1.flink運行時的組件
![]() ?
?
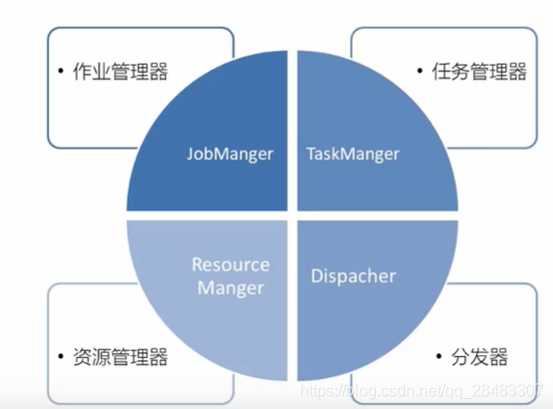
Flink 運行時架構主要包括四個不同的組件,它們會在運行流處理應用程式時協同作業:
作業管理器(JobManager)、資源管理器(ResourceManager)、任務管理器(TaskManager),
以及分發器(Dispatcher),因為 Flink 是用 Java 和 Scala 實作的,所以所有組件都會運行在
Java 虛擬機上,每個組件的職責如下:
1.1作業管理器(jobmanager)
- 控制一個應用程式執行的主行程,也就是說,每個應用程式都會被一個不同的JobManager 所控制執行,
- JobManager 會先接收到要執行的應用程式, 這個應用程式會包括:作業圖(JobGraph)、邏輯資料流圖(logical dataflow graph)和打包了所有的類、庫和其它資源的 JAR 包(也就是我們所說的job作業提交),
- jobManager 會把 JobGraph 轉換成一個物理層面的資料流圖,這個圖被叫做“執行圖”(ExecutionGraph),包含了所有可以并發執行的任務,
- JobManager 會向資源管理器(ResourceManager)請求執行任務必要的資源,也就是任務管理器(TaskManager)上的插槽( slot),一旦它獲取到了足夠的資源,就會將執行圖分發到真正運行它們的TaskManager 上,而在運行程序中, JobManager 會負責所有需要中央協調的操作,比如說檢查點(checkpoints)的協調,
1.2任務管理器(task manager)
- Flink 中的作業行程,通常在 Flink 中會有多個 TaskManager 運行,每一個 TaskManager都包含了一定數量的插槽(slots),插槽的數量限制了 TaskManager 能夠執行的任務數量,
- 啟動之后, TaskManager 會向資源管理器注冊它的插槽;收到資源管理器的指令后,TaskManager 就會將一個或者多個插槽提供給 JobManager 呼叫, JobManager 就可以向插槽分配任務(tasks)來執行了,
- 在執行程序中,一個 TaskManager 可以跟其它運行同一應用程式的 TaskManager 交換資料,
1.3資源管理器(resource manager)
- 主要負責管理任務管理器(TaskManager)的插槽(slot), TaskManger 插槽是 Flink 中定義的處理資源單元,
- Flink 為不同的環境和資源管理工具提供了不同資源管理器,比如YARN、 Mesos、 K8s,以及 standalone 部署,
- 當 JobManager 申請插槽資源時, ResourceManager會將有空閑插槽的 TaskManager 分配給 JobManager,如果 ResourceManager 沒有足夠的插槽來滿足 JobManager 的請求,它還可以向資源提供平臺發起會話,以提供啟動 TaskManager行程的容器,另外, ResourceManager 還負責終止空閑的 TaskManager,釋放計算資源,
1.4分發器(dispatcher)
- 可以跨作業運行,它為應用提交提供了 REST 介面,
- 當一個應用被提交執行時,分發器就會啟動并將應用移交給一個 JobManager,由于是 REST 介面,所以 Dispatcher 可以作為集群的一個 HTTP 接入點,這樣就能夠不受防火墻阻擋,
- Dispatcher 也會啟動一個 Web UI,用來方便地展示和監控作業執行的資訊,
- Dispatcher 在架構中可能并不是必需的,這取決于應用提交運行的方式,
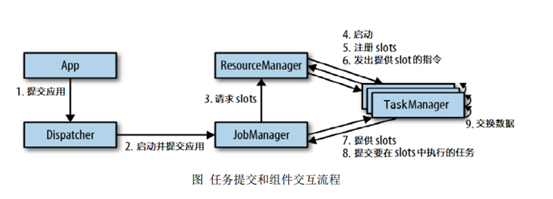
2.任務提交流程
![]() ?
?
上圖是從一個較為高層級的視角,來看應用中各組件的互動協作,
- 首先 通過Rest介面提交給了分發器dispatcher
- dispatcher啟動jobmanager,并且將應用交給jobmanager
- jobmanager向ResourceManager申請資源
- ResourceManger就會啟動taskmanager,空閑的slots就會向ResourceManager注冊
- ResourceManager會對taskmanager發出提供slot的指令
- taskmanager與jobmanager進行通信(心跳通信)
- taskmanager提供slots給jobmanager
- jobmanager給slots分配任務
- 不同的taskmanager在執行任務時,會根據需要交換資料
如果部署的集群環境不同(例如 YARN, Mesos, Kubernetes, standalone 等),其中一些步驟可以被省略,或是有些組件會運行在同一個 JVM 行程中,
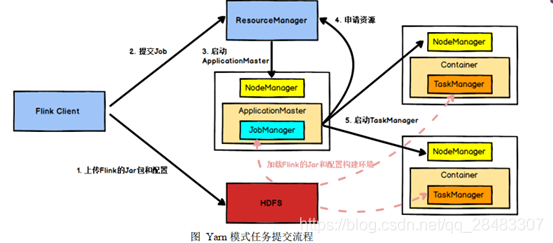
具體地,如果我們將 Flink 集群部署到 YARN 上,那么就會有如下的提交流程:
![]() ?
?
- Flink 任務提交后, Client 向 HDFS 上傳 Flink 的 Jar 包和配置
- 之后向 YarnResourceManager 提交任務, ResourceManager(YARN的資源管理器) 分配 Container 資源并通知對應的NodeManager 啟動 ApplicationMaster, ApplicationMaster 啟動后加載hdfs上的 Flink 的 Jar 包和配置構建環境
- 然后啟動 JobManager,之后 ApplicationMaster 向 ResourceManager申 請 資 源 啟 動 TaskManager
- ResourceManager 分 配 Container 資 源 后 , 由ApplicationMaster 通 知 資 源 所 在 節 點 的 NodeManager 啟 動 TaskManager ,NodeManager 加載 Flink 的 Jar 包和配置構建環境并啟動 TaskManager,
- TaskManager啟動后向 JobManager 發送心跳包,并等待 JobManager 向其分配任務,
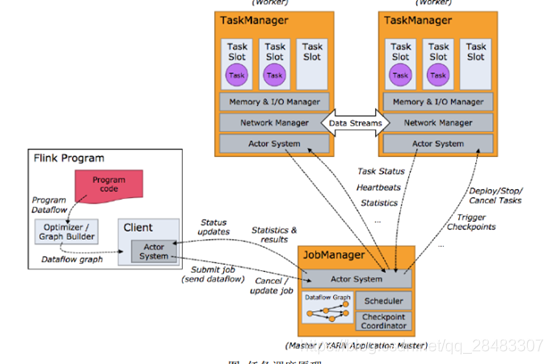
3.任務調度流程
![]() ?
?
- flink程式代碼,編譯打包后,會先生成初始的邏輯資料流圖(Dataflow graph)
- 通過提交任務的客戶端(client),提交給dispatcher或者resourcemanager(flink on yarn),最終是給到jobmanager,
- jobmanager將Dataflow graph 轉換為可執行的execution graph(可執行的資料流圖),發送給所有的taskmanager
- 每一個taskmanager都有task slot,slots并行執行
當 Flink 集 群 啟 動 后 , 首 先 會 啟 動 一 個 JobManger 和 一 個 或 多 個 的
TaskManager,由 Client 提交任務給 JobManager, JobManager 再調度任務到各個
TaskManager 去執行,然后 TaskManager 將心跳和統計資訊匯報給 JobManager,
TaskManager 之間以流的形式進行資料的傳輸,上述三者均為獨立的 JVM 行程,
Client 為提交 Job 的客戶端,可以是運行在任何機器上(與 JobManager 環境
連通即可),提交 Job 后, Client 可以結束行程( Streaming 的任務),也可以不
結束并等待結果回傳,
JobManager 主 要 負 責 調 度 Job 并 協 調 Task 做 checkpoint, 職 責 上 很 像
Storm 的 Nimbus,從 Client 處接收到 Job 和 JAR 包等資源后,會生成優化后的
執行計劃,并以 Task 的單元調度到各個 TaskManager 去執行,
TaskManager 在啟動的時候就設定好了槽位數( Slot),每個 slot 能啟動一個
Task, Task 為執行緒,從 JobManager 處接收需要部署的 Task,部署啟動后,與自
己的上游建立 Netty 連接,接收資料并處理,
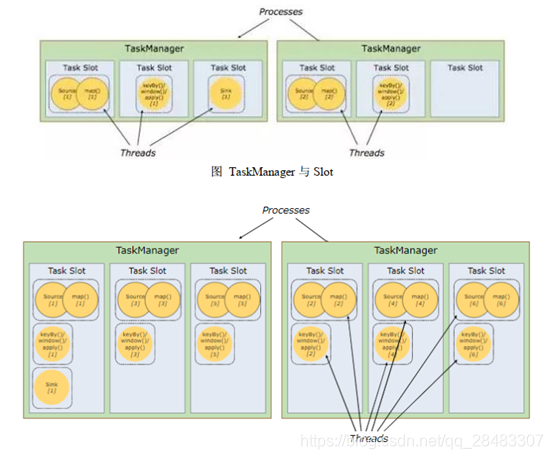
4.TaskManager與Slots
每個 task slot 表示 TaskManager 擁有資源的一個固定大小的子集,假如一個TaskManager 有三個 slot,那么它會將其管理的記憶體分成三份給各個 slot,資源 slot化意味著一個 subtask 將不需要跟來自其他 job 的 subtask 競爭被管理的記憶體,取而代之的是它將擁有一定數量的記憶體儲備,需要注意的是,這里不會涉及到 CPU 的隔離, slot 目前僅僅用來隔離 task 的受管理的記憶體,
通過調整 task slot 的數量,允許用戶定義 subtask 之間如何互相隔離,如果一個TaskManager 一個 slot,那將意味著每個 task group 運行在獨立的 JVM 中(該 JVM可能是通過一個特定的容器啟動的),而一個 TaskManager 多個 slot 意味著更多的subtask 可以共享同一個 JVM,而在同一個 JVM 行程中的 task 將共享 TCP 連接(基于多路復用)和心跳訊息,它們也可能共享資料集和資料結構,因此這減少了每個task 的負載,
![]() ?
?
- flink中每一個TaskManager都是一個JVM行程,它可能在獨立的執行緒上執行一個或者多個subtask
- 為了控制一個TaskManager能接受多少個task,Taskmanager通過task slot來進行控制(一個Taskmanager至少有一個slot)
- 每臺機子設定的slot數量,通常可以設定為cpu的執行緒數
- 默認情況下, Flink 允許子任務共享 slot,即使它們是不同任務的子任務(前提是它們來自同一個 job) , 這樣的結果是,一個 slot 可以保存作業的整個管道,
- Task Slot 是靜態的概念,是指 TaskManager 具有的并發執行能力
可以通過引數 taskmanager.numberOfTaskSlots 進行配置; 而并行度 parallelism 是動態概念,即 TaskManager 運行程式時實際使用的并發能力,可以通過引數 parallelism.default進行配置,也就是說,假設一共有 3 個 TaskManager,每一個 TaskManager 中的分配 3 個TaskSlot,也就是每個 TaskManager 可以接收 3 個 task,一共 9 個 TaskSlot,如果我們設定 parallelism.default=1,即運行程式默認的并行度為 1, 9 個 TaskSlot 只用了 1個,有 8 個空閑,因此,設定合適的并行度才能提高效率,
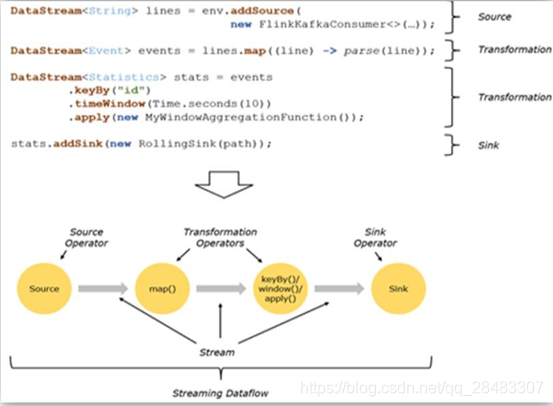
5.程式與資料流(DataFlow)
![]() ?
?
所有的 Flink 程式都是由三部分組成的: Source 、 Transformation 和 Sink,
Source 負責讀取資料源, Transformation 利用各種算子進行處理加工, Sink 負責輸出,
在運行時, Flink 上運行的程式會被映射成“邏輯資料流”( dataflows) ,它包含了這三部分, 每一個 dataflow 以一個或多個 sources 開始以一個或多個 sinks 結束, dataflow 類似于任意的有向無環圖( DAG),在大部分情況下,程式中的轉換運算( transformations) 跟 dataflow 中的算子(operator) 是一一對應的關系,但有時候,一個 transformation 可能對應多個 operator,
6.執行圖(ExecutionGraph)
由 Flink 程式直接映射成的資料流圖是 StreamGraph,也被稱為邏輯流圖,因為它們表示的是計算邏輯的高級視圖,為了執行一個流處理程式, Flink 需要將邏輯流圖轉換為物理資料流圖(也叫執行圖) ,詳細說明程式的執行方式,
Flink 中的執行圖可以分成四層: StreamGraph -> JobGraph -> ExecutionGraph ->物理執行圖,
- StreamGraph:是根據用戶通過 Stream API 撰寫的代碼生成的最初的圖,用來表示程式的拓撲結構,
- JobGraph: StreamGraph 經過優化后生成了 JobGraph,提交給 JobManager 的資料結構,主要的優化為,將多個符合條件的節點 chain 在一起作為一個節點,這樣可以減少資料在節點之間流動所需要的序列化/反序列化/傳輸消耗,
- ExecutionGraph : JobManager 根 據 JobGraph 生 成 ExecutionGraph ,ExecutionGraph 是 JobGraph 的并行化版本,是調度層最核心的資料結構,
- 物理執行圖: JobManager 根據 ExecutionGraph 對 Job 進行調度后,在各個TaskManager 上部署 Task 后形成的“圖”,并不是一個具體的資料結構,

![]() ?
?
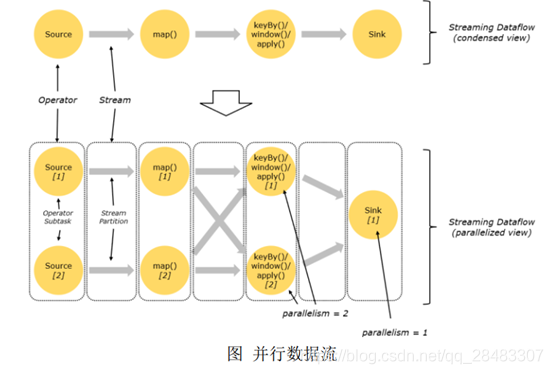
7.并行度(Parallelism)
Flink 程式的執行具有并行、分布式的特性,
在執行程序中,一個流( stream) 包含一個或多個磁區( stream partition) ,而每一個算子( operator)可以包含一個或多個子任務( operator subtask) ,這些子任務在不同的執行緒、不同的物理機或不同的容器中彼此互不依賴地執行,
一個特定算子的子任務( subtask) 的個數被稱之為其并行度( parallelism) ,
一般情況下, 一個流程式的并行度,可以認為就是其所有算子中最大的并行度,一
個程式中,不同的算子可能具有不同的并行度,
尚硅谷大資料技術之 Flink
![]() ?
?
Stream 在算子之間傳輸資料的形式可以是 one-to-one(forwarding)的模式也可以
是 redistributing 的模式,具體是哪一種形式,取決于算子的種類,
One-to-one: stream(比如在 source 和 map operator 之間)維護著磁區以及元素的
順序,那意味著 map 算子的子任務看到的元素的個數以及順序跟 source 算子的子
任務生產的元素的個數、順序相同, map、 fliter、 flatMap 等算子都是 one-to-one 的
對應關系,(PS.類似于 spark 中的窄依賴)
Redistributing: stream(map()跟 keyBy/window 之間或者 keyBy/window 跟 sink
之間)的磁區會發生改變,每一個算子的子任務依據所選擇的 transformation 發送數
據到不同的目標任務,例如, keyBy() 基于 hashCode 重磁區、 broadcast 和 rebalance
會隨機重新磁區,這些算子都會引起 redistribute 程序,而 redistribute 程序就類似于
Spark 中的 shuffle 程序,(PS.類似于 spark 中的寬依賴)
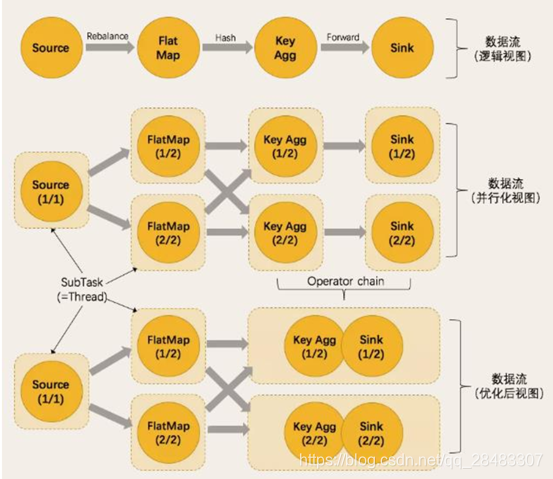
8.任務鏈(Operator Chains)
相同并行度的 one to one 操作, Flink 這樣相連的算子鏈接在一起形成一個 task,原來的算子成為里面的一部分,將算子鏈接成 task 是非常有效的優化:它能減少執行緒之間的切換和基于快取區的資料交換,在減少時延的同時提升吞吐量,鏈接的行為可以在編程 API 中進行指定,
![]() ?
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/32575.html
標籤:大數據
下一篇:「Flink」事件時間與水印