我正在加載一個帶有資料時間的csv檔案,當試圖使用df['times'] = pd.to_datetime(df['times'], format='%Y-%m-%d %H:%M:%S')進行轉換時,出現了錯誤。另外,請找到Jupyter筆記本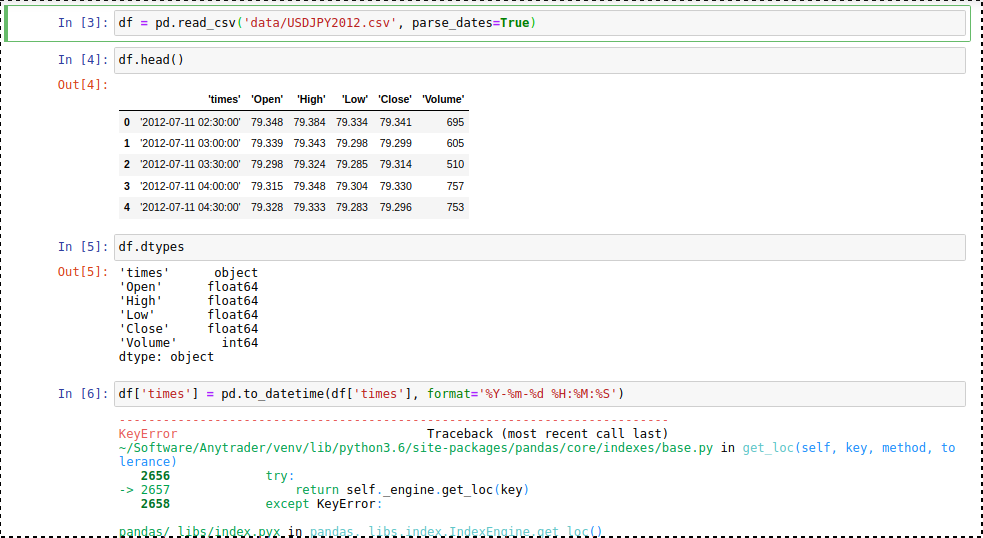
---------------------------------------------------------------------------
KeyError 回溯(最近一次呼叫)
~/Software/Anytrader/venv/lib/python3.6/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
2656 try:
-> 2657 return self._engine.get_loc(key)
2658 except KeyError:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.indexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.px in pandas._libs.hashable.PyObjectHashTable.get_item()
KeyError: 'times'/span>
在處理上述例外的程序中,發生了另一個例外。
KeyError 回溯(最近的一次呼叫)。
<ipython-input-6-4f05a9476911> in < module>
----> 1 df['times'] = pd. to_datetime(df['times'], format='%Y-%m-%d %H:%M:%S')
2 df.dtypes
~/Software/Anytrader/venv/lib/python3.6/site-packages/pandas/core/frame.py in __getitem__(self, key)。
2925 if self.columns.nlevels > 1:
2926 return self._getitem_multilevel(key)
-> 2927 indexer = self.columns.get_loc(key)
2928 if is_integer(indexer):
2929 indexer = [indexer] 。
~/Software/Anytrader/venv/lib/python3.6/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
2657 return self._engine.get_loc(key)
2658 except KeyError:
-> 2659 return self._engine.get_loc(self._maybe_cast_indexer(key))
2660 indexer = self.get_indexer([key], method=method, tolerance=tolerance)
2661 if indexer.ndim > 1 or indexer.size > 1:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.indexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.px in pandas._libs.hashable.PyObjectHashTable.get_item()
KeyError: 'times'。
uj5u.com熱心網友回復:
從你的截圖來看,你的列名包括引號。試試這個:
df["'times'"/span>] = pd. to_datetime(df["'times'"], format='%Y-%m-%d %H:%M:%S')
另一種方法(可能更好),你可以在從檔案中加載資料后立即從列名中剝離引號。
df.columns = df.columns.str.strip("' ")
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/323170.html
標籤: