我正在使用 R 編程語言。我有一個資料集,其中包含一個人的身高以及他們是否打籃球。
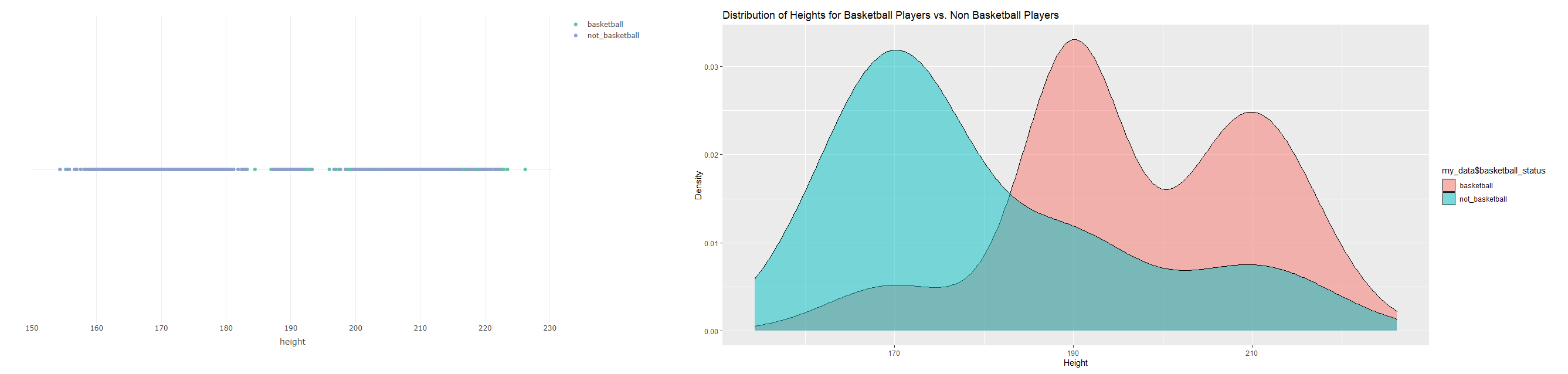
我想看看平均而言,超過 80%(身高方面)的人是否會打籃球。
為此,我:
- 我隨機將資料分成 70% 的組(訓練)和 30% 的組(測驗)
- 我計算了火車組的第 80 個百分點:使用這個第 80 個百分點,我看看測驗組有多少人打籃球
- 我計算平均準確度(在測驗組中)
- 我多次重復此程序(例如 100 次)并計算總平均值。
以下是生成此示例資料的 R 代碼:
set.seed(123)
height <- rnorm(1000,210,5)
status <- c("basketball", "not_basketball")
basketball_status <- as.character(sample(status, 1000, replace=TRUE, prob=c(0.80, 0.20)))
data_1 <- data.frame(height, basketball_status)
height <- rnorm(1000,190,1)
status <- c("basketball", "not_basketball")
basketball_status <- as.character(sample(status, 1000, replace=TRUE, prob=c(0.8, 0.2)))
data_2 <- data.frame(height, basketball_status)
height <- rnorm(1000,170,5)
status <- c("basketball", "not_basketball")
basketball_status <- as.character(sample(status, 1000, replace=TRUE, prob=c(0.20, 0.80)))
data_3 <- data.frame(height, basketball_status)
my_data <- rbind(data_1, data_2, data_3)
這是迭代程序:
library(dplyr)
results <- list()
for (i in 1:100) {
train_i<-sample_frac(my_data, 0.7)
sid<-as.numeric(rownames(train_i))
test_i<-my_data[-sid,]
quantiles = data.frame( train_i %>% summarise (quant_1 = quantile(height, 0.80)))
test_i$basketball_pred = as.character(ifelse(test_i$height > quantiles$quant_1 , "basketball", "not_basketball" ))
test_i$accuracy = ifelse(test_i$basketball_pred == test_i$basketball_status, 1, 0)
results_tmp = data.frame(test_i %>%
dplyr::summarize(Mean = mean(accuracy, na.rm=TRUE)))
results_tmp$iteration = i
results_tmp$total_mean = mean(test_i$accuracy)
results[[i]] <- results_tmp
}
results
results_df <- do.call(rbind.data.frame, results)
但是當我運行迭代程序時,所有的平均值看起來都一樣:
head(results_df)
Mean iteration total_mean
1 0.8344444 1 0.8344444
2 0.8344444 2 0.8344444
3 0.8344444 3 0.8344444
4 0.8344444 4 0.8344444
5 0.8344444 5 0.8344444
6 0.8344444 6 0.8344444
問題:有誰知道為什么會這樣?
謝謝
uj5u.com熱心網友回復:
sid<-as.numeric(rownames(train_i))不是在做你期望的,我想。您可能希望確定前一行中包含哪些原始資料幀行train_i<-sample_frac(my_data, 0.7),但它實際上只是輸出 1:2100,以便以后的所有步驟每次都提供相同的結果。
我想如果你用以下內容替換這些行:
my_data$row = 1:nrow(my_data)
train_i <- sample_frac(my_data, 0.7)
sid <- train_i$row
你會得到你期待的結果。
Mean iteration total_mean
1 0.5111111 1 0.5111111
2 0.5244444 2 0.5244444
3 0.5177778 3 0.5177778
4 0.5488889 4 0.5488889
5 0.5322222 5 0.5322222
對我有用的完整代碼:
results <- list()
for (i in 1:100) {
my_data$row = 1:nrow(my_data)
train_i<-sample_frac(my_data, 0.7)
sid<-train_i$row
test_i<-my_data[-sid,]
quantiles = data.frame( train_i %>% summarise (quant_1 = quantile(height, 0.80)))
test_i$basketball_pred = ifelse(test_i$height > quantiles$quant_1 , "basketball", "not_basketball" )
test_i$accuracy = ifelse(test_i$basketball_pred == test_i$basketball_status, 1, 0)
results_tmp = data.frame(test_i %>%
dplyr::summarize(Mean = mean(accuracy, na.rm=TRUE)))
results_tmp$iteration = i
results_tmp$total_mean = mean(test_i$accuracy)
results[[i]] <- results_tmp
}
uj5u.com熱心網友回復:
不是答案 - 使用@ Jon Spring 親切提供的答案:
results <- list()
for (i in 1:100) {
my_data$row = 1:nrow(my_data)
train_i <- sample_frac(my_data, 0.7)
sid <- train_i$row
quantiles = data.frame( train_i %>% summarise (quant_1 = quantile(height, 0.80)))
test_i$basketball_pred = as.character(ifelse(test_i$height > quantiles$quant_1 , "basketball", "not_basketball" ))
test_i$accuracy = ifelse(test_i$basketball_pred == test_i$basketball_status, 1, 0)
results_tmp = data.frame(test_i %>%
dplyr::summarize(Mean = mean(accuracy, na.rm=TRUE)))
results_tmp$iteration = i
results_tmp$total_mean = mean(test_i$accuracy)
results[[i]] <- results_tmp
}
results
results_df <- do.call(rbind.data.frame, results)
這是最終答案:
head(results_df)
Mean iteration total_mean
1 0.8344444 1 0.8344444
2 0.8344444 2 0.8344444
3 0.8344444 3 0.8344444
4 0.8344444 4 0.8344444
5 0.8344444 5 0.8344444
6 0.8344444 6 0.8344444
@Jon Spring:數字還是一樣?我是否正確理解您的回答?
非常感謝您的幫助!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/318466.html