我正試圖用一個網站搜索關鍵詞從《Vogue》中搜刮文章標題和鏈接。我無法得到前100個結果,因為 "顯示更多 "按鈕將它們遮住了。我以前通過使用變化的URL來解決這個問題,但Vogue的URL沒有變化以包括頁碼、結果編號等。
import 請求
from bs4 import BeautifulSoup as bs
url = 'https://www.vogue.com/search?q=HARRY STYLES&sort=score desc'。
r = requests.get(url)
soup = bs(r.content, 'html')
links = soup.find_all('a', {'class':" summary-item-tracking__hed-link summary-item__hed-link")
titles = soup.find_all('h2', {'class':"summary-item__hed"})
res = []
for i in range(len(titles)):
entry = {'Title': titles[i].text.strip(), 'Link': 'https://www.vogue.com' links[i]['href'].strip()}.
res.append(entry)
關于如何刮取 "顯示更多 "按鈕之后的資料,有什么提示嗎?
uj5u.com熱心網友回復:
你可以使用你的瀏覽器的網路開發工具檢查網站上的請求,以找出它是否對你感興趣的資料提出了特定的請求。 在這種情況下,網站正在通過向一個像這樣的URL發出GET請求來加載更多的資訊:
其中 假設您可以/將要請求有限數量的頁面,并且由于資料格式是JSON,您將不得不將其轉換為 然后,"標題 "將是 作為一個提示,我認為這是一個很好的做法,嘗試看看網站是如何手動作業的,然后嘗試自動化的程序。
如果你想向該URL請求資料,請確保在請求之間包含一些延遲,這樣你就不會被踢出或被阻止。
uj5u.com熱心網友回復: 你必須從開發者工具中檢查網路。然后你要確定網站如何請求資料。你可以在截圖中看到請求和回應。
如你所見,該網站正在使用頁面引數。
每個頁面有8個標題。所以你必須使用回圈來獲得100個標題。
代碼: 輸出:
標籤: 上一篇:如何從網站上抓取描述
下一篇:腳本在執行程序中某個地方被卡住了
。
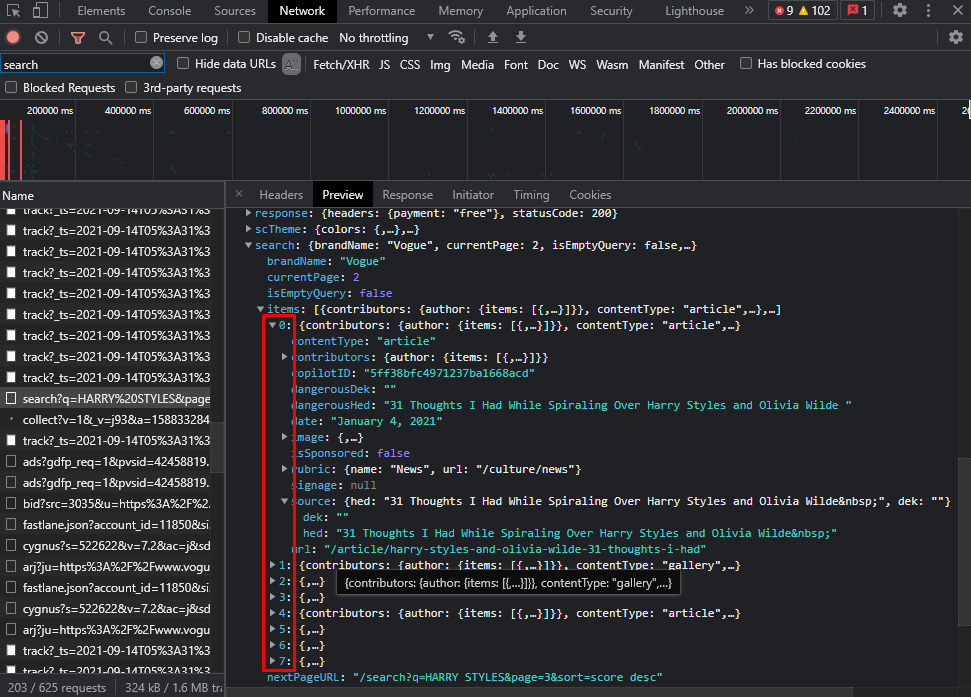
https://www.vogue.com/search?q=HARRY STYLES&page=<page_number>&sort=score desc&format=json<page_number>為>1,因為第1頁是你訪問網站時默認看到的內容。dict()或其他資料結構以提取您想要的資料。特別是針對JSON物件的"search.items"鍵,因為它包含了請求頁面的文章資料陣列。
search.items[i].source.hed,你可以用search.items[i].url來組合鏈接。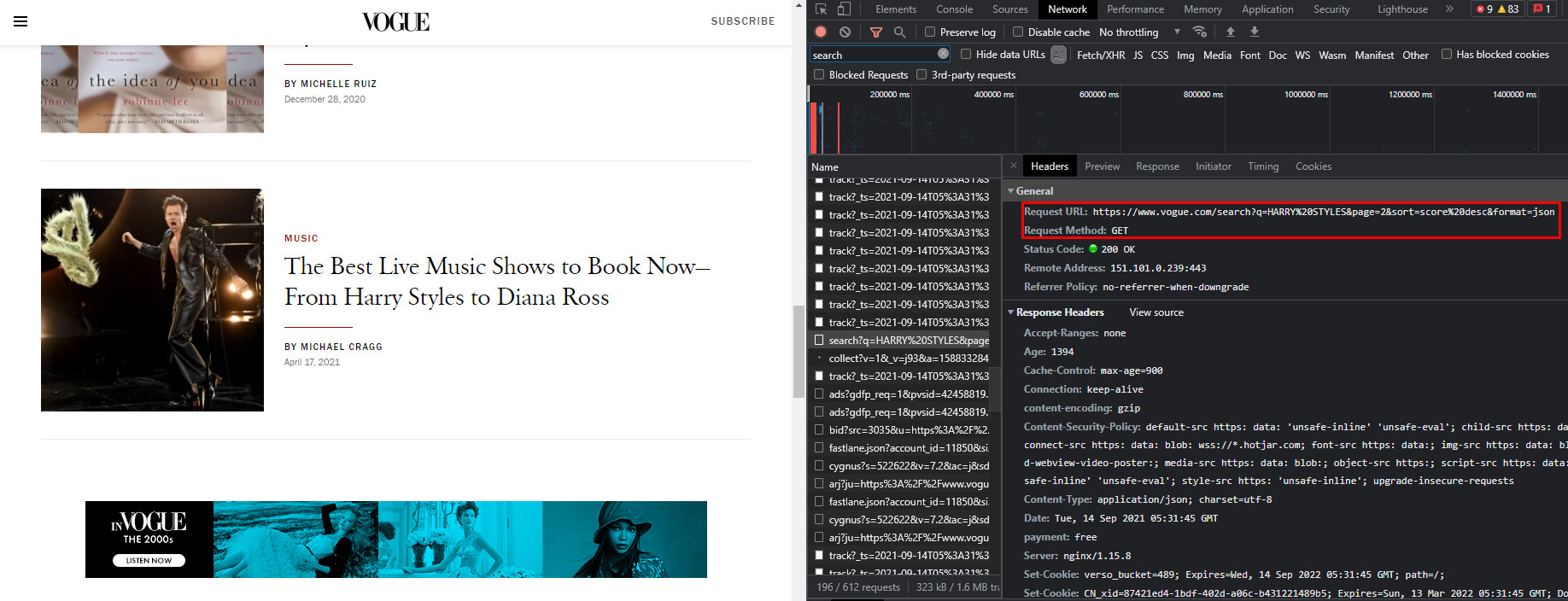
import cloudscraper,json,html
counter=1
for i in range(1,14)。
url = f'https://www.vogue.com/search?q=HARRY STYLES&page={i}& sort=score desc& format=json'
scraper = cloudscraper.create_scraper(browser={'browser': 'firefox','平臺': 'windows','手機'。False},delay=10)
byte_data = scraper.get(url).content
json_data = json.load(byte_data)
for j in range(0,8) 。
title_url = 'https://www.vogue.com' (html.unescape(json_data['search'][' items'][j]['url'])
t = html.unescape(json_data['search']['items'][j]['source']['hed'] )
print(counter," - " t ' - ' title_url)
if (counter == 100) 。
break (counter == 100).
counter = counter 1: break.