問題概述
我想用Pandas在Python中加載.txt檔案。
示例檔案
為了證明我的問題,我創建了一個測驗檔案,在vi中編輯后如下:
"姓名"|"姓氏"|"地址"|"注釋"^M
"Angelo"|""|"Kenton Square 5"|"note 1"^M
"Angelo"|""|"肯頓的^M
Sqr5"|"note2"^M
"Angelo"|""|"Kenton"s ^M
路"|"Note3"^M
加載資料
為了加載這個檔案,我在Jupyter筆記本中運行以下命令:
test = pd.read_csv('test.txt', sep ='|')
這就像下面的螢屏截圖一樣加載了檔案:
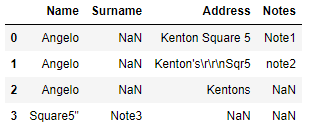
問題
我想解決檔案中的例子 "note2 "和 "note3 "所代表的兩個問題:
note2的問題
note2問題 我怎樣才能在加載檔案時去掉^M呢?
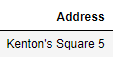
- 我是否應該在使用bash命令加載檔案之前洗掉這些內容,或者
- 我是否應該在使用bash命令加載檔案之前洗掉這些內容?
- 我是否應該在使用Python將其加載到Jupyter中之后洗掉這些內容?
- 你能建議在每種情況下的代碼嗎,你會推薦哪一種(以及為什么)?
Note3問題
如何將字串運算式中的雙引號替換為撇號?這里它將其分解到另一行,這是不正確的。這應該裝在第2行,如下所示。
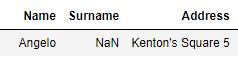
"Note3 "的例子是一個復合的例子,因為它在字串中也有"^M "字符,但在這里我感興趣的是用一撇一捺來替換雙引號,這樣它就不會破壞它到另一行的加載了。
謝謝你的幫助,非常感謝。
Angelo
uj5u.com熱心網友回復:
如何用撇號替換字串運算式中的雙引號?
如果要轉換為'的總是在字母(單詞)之間,你可以使用正則運算式(re)按以下方式預處理你的檔案
import re
txt = ''"姓名"|"姓氏"|"地址"|"注釋"
"Angelo"|""|"Kenton Square 5"|"Note 1"
"Angelo"|""|"Kenton的
Sqr5"|"備注2"
"Angelo"|""|"Kenton "s
路"|"注3"''/span>
clean_text = re.sub(r'(?<=w)"(?=w)', "' ", txt)
print(clean_text)
輸出
"姓名"|"姓氏"|"地址"|"注釋"。
"Angelo"|""|"Kenton Square 5"|"備注1"。
"Angelo"|""|"肯頓的
Sqr5"|"note2"
"Angelo"|""|"肯頓的
路"|"Note3"。
解釋:使用零長度的斷言來尋找"",它位于單詞字符之后和單詞字符之前。
如果你有文本檔案,首先要把它當作文本檔案來讀,即:
如果你有文本檔案,首先要把它當作文本檔案來讀。
with open("test.txt"/span>,"r"/span>) as f:
txt = f.read()
然后清理它
import re
clean_text = re.sub(r'(?<=w)"(?=w)', " '", txt)
然后用io.StringIO將其放入pandas.DataFrame,如下所示
import io
import pandas as pd
test = pd.read_csv(io.StringIO(clean_text), sep ='|')
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/327684.html
標籤: