如何使用openpyxl將pandas **多索引資料框架的結果連同列標題和索引值匯出到excel?
我認為我需要在 dataframe_to_rows() 方法中設定 index=True。然而,當我這樣做時,它拋出了一個 ValueError:指出它無法將 IndexLabel 值轉換為 excel 值。例如:
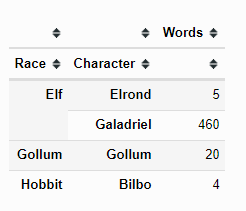
ValueError: 無法將('Elf', 'Elrond')轉換為 Excel。
我的當前代碼
我的當前代碼 注意:我有一個現有的excel模板檔案,其中有一個名為 "myPivot "的空作業表,我想把我的透視表寫進去。
我使用的資料集在這里: 我使用的資料集在這里
作業目錄中應該存在一個名為 p.s - 對
標籤: 下一篇:VBA如果單元格包含值,則復制它
import openpyxl
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
from pathlib import Path
multi_df = df.set_index(['Film', 'Chapter', 'Race', 'Character']).sort_index()
subset_df = multi_df.loc[('The Fellowship Of The Ring', '01: Prologue'), : ]
# 讀取TEMPLATE檔案,模板的副本將從該檔案中填充。
outfile = 'TEST_Pivot2XL_TEMPLATE.xlsx'/span>
template_filename = 'YYMMDD-YYMMDD_LOTR_TEMPLATE.xlsx'/span>
wb = openpyxl.load_workbook(Path(Path.cwd() / "ReportFiles" / "Summary" / str(模板_filename))
ws = wb["myPivot"]
for r in dataframe_to_rows(subset_df, index=True, header=True) 。
ws.append(r)
wb.save(file)
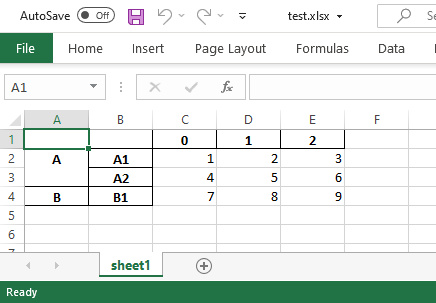
test.xlsx的檔案,這樣代碼才能發揮作用。請注意,它將寫到作業表的開頭,而不是追加到已經存在的內容。
writer.book和writer.sheet的賦值似乎沒有用,但ExcelWriter使用它們來計算哪些作業表已經存在,而不是寫新的作業表。