一、安裝準備
本次安裝的版本是截止2020.1.30最新的版本0.17.0
軟體要求
-
需要Java 8(8u92 +)以上的版本,否則會有問題
-
Linux,Mac OS X或其他類似Unix的作業系統(不支持Windows)
硬體要求
Druid包括一組參考配置和用于單機部署的啟動腳本:
nano-quickstartmicro-quickstartsmallmediumlargexlarge
單服務器參考配置
Nano-Quickstart:1個CPU,4GB RAM
- 啟動命令:
bin/start-nano-quickstart - 配置目錄:
conf/druid/single-server/nano-quickstart
微型快速入門:4個CPU,16GB RAM
- 啟動命令:
bin/start-micro-quickstart - 配置目錄:
conf/druid/single-server/micro-quickstart
小型:8 CPU,64GB RAM(?i3.2xlarge)
- 啟動命令:
bin/start-small - 配置目錄:
conf/druid/single-server/small
中:16 CPU,128GB RAM(?i3.4xlarge)
- 啟動命令:
bin/start-medium - 配置目錄:
conf/druid/single-server/medium
大型:32 CPU,256GB RAM(?i3.8xlarge)
- 啟動命令:
bin/start-large - 配置目錄:
conf/druid/single-server/large
大型X:64 CPU,512GB RAM(?i3.16xlarge)
-
啟動命令:
bin/start-xlarge -
配置目錄:
conf/druid/single-server/xlarge
我們這里做測驗使用選擇最低配置即可nano-quickstart
二、下載安裝包
訪問官網:
http://druid.io/現在也會跳轉https://druid.apache.org/
或者直接訪問https://druid.apache.org/
點擊download進入下載頁面:
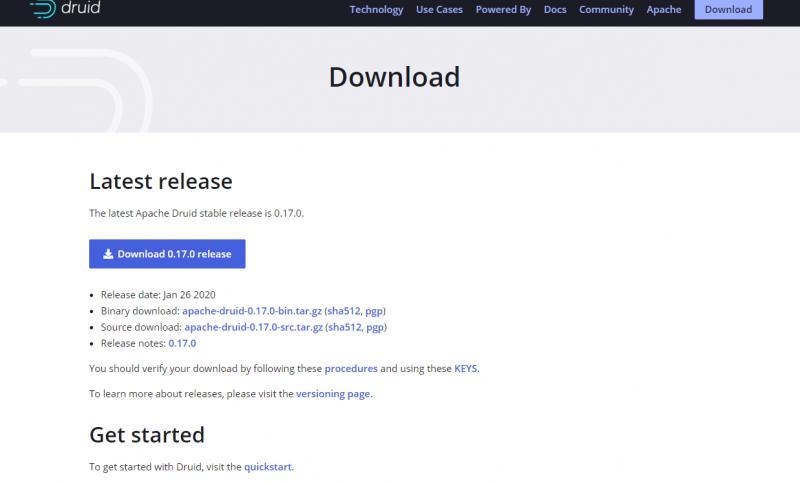
選擇最新版本: apache-druid-0.17.0-bin.tar.gz 進行下載
200多M

也可以選擇下載原始碼包 用maven進行編譯
三、安裝
上傳安裝包
在終端中運行以下命令來安裝Druid:
tar -xzf apache-druid-0.17.0-bin.tar.gz
cd apache-druid-0.17.0
安裝包里有這幾個目錄:
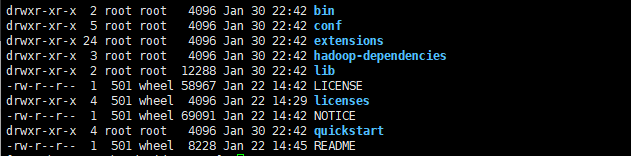
LICENSE和NOTICE檔案bin/*-腳本conf/*-單服務器和集群設定的示例配置extensions/*-擴展hadoop-dependencies/*-Druid Hadoop依賴lib/*-Druid庫quickstart/*-快速入門教程的組態檔,樣本資料和其他檔案
組態檔
#進入我們要啟動的組態檔位置:
cd conf/druid/single-server/nano-quickstart/

_common 公共配置

是druid一些基本的配置,比如元資料庫地址 各種路徑等等
其他的是各個節點的配置
比較類似,比如broker
cd broker/

jvm配置
main配置
runtime運行時相關的配置
回到主目錄
啟動的conf在
cd conf/supervise/single-server
里面是不同配置啟動不同的腳本
四、啟動
回到主目錄
./bin/start-nano-quickstart
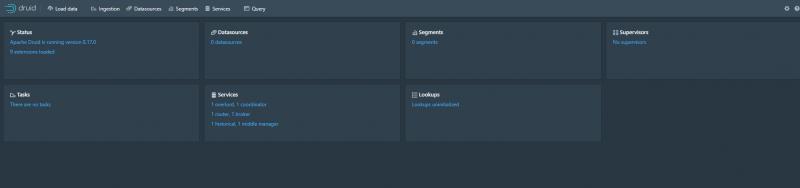
啟動成功:

訪問
localhost:8888
看到管理頁面
如果要修改埠,需要修改配置的埠和主目錄下的
vi bin/verify-default-ports
五、加載資料
Druid提供了一個示例資料檔案,其中包含2015年9月12日發生的Wiki的示例資料,
此樣本資料位于quickstart/tutorial/wikiticker-2015-09-12-sampled.json.gz
示例資料大概是這樣:
{
"timestamp":"2015-09-12T20:03:45.018Z",
"channel":"#en.wikipedia",
"namespace":"Main",
"page":"Spider-Man's powers and equipment",
"user":"foobar",
"comment":"/* Artificial web-shooters */",
"cityName":"New York",
"regionName":"New York",
"regionIsoCode":"NY",
"countryName":"United States",
"countryIsoCode":"US",
"isAnonymous":false,
"isNew":false,
"isMinor":false,
"isRobot":false,
"isUnpatrolled":false,
"added":99,
"delta":99,
"deleted":0,
}
Druid加載資料分為以下幾種:
- 加載檔案
- 從kafka中加載資料
- 從hadoop中加載資料
- 自定義加載方式
我們這樣演示一下加載示例檔案資料
1、進入localhost:8888 點擊load data
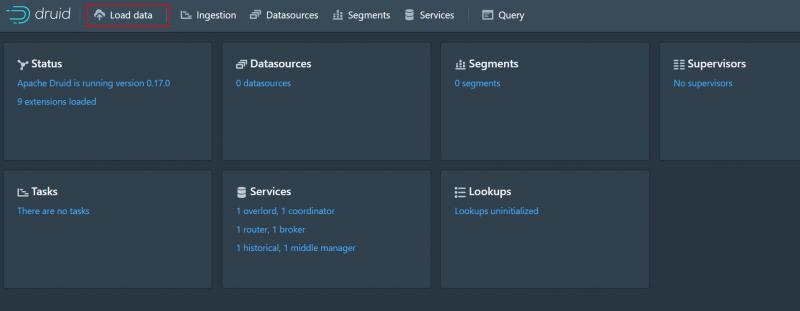
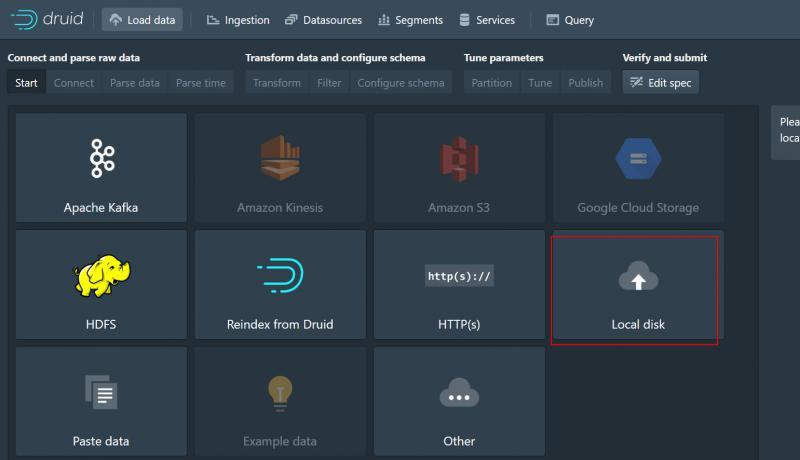
2、選擇local disk
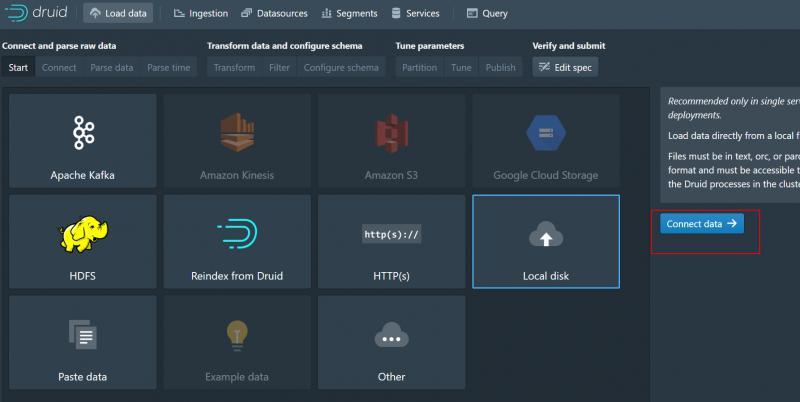
3、選擇Connect data
4、預覽資料
Base directory輸入quickstart/tutorial/
File filter輸入 wikiticker-2015-09-12-sampled.json.gz
然后點擊apply預覽 就可以看見資料了 點擊Next:parse data決議資料
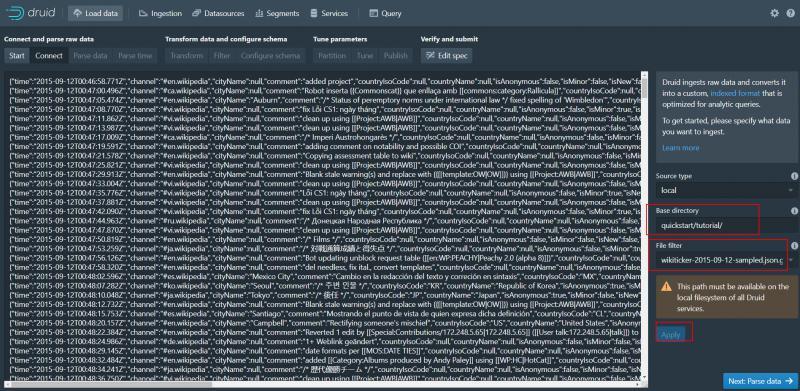
5、決議資料
可以看到json資料已經被決議了 繼續決議時間
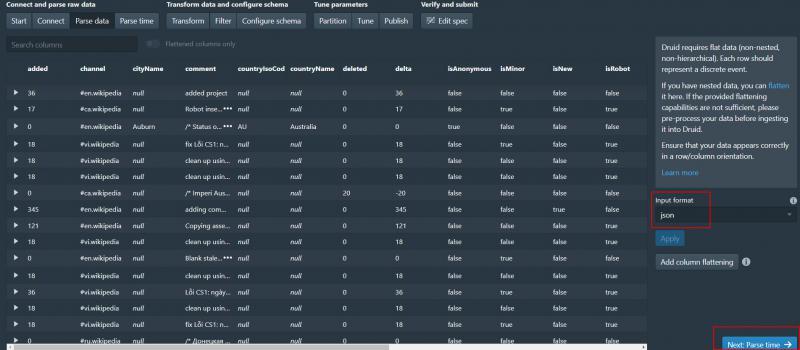
6、決議時間
決議時間成功 之后兩步是transform和filter 這里不做演示了 直接next
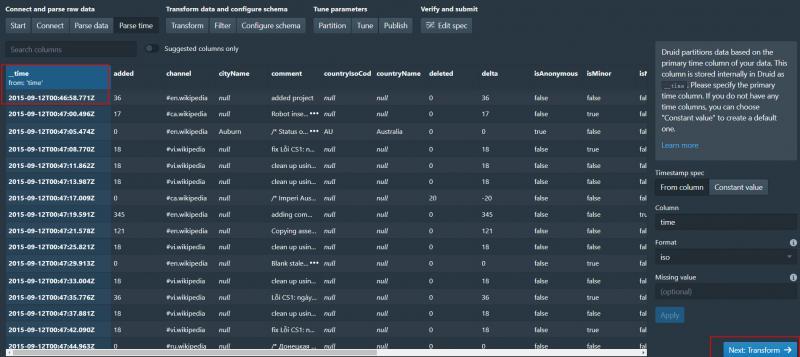
7、確認Schema
這一步會讓我們確認Schema 可以做一些修改
由于資料量較小 我們直接關掉Rollup 直接下一步
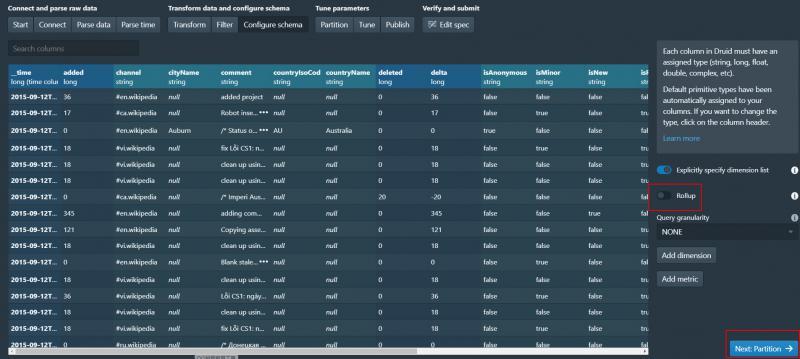
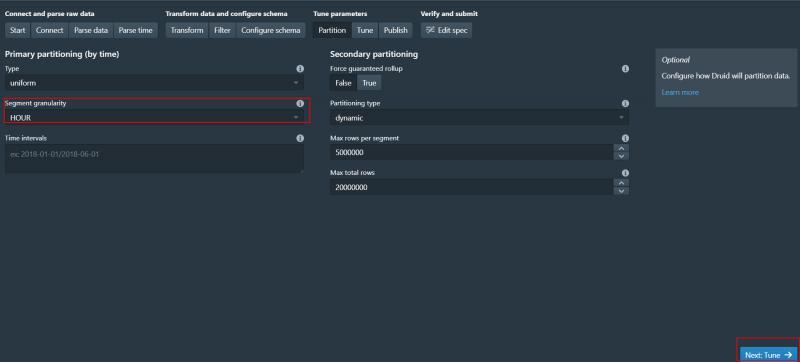
8、設定分段
這里可以設定資料分段 我們選擇hour next
9、確認發布
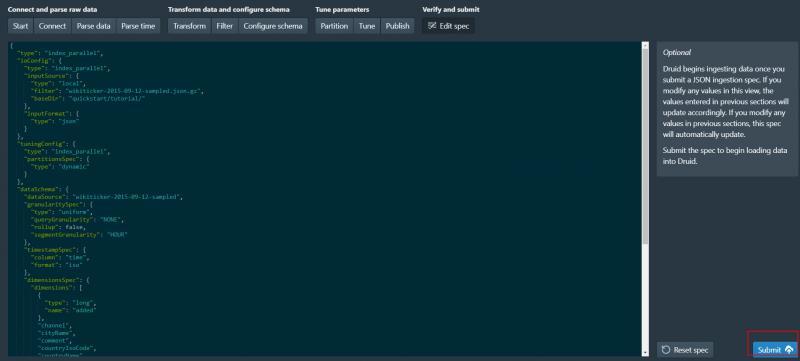
10、發布成功 開始決議資料
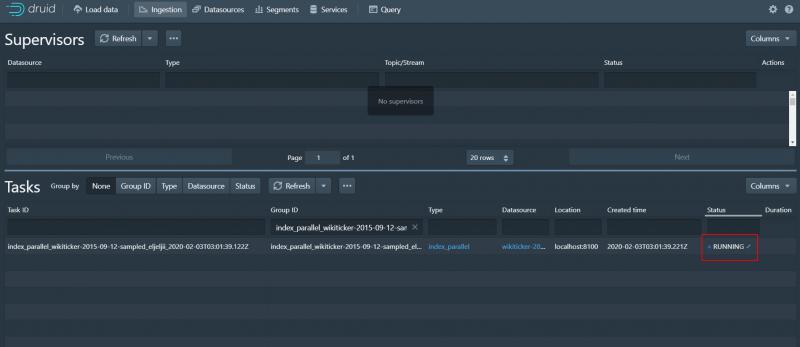
等待任務成功
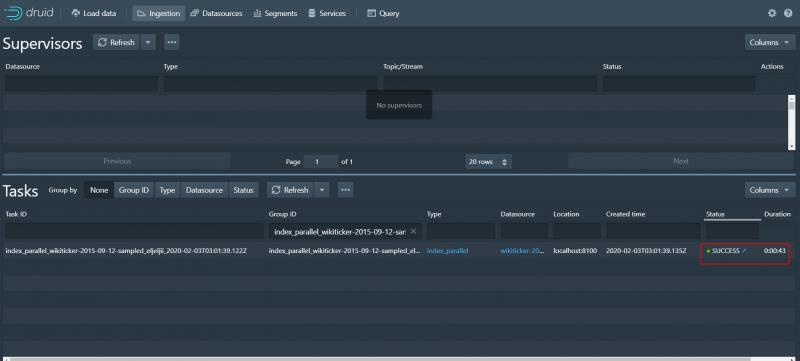
11、查看資料
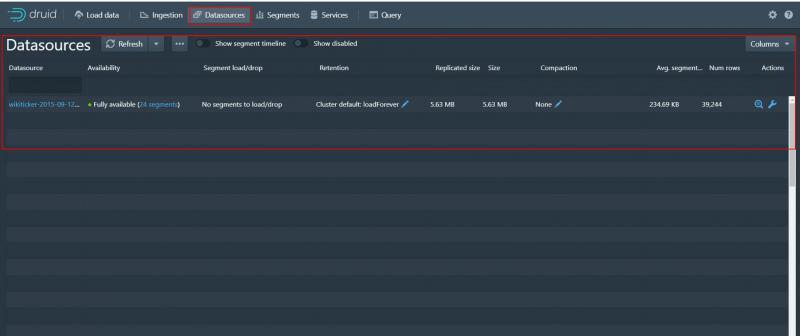
選擇datasources 可以看到我們加載的資料
可以看到資料源名稱 Fully是完全可用 還有大小等各種資訊
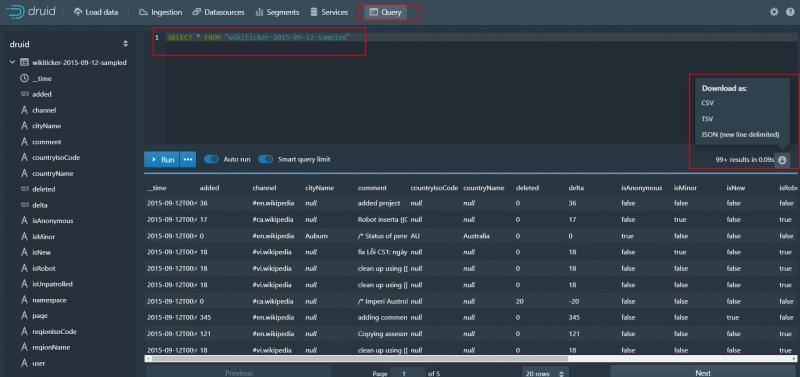
12、查詢資料
點擊query按鈕
我們可以寫sql查詢資料了 還可以將資料下載
Druid相關博文
什么是Druid
靜下心來,努力的提升自己,永遠都沒有錯,更多實時計算相關博文,歡迎關注實時流式計算

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/32586.html
標籤:大數據
上一篇:「Flink」事件時間與水印