假設我有500個隨機的3D點,用一個(500, 3)陣串列示:
import numpy as np
np.random.seed(99)
points = np.random.uniform(0, 10, (500, 3)
現在我想從這500個點中抽取n = 20個點,以便所有成對距離的最小值為最大。我正在使用一種貪婪的方法,每次都對最小距離最大化的點進行采樣。下面是我的Python實作:
from scipy.spatial import distance_matrix
def sample_n_points(points, n) 。
sampled_points = [point[0]]
remained_points = points[1 :]
n_sampled = 1 ]
while n_sampled < n。
min_dists = distance_matrix(resid_points, sampled_points).min(axis=1)
imax = np.argmax(min_dists)
sampled_points.append(remained_points[imax])
np.delete(remained_points, (imax), axis=0)
n_sampled = 1 1
return np.asarray(sampled_points)
print(sample_n_points(point, n=20)
輸出:
[[6.72278559 4.88078399 8.25495174]
[1.01317279 9.74063145 0.15102072]
[5.21672436 0.39259574 0.1069965 ]
[9.89383494 9.77095442 1.15681204]
[0.77144184 9.99325146 9.8976312 ]
[0.04558333 2.34842151 5.25634324]
[9.58126175 0.57371576 5.01765991]
[9.93010888 9.959526 9.18606297]
[5.27648557 9.93960401 4.82093673]
[2.97622499 0.46695721 9.90627399]
[0.28351187 3.64220133 0.06793617]
[6.27527665 5.58177254 0.3544929 ]
[0.4861886 7.45547887 5.342708 ]
[0.83203965 5.00400167 9.40102603]
[5.21120971 2.89966623 4.24236342]
[9.18165946 0.26450445 9.58031481]
[5.47605481 9.4493094 9.94331621]
[9.31058632 6.36970353 5.33362741]
[9.47554604 2.31761252 1.53774694]
[3.99460408 6.17908899 6.00786122 ]]
然而,通過使用這段代碼,并不能保證有一個最佳解決方案。我的代碼最明顯的 "錯誤 "是,它總是從第一個點開始采樣。當然,我可以用每一個點作為起點來運行我的代碼,最后取一個最小距離最大化的點,但即使這樣也不會得到最優解。這些點在開始時彼此相距甚遠,但隨著更多的點被采樣,它們被迫彼此靠近。經過一番思考,我意識到這個問題基本上變成了
。在一組三維點中找到分布最均勻的子集。
我想知道是否有任何演算法可以相對快速地找到最優解或給出一個好的近似值?
編輯
這個優化問題的決策問題版本是:
給定一個距離閾值t,是否有可能找到一個n個點的子集,使子集中的每一對點都至少相距t。
從圖的角度來看,這可以解釋為
在歐氏圖中尋找一個獨立的集合,如果成對的距離d(v1,v2)≤t,則點v1, v2之間有一條邊。
如果我們能夠解決這個決策問題,那么優化問題也可以通過對閾值t的二進制搜索來解決。
uj5u.com熱心網友回復:
希望我已經理解了你的要求。
從你的開始說起:
from scipy.spatial import distance_matrix
import numpy as np
np.random.seed(99)
points = np.random.uniform(0, 10, (500, 3)
你應該得到所有點之間的距離,并按距離排序:
# get distances between all points
d = distance_matrix(point, points)
# 歸零相同的上層三角形 # 歸零相同的上層三角形
dt = np.tril(d)
#列出距離和它們的索引。
dtv = [(dt[i, j], i, j) for (i, j) in np.argwhere(dt > 0)]
# 排序串列
dtvs = sorted(dtv, key=lambda x: x[0], reverse=True)
然后你可以增長一個集合,以獲得對最大距離有貢獻的20個點的索引。
編輯將結果限制在k唯一的點的索引。
kpoint_index = set()
k = 20
i =0
for p in (j for i in dtvs for j in i[1: ]):
kpoint_index.add(p)
if len(kpoint_index) == k。
break
print("index to points:"/span>, kpoint_index)
給定:
index to points: {393, 11, 282, 415, 160, 302, 189, 319, 194, 453, 73, 74, 459, 335, 469, 221, 103, 232, 236, 383}。
這個運行速度相當快 - 但我沒有計時。
uj5u.com熱心網友回復:
在一些富有啟發性的評論之后,我認識到精確的解決方案對于中等規模的問題來說也是難以解決的。
一個可能的近似解決方案是使用K-means聚類。這里有一個二維的例子,我可以在其中加入一個圖表。
np.random.seed(99)
n=500
k = 20 20
pts2D = np.random.uniform(0, 10, (n, 2)
kmeans = KMeans(n_clusters=k, random_state=0).fit(pts2D)
標簽 = kmeans.predict(pts2D)
cntr = kmeans.cluster_centers_。
現在我們可以找到哪個原始點離每個聚類中心最近了:
# indices of nearest points to centres
approx = []
for i, c in enumerate(cntr):
lab = np.where(labels == i)[0]
pts = pts2D[lab]
d = distance_matrix(c[None, ...], pts)
idx1 = np.argmin(d, axis=1) 1
idx2 = np.searchsorted(np.cumsum(labs == i), idx1)[0]
approx.append(idx2)
然后,我們可以將結果繪制出來:
fig, ax = plt.subplots(figsize=(5, 5)
ax.plot(pts2D[:, 0], pts2D[:, 1], '. ' )
ax.plot(cntr[:, 0], cntr[:, 1], 'x'/span>)
ax.plot(pts2D[approx, 0], pts2D[approx, 1], 'r。')
ax.set_aspect("equal")
fig.legend(["點", "中心", "選定"], loc=1)
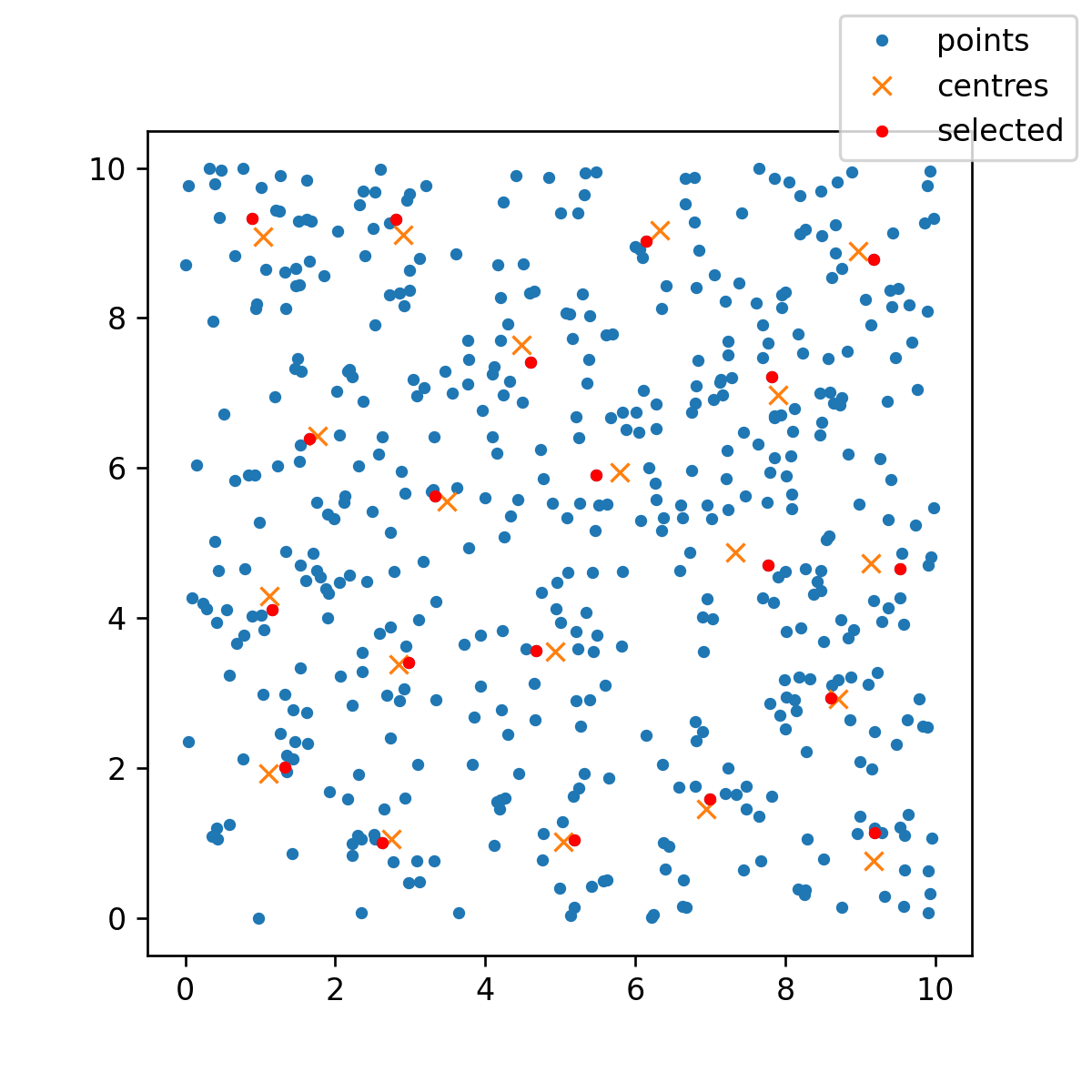
最后,如果真實的點總是均勻分布的,你可以通過均勻地放置 "中心 "并選擇離每個點最近的點來獲得一個很好的近似。這樣就不需要K-means了。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/326843.html
標籤: