
一、Druid是什么
Druid 單詞來源于西方古羅馬的神話人物,中文常常翻譯成德魯伊,
玩過魔獸世界,暗黑破壞神,Dota,爐石傳說,Dota自走棋的朋友,對這個詞一定不陌生,
本文中所介紹的Druid是一個分布式的支持實時分析的資料存盤系統,通俗一點:高性能實時分析資料庫,它由美國廣告技術公司MetaMarkets于2011年創建,并且于2012年開源,MetaMarkets是一家專門為在線媒體公司提供資料服務的公司,主營是DSP廣告運營推送平臺,由于對實時性要求非常高,公司不得不放棄原始的大資料方案,Druid也就應運而生,
Druid的官方網站地址是:http://druid.io/
目前Druid已基于Apache License 2.0協議開源,正在由Apache范訓,代碼托管于Github,
最新官網地址為:
https://druid.apache.org/
阿里曾開源過一個專案叫做Druid是一個資料庫連接池,與本文所述Driud只是名字相同,并沒有什么聯系,Github上兩者都有相應的版本庫,
本文說的Druid是Apache Druid
Github地址:https://github.com/apache/druid/ 已經有9k+star 最新release版本已經到0.17 正處于上升期,
二、Druid特性與基本概念
Druid主要解決的問題就是傳統資料庫無法解決的大資料量查詢性能的問題,
所以她的本質就是一個分布式支持實時資料分析的資料存盤系統,
能夠快速的實作查詢與資料分析,高可用,高擴展能力,
特性
1.快速查詢:druid提供了快速的聚合能力以及快速OLAP查詢能力,多租戶的設計,是面向用戶分析應用的理想方式,druid的資料聚合粒度可以是1分鐘,5分鐘,1小時或者1天等,資料的記憶體化提高了druid的查詢速度,
OLAP:與之相對的是OLTP,這里通過一個在線商城舉例,比如在一個在線商城中兩者都是做什么呢?
- OLTP就是商品瀏覽,交易,用戶資料,必須支持事務,頻繁查詢修改, OLTP(聯機事務處理),傳統資料庫的主要應用,面向最基本的CRUD操作,特點是實時性高,資料量小,可以修改洗掉資料,要求有嚴格的事務,
- OLAP就是對商城資料進行分析,資料量大, OLAP(聯機分析處理),支持復雜的分析操作,對決策的支持,特點是資料量大,吞吐量大,只支持查詢,
2.實時資料注入:druid支持流資料的注入,并提供了資料的事件驅動,保證在實時和離線環境下事件的實效性和統一性,歷史資料不改變,實時資料實時接入,
3.可擴展的PB級存盤:druid集群可以很方便的擴容到PB的資料量,每秒百萬級別的資料注入,即便在加大資料規模的情況下,也能保證時其效性,druid可以按照時間范圍把聚合資料進行磁區處理,
4.多環境部署:druid既可以運行在商業的硬體上,也可以運行在云上,它可以從多種資料系統中注入資料,包括hadoop,spark,kafka,storm和samza等,
5.豐富的社區:druid擁有豐富的社區,供大家學習,
Metamarkets之前幾個druid開發者成立了一家叫做imply.io的新公司:https://imply.io/
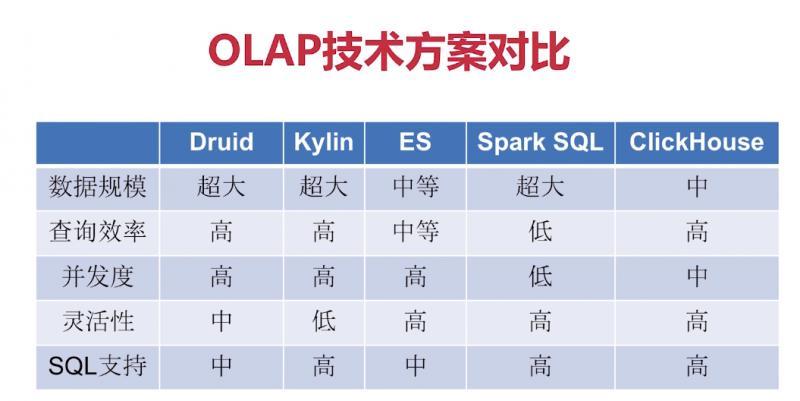
Druid與其他OLAP方案對比:
使用場景
根據Druid的特性可知,druid適合的場景:
-
查詢多修改很少
-
查詢以聚合或分組為主
-
快速查詢
-
需要支持離線和實時的資料源
由此可見Druid在實時計算中,作為實時報表和實時大屏的查詢環節非常的合適,
而且druid具有非常好的性能:
高擴展使用列式存盤的分布式系統;高容錯,自平衡,保證查詢延遲和資料完整性;自動聚合,索引資料,提供多種演算法優化查詢效率,
所以druid中一般保存的是聚合后的資料,
基本概念
1、資料格式
druid在資料攝入之前,首先需要定義一個資料源也就是Datasource,這個dataSource的結構是 時間列(TimeStamp),維度列(Dimension)和指標列(Metric),
時間列:druid會將時間相近的一些資料聚合在一起,查詢的時候指定時間范圍,
維度列:作為標識一些統計的維度,比如各種型別,
指標列:就是用于聚合和計算的列,包括count,sum等等,
2、資料攝入
druid提供了兩種資料攝入方式,實時和批處理,
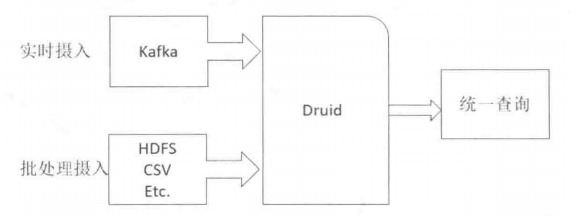
3、資料查詢
druid支持兩種查詢,原生和sql
sql查詢大同小異
[ EXPLAIN PLAN FOR ]
[ WITH tableName [ ( column1, column2, ... ) ] AS ( query ) ]
SELECT [ ALL | DISTINCT ] { * | exprs }
FROM table
[ WHERE expr ]
[ GROUP BY exprs ]
[ HAVING expr ]
[ ORDER BY expr [ ASC | DESC ], expr [ ASC | DESC ], ... ]
[ LIMIT limit ]
[ UNION ALL <another query> ]
druid的原生查詢采用json方式,通過http傳送,
一個druid查詢groupby的例子,指定了時間范圍,聚合粒度,資料源等,
{
"queryType": "groupBy",
"dataSource": "sample_datasource",
"granularity": "day",
"dimensions": ["country", "device"],
"limitSpec": { "type": "default", "limit": 5000, "columns": ["country", "data_transfer"] },
"filter": {
"type": "and",
"fields": [
{ "type": "selector", "dimension": "carrier", "value": "AT&T" },
{ "type": "or",
"fields": [
{ "type": "selector", "dimension": "make", "value": "Apple" },
{ "type": "selector", "dimension": "make", "value": "Samsung" }
]
}
]
},
"aggregations": [
{ "type": "longSum", "name": "total_usage", "fieldName": "user_count" },
{ "type": "doubleSum", "name": "data_transfer", "fieldName": "data_transfer" }
],
"postAggregations": [
{ "type": "arithmetic",
"name": "avg_usage",
"fn": "/",
"fields": [
{ "type": "fieldAccess", "fieldName": "data_transfer" },
{ "type": "fieldAccess", "fieldName": "total_usage" }
]
}
],
"intervals": [ "2012-01-01T00:00:00.000/2012-01-03T00:00:00.000" ],
"having": {
"type": "greaterThan",
"aggregation": "total_usage",
"value": 100
}
}
三、應用場景
druid常見應用領域包括:
- 點擊流分析(網路和移動分析)
- 風險/欺詐分析
- 網路遙測分析(網路性能監控)
- 服務器指標存盤
- 供應鏈分析(制造指標)
- 應用程式性能指標
- 商業智能/ OLAP
用戶行為分析
Druid可以用于,點擊流,視圖流,活動流,
準確地和近似地計算用戶指標,計算出日常活動用戶之類的平均指標,以查看總體趨勢,或者精確計算以呈現給運營部門,
數字營銷
Druid常用于存盤和查詢在線廣告資料,這些資料通常來自廣告服務器,對于衡量和了解廣告系列的效果,點擊率,轉化率(損耗率)等等,
OLAP和BI
Druid通常用于BI,與Hive之類的SQL-on-Hadoop引擎不同,Druid專為高并發性和亞秒級查詢而設計,可通過UI進行互動式資料探索,
總之,在實時計算應用越來越廣泛的今天,druid將憑借著她的高性能和OLAP的優勢,在實時的BI已經大屏等領域大放異彩!
靜下心來,努力的提升自己,永遠都沒有錯,更多實時計算相關博文,歡迎關注實時流式計算

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/32555.html
標籤:大數據