試圖創建一個用于測驗管理的Python程式。問題被存盤在一個SQLLite資料庫中。每個問題都有一個ID、Marks欄位(以及其他欄位)。我們的目的是,管理員可以使用formulate()函式來傳遞引數,說明他們希望每個分數有多少個問題。例如,測驗資料庫中有3分、5分和10分的問題。因此,如果管理員想選擇2個3分的問題、4個5分的問題和1個10分的問題,他們可以簡單地使用
。formulate ([2,3] [4,5] [1,10]),該函式將能夠為每個計數隨機抽取問題。
我還想使用一個構造器來獲得一些關于OOP方面的練習。我已經設法讓它在一個單一的集合中作業,即formulate([2,3]),但我不確定如何在一個引數中允許多個分陣列。也不知道如何正確使用建構式。
def __init__(self, quizparam)。
self._quizpaper = quizparam
quizparam[key]
def formulate(quizparam)。
conn = sqlite3.connect("QuizApp.DB"/span>)
cur = conn.cursor()
sql_query = "SELECT id, key FROM questions WHERE marks = ('%d') ORDER BY RANDOM() LIMIT ('%d')" %(quizparam[0],quizparam[1])
cur.execute(sql_query)
out = cur.fetchall()
variable = {key:val for key,val in out }
print(variable)
conn.close()
下面是我對一個單引數集的輸出
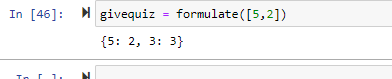
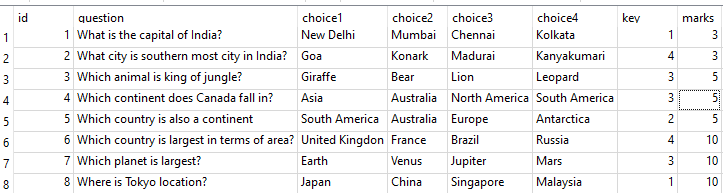
這是我的SQL Lite DB
uj5u.com熱心網友回復:
這里有幾個要點需要解決。 讓我們考慮一下這些:
我不太確定你在使用建構式和__init__函式方面想要什么。 這可能比我們需要的更復雜,所以現在讓我們專注于讓formulate函式作業。
引數化查詢
你的SQLite查詢使用字串替換來指定 "mark "值和查詢限制。 這可以作業,但最好的做法是使用引數化查詢。 基本上,我們可以在SQL文本中使用?,然后在cur.execute()呼叫中提供替換值。 資料庫本身會處理這些值的替換。
而不是這樣:
sql_query = "SELECT id, key FROM questions WHERE marks = ('%d') ORDER BY RANDOM() LIMIT ('%d')"%(quizparam[0],quizparam[1] )
cur.execute(sql_query)
試一下:
sql_query = "SELECT id, key FROM questions WHERE marks=? ORDER BY RANDOM() LIMIT ? ;"
cur.execute(sql_query, (quizparam[0], quizparam[1] )
靈活的函式引數
你的formulate函式可以對一個引數起作用,但是為了讓它靈活地接受多個引數,我們需要從:
def forumlate(quizparam)。
對此:
def formulate(*quizparams) 。
*允許該函式接受任意數量的引數,然后quizparams捕獲這些引數。
下面的函式將通過回圈處理存盤在quizparams中的[num_q, marks]引數來處理一個或多個引數。
def formulate(*quizparams)。
conn = sqlite3.connect("QuizApp.DB"/span>)
cur = conn.cursor()
結果 = [] # 將是一個形式為[(id, key), (id, key), ...]/span>的圖元串列。
# 現在回圈瀏覽這些引數。
# 同時,將每個引數對解包為 "num_question "和 "marks "兩個變數。
for num_q, marks in quizparams:
sql_query = "SELECT id, key FROM questions WHERE marks=? ORDER BY RANDOM() LIMIT ?;"
cur.execute(sql_query, (marks, num_q)) #引數化查詢
results.extend(cur.fetchall())
conn.close()
print(results)
制定([2,3], [1,5] )
>>> [(1, 1), (2, 4), (3, 3) ]
替代性方法
上面的formulate函式對于你所描述的需求非常有效。 資料庫可以處理我們所要求的id和key,并對結果進行隨機化和限制。 如果你有大量的測驗問題(如數十萬),那么這無疑是最好的解決方案。
但就個人而言,我通常更傾向于盡量減少資料庫互動代碼,并使用 Python 處理更多的邏輯。 下面的解決方案使用了我寫的 "easy_db "庫來簡化資料庫作業。 只需用pip安裝即可:
pip install easy_db
下面的函式簡化了與我們的資料庫的互動,并在Python而不是SQL中應用邏輯。 此外,我們正在為每個問題提取整行的資料。
我想你需要實際的問題細節,為什么不一次性提取所有的資訊,而要用你的formulate函式提供的id和key第二次查詢資料庫呢?
import easy_db
import random
def alternate_formulate(*quizparams)。
db = easy_db.DataBase("QuizApp.DB") # 連接到資料庫。
questions = db.pull("questions") # 獲取 "questions "表作為dicts的串列。
random.shuffle(questions) # 隨機化問題的順序。
結果 = []
for num_q, marks in quizparams:
# 過濾到有正確分數的行,并限制行的數量為num_q。
subset = [row for row in questions if row["marks"] == marks] [:num_q]
結果.extend(subset)
print(results)
alternative_formulate([2,3], [1,5] )
>>>[{'id': 2, 'question': '什么城市...', 'key': 4, 'marks': 3, ...},
{'id': 1, 'question': 'What is the...', 'key': 1, 'marks': 3, ...},
{'id': 3, 'question': '哪個動物...', 'key': 3, 'marks': 5, ...}] 。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/327121.html
標籤: