我一直試圖根據我發現的一個解決方案來創建這個python csv分割器。
第一個問題是在每個子檔案中保留第一行(列標題)。它沒有在每個檔案分割中保留第一行作為 "標題"。
第二個問題是,我試圖將分割后的檔案發送到腳本創建的一個子目錄。它確實找到了這個目錄,但它在第一次分割時就停止了,它沒有像以前那樣繼續分割回圈,而我卻把它留在了根檔案夾上。
有誰知道這是怎么做到的?
這里是腳本:
import os
import time
import pandas as pd
# 要讀入的csv檔案名'D:path est.csv'
# get the number of lines of the csv file to be read
number_lines = sum(1 for row in (open(in_csv))
# 寫入csv的資料行數大小,。
# 你可以根據你的需要改變行的大小。
rowsize = 100
# 開始回圈處理資料,每組資料寫入一個新檔案。
for i in range(0, number_lines, rowsize):
df = pd.read_csv(in_csv,
nrows=rowsize, # 每次回圈要讀取的行數# 跳過已經讀取的行。
# Subdir maker[/span]。
directory = 'output'/span>
parent_dir = 'path/rows'/span>
path = os.path.join(parent_dir, directory)
os.mkdir(path)
print('Directory created.
')
time.sleep(2)
# csv將資料寫入一個帶有索引名稱的新檔案。 input_1.csv等。
out_csv = os.path.join(path, 'NewFile' str(i) ' .csv')
print('Initiating slicer...' )
time.sleep(2)
df.to_csv(out_csv,
index=False,
header=True,
mode='a', #append data to csv file.
chunksize=rowsize) # 每個回圈要追加的資料大小。
預先感謝大家。
uj5u.com熱心網友回復:
你可以使用一個range而不是一個整數,以便在保留標題的同時跳過行。在這種情況下,你也想從i開始,而不是0。
for i in range(1, number_lines, rowsize)。
df = pd.read_csv(in_csv,
nrows=rowsize, # 每次回圈要讀取的行數range(1, i) # 跳過已經讀過的行。
另外,你只需要創建一次輸出目錄,所以你應該在回圈之前做這個。只需將 "Subdir maker "部分移到回圈之前。
uj5u.com熱心網友回復:
你可以嘗試在pd.read_csv中指定header
df = pd.read_csv(in_csv,
header=0
nrows=rowsize, # 每次回圈讀取的行數# 跳過已經讀取的行。
uj5u.com熱心網友回復:
我從來沒有使用過pandas,但是我用純Python做了一些CSV的東西,它總是能夠成功。以下是我認為你想做的事情的一個版本,沒有依賴性:
import csv, os
def get_csv_writer(path)。
csv_file = open(path, newline=""/span>, mode="w"/span>)
return csv.writer(csv_file), csv_file
rowsize=100
in_csv = "test.csv"/span>
number_lines = sum(1 for row in (open (in_csv))
with open(in_csv, newline=""/span>, mode="r"/span>) as foo_csv:
reader = csv.reader(foo_csv)
header = reader.__next__()
filenum =1
csv_dir = "split_csv"。
os.mkdir(csv_dir)
filename = f "foo{filenum}.csv"。
path = os.path.join(csv_dir, filename)
csv_writer, csv_file = get_csv_writer(path)
csv_writer.writerow(header)
for i, row in enumerate(reader):
if i % rowsize == 0 and i != 0:
csv_file.close()
filenum = 1: csv_file.close()
filename = f "foo{filenum}.csv"/span>。
path = os.path.join(csv_dir, filename)
csv_writer, csv_file = get_csv_writer(path)
csv_writer.writerow(header)
csv_writer.writerow(row)
下面是在我的機器上看起來的情況:
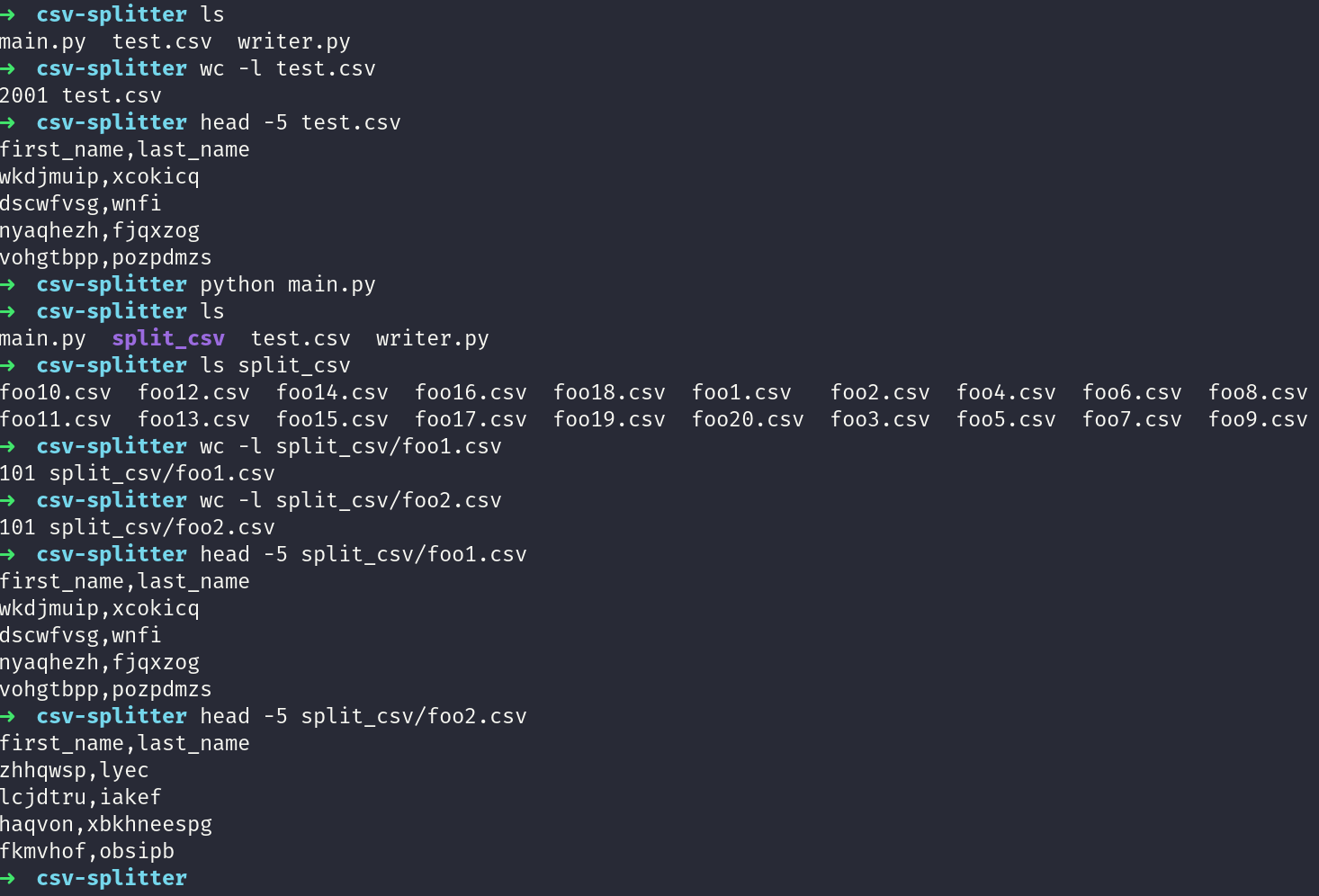
請注意,每個檔案有101行,因為標題是第一行。
uj5u.com熱心網友回復:
將第一行設定為 "索引 "將在資料框架(df)中保持其位置。
下面是一行代碼,當你的資料在df中,但在你開始進一步操作它之前,你可以插入這行代碼:
在資料框架中,你可以插入這行代碼。
df.set_index('Title', inplace=True) # 設定'列的標題'作為索引值。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/328052.html
標籤: