json
下一篇:SQL Server GROUP BY中的WITH CUBE、WITH ROLLUP原理測驗及GROUPING應用