在作業中,日常的資料庫開發,其實大部分用到的資料庫知識并不復雜,無非是CRUD【增刪改查】,但是偶爾會有一些特殊的需求,看似合理,但是一時半會兒也想不起來如何下手,所以只能去百度查找,為了方便起見,這里列舉了一些作業中日常用到但又稍微復雜的陳述句,僅供學習分享使用,如有不足之處,還請指正,
磁區排序【partition by】
按指定列分組,同時另一列排序,如:成績表中,按班級分組,成績排序,排出每一班級的成績順序,
磁區排序語法:
1 select row_number()[rank(),dense_rank()] OVER (PARTITION BY 分組欄位1,分組欄位2 ORDER BY 排序欄位1) from table;
注意:此處不可以用group by ,因為group by 是分組進行匯總功能,
row_number示例:
1 select sno,cno,degree, 2 row_number()over(partition by cno order by degree desc) mm 3 from score
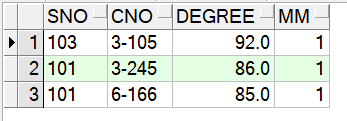
rank示例:
1 SELECT * 2 FROM (select sno,cno,degree, 3 rank()over(partition by cno order by degree desc) mm 4 from score) 5 where mm = 1;
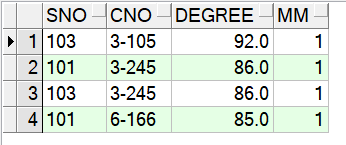
rank和row_number的區別
由以上的例子得出,在求第一名成績的時候,不能用row_number(),因為如果同班有兩個并列第一,row_number()只回傳一個結果,具體差異如下:
- rownumber函式回傳一個唯一的值,當碰到相同資料時,排名按照記錄集中記錄的順序依次遞增,
- rank函式回傳一個唯一的值,除非遇到相同的資料,此時所有相同資料的排名是一樣的,同時會在最后一條相同記錄和下一條不同記錄的排名之間空出排名,rank()是跳躍排序,有兩個第二名時接下來就是第四名(同樣是在各個分組內),
- dense_rank函式回傳一個唯一的值,除非當碰到相同資料,此時所有相同資料的排名都是一樣的,dense_rank()是連續排序,有兩個第二名時仍然跟著第三名,他和row_number的區別在于row_number是沒有重復值的,
遞回查詢【start with】
如果表中存在層次資料,則可以使用層次化查詢子句查詢出表中行記錄之間的層次關系,如:在一個表中,有兩個欄位:id,父id,則遞回查詢的意思是回圈查詢出具有遞回關系的資料,
語法:
1 [ START WITH CONDITION1 ] 2 CONNECT BY [ NOCYCLE ] CONDITION2 3 [ NOCYCLE ]
start with 子句為可選項,用來標識哪行作為查找樹型結構的第一行(即根節點,可指定多個根節點),若該子句被省略,則表示所有滿足查詢條件的行作為根節點,2.關于PRIOR PRIOR置于運算子前后的位置,決定著查詢時的檢索順序,
1. 從根節點自頂向下
1 select empno, mgr, level as lv 2 from scott.emp a 3 start with mgr is null 4 connect by (prior empno) = mgr 5 order by level;
--分析
層次查詢執行邏輯:
- 確定上一行(相對于步驟b中的當前行),若start with 子句存在,則以該陳述句確定的行為上一行,若不存在則將所有的資料行視為上一行,
- 從上一行出發,掃描除該行之外所有資料行,
- 匹配條件 (prior empno) = mgr
注意:
一元運算子 prior,意思是之前的,指上一行
當前行定義:步驟2中掃描得到的所有行中的某一行
匹配條件含義:當前行欄位 mgr 的值等于上一行欄位 empno中的值,若滿足則取出該行,并將level + 1,
匹配完所有行記錄后,將滿足條件的行作為上一行,執行步驟 2,3,直到所有行匹配結束,
2. 從根節點自底向上
1 select empno, mgr, level as lv 2 from scott.emp a 3 start with empno = 7876 4 connect by (prior mgr ) = empno 5 order by level;
--分析
層次查詢執行邏輯:
- 確定上一行(相對于步驟b中的當前行),若start with 子句存在,則以該陳述句確定的行為上一行,若不存在則將所有的資料行視為上一行,
- 從上一行出發,掃描除該行之外所有資料行,
- 匹配條件 (prior mgr ) = empno
注意:
一元運算子 prior,意思是之前的,指上一行,
當前行定義:步驟2中掃描得到的所有行中的某一行,
匹配條件含義:當前行欄位 empno 的值等于上一行欄位 mgr 中的值,若滿足則取出該行,并將 level + 1,
匹配完所有行記錄后,將滿足條件的行作為上一行,執行步驟2,3,直到所有行匹配結束,
3. 遞回查詢總結
自頂向下,自下向上口訣:
start with child_id = 10 connect by (prior child_id) = parent_id
prior 和 子列在一起,表示尋找它的子孫,即自頂向下,和父列在一起,表示開始尋找它的爸爸,即自下向上,
一列多行轉換成一行【listagg】
LISTAGG是Oracle 11g推出的,listagg函式的語法結構如下:
1 LISTAGG( [,]) WITHIN GROUP (ORDER BY ) [OVER (PARTITION BY )]
listagg雖然是聚合函式,但可以提供分析功能(比如可選的OVER()子句),使用listagg中,下列中的元素是必須的:
- 需要聚合的列或者運算式
- WITH GROUP 關鍵詞
- 分組中的ORDER BY子句
示例:
1 SELECT deptno,LISTAGG(ename, ',') WITHIN GROUP (ORDER BY deptno) AS employees FROM emp GROUP BY deptno;
拆分字串成多行【REGEXP_SUBSTR】
有一個問題,需要把一個帶有,的字串拆分成多行,通過查詢資料,這個操作需要使用以下2個關鍵知識:
- REGEXP_SUBSTR函式
- 為了實作動態引數,使用 connect by
REGEXP_SUBSTR語法:
1 function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
引數說明:
__srcstr :需要進行正則處理的字串
__pattern :進行匹配的正則運算式
__position :起始位置,從第幾個字符開始正則運算式匹配(默認為1)
__occurrence :標識第幾個匹配組,默認為1
__modifier :模式('i'不區分大小寫進行檢索;'c'區分大小寫進行檢索,默認為'c',)
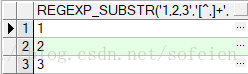
示例:
1 select regexp_substr('1,2,3','[^,]+',1,1) result from dual; 2 select regexp_substr('1,2,3','[^,]+',1,2) result from dual;
可以通過connect by可以構造連續的值,如下所示:
1 select rownum from dual connect by rownum<=7;

結合REGEXP_SUBSTR 及 connect by 即可實作拆分字串為多行的需求,最終的陳述句為:
1 SELECT REGEXP_SUBSTR ('1,2,3', '[^,]+', 1,rownum) 2 from dual connect by rownum<=LENGTH ('1,2,3') - LENGTH (regexp_replace('1,2,3', ',', ''))+1;
有則修改,無則插入【merge into】
當我們對一個表中資料執行操作:如果存在,進行修改;如果不存在,進行插入,此種情況下,采用merge into 陳述句最為合適,
merge info語法:
1 MERGE INTO [target-table] A USING [source-table sql] B ON([conditional expression] and [...]...) 2 3 WHEN MATCHED THEN 4 5 [UPDATE sql] 6 7 WHEN NOT MATCHED THEN 8 9 [INSERT sql]
merge into作用:
判斷B表和A表是否滿足ON中條件,如果滿足則用B表去更新A表,如果不滿足,則將B表資料插入A表但是有很多可選項,如下:
- 正常模式
- 只update或者只insert
- 帶條件的update或帶條件的insert
- 全插入insert實作
- 帶delete的update(覺得可以用3來實作)
merge into示例:
1 merge into score a 2 using (select std_no, c.dept_no 3 from student c 4 where c.std_no in 5 (select std_no from tmp_20210809)) b 6 on (a.std_no = b.std_no and a.balb_type = '01') 7 when matched then 8 update set a.pre_bal = nvl(a.pre_bal, 0) + 5.8 9 WHEN NOT MATCHED THEN 10 insert 11 (a.bal_id, a.std_no, a.balb_type, a.pre_bal, a.dept_no) 12 values 13 (序列, b.std_no, '01', 5.8, b.dept_no);
備注
在這個世上,根本就沒有所謂的一蹴而就,只有榷訓月累的努力,才有厚積薄發的可能,請沉下心來,不要好高騖遠,也不要總是去艷羨別人,專心做好自己的事,當你的才華配得上夢想時,好運自會不期而遇,
 作者:Alan.hsiang
作者:Alan.hsiang
出處:http://www.cnblogs.com/hsiang/
本文著作權歸作者和博客園共有,寫文不易,支持原創,歡迎轉載【點贊】,轉載請保留此段宣告,且在文章頁面明顯位置給出原文連接,謝謝,
關注個人公眾號,定時同步更新技術及職場文章
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/320941.html
標籤:Oracle