1. 概述
Apache Cassandra將資料存盤在表中,每個表都由行和列組成,CQL(Cassandra查詢語言)用于查詢存盤在表中的資料,Apache Cassandra資料模型基于查詢并針對查詢進行了優化,Cassandra不支持用于關系資料庫的關系資料建模,Cassandra資料建模專注于查詢,
Cassandra中的資料建模使用查詢驅動(query-driven)的方法,其中特定查詢是組織資料的關鍵,查詢(Query)是從表中選擇資料的結果,模式(Schema)是對表中資料的排列方式的定義,Cassandra的資料庫設計基于對快速讀寫的需求,因此架構設計越好,資料寫入和檢索的速度就越快,
相反,關系型資料庫根據設計的表和關系對資料進行規范化,然后撰寫將要進行的查詢,關系資料庫中的資料建模是表驅動(table-driven)的,表之間的任何關系都表示為查詢中的表連接,
1.1. 什么是資料建模
資料建模是識別物體及其關系的程序,在關系資料庫中,資料放在具有外鍵的規范化表中,外鍵用于參考其他表中的相關資料,應用程式將進行的查詢由表的結構驅動,相關資料作為表連接進行查詢,
在Cassandra中,資料建模是查詢驅動(query-driven)的, 資料訪問模式和應用程式查詢確定資料的結構和組織,然后將其用于設計資料庫表,
資料圍繞特定查詢建模,查詢的最佳設計是訪問單個表,這意味著查詢中涉及的所有物體必須位于同一表中,以使資料訪問(讀取)變得非常快, 資料被建模為最適合一個查詢或一組查詢,一個表可能具有一個或多個最適合查詢的物體,由于物體之間通常確實具有關系,并且查詢可能涉及物體之間具有關系的物體,因此單個物體可以包含在多個表中,
1.2. 查詢驅動的建模
在關系資料庫模型中,查詢使用表連接從多個表獲取資料,而在Cassandra中不支持連接,因此所有必需欄位(列)必須組合在一個表中,由于每個查詢都由一個表支持,因此在稱為非規范化的程序中,資料會在多個表之間冗余, 資料冗余和高寫入吞吐量用于實作高讀取性能,
1.3. 目標
主鍵(primary key)和磁區鍵(partition key)的選擇對于在整個集群中均勻分布資料很重要,使查詢讀取的磁區數量保持最少也很重要,因為不同的磁區可能位于不同的節點上,并且協調器將需要向每個節點發送請求,從而增加了請求的開銷和延遲,即使查詢中涉及的不同磁區位于同一節點上,較少的磁區也可以提高查詢效率,
1.4. 磁區
磁區鍵(partition key)是從主鍵(primary key)的第一個欄位生成的,使用磁區鍵磁區到哈希表的資料可以提供更快的查詢,用于查詢的磁區越少,查詢的回應時間就越快,
下面是一個磁區的例子,假設表t有一個主機id
CREATE TABLE t (
id int,
k int,
v text,
PRIMARY KEY (id)
);
磁區鍵是從主鍵id生成的,用于在群集中的各個節點之間進行資料分配,
下面這個例子,是一個復合主鍵
CREATE TABLE t (
id int,
c text,
k int,
v text,
PRIMARY KEY (id,c)
);
對于具有復合主鍵的表t,第一個欄位id用于生成磁區鍵,第二個欄位c是用于在磁區內排序的聚類鍵,使用聚類鍵對資料進行排序可以提高檢索相鄰資料的效率,
通常,對主鍵的第一個欄位進行哈希處理以生成磁區鍵,而其余欄位則是用于對磁區內的資料進行排序的聚類關鍵字,對資料進行磁區可以提高讀寫效率,不是主鍵欄位的其他欄位可以單獨建立索引,以進一步提高查詢性能,
接下來這個例子,id1和id2用戶生成磁區鍵,c1和c2用于在磁區內排序的聚類關鍵字,
CREATE TABLE t (
id1 int,
id2 int,
c1 text,
c2 text
k int,
v text,
PRIMARY KEY ((id1,id2),c1,c2)
);
1.5. 與關系資料模型比較
關系資料庫使用外鍵將資料存盤在與其他表有關系的表中,關系資料庫的資料建模方法是以表為中心的,查詢必須使用表連接從多個表中獲取資料,這些表之間存在關系,Apache Cassandra沒有外鍵或關系完整性的概念,Cassandra的資料模型是基于設計高效的查詢,不涉及多個表的查詢,關系資料庫對資料進行規范化以避免重復,相反,Cassandra通過在以查詢為中心的資料模型的多個表中冗余資料來對資料進行非規范化,如果Cassandra資料模型不能完全整合用于特定查詢的不同物體之間關系的復雜性,則可以使用應用程式代碼中的客戶端連接(client-side joins),
1.6. 資料建模示例
假設有一組雜志資料,屬性有雜志id、雜志名稱、出版頻率、出版日期和出版商,
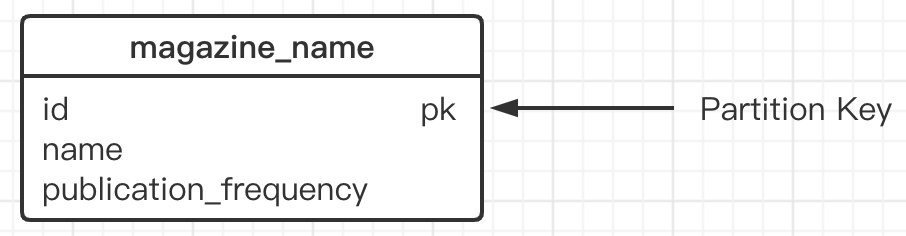
查詢一:列出所有雜志名稱,包括其發布頻率,
由于不需要查詢所有屬性,因此資料模型將僅由ID(用于磁區鍵),雜志名稱和發布頻率組成,如下圖所示:
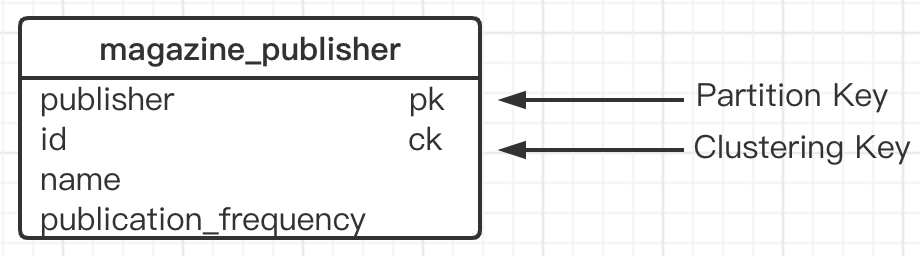
查詢二:按出版商列出所有雜志名稱
輸出列增加出版商,同時用出版商作磁區鍵,如下圖所示:
1.7. 定義Schema
對于查詢一,定義如下:
CREATE TABLE magazine_name (
id int PRIMARY KEY,
name text,
publication_requency text
)
對于查詢二,定義如下:
CREATE TABLE magazine_publisher (
publisher text,
id int,
name text,
publication_requency text,
PRIMARY KEY (publisher, id)
) WITH CLUSTERING ORDER BY (id DESC)
2. 概念資料建模
首先,創建一個簡單的域模型,它在關系型世界中很容易理解,然后看看如何在Cassandra中將它從關系型映射到分布式哈希表模型,
以酒店預訂為例,概念性領域包括酒店、入住酒店的客人、每個酒店的房間集合、這些房間的價格和空房情況以及為客人預訂的預訂記錄,酒店通常還會維護“景點”的集合,這些景點包括公園,博物館,購物畫廊,古跡或客人在住宿期間可能要參觀的酒店附近的其他地方,旅館和興趣點都需要維護地理位置資料,以便可以在地圖上找到它們進行混搭,并計算距離,ER圖如下:
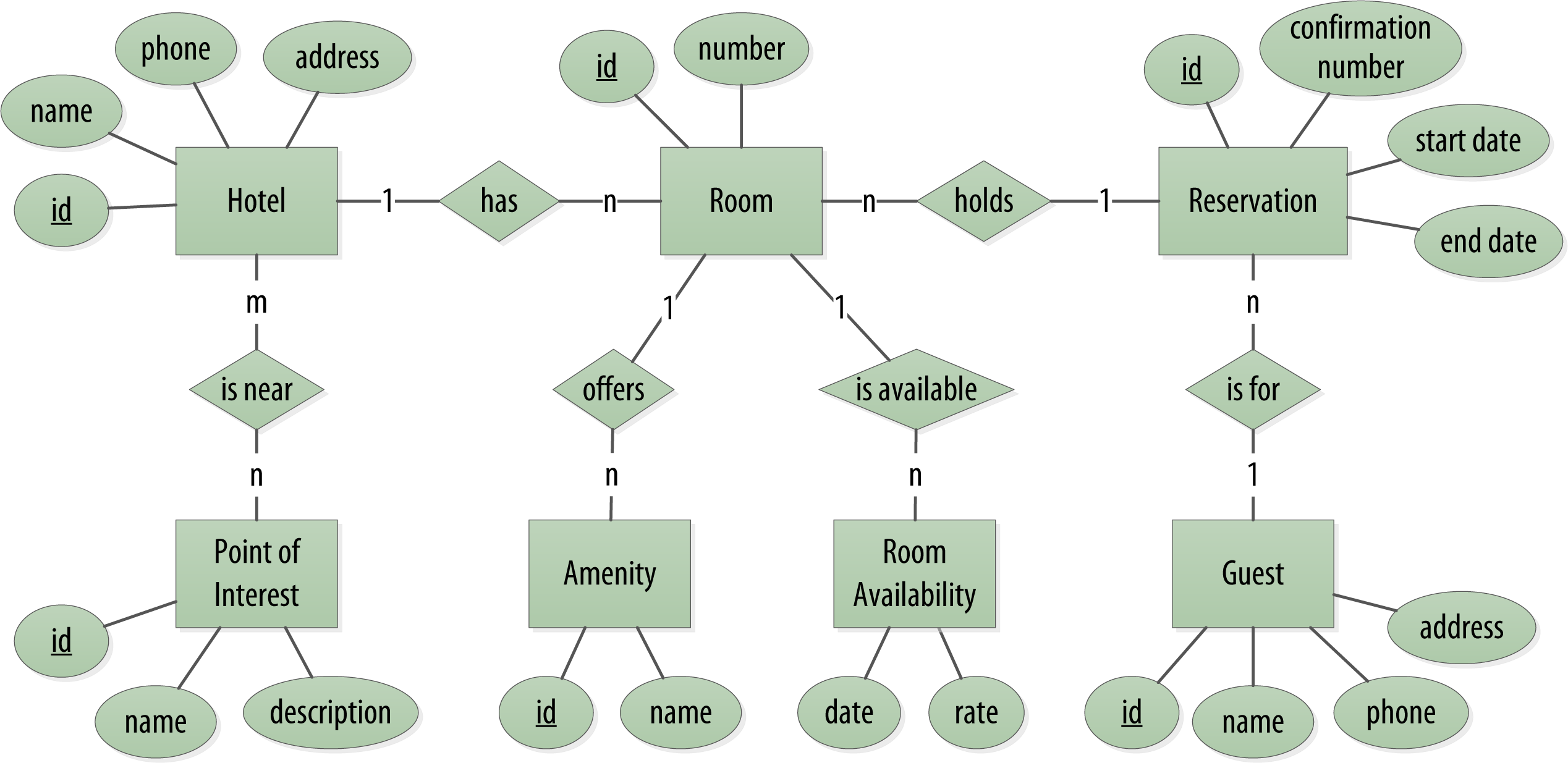
一目了然,一個酒店有多個房間,一個房間里面有多個休閑設施,房間的空閑情況也是分時段的,酒店附近有多個景點,一位顧客可以訂多個房間,每一個預訂記錄對應多個房間,
3. 關系型資料庫設計
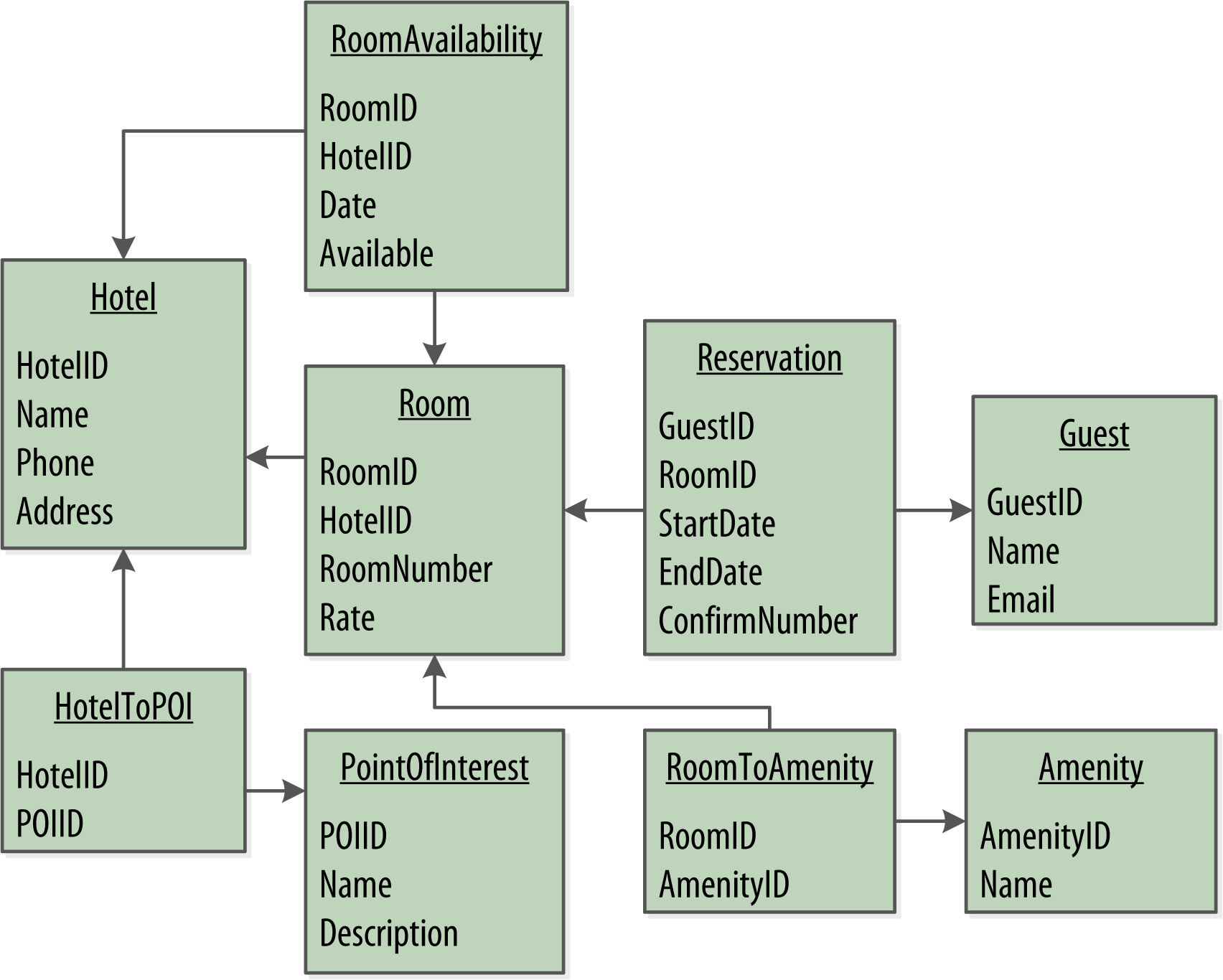
當我們構建一個新的資料驅動應用程式時,將使用關系型資料庫,首先,將領域物件轉化為一組規范化的表,并使用外鍵參考其他表中的相關資料,
3.1. RDBMS和Cassandra之間的設計差異
• 沒有連接(join)
在Cassandra中,無法執行連接(join)操作,如果你已經設計了一個資料模型并且需要一個連接其它表的資料,那么你不得不在客戶端做這種連接,或者創建一個非規范化的第二個表來表示連接結果,后一種方法是Cassandra資料建模的首選方法,
• 沒有外鍵參考
在關系資料庫中,可以在表中指定外鍵來參考另一個表的主鍵,但Cassandra并沒有強制要求必須定義外鍵來參考,在表中存盤與其他物體相關的ID仍然是常見的設計需求,但是級聯洗掉等操作不可用,
• 非規范化
在關系資料庫設計中,經常會強調范式重要性,資料庫設計三范式,但是在Cassandra中,遵循范式不是一個好的選擇,因為通常在不遵循范式時執行得最好,
關系資料庫故意去規范化的第二個原因是需要保留的業務檔案結構,也就是說,有一個封閉的表,它參考了很多外部表,這些表的資料可能會隨著時間的變化而變化,但是你需要將封閉的檔案保存為歷史記錄中的一個快照,這里最常見的例子是發票,假設已經有了customer和product表,可能你認為可以只制作一個針對這些表的發票,但在實踐中永遠不應該這樣做,顧客或價格資訊可能會改變,然后你將失去失去發票單據上發票日期的完整性,這可能違反審計、報告、或法律,并導致其他問題,可以看到,在這種情況下,冗余是必要的,
在Cassandra中,非規范化是完全正常的,
• 查詢優先
簡單的來說,關系建模意味著概念領域模型開始,用表來表示領域物件,用表欄位來表示領域物件的屬性,然后設定主鍵和外鍵來表示領域物件之前的關系,如果有多對多的關系,還要再建一張中間表,關系世界中的查詢是次要的,只要對表進行適當的建模,就可以始侄訓得所需的資料,即使必須使用幾個復雜的子查詢或連接陳述句,這通常也是正確的,
相比之下,在Cassandra中,不是從資料模型開始的,而是從查詢模型開始的,Cassandra不是先對資料建模,然后撰寫查詢,而是先對查詢建模,讓資料圍繞查詢進行組織,考慮應用程式將使用的最常見的查詢路徑,然后創建支持它們所需的表,
• 最佳存盤設計
在關系資料庫中,對于用戶來說,表是如何存盤在磁盤上的通常是透明的,基本不用關心,然而,這是Cassandra中的重要考慮因素,由于Cassandra表都存盤在磁盤上的獨立檔案中,因此將相關列一起定義在同一個表中非常重要,
在Cassandra中創建資料模型時,一個關鍵目標是最小化必須搜索的磁區數量,以滿足給定的查詢,由于磁區是不跨節點劃分的存盤單元,因此搜索單個磁區的查詢通常會產生最佳性能,
• 排序是一個設計決策
在RDBMS中,可以通過在查詢中使用ORDER BY輕松地更改記錄回傳的順序,默認的排序順序是不可配置的;默認情況下,記錄是按照寫入的順序回傳的,如果要更改順序,只需修改查詢即可,并且可以根據任何列進行排序,
但是,在Cassandra中,排序的處理方式有所不同,這是一個設計決策,查詢中可用的排序順序是固定的,并且完全由在CREATE TABLE命令中提供的集群列的選擇確定,CQL SELECT陳述句確實支持ORDER BY語意,但僅按聚簇列指定的順序,
4. 定義應用程式的查詢
既然是查詢驅動的,那么就先看看針對酒店預訂這個例子,業務都需要查詢,畢竟技術是為業務服務的,拋開業務彈設計是不可取的,
(畫外音:此刻,突然想到那句“技術支撐商業、技術拓展商業、技術創作商業”)
言歸正傳,在酒店預訂的例子中,可以大致梳理出以下業務查詢:
Q1: 查找某個景點附近的酒店
Q2: 查找某個酒店的資訊
Q3: 查找某個酒店附近的景點
Q4: 在給定的日期范圍內找到一個可用的房間
Q5: 查找房間的價格和設施
Q6: 通過確認碼查找預訂
Q7: 根據酒店、日期和顧客姓名查找預訂
Q8: 按顧客姓名查找所有預訂
Q9: 查看顧客詳細資訊
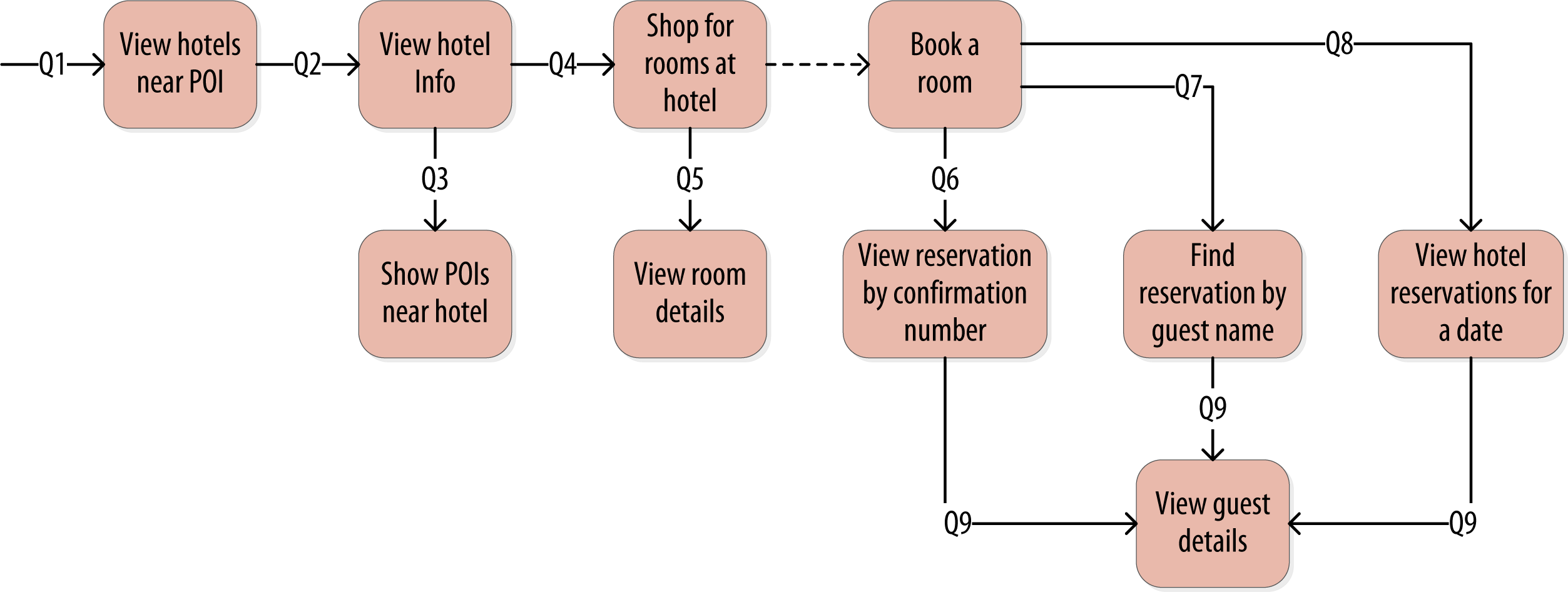
5. 邏輯資料建模
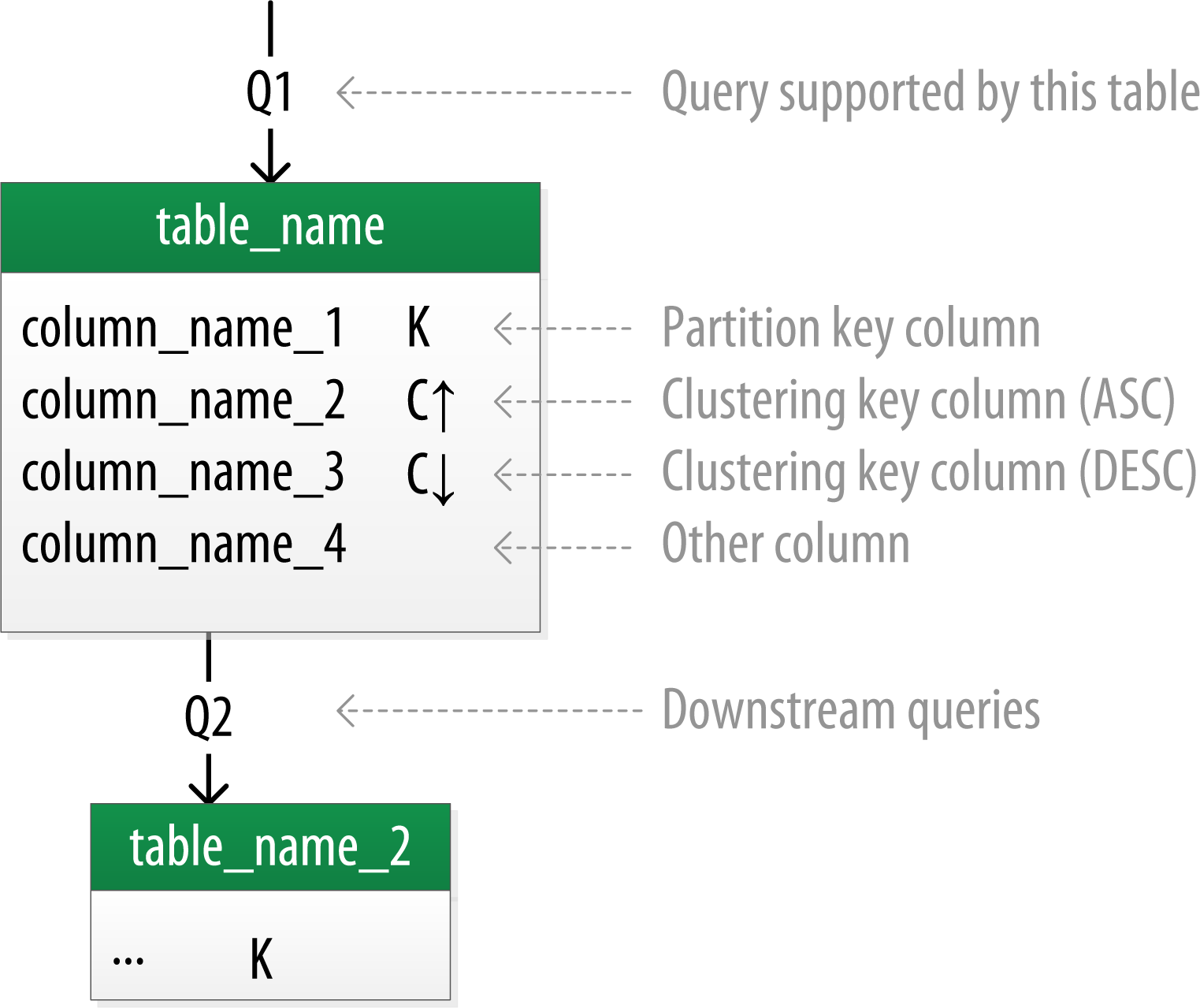
為了更生動形象地表示資料模型,這里采用下面這種圖表方式:
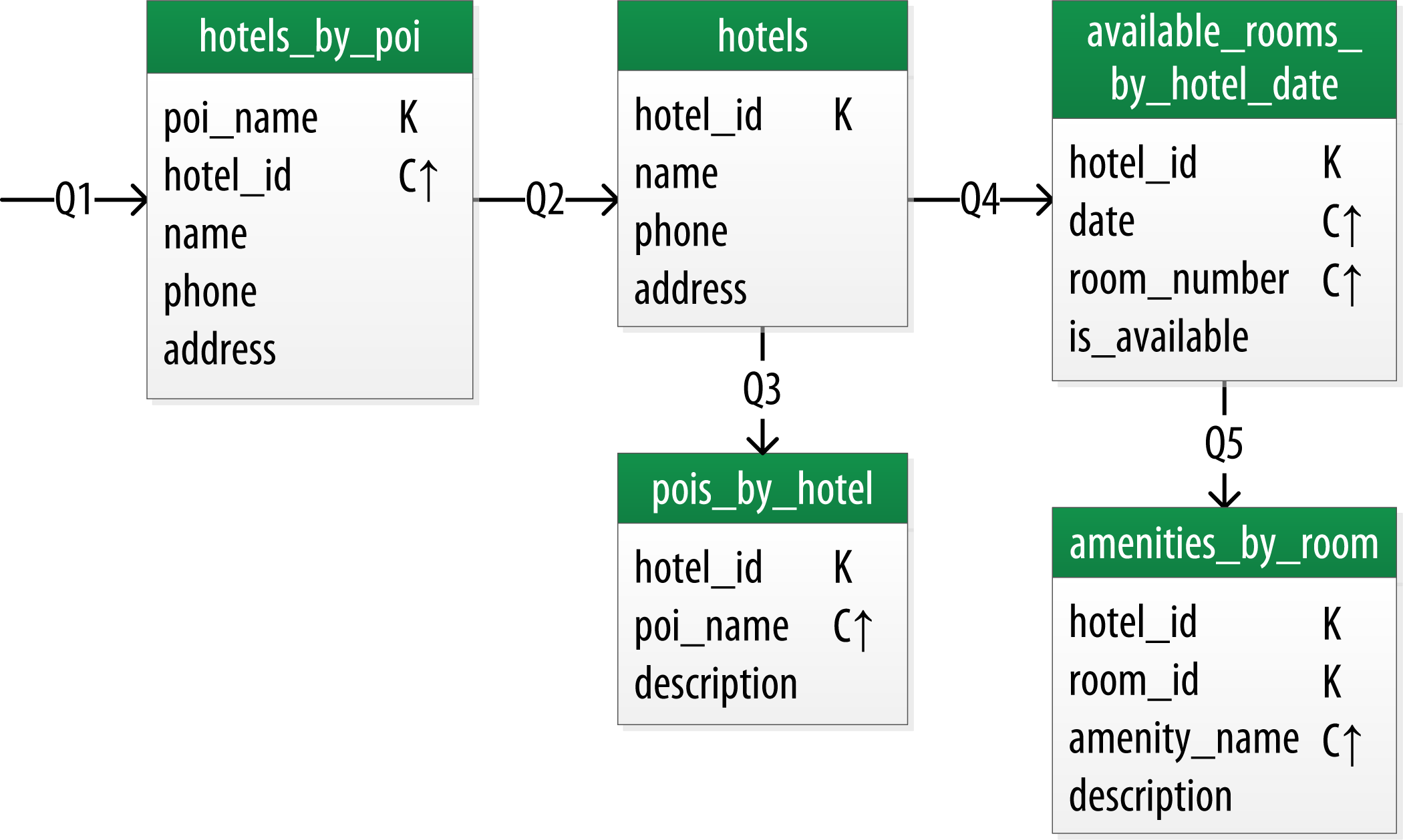
5.1. Hotel邏輯資料模型
按照上面的圖表方式,酒店邏輯資料模型表示如下:
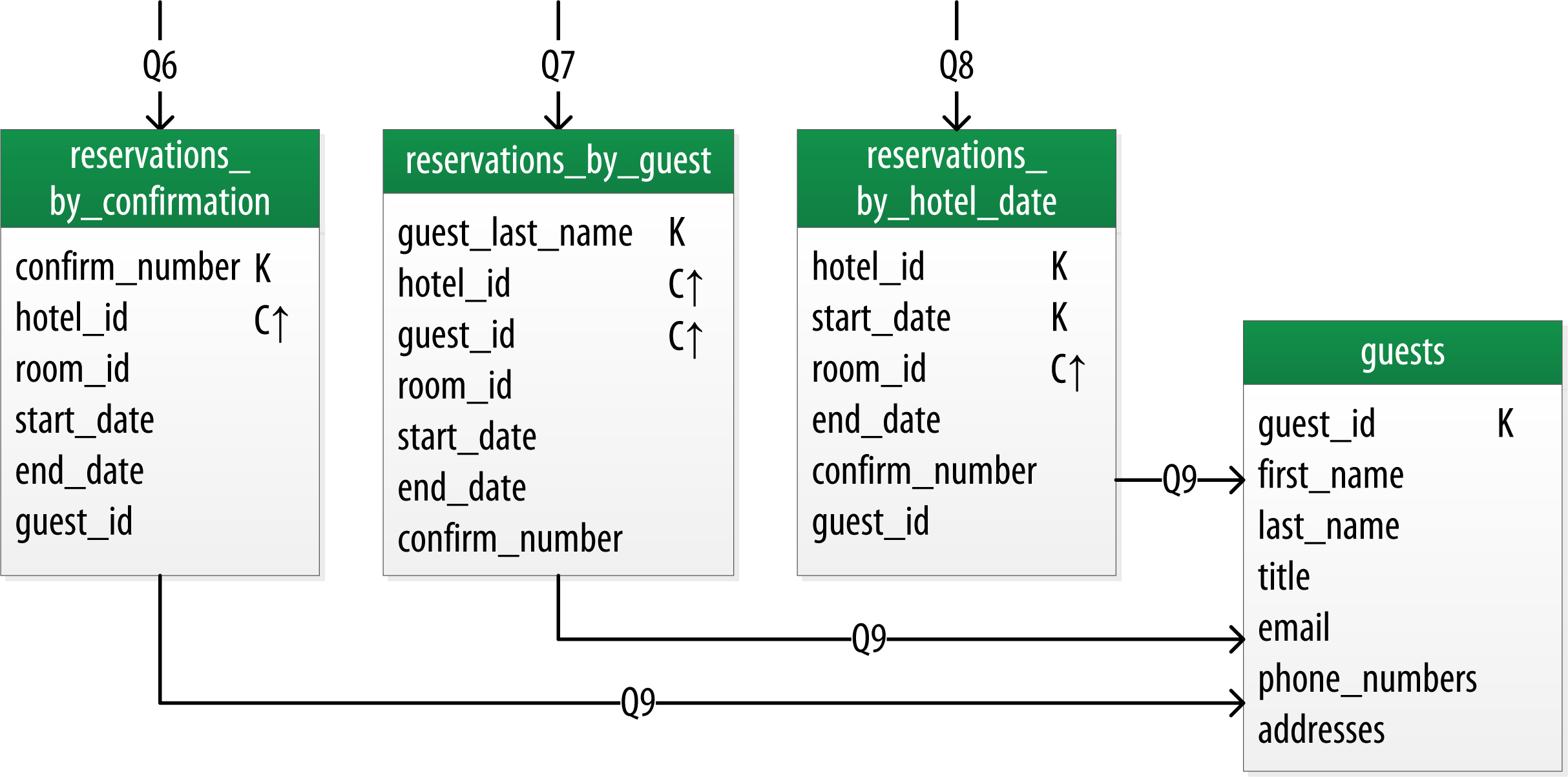
5.2. Reservation邏輯資料模型
同樣的方式,預訂邏輯資料模型表示如下:
6. 物理資料建模
(畫外音:一切設計都是為了查詢,這話聽著很耳熟,哈哈,Elasticsearch說過,一切設計都是為了提高檢索的性能)
為了方便理解,采用如下格式來表示,不用多說,看圖說話:

酒店資料模型:
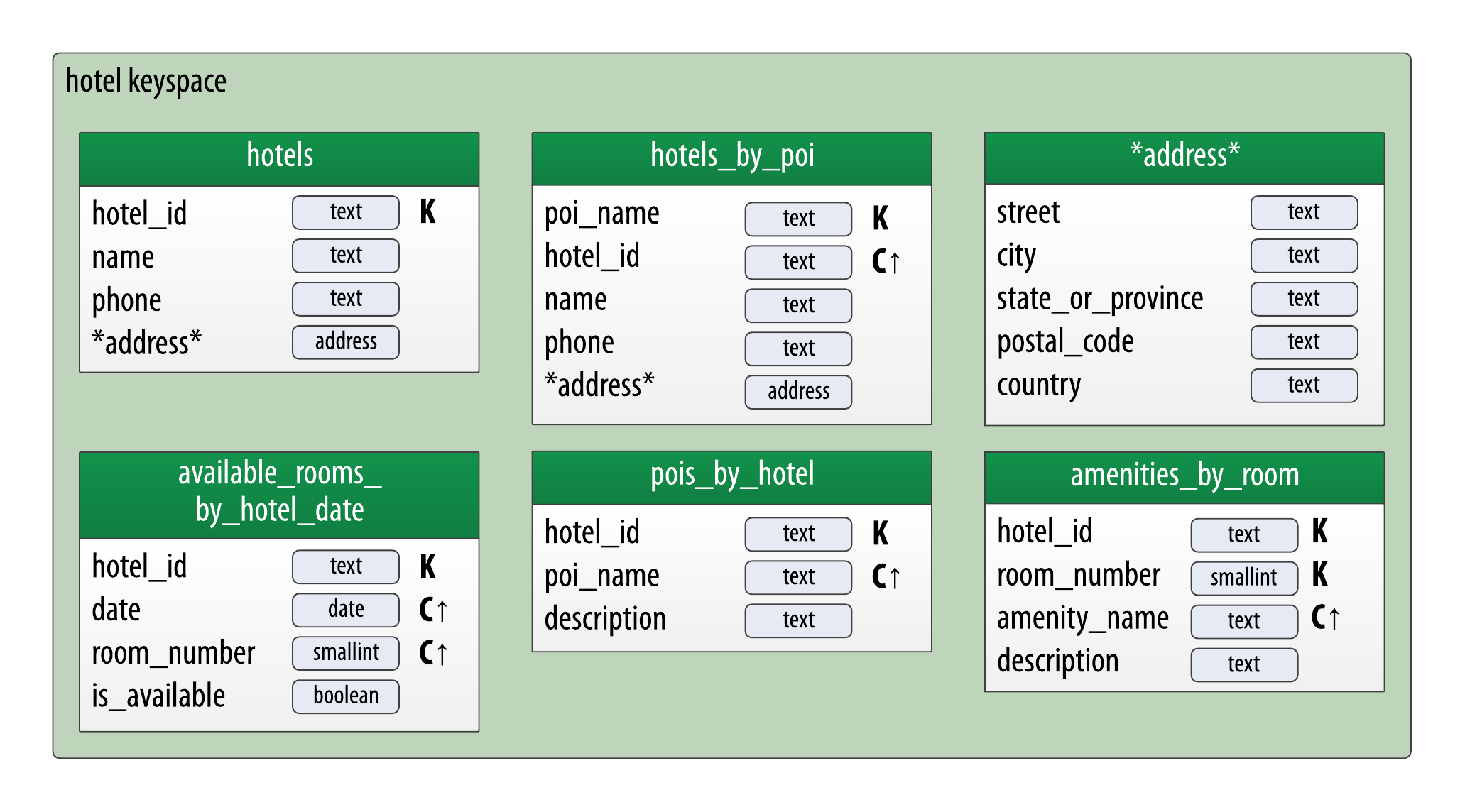
預訂資料模型:

7. 評估和完善資料模型
7.1. 計算磁區大小
首先要考慮的是,表的磁區是否太大,或者換句話說,太寬,磁區大小是通過存盤在磁區中的單元格(值)的數量來度量的,Cassandra的硬限制是每個磁區有20億個單元格(PS:類比Excel中的單元格),但是在達到這個限制之前,可能會遇到性能問題,
磁區大小計算公式:N_v = N_r (N_c - N_{pk} - N_s) + N_s
其中:
N_r表示行數
N_c表示列數
N_pk表示主鍵列數
N_s表示靜態列數
N_v表示單元格數量
那么,單元格數量 = 行數 × (總列數 - 主鍵列數 - 靜態列數) + 靜態列數
以available_rooms_by_hotel_date表為例,根據公式,該表的單元格總數 = 行數 × (4 - 3 -0) + 0
7.2. 計算磁盤大小
每種資料型別所占磁盤空間大小不一,粗略地可以用所有列所占磁盤大小乘以行數來計算
7.3. 拆分大磁區
有一種稱為bucketing的技術常被用來將資料分割成中等大小的磁區,例如,可以通過向磁區鍵添加一個month列(可能表示為一個整數)來分解available_rooms_by_hotel_date表,與原設計的對比如下圖所示,雖然month列部分重復了date,但它提供了一種很好的方法,可以在磁區中對相關資料進行分組,而且磁區不會變得太大,

8. 定義資料庫Schema
schema可以理解為資料庫,一個schema就是指一個資料庫
下面是為hotel keyspace定義的schema:
CREATE KEYSPACE hotel WITH replication =
{‘class’: ‘SimpleStrategy’, ‘replication_factor’ : 3};
CREATE TYPE hotel.address (
street text,
city text,
state_or_province text,
postal_code text,
country text );
CREATE TABLE hotel.hotels_by_poi (
poi_name text,
hotel_id text,
name text,
phone text,
address frozen<address>,
PRIMARY KEY ((poi_name), hotel_id) )
WITH comment = ‘Q1. Find hotels near given poi’
AND CLUSTERING ORDER BY (hotel_id ASC) ;
CREATE TABLE hotel.hotels (
id text PRIMARY KEY,
name text,
phone text,
address frozen<address>,
pois set )
WITH comment = ‘Q2. Find information about a hotel’;
CREATE TABLE hotel.pois_by_hotel (
poi_name text,
hotel_id text,
description text,
PRIMARY KEY ((hotel_id), poi_name) )
WITH comment = Q3. Find pois near a hotel’;
CREATE TABLE hotel.available_rooms_by_hotel_date (
hotel_id text,
date date,
room_number smallint,
is_available boolean,
PRIMARY KEY ((hotel_id), date, room_number) )
WITH comment = ‘Q4. Find available rooms by hotel date’;
CREATE TABLE hotel.amenities_by_room (
hotel_id text,
room_number smallint,
amenity_name text,
description text,
PRIMARY KEY ((hotel_id, room_number), amenity_name) )
WITH comment = ‘Q5. Find amenities for a room’;
reservation keyspace 的 schema 如下:
CREATE KEYSPACE reservation WITH replication = {‘class’:
‘SimpleStrategy’, ‘replication_factor’ : 3};
CREATE TYPE reservation.address (
street text,
city text,
state_or_province text,
postal_code text,
country text );
CREATE TABLE reservation.reservations_by_confirmation (
confirm_number text,
hotel_id text,
start_date date,
end_date date,
room_number smallint,
guest_id uuid,
PRIMARY KEY (confirm_number) )
WITH comment = ‘Q6. Find reservations by confirmation number’;
CREATE TABLE reservation.reservations_by_hotel_date (
hotel_id text,
start_date date,
end_date date,
room_number smallint,
confirm_number text,
guest_id uuid,
PRIMARY KEY ((hotel_id, start_date), room_number) )
WITH comment = ‘Q7. Find reservations by hotel and date’;
CREATE TABLE reservation.reservations_by_guest (
guest_last_name text,
hotel_id text,
start_date date,
end_date date,
room_number smallint,
confirm_number text,
guest_id uuid,
PRIMARY KEY ((guest_last_name), hotel_id) )
WITH comment = ‘Q8. Find reservations by guest name’;
CREATE TABLE reservation.guests (
guest_id uuid PRIMARY KEY,
first_name text,
last_name text,
title text,
emails set,
phone_numbers list,
addresses map<text,
frozen<address>,
confirm_number text )
WITH comment = ‘Q9. Find guest by ID’;
9. 檔案
https://cassandra.apache.org/doc/latest/data_modeling/index.html
https://cassandra.apache.org/doc/latest/data_modeling/intro.html
https://cassandra.apache.org/doc/latest/data_modeling/data_modeling_rdbms.html
https://cassandra.apache.org/doc/latest/cql/index.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/3164.html
標籤:NoSQL